- The paper presents a novel mask-based discrete diffusion method that unifies multimodal processing by modeling joint discrete token distributions.
- It leverages a progressive training pipeline and adaptive decoding strategies to efficiently align and generate text, image, and speech data.
- Empirical evaluations show competitive performance in speech recognition, visual tasks, and cross-modal generation with reduced inference steps.
Omni-Diffusion: Unified Multimodal Understanding and Generation with Masked Discrete Diffusion
Motivation and Context
Multimodal intelligence research has prioritized unified models capable of seamlessly processing and generating data across modalities such as text, images, and speech. Most multimodal LLMs (MLLMs) leverage autoregressive architectures, but recent advances in discrete diffusion models have demonstrated efficacy in multiple domains, especially in generative and understanding tasks. Omni-Diffusion presents the first mask-based discrete diffusion approach for any-to-any multimodal comprehension and generation, directly modeling the joint distribution over discrete multimodal tokens, thus eliminating modality-specific architectures and aligning semantic representations intrinsically.

Figure 1: Overview of Omni-Diffusion, demonstrating unified handling and generation for arbitrary multimodal input/output, including complex modalities integration.
Omni-Diffusion builds upon a pre-trained diffusion LLM backbone, employing modality-specific tokenizers (MAGVIT-v2 for images, SenseVoiceSmall for speech, Dream-7B for text). All modalities are tokenized into sequences, then concatenated with modality start/end delimiters to form a unified token sequence x0∈RL. The mask-based diffusion process replaces a fraction of x0 with [MASK] tokens, and the model is trained via cross-entropy to recover original tokens, providing intrinsic multimodal alignment without modality-specific optimization.
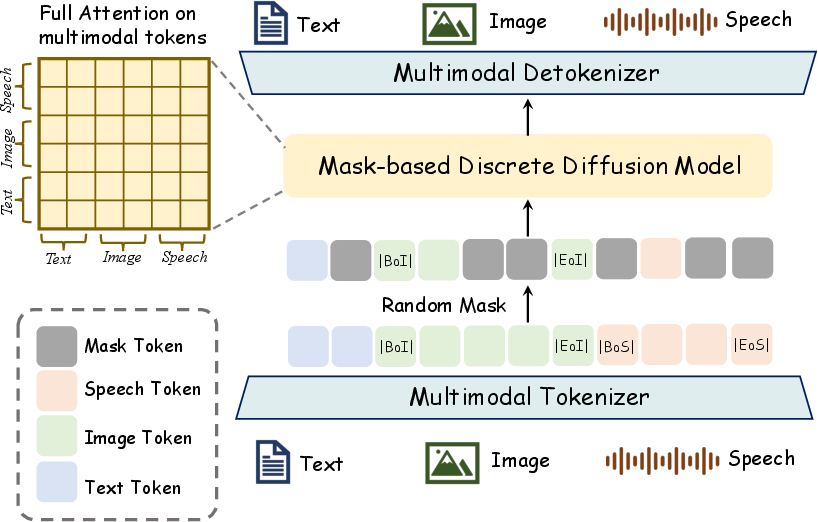
Figure 2: Omni-Diffusion’s architecture, illustrating unified token prediction for text, image, and speech using mask-based diffusion.
Progressive Multimodal Alignment and Training Techniques
Achieving robust alignment across modalities requires progressive expansion of modalities during training. Omni-Diffusion employs a three-stage pipeline:
- Stage 1: Visual-language pre-alignment for text-to-image and image captioning.
- Stage 2: Joint language-speech-visual training using ASR, TTS, and continuance of Stage 1 datasets.
- Stage 3: Fine-tuning on the constructed Speech-Driven Visual Interaction (SDVI) dataset for tasks like speech-driven visual QA and speech-to-image, further enhancing cross-modal fusion.
An attenuated tail-pad masking strategy mitigates pad token overfitting, enabling variable-length generation. The SDVI dataset ensures diverse cross-modal tasks, with careful processing to avoid undesirable speech synthesis scenarios.
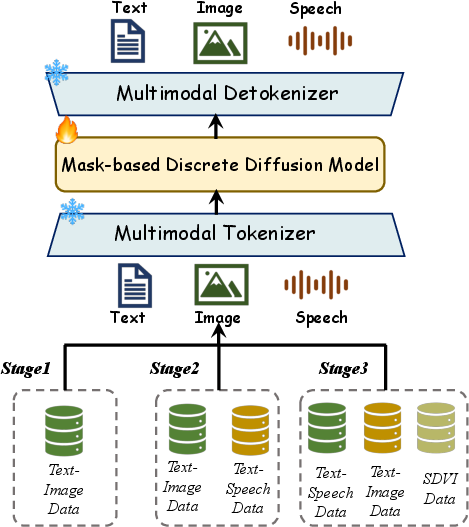
Figure 3: Three-stage progressive training pipeline for multimodal alignment in Omni-Diffusion.
Inference and Decoding Strategies
Omni-Diffusion’s inference leverages entropy-based decoding (sampling based on token confidence via entropy), repetition penalty, classifier-free guidance, and specialized mechanisms:
- Position Penalty: Decodes image tokens preferentially from central positions, suppressing edge repetition.
- Special Token Pre-Infilling: Handles dialogue tasks by guiding segment-wise modality generation.
- Adaptive Token-Length Assignment: Establishes optimal sequence length for speech/text conversion, improving efficiency and quality.
Empirical Evaluation and Numerical Results
Speech Tasks
Omni-Diffusion achieves a Word Error Rate (WER) of 7.05 on LibriSpeech and 3.07 on LibriTTS, surpassing AnyGPT (WER 8.50) and closely approaching specialized CosyVoice (WER 2.89), demonstrating competitive generality and performance in speech recognition and synthesis.
Visual Tasks
On VQA benchmarks (POPE, MME, Seed-2-Plus) and text-to-image generation (MSCOCO), Omni-Diffusion achieves:
- POPE: 76.6, MME-Perception: 1216.7, Seed-2-Plus: 34.5
- CLIP-T: 0.235, CLIP-I: 0.667
These scores reflect strong parity with specialized visual LLMs and diffusion-based generation models, particularly in multimodal settings.
Cross-Modal Generation
Image generation conditioned on speech and text yield similar CLIP scores, confirming robust cross-modal alignment. Generated samples from spoken interactions and image synthesis tasks visually validate semantic consistency and detail quality.

Figure 4: Omni-Diffusion samples for spoken interaction with visual content, showcasing robust multimodal reasoning.

Figure 5: Omni-Diffusion generated samples for text-to-image and speech-to-image tasks, demonstrating cross-modality fidelity.
Inpainting and Parallel Decoding
Without task-specific fine-tuning, Omni-Diffusion performs image inpainting simply by masking the unknown region, producing harmonious completions aligned to text prompts.

Figure 6: Output samples from inpainting, highlighting the model's native mask-based generation capability.
Discrete diffusion models support parallel decoding—Omni-Diffusion maintains strong generation quality (CLIP-T/CLIP-I and WER metrics) even as the number of inference steps is reduced to as low as 10, substantially enhancing sampling efficiency over autoregressive baselines.

Figure 7: Example images generated under varying time steps for the same prompt, illustrating sampling efficiency.
Qualitative Generation and Modality Consistency
Additional qualitative samples demonstrate vivid generation for both text-to-image and speech-to-image scenarios, indicating effective semantic transfer and modality fusion. The model reliably produces consistent outputs given equivalent text or speech prompts.

Figure 8: Text-to-image samples displaying high content alignment and detail.

Figure 9: Speech-conditioned image generation, retaining semantic coherence across modalities.
Theoretical and Practical Implications
Omni-Diffusion’s mask-based discrete diffusion paradigm offers:
- Intrinsic multimodal semantic alignment by jointly modeling discrete token distributions, avoiding external output adapters.
- Efficient token generation via parallel decoding, benefiting latency-constrained and real-time applications.
- Generalization across comprehension and generation tasks, enabling seamless any-to-any input/output modality transfer.
- Task-agnostic inpainting and editing, facilitating flexible downstream multimodal manipulation.
The approach demonstrates that discrete diffusion models can serve as competitive, scalable foundation models for multimodal intelligence, challenging the dominance of autoregressive architectures and providing a path towards universal, modality-agnostic AI systems.
Future Directions
This work suggests several promising avenues:
- Extension to additional modalities (video, structured data, haptics) using generalized tokenization frameworks.
- Algorithmic refinement for adaptive masking and sampling strategies, further reducing inference steps.
- Investigation into large-scale in-context learning and integration with reinforcement learning from human feedback (RLHF) for robustness and controllability.
- Exploration of real-time deployment and streaming scenarios enabled by parallel decoding.
Conclusion
Omni-Diffusion defines a unified framework for multimodal understanding and generation via mask-based discrete diffusion, directly modeling joint distributions over multimodal tokens. Results indicate competitive or superior performance to autoregressive and modality-specialized baselines, efficient parallel decoding, and robust alignment across tasks and modalities. This diffusion-centric approach establishes a solid foundation for future multimodal AI development, both from architectural and practical perspectives (2603.06577).