Scaling Beyond Masked Diffusion Language Models
Abstract: Diffusion LLMs are a promising alternative to autoregressive models due to their potential for faster generation. Among discrete diffusion approaches, Masked diffusion currently dominates, largely driven by strong perplexity on language modeling benchmarks. In this work, we present the first scaling law study of uniform-state and interpolating discrete diffusion methods. We also show that Masked diffusion models can be made approximately 12% more FLOPs-efficient when trained with a simple cross-entropy objective. We find that perplexity is informative within a diffusion family but can be misleading across families, where models with worse likelihood scaling may be preferable due to faster and more practical sampling, as reflected by the speed-quality Pareto frontier. These results challenge the view that Masked diffusion is categorically the future of diffusion language modeling and that perplexity alone suffices for cross-algorithm comparison. Scaling all methods to 1.7B parameters, we show that uniform-state diffusion remains competitive on likelihood-based benchmarks and outperforms autoregressive and Masked diffusion models on GSM8K, despite worse validation perplexity. We provide the code, model checkpoints, and video tutorials on the project page: http://s-sahoo.github.io/scaling-dllms
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies a new way for computers to write text quickly and well. Most LLMs today write one word at a time from left to right (called “autoregressive” or AR). Diffusion LLMs work differently: they fill in and improve the whole sentence in several passes, which can be faster. The paper compares three kinds of diffusion models to see how they perform as they get bigger and how fast they can generate text, and asks: Is the currently popular “Masked diffusion” method really the best long-term choice?
Key objectives
Here are the main questions the paper tries to answer:
- How do different diffusion LLMs improve as we give them more computing power and data? This is called studying “scaling laws.”
- Is “perplexity” (a standard score that measures how surprised a model is by the test data) the best way to compare different diffusion methods?
- Can we make Masked diffusion models train more efficiently with a simple change to their training objective?
- Which models give the best balance between speed and quality when generating text?
- How do these models perform when scaled up to 1.7 billion parameters, especially on math word problems like GSM8K?
Methods and approach
Think of text generation like writing a paragraph:
- Autoregressive (AR) models write one word at a time, left to right, carefully keeping track of what they’ve already written. This can be slow because you can’t write the next word until you finish the current one.
- Diffusion models write by revising the whole paragraph in multiple passes. They start with a messy or partially blank version and repeatedly “clean it up” across several steps. This can be faster because many parts are updated at the same time.
The paper focuses on three diffusion families:
- Masked diffusion (MDLM): Imagine a sentence with blanks (mask tokens) that the model fills in and un-masks step by step.
- Uniform-state diffusion (Duo): Instead of blanks, tokens are fuzzed toward “random letters,” and the model repeatedly corrects them. This allows self-correction and often good results in fewer steps.
- Interpolating diffusion (Eso-LM): A hybrid between AR and Masked diffusion. It uses AR-style memory tricks called “KV caching” so it can reuse past computations and speed up decoding, while still updating multiple tokens in parallel.
How they compare models:
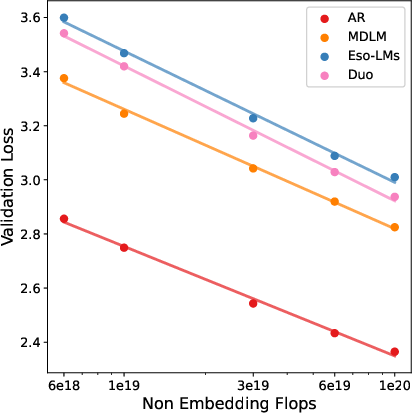
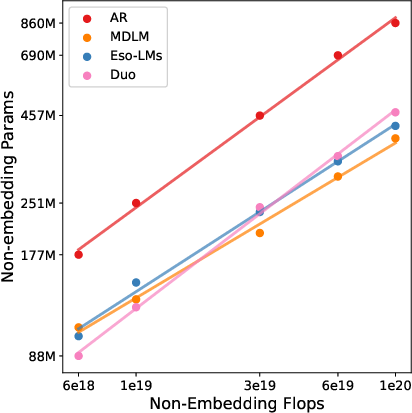
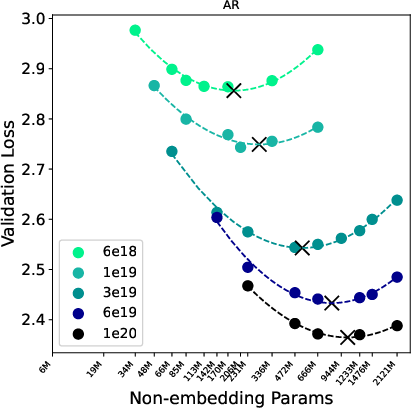
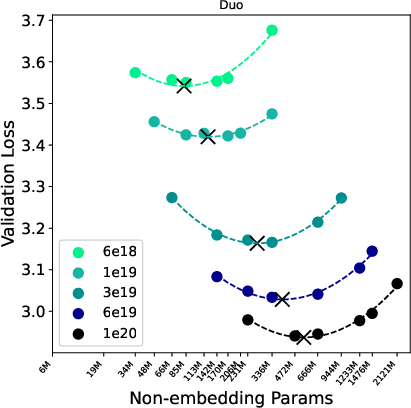
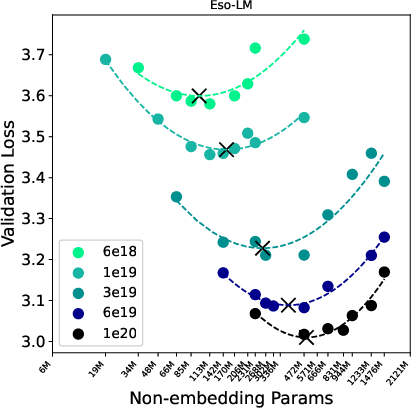
- Scaling laws: They match training compute (“IsoFLOP,” think same spending budget) and study how validation loss (related to perplexity) and best model size change as compute increases.
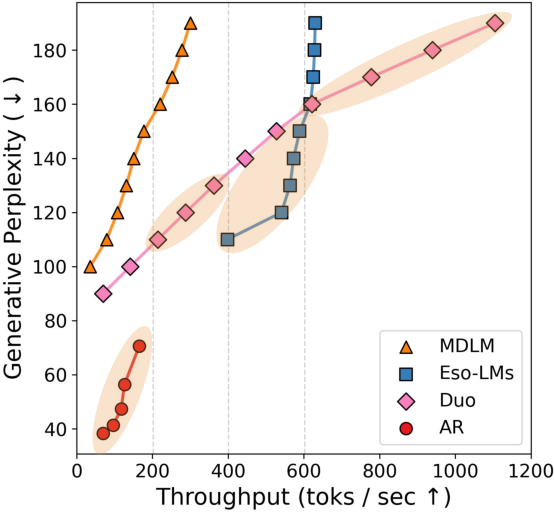
- Speed vs. quality: They measure how good the generated text is (using a “Generative Perplexity” score from a strong AR evaluator) and how many tokens per second the model can produce. They then draw a “Pareto frontier,” which shows the best speed-quality trade-offs.
- Training tweak for MDLM: They use a simpler, lower-variance training loss (similar to cross-entropy) that makes MDLM training more stable and compute-efficient.
- Large-scale test: They train all methods to 1.7B parameters and test on both general benchmarks and GSM8K (math word problems).
Technical terms in everyday language:
- Perplexity: A lower number means the model better predicts test data. Think of it as “how surprised the model is by the correct answers.”
- KV caching: A way for AR-like models to remember past work so they don’t redo the same calculations.
- Few-step sampling: Generating good text with fewer passes, which is faster.
- Pareto frontier: The set of best possible speed-quality points where you can’t get faster without getting worse quality, or vice versa.
Main findings
1) Perplexity is useful, but not the whole story
- Within one family of diffusion models, perplexity can guide improvements.
- Across different diffusion families, comparing perplexity can be misleading because they use different noise processes and likelihood bounds. A model with slightly worse perplexity might be better in practice if it generates faster or improves more with extra sampling steps.
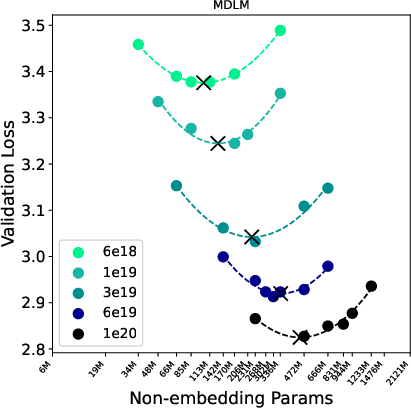
2) A simple training change makes Masked diffusion more efficient
- Training MDLMs with a low-variance loss (a simpler version of the usual objective) makes them about 12% more FLOPs-efficient compared to the standard training. This means they use less compute to reach the same validation loss.
- This also shifts the “best” MDLM checkpoints toward smaller models, which can reduce the cost of running them at inference time.
3) Speed-quality trade-offs differ across families
- AR models produce the highest-quality samples but are slow because they generate one token at a time.
- Duo (Uniform-state diffusion) tends to dominate in speed when the desired throughput is high, thanks to efficient few-step generation.
- Eso-LM (Interpolating diffusion) is best in a middle speed range because it uniquely supports KV caching while still generating in parallel.
- Sample diversity (measured by entropy) remains broadly similar across methods.
In plain terms: depending on whether you want the absolute best quality or the fastest generation, different models come out on top.
4) Billion-parameter results: math matters
- At 1.7B parameters, AR was strongest on standard validation-style benchmarks.
- Duo was competitive on those benchmarks despite worse validation perplexity.
- On GSM8K (math word problems) after supervised fine-tuning, Duo performed best among AR, MDLM, and Eso-LM—even though its validation perplexity was worse. This suggests that some diffusion methods may have strengths in reasoning tasks that aren’t captured by perplexity alone.
Implications and impact
- Don’t judge diffusion LLMs only by perplexity. Consider how they sample, how fast they can generate, and how they perform on real tasks.
- If you need the highest raw text quality and don’t mind slower generation, AR is strong.
- If you need fast generation with good quality in fewer steps, Uniform-state diffusion (Duo) is a great choice.
- If you want parallel generation plus AR-style speedups like KV caching, Eso-LM is compelling in the middle speed range.
- A small training tweak can make Masked diffusion more compute-efficient, which helps when scaling models.
- Diffusion LLMs are a promising alternative to AR, and future larger-scale studies might reveal new advantages—especially for tasks involving reasoning and multi-step thinking.
Overall, the paper argues that the “best” model depends on your goals: speed, quality, or task type. It encourages the community to look beyond perplexity and include practical generation speed and downstream performance when comparing LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up studies.
- Cross-family likelihood comparability
- No unified, cross-family-comparable likelihood metric is provided; NELBOs differ across MDLM, Duo, and Eso-LM, making perplexity-based scaling comparisons potentially misleading. Develop or validate a common evaluation bound or alternative likelihood proxy that is comparable across diffusion families.
- Reliance on Gen PPL under a single AR evaluator
- Speed–quality frontiers use “Gen PPL” measured by Llama‑2‑7B only; robustness to evaluator choice is untested. Evaluate multiple evaluator models (sizes/architectures) and include human preference judgments to verify that conclusions on the Pareto frontier are stable.
- Limited diversity/quality metrics
- Diversity is proxied by sequence entropy only; other measures (self-BLEU, distinct‑n, repetition ratios, MAUVE) and human assessments are not reported. Add complementary metrics to confirm that speed gains do not degrade semantic diversity or coherence.
- Unconditional generation focus in speed–quality tradeoffs
- Throughput and Gen PPL are computed for unconditional sampling. Extend the analysis to conditional tasks (e.g., instruction following, summarization, code) where conditioning and KV caching interact differently with decoding parallelism.
- Single precision regime for sampling vs real-world deployability
- All diffusion sampling is run in float64 to avoid numerical issues, whereas deployment typically uses bfloat16/float16. Quantify quality/diversity degradation and instabilities under low-precision sampling, and assess algorithmic or normalization fixes that preserve stability in realistic settings.
- Restricted sampler ablations
- MDLM and Duo are evaluated with the ancestral sampler; Eso‑LM with a specific block sampler. Compare a broader set of samplers (e.g., tempered resampling, remasking, guidance, deterministic or partial resampling schedules) across families to isolate algorithmic vs architectural contributions to speed–quality tradeoffs.
- Noise schedule sensitivity
- The low‑variance MDLM objective is validated under a linear schedule; sensitivity to other schedules (cosine, learned schedules) is not explored. Evaluate whether compute-efficiency gains persist across schedules and step discretizations.
- Objective-design space beyond the proposed low-variance MDLM loss
- Only one variance-reduction tweak is tested. Investigate alternative objectives (e.g., discrete flow matching variants, contrastive or denoising cross-entropy hybrids) for MDLM, Duo, and Eso‑LM, and quantify their impact on scaling exponents and constants.
- Limited compute range for scaling-law fits
- Scaling exponents are estimated up to ≈1e20 training FLOPs. Test larger budgets and model sizes to check for exponent shifts, breakpoints, or family-specific regime changes, especially given known non-linearities in LLM scaling.
- Hyperparameter confounding in “compute-optimal” curves
- A single optimizer, schedule, and weight decay are used across families. Verify that compute-optimal model sizes and loss exponents are robust to hyperparameters (LRs, warmup, clipping, regularization, batch size).
- Architecture fairness and confounds
- Eso‑LM uses decoder-only causal denoisers with shuffled inputs, while MDLM/Duo use bidirectional denoisers; AR keeps time-conditioning modules inactive. Provide ablations that hold the backbone (causal vs bidirectional) fixed across families to disentangle diffusion-process effects from architectural capacity.
- KV caching benefits not fully characterized
- Claims about Eso‑LM’s KV caching advantage are not validated in realistic long-context, online (single-stream) and batched settings. Measure both latency and throughput as a function of context length and output length, including cache warmup costs and memory ceilings.
- Context-length generalization
- All small-scale scaling uses context length 2048. Test longer contexts (e.g., 8k–32k) to assess whether diffusion families differ in long-context efficiency, quality, cacheability, and degradation patterns.
- Dataset and tokenizer shifts across scales
- Small-scale experiments use SlimPajama and a 32k tokenizer; 1.7B experiments use a 128k vocabulary and the Nemotron dataset mix. Re-run at scale with the same tokenizer/data to eliminate confounds and validate that Pareto and scaling conclusions hold.
- Limited downstream coverage
- Downstream evaluation is restricted to a small suite of MCQ tasks and GSM8K. Assess broader tasks (MMLU, BIG-bench, code, translation, summarization, reasoning beyond arithmetic) to evaluate whether the observed trade-offs generalize.
- GSM8K decoding collapses to left-to-right
- To align with prior work, diffusion models are decoded left-to-right (collapsing parallel advantages). Test diffusion-native decoding strategies (few-step refinement, guided denoising, or hybrid decoding) on math/reasoning to see if advantages persist when parallelism is used.
- Mechanistic understanding of Duo’s math advantage
- Duo outperforms AR/MDLM on GSM8K after SFT despite worse perplexity, but the causal factors (self-correction, error propagation, inductive biases) are not analyzed. Provide controlled experiments and behavior diagnostics (e.g., error localization, iterative refinement success rates).
- Training-time vs inference-time compute tradeoffs
- IsoFLOP scaling focuses on training compute; inference cost differences (steps vs model size vs cache reuse) are only partially captured via throughput. Develop a joint train+inference compute budget framework to identify deployment-optimal regimes.
- Calibration and confidence estimation
- Prior work uses confidence-based sampling; this paper avoids it on GSM8K. Evaluate calibration across families (ECE, Brier) and how confidence signals affect decoding strategies and downstream quality.
- Robustness and distribution shift
- No experiments probe robustness to noisy inputs, out-of-distribution prompts, or adversarial perturbations. Test stability and sample quality under perturbations and domain shifts for each diffusion family.
- Guidance and controllability at scale
- Duo purportedly excels at guided generation; this is not tested here. Benchmark controllability (e.g., classifier-free guidance, constrained decoding) across families in both few-step and many-step regimes.
- Numerical stability and error accumulation
- The paper notes degeneracy issues with certain block decoders at low steps but does not characterize failure modes quantitatively. Map error accumulation across steps/timesteps and propose diagnostics for sampler-induced artifacts.
- Token-remasking/denoising order effects
- Eso‑LM’s shuffled/blocked order and MDLM’s denoising order influence performance. Systematically study orderings (random, heuristic, learned) and their impact on quality and speed.
- Parameter–data allocation and optimality under diffusion
- Compute-optimal allocations are inferred from empirical sweeps; a theoretical or semi-analytic framework for optimal parameter/data scaling in discrete diffusion remains open. Derive or validate Chinchilla-like laws tailored to diffusion families.
- Reproducibility and open baselines
- While code/checkpoints are promised, critical artifacts (evaluator models, exact preprocessing filters, sampler implementations) need full release to reproduce speed–quality frontiers. Ensure standardized harnesses to avoid evaluation drift.
- Safety and moderation in parallel decoding
- Parallel refinement may interact with toxicity/faithfulness filters differently than AR decoding. Evaluate harmful output rates and the effectiveness of post-hoc filtering across families and samplers.
- Energy and cost accounting
- Throughput (tokens/s) is reported, but energy efficiency (J/token), memory footprint, and cost-per-quality-point are not measured. Provide holistic hardware-aware cost curves to inform deployment choices.
- Generalization to multilingual/tokenizer-rich settings
- Results are primarily monolingual/tokenizer-specific. Test whether conclusions hold across multilingual corpora and radically different tokenizations (e.g., byte-level, unigram), especially for USDM where uniform priors interact with vocabulary size.
- Extensibility to mixture-of-experts and retrieval-augmented settings
- The interplay between diffusion families and MoE routing or retrieval/KV-sharing is unexplored. Evaluate whether KV-caching advantages of Eso‑LM amplify in MoE or RAG architectures.
Glossary
- Adaptive layer normalization: A variant of layer normalization that conditions on auxiliary inputs (e.g., diffusion time) to modulate activations. "All models use the Diffusion Transformer (DiT) backbone \citep{peebles2023scalable}, with rotary positional embeddings \citep{su2023roformer} and adaptive layer normalization for conditioning on diffusion time (with learnable parameters)."
- Ancestral sampler: A sampling procedure that iteratively samples from learned conditional distributions step-by-step. "for MDLM and Duo we use the ancestral sampler and vary the number of sampling steps via ;"
- AO-ARMs: Auto-encoding autoregressive models; a framework connecting masked diffusion and autoregressive decoding. "it exploits the connection between MDMs and AO-ARMs~\citep{ou2025your} to use a decoder-only denoiser with causal attention applied to a shuffled ."
- Autoregressive (AR): Models that factorize sequence likelihood left-to-right and generate one token at a time. "Autoregressive (AR) LLMs have long dominated text generation due to strong likelihoods and a mature training and evaluation ecosystem."
- Bidirectional attention: Attention mechanism where tokens attend to both left and right context. "For MDMs, we use bidirectional attention and likewise set the diffusion-time input to zero."
- Block diffusion: A diffusion approach that decodes consecutive tokens in parallel. "Unlike block diffusion~\citep{arriola2025block}, it supports KV caching without sacrificing parallel generation."
- Block sampler: A sampler that denoises only well-separated tokens in parallel per step. "Inspired by the discovery, \citet{sahoo2025esoteric} proposes a sampler for Eso-LM that improves upon the ancestral sampler in MDLM, called the Block sampler, that only decodes far-apart tokens in parallel and significantly improves sample quality at low sampling steps."
- Causal attention: Attention restricted to past positions to enable left-to-right decoding and caching. "A practical advantage of causal attention is that one can cache key/value states from earlier positions, substantially reducing the cost of decoding during inference (KV caching)."
- Compute-optimal: The choice of parameters and data that minimizes validation loss for a fixed training compute budget. "We fit scaling laws for compute-optimal validation loss and model size, enabling direct comparisons of scaling exponents and constant-factor gaps."
- Denoiser: The neural network that predicts clean token distributions from corrupted inputs during diffusion. "Let be a denoiser (typically a bidirectional Transformer) that outputs a categorical distribution for each position."
- Diffusion LLMs (d-LLMs): LLMs that generate by iterative denoising rather than left-to-right decoding. "Diffusion LLMs are a promising alternative to autoregressive models due to their potential for faster generation."
- Diffusion Transformer (DiT): A Transformer architecture adapted for diffusion modeling. "All models use the Diffusion Transformer (DiT) backbone \citep{peebles2023scalable}, with rotary positional embeddings \citep{su2023roformer} and adaptive layer normalization for conditioning on diffusion time (with learnable parameters)."
- Entropy: A measure of sample diversity. "Sample diversity (measured by entropy) remains broadly similar across algorithms, with Duo exhibiting slightly reduced diversity; see Fig.~\ref{fig:all-quality-entropy}."
- Esoteric LLM (Eso-LM): A hybrid model that interpolates between masked diffusion and autoregressive generation. "Esoteric LLM (Eso-LM)~\citep{sahoo2025esoteric} is a hybrid model of AR and MDLM."
- Few-step generation: Producing samples in a small number of diffusion steps to improve speed. "Duo supports few-step generation, and Eso-LM support KV caching capabilities not reflected in validation perplexity alone."
- FLOPs: Floating-point operations; a measure of computational cost. "We compute exact training compute (combined forward and backward FLOPs) using the calflops Python package~\citep{calflops}."
- Forward noising process: The corruption process that gradually moves data toward a simple prior. "Discrete diffusion models construct a forward noising process that gradually transforms clean data into a simple prior, and then learn a reverse generative process to map the samples from the prior distribution to data"
- Generative Perplexity (Gen PPL): An evaluator-computed perplexity used to assess sample quality. "we draw 1000 unconditional samples and compute Generative Perplexity (Gen PPL) under a pretrained Llama-2 (7B) model."
- GSM8K: A math word problem benchmark for evaluating reasoning. "We also assess mathematical reasoning on GSM8K~\citep{cobbe2021training}."
- IsoFLOP: Analysis under fixed training compute budgets for fair scaling comparisons. "We perform an IsoFLOP study \citep{hoffmann2022training} over compute budgets"
- KV caching: Caching key/value attention states to accelerate inference. "Interpolating diffusion methods~\citep{arriola2025block, sahoo2025esoteric} support KV caching during inference, enabling substantially faster decoding than other diffusion families."
- Likelihood scaling: How likelihood-based metrics improve with compute. "While MDLM exhibits the strongest likelihood scaling, we show that (i) its scaling can be improved with a low-variance training objective, reducing the compute multiplier to within about 12\% of AR while shifting compute-optimal checkpoints toward smaller models, and (ii) diffusion families with worse perplexity scaling, notably Duo and Eso-LM, can dominate the speed-quality Pareto frontier due to more efficient sampling."
- Masked Diffusion LLMs (MDLM): Discrete diffusion models that corrupt tokens into a mask state and denoise them. "In particular, discrete diffusion models, especially Masked Diffusion LLMs (MDLM)Unlike block diffusion, have closed much of the perplexity gap to AR models at small scales~\citep{sahoo2024simple, shi2025simplifiedgeneralizedmaskeddiffusion, ou2025your, arriola2025block}."
- Negative Evidence Lower Bound (NELBO): The negative variational training objective that upper-bounds negative log-likelihood. "Eso-LM is trained using the low-variance objective in~#1{eqn:mdlm_low_var} and evaluated using the exact NELBO in~#1{eq:mdlm-nelbo}."
- Noise schedule: A schedule controlling the corruption level over diffusion time. "Here decreases monotonically with and serves as the {noise schedule}: corresponds to (nearly) clean data, and corresponds to the prior."
- Pareto frontier: The set of non-dominated trade-offs between speed and quality. "To construct a speed-quality Pareto frontier, we proceed as follows."
- Perplexity: A standard likelihood-based metric for language modeling performance. "Diffusion-based LLMs (d-LLMs) are typically optimized and compared using likelihood-based metrics such as validation perplexity."
- Reverse posterior: The conditional distribution used to denoise from a noisier state. "For , the exact reverse posterior has a convenient form due to the absorbing nature of the mask: if , the token must remain fixed; if , the posterior mixes between the clean token and the mask distribution~\citep{sahoo2024simple}:"
- Rotary positional embeddings: Position encodings that rotate queries/keys by position-dependent phases. "All models use the Diffusion Transformer (DiT) backbone \citep{peebles2023scalable}, with rotary positional embeddings \citep{su2023roformer} and adaptive layer normalization for conditioning on diffusion time (with learnable parameters)."
- Scaling laws: Empirical power-law relationships between performance, size, and compute. "Scaling Laws. Diffusion models exhibit similar scaling behavior wrt AR models."
- Self-correction: The ability to revise tokens multiple times during reverse diffusion. "As a result, the reverse process can revise token values multiple times, enabling ``self-correction'' and improving few-step sampling and guided generation."
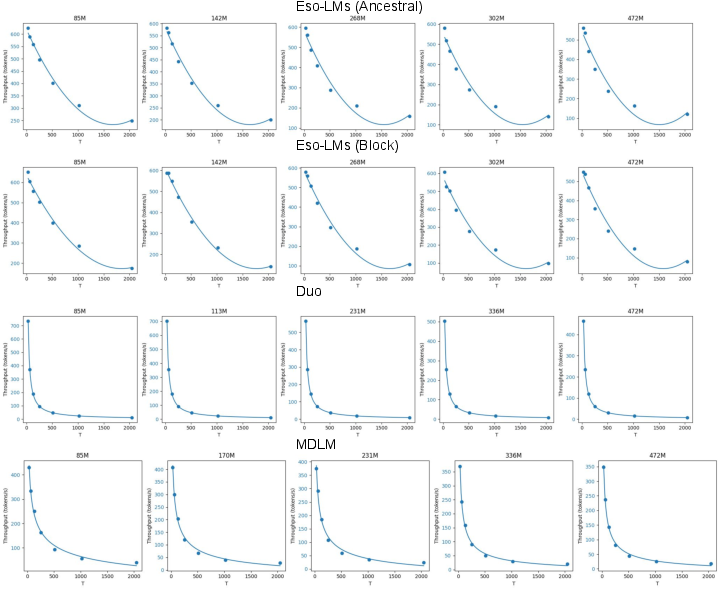
- Throughput: Tokens per second generated during sampling. "We report the highest throughput achieved by compute-optimal models across a range of training FLOPs budgets."
- Uniform-state Diffusion Models (USDMs): Diffusion models that diffuse toward a uniform categorical prior. "Uniform-state Diffusion Models (USDMs)~\citep{lou2024discrete,schiff2025simple,sahoo2025the} instantiate #1{eq:interp-forward} with a uniform prior :"
- Variational bound: A tractable lower bound on log-likelihood used for training. "Training is commonly phrased in terms of a negative variational bound on ."
Practical Applications
Overview
Based on the paper’s findings on scaling laws and speed–quality trade-offs for discrete diffusion LLMs (d-LLMs)—including Masked Diffusion (MDLM), Uniform-state Diffusion (Duo), and interpolating diffusion (Eso-LM)—the following lists distill actionable, real-world applications. Each item specifies sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed with current methods, code, and model checkpoints provided by the authors.
- Diffusion-aware inference routing for LLM services (software/AI infrastructure)
- What: Route requests across AR, Duo, and Eso-LM based on target quality and latency using the paper’s speed–quality Pareto frontier. Dynamically set sampling steps T (and block size L′ for Eso-LM) to hit SLA targets.
- Tools/Workflows: Inference middleware that monitors throughput and Gen-PPL or proxy scores; auto-tuner for T/L′; model pool with hot-swapped weights.
- Assumptions/Dependencies: Models and checkpoints loaded concurrently; agreed-upon quality proxy (e.g., evaluator-based Gen PPL); sufficient GPU memory; batch size tuned per model.
- Adopt low-variance cross-entropy training for MDLM (software/LLM training)
- What: Replace the high-variance NELBO with the simple cross-entropy training loss for MDLM to save ~12% training FLOPs and shift compute-optimal checkpoints to smaller models.
- Tools/Workflows: Training code patch for objective; evaluation retains NELBO; existing DiT backbones; standard AdamW schedules.
- Assumptions/Dependencies: Comparable data regime; same tokenizer; downstream benchmarks tolerate minor distribution shifts; evaluation uses correct ELBO.
- Few-step high-throughput generation with Duo for short-form content (media, marketing, localization)
- What: Use Duo’s self-correction and few-step sampling to generate many short outputs quickly (e.g., variants, paraphrases, ad-text).
- Tools/Workflows: Ancestral sampler with small T (e.g., 3–8 steps); batched parallel decoding; optional guidance for controllability.
- Assumptions/Dependencies: Quality targets achievable at low T; prompts/tasks well-suited to short outputs; monitoring for diversity and style drift.
- KV-cached diffusion in the mid-throughput regime via Eso-LM + block sampler (software/AI infra)
- What: Deploy Eso-LM in full diffusion mode with the block sampler—supporting KV caching and parallel generation—to dominate throughput in 400–600 toks/s regimes.
- Tools/Workflows: Implement block sampler (ensure L′ divides context length); causal denoiser with shuffled inputs; K/V cache-enabled inference stack.
- Assumptions/Dependencies: Causal attention denoiser; hardware with ample memory bandwidth; quality tuned via L′ and T; careful choice of block distance to avoid degeneration.
- Math/logic assistants using Duo after SFT (education, tutoring platforms)
- What: Build math-solvers and reasoning tutors leveraging Duo’s strong GSM8K performance after supervised fine-tuning.
- Tools/Workflows: SFT on math datasets (e.g., GSM8K-style); left-to-right decoding for evaluations; optional chain-of-thought formatting; confidence calibration.
- Assumptions/Dependencies: Licensed/curated math data; generalization beyond GSM8K; cost-effective serving at chosen T; prompt hygiene for correctness.
- Guidance-friendly, controllable text generation (healthcare documentation, advertising copy)
- What: Use Uniform-state diffusion’s self-correction and guidance compatibility for constrained generation (e.g., structured medical notes, constrained brand-safe outputs).
- Tools/Workflows: Classifier- or rule-guided sampling; constraints integrated into reverse process; step-wise rescoring; partial rejection sampling.
- Assumptions/Dependencies: Reliable guidance signals; domain-validated constraints; careful tuning to avoid mode collapse; governance for regulated content.
- Compute-optimal training planning (MLOps/academia)
- What: Apply the IsoFLOP procedure and fitted scaling to pick parameter count N and tokens D for a fixed FLOPs budget; reduce over/under-parameterization.
- Tools/Workflows: FLOPs calculators; grid search templates; second-order fits in log N; Chinchilla-style curves adapted for diffusion families.
- Assumptions/Dependencies: Large-data regime; similar architectures/tokenizers; stable optimization hyperparameters.
- Evaluation dashboards beyond perplexity (academia, policy, procurement)
- What: Report speed–quality Pareto curves, evaluator-based Gen PPL, and sequence entropy, not just validation perplexity, especially for cross-family comparisons.
- Tools/Workflows: Evaluation harness with strong AR evaluator (e.g., Llama-2 7B) for Gen PPL; float64 sampling for diversity stability; entropy tracking.
- Assumptions/Dependencies: Agreement on evaluator model; compute for high-precision sampling; community acceptance of metrics.
- Edge/on-device text generation via few-step diffusion (mobile apps, embedded devices)
- What: Use small Duo or Eso-LM checkpoints with low T for simple tasks (auto-replies, canned responses, templated text).
- Tools/Workflows: Quantization; distillation; on-device inference with small T; trigger-based activation to limit compute.
- Assumptions/Dependencies: Accuracy acceptable for task; memory constraints; power/thermal limits; robust offline tokenizer.
- Throughput-tiered API SKUs (business/operations)
- What: Offer product tiers mapping to different diffusion families and sampling steps (e.g., “fast”, “balanced”, “quality-first”), priced by throughput/latency.
- Tools/Workflows: Inference router; billing telemetry tied to T and model type; customer-facing SLAs per tier.
- Assumptions/Dependencies: Stable mappings from T/model to perceived quality; effective monitoring and rollback policies.
Long-Term Applications
These require further research, scaling, or systems engineering.
- Hybrid decoding engines that auto-switch AR/Duo/Eso-LM (software/AI infra)
- What: Segment texts by difficulty/sensitivity and allocate decoding across AR (for top quality), Duo (for low-latency), and Eso-LM (for KV-cached mid-latency), possibly at token- or span-level.
- Tools/Workflows: Bandit/RL controllers; quality predictors; per-span budgeters; streaming interfaces.
- Assumptions/Dependencies: Interoperable vocabularies and prompts; smooth continuity across segments; guardrails for quality consistency.
- Hardware–software co-design for few-step diffusion and block sampling (semiconductor, cloud providers)
- What: Accelerators that exploit high parallelism and sparse attention patterns of block samplers, optimized KV cache pipelines for diffusion.
- Tools/Workflows: Compiler passes specialized for step-wise denoising; cache prefetch; tensor-core utilization for small-T regimes.
- Assumptions/Dependencies: Algorithmic stability across versions; market size for diffusion-first serving; ISA support.
- Standardized evaluation and procurement standards beyond perplexity (policy/standards bodies)
- What: Require reporting speed–quality Pareto curves, evaluator-based Gen PPL, and energy/throughput for public model cards and RFPs.
- Tools/Workflows: Shared benchmarks and evaluators; reproducible FLOPs and energy accounting; governance templates.
- Assumptions/Dependencies: Community and industry buy-in; legal/regulatory clarity.
- Energy-efficient operations via diffusion-aware scheduling (energy/sustainability, cloud FinOps)
- What: Reduce energy by selecting smaller compute-optimal checkpoints and lower T when acceptable, carbon-aware routing between AR/diffusion regimes.
- Tools/Workflows: Carbon intensity monitoring; cost/quality/energy tri-optimization; auto-scaling policies.
- Assumptions/Dependencies: Accurate energy telemetry; robust QoS monitoring; acceptance of small quality trade-offs.
- Domain-specific Duo variants for structured reasoning and verification (software verification, legal, finance)
- What: Leverage self-correction to iteratively refine and verify outputs (e.g., contract clause checks, financial reconciliations, code spec conformance).
- Tools/Workflows: Integrations with verifiers/checkers; step-wise critique-and-revise loops; programmatic constraints.
- Assumptions/Dependencies: High-quality domain data; verifier coverage; risk controls for failure modes.
- Bidirectional-capacity diffusion with KV caching (research frontier)
- What: New architectures that retain bidirectional capacity of MDLM/USDM while enabling KV cache-like speedups (e.g., via masked causal factorization or reordered denoising).
- Tools/Workflows: Novel attention layouts; learned generation orders; block-sparse kernels.
- Assumptions/Dependencies: Theoretical grounding; training stability; backward compatibility with tooling.
- Safety- and policy-guided diffusion generation (healthcare, public sector, safety-critical)
- What: Integrate classifiers/policies/constraints directly into the reverse process to enforce safety, compliance, or style standards.
- Tools/Workflows: Guided diffusion using external scorers; constrained decoding; red-teaming loops.
- Assumptions/Dependencies: Reliable guides; auditable logs; regulatory validation.
- Curriculum and lab infrastructure for scaling-law practice (academia/education)
- What: Courses/labs that teach IsoFLOP studies, cross-family comparisons, and speed–quality evaluation to equip practitioners with compute-optimal training skills.
- Tools/Workflows: Open-source labs; cloud credits; canned datasets and evaluators.
- Assumptions/Dependencies: Access to compute; maintenance of reference code/checkpoints.
- RAG pipelines with decoding-strategy optimization (enterprise software)
- What: Choose diffusion family/steps based on retrieval difficulty, context length, and latency budget; allocate more steps for ambiguous queries.
- Tools/Workflows: Orchestrators that observe retrieval confidence; step schedulers; per-query adaptive inference.
- Assumptions/Dependencies: Reliable retrieval quality signals; latency budgets; UX tolerance for variable response times.
- Auto-tuned sampling schedules and learned step controllers (ML tooling)
- What: Learn mappings from prompt/task features to optimal T and L′, balancing quality and speed over time via online feedback.
- Tools/Workflows: Meta-controllers; online A/B testing; reinforcement learning with bandit feedback.
- Assumptions/Dependencies: Sufficient feedback signals; guardrails to prevent regressions; privacy-aware telemetry.
- Sector-specific productization
- Healthcare: Rapid, constrained draft generation for clinical notes using guided USDM; structured templates with self-correction.
- Education: Math reasoning tutors powered by Duo SFT; step-wise explanation and revision.
- Finance: Fast drafting of earnings summaries and call notes with Eso-LM in KV-cached mode, escalating to AR for final polish.
- Software development: High-throughput code suggestion at low T, followed by AR re-check for critical sections.
- Assumptions/Dependencies: Domain datasets and evaluators; governance frameworks; integration with verification or human-in-the-loop review.
Notes on cross-cutting assumptions and dependencies:
- Results depend on large-data regimes, shared tokenizers, and matched compute budgets.
- Speed–quality conclusions are sensitive to sampling precision (float64 avoids artificial entropy loss during evaluation).
- Pareto dominance regions (Duo vs Eso-LM vs AR) may shift with larger scales, different hardware, or new samplers.
- Block sampler quality depends on block spacing and context divisibility (L′ must divide L).
- Duo’s math gains were observed after SFT on GSM8K-style data; generalization to other domains requires validation.
Collections
Sign up for free to add this paper to one or more collections.