Residual Context Diffusion Language Models
Abstract: Diffusion LLMs (dLLMs) have emerged as a promising alternative to purely autoregressive LLMs because they can decode multiple tokens in parallel. However, state-of-the-art block-wise dLLMs rely on a "remasking" mechanism that decodes only the most confident tokens and discards the rest, effectively wasting computation. We demonstrate that recycling computation from the discarded tokens is beneficial, as these tokens retain contextual information useful for subsequent decoding iterations. In light of this, we propose Residual Context Diffusion (RCD), a module that converts these discarded token representations into contextual residuals and injects them back for the next denoising step. RCD uses a decoupled two-stage training pipeline to bypass the memory bottlenecks associated with backpropagation. We validate our method on both long CoT reasoning (SDAR) and short CoT instruction following (LLaDA) models. We demonstrate that a standard dLLM can be efficiently converted to the RCD paradigm with merely ~1 billion tokens. RCD consistently improves frontier dLLMs by 5-10 points in accuracy with minimal extra computation overhead across a wide range of benchmarks. Notably, on the most challenging AIME tasks, RCD nearly doubles baseline accuracy and attains up to 4-5x fewer denoising steps at equivalent accuracy levels.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way to make a special kind of LLM—called a diffusion LLM (dLLM)—smarter and faster at writing text and solving problems. dLLMs are good because they can fill in many words at once instead of one-by-one, but they often throw away useful information during generation. The authors propose Residual Context Diffusion (RCD), a method that recycles those “thrown-away” hints and feeds them back into the model to improve the next step. The result: better accuracy, fewer steps, and little extra cost.
Key questions the paper tries to answer
- Can we reuse the information that dLLMs normally discard during generation to improve results?
- How do we turn that leftover information into something the model can actually use without confusing it?
- How can we train this idea efficiently so it works on big models without running out of memory?
- Does this really make dLLMs more accurate and faster on real tasks (like math problems and reasoning)?
How the method works (in everyday language)
Think of writing a paragraph with friends:
- An autoregressive model (AR) writes one word at a time.
- A diffusion LLM tries many words in many spots at once—like making several rough drafts, then steadily polishing them.
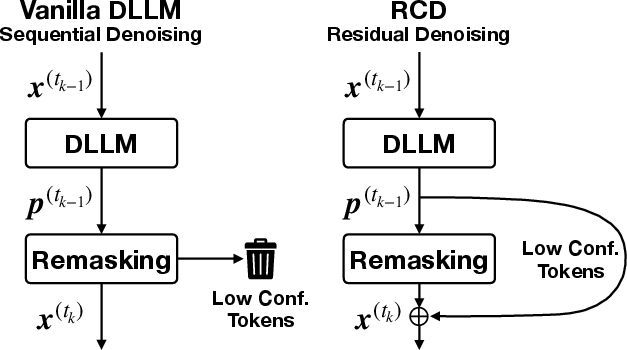
Here’s the problem: in each polishing step, the model keeps only the “most certain” words and remasks (hides) the uncertain ones, even though it already spent time thinking about them. That’s wasted effort, and it throws away helpful context.
RCD’s idea is simple and clever:
- When the model is unsure about a word, it still produces a probability distribution—a ranked list of what that word might be.
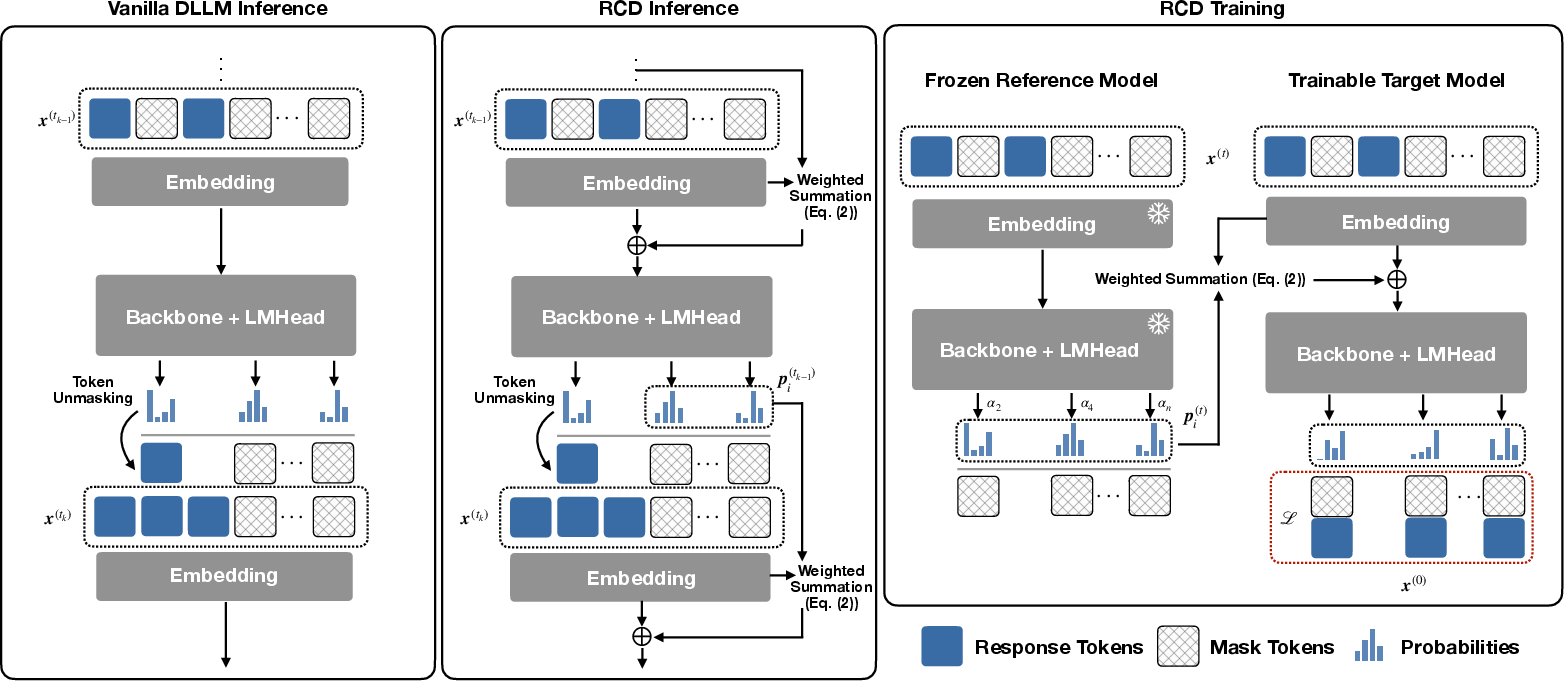
- Instead of tossing that distribution, RCD turns it into a “soft hint” vector using the model’s own embedding dictionary (you can imagine this as blending the word meanings of all the candidates the model considered).
- RCD then injects this soft hint back into the masked positions for the next step. This is like leaving sticky notes on the erased spots saying, “I’m not sure, but it’s probably one of these meanings.”
Two important details make this work:
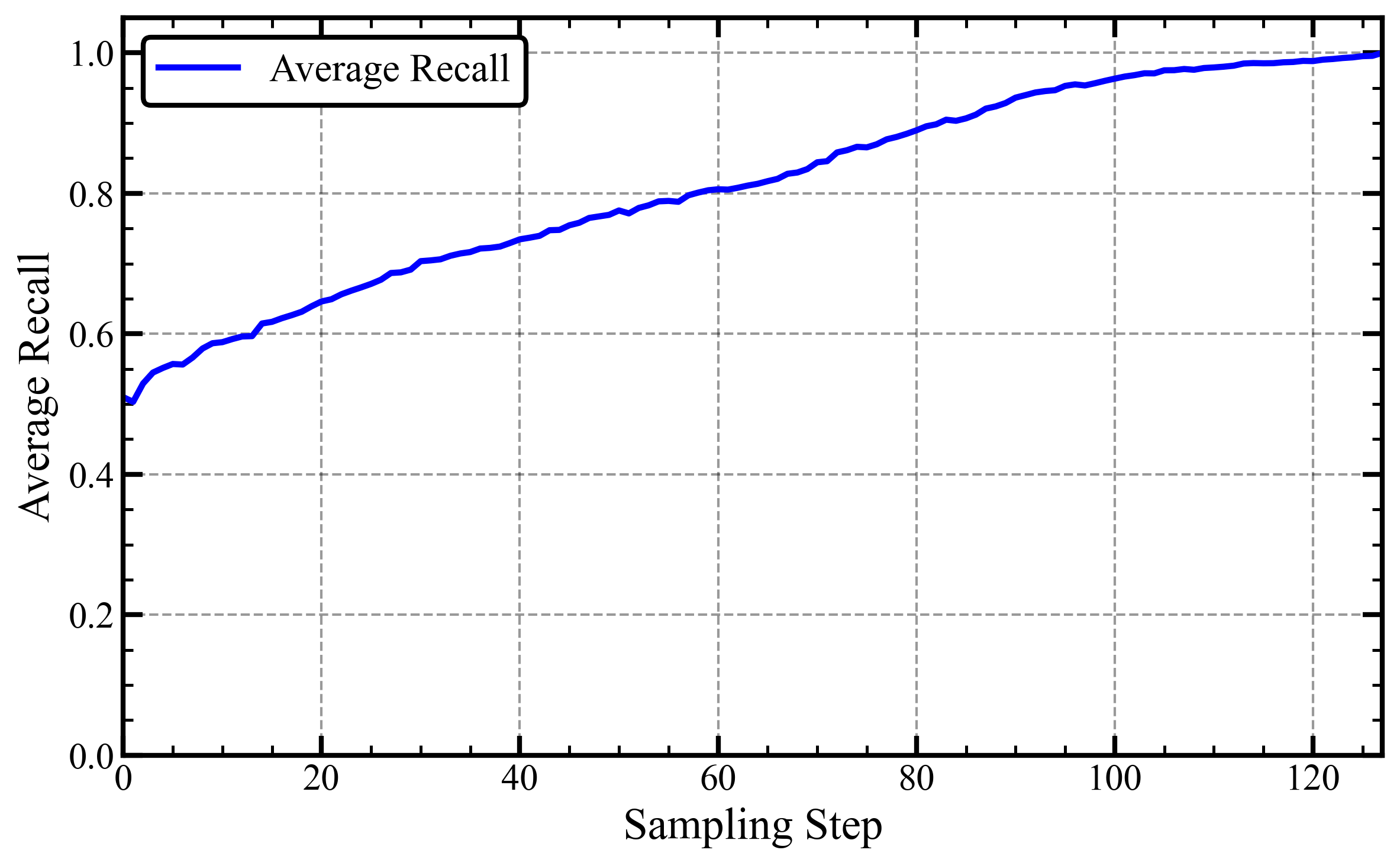
- Entropy weighting: If the model is very unsure (the probabilities are spread out), that uncertainty actually carries a lot of information. RCD measures this “spread” using entropy and gives higher weight to those richer hints. If the model is confident, it adds less.
- Two-stage training: Training this kind of feedback loop directly would be heavy and unstable. So the authors use a “teacher and student” approach:
- A lightweight reference model (the teacher) generates clean, stable hint distributions.
- The target model (the student) learns how to use those hints without backpropagating through long loops. This keeps memory use manageable and training stable.
At inference time (when you actually use the model):
- Warm start: The teacher helps for the first step to kick things off with good hints.
- After that, the student generates its own hints in a loop.
- Temperature tuning: They adjust the “softness” of the student’s probability distributions so the hint strengths match what the student learned during training.
Main findings and why they matter
Across multiple models and benchmarks, RCD consistently improves accuracy with minimal overhead. In plain terms: you get better results faster.
Highlights:
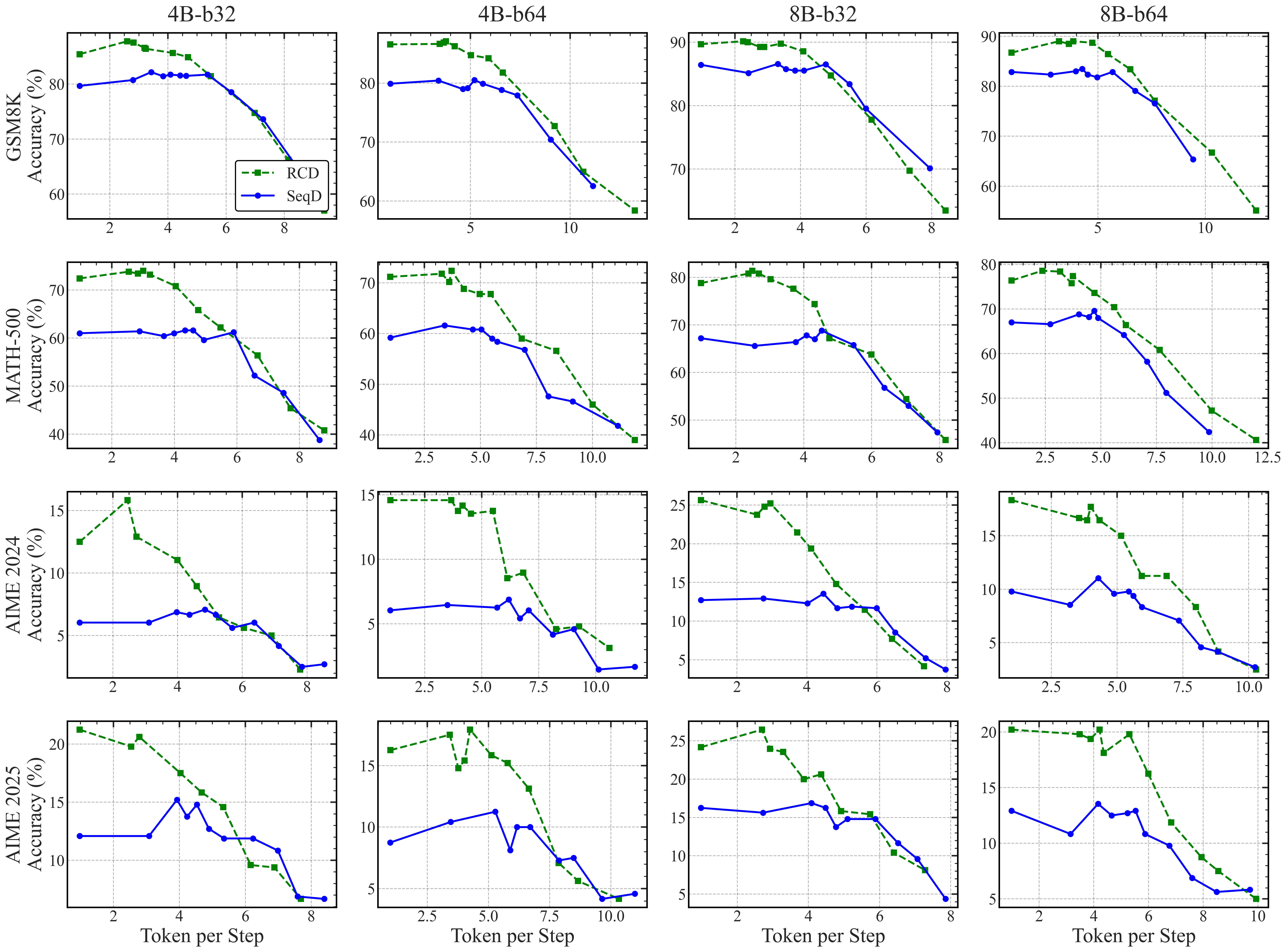
- Accuracy gains of about 5–10 points on well-known math and reasoning benchmarks like GSM8K and MATH500.
- On very tough AIME competition problems, RCD nearly doubles accuracy compared to standard diffusion decoding.
- RCD can reach the same accuracy with 4–5 times fewer denoising steps, meaning it’s much more efficient.
- It works across different model sizes and setups (like SDAR and LLaDA), and keeps throughput (tokens per second) close to the baseline.
- It trains efficiently: with around 1 billion tokens, you can convert a standard dLLM into the RCD style.
- Compared to another method that tries to pass hidden states around, RCD is more stable and data-efficient, because it uses the model’s own embedding “dictionary” rather than raw internal states.
These results matter because diffusion LLMs promise faster generation by decoding in parallel. RCD helps realize that promise by not wasting intermediate computation and by turning uncertainty into useful context.
Implications: Why this could be important
- Faster and smarter models: By reusing what models already compute, RCD boosts accuracy and reduces steps. That can lower costs, save energy, and make parallel decoding more practical.
- Better reasoning: The method especially helps on multi-step math and logic problems, where carrying forward “soft hints” improves the model’s chain of thought.
- Scales to big models: Because RCD uses the model’s own embeddings and a two-stage training plan, it avoids the memory and stability problems common in feedback loops.
- General idea: Recycling intermediate computation may be useful beyond language—any system that iteratively refines guesses could benefit from turning uncertainty into helpful context.
In short, RCD is a neat, practical upgrade that makes diffusion LLMs use their “half-right” thoughts to get more right answers, more quickly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research:
- Theoretical understanding of residual injection: no formal analysis of when entropy-weighted residual blending improves denoising vs. destabilizes it, nor convergence guarantees for the self-referential residual loop.
- Reliability under error propagation: lack of study on failure modes where incorrect residuals amplify downstream mistakes; no safeguards or diagnostics (e.g., gating, trust-region constraints, fallback policies).
- Temperature-scaled entropy calibration: unclear guidance on tuning and scheduling the residual temperature T_res across steps, tasks, and models; no automated calibration or adaptation strategies.
- Learned residual weighting: entropy-based α is fixed; no exploration of learned gating functions (e.g., small MLPs, attention over distributions) that adapt α to context, layer, or task.
- Residual content selection: residuals use full distributions; no ablation of top-k truncation, confidence masking, distribution sharpening/flattening, or class-conditional weighting to reduce noise and compute.
- Injection location and mechanism: residuals are only blended at the input embedding; no exploration of injecting at intermediate layers, via side channels, residual adapters, or attention key/value augmentation.
- Training alternatives to two-stage decoupling: no investigation of memory-efficient end-to-end training (e.g., truncated BPTT, checkpointing, synthetic gradients, low-rank state propagation) to jointly learn residual production and consumption.
- Reference–target mismatch: limited analysis of how teacher quality, size, architecture, or domain affects target performance; no systematic study of optimal teacher–student size ratios or cross-model compatibility.
- Warm start dependency: inference requires teacher invocation for the first step; throughput and latency impact is not quantified, and alternatives (self-warm starts, cached priors) aren’t evaluated.
- Stability vs. block size: while larger blocks appear beneficial, there is no scaling law or systematic characterization of stability/accuracy trade-offs across block sizes and lengths.
- Interaction with remasking policy: residuals are evaluated under top-m selection; no study of alternative selection criteria (e.g., nucleus/top-p, entropy thresholds, adaptive m) and their synergy/conflict with residuals.
- Robustness to distribution shifts: evaluation is concentrated on mathematical reasoning; generalization to diverse domains (instruction following, QA, summarization, code generation, multilingual) remains untested.
- Comparisons to strong AR baselines: no head-to-head against frontier autoregressive systems at matched latency/throughput; the remaining gap to state-of-the-art AR accuracy is not quantified.
- Long-context scalability: SDAR is tested at 16k; no experiments beyond this (e.g., 32k–128k), nor analysis of memory/latency scaling and stability with very long contexts.
- Sensitivity analyses: limited exploration of hyperparameters (confidence thresholds, α mappings, residual magnitude) and their effects across tasks, model scales, and decoding regimes.
- Throughput and compute accounting: “minimal overhead” is asserted but not rigorously profiled; per-step FLOPs, memory footprint, cache behavior, and end-to-end latency (including warm start) are not reported.
- Quantization and deployment: compatibility with INT8/INT4 quantization, speculative/draft decoding, KV-cache reuse regimes, and single-GPU/mobile deployment is not evaluated.
- Safety and privacy: residuals blend distributions at masked positions; potential leakage of sensitive or unintended information, safety impacts, and mitigation strategies are not discussed.
- Calibration and uncertainty: residuals leverage entropy, but broader effects on calibration (e.g., ECE), confidence estimation, and selective generation are not measured.
- Diversity and sampling: evaluation largely uses greedy or Pass@1; effects on sample diversity, Pass@k, or beam search in dLLMs with residuals are unexplored.
- Cross-lingual and tokenization effects: behavior with different tokenizers (BPE, SentencePiece), scripts, and morphologies, and whether embedding-space mixture semantics degrade in multilingual settings, remain unknown.
- Residual norm and scaling: potential norm mismatches between residual vectors and mask embeddings are noted but not systematically analyzed; no normalization/whitening or adaptive scaling strategies are tested.
- Layer tying and embedding alignment: claim that RCD bypasses LM-head/input-embedding decoupling is not backed by quantitative analyses of embedding-space alignment across scales and architectures.
- Alternative residual representations: beyond weighted sums over the codebook, no exploration of learned residual subspaces, low-rank projections, mixture-of-experts residuals, or semantic concept bases.
- Interaction with RLHF and post-training: effects of residuals under preference optimization, RLHF, or instruction-tuning pipelines are not examined.
- Data contamination control: GSM8K contamination is acknowledged, but a clean, controlled evaluation isolating RCD’s gains from contamination effects is missing.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams already operating diffusion LLMs (dLLMs) or evaluating parallel decoding. They leverage the paper’s Residual Context Diffusion (RCD) module, two-stage training pipeline, and entropy-weighted residual injection to recover discarded computation, boost accuracy, and reduce denoising steps.
- Sector: Software/AI Platforms — Upgrade existing dLLM services with RCD for higher accuracy at similar throughput
- What: Drop-in conversion of standard block-wise dLLMs (e.g., SDAR, LLaDA) to RCD using the provided code/models to improve instruction following and complex reasoning tasks.
- Why: Empirically 5–10 point accuracy gains on GSM8K/MATH500 and up to 2× accuracy on AIME24/25 with 4–5× fewer steps at equivalent accuracy.
- Tools/products/workflows: Integrate the RCD residual module; calibrate residual temperature T_res; adopt warm-start inference; use Fast-dLLM or D2F engines for deployment; add an “accuracy–latency Pareto knob” to inference settings.
- Assumptions/dependencies: Availability of a dLLM backbone with masked denoising and block decoding; modest finetuning budget (~0.3–1B tokens); a reference model checkpoint for warm start; GPU inference stacks that support parallel decoding.
- Sector: Education — Math and STEM tutoring with stronger long chain-of-thought (CoT)
- What: Classroom or tutoring assistants for multi-step problem solving (algebra, calculus, olympiad-style questions).
- Why: RCD’s gains on AIME and MATH500 indicate better long-CoT derivation and fewer decoding iterations per solution.
- Tools/products/workflows: Curriculum-aligned prompts; auto-generated step-by-step feedback; adjustable confidence thresholds to trade speed vs. detail.
- Assumptions/dependencies: Proper evaluation against contamination; educational guardrails; training data reflecting curricular domains.
- Sector: Software Engineering — Code suggestion and review using masked diffusion code models
- What: Faster, more reliable multi-token code completions and review comments with parallel decoding.
- Why: RCD aggregates information from undecoded positions, stabilizing masked diffusion code generation.
- Tools/products/workflows: IDE plugins with RCD-inference mode; batched code suggestions across files/functions; entropy-driven “uncertainty-aware” suggestions.
- Assumptions/dependencies: Compatible diffusion code LLMs (e.g., DiffuCoder-like setups); proper calibration to avoid hallucinated APIs; integration with CI tooling.
- Sector: Customer Support/Operations — High-throughput summarization and triage for long tickets/emails
- What: Large-scale summarization and routing workflows exploiting block-wise parallel decoding to meet SLA targets.
- Why: RCD enables higher token-per-step regimes with maintained coherence, reducing latency for long inputs.
- Tools/products/workflows: Batch inference pipelines; throughput-matched accuracy tuning; residual context monitoring.
- Assumptions/dependencies: Access to long-context dLLMs (e.g., SDAR at 16k tokens); domain-specific finetuning for support taxonomies.
- Sector: Finance/Legal — Long-context analysis and reasoning over documents
- What: Contract review, due diligence, and research memos requiring multi-step reasoning on long inputs.
- Why: RCD turns discarded distributions into contextual priors, improving multi-hop reasoning with fewer steps.
- Tools/products/workflows: Document ingestion and segmentation; block-size selection (b32/b64) for KV cache reuse; calibrated confidence thresholds per task.
- Assumptions/dependencies: Domain adaptation; compliance and audit trails; careful validation to avoid subtle reasoning errors.
- Sector: Cloud/HPC/Serving — Efficiency gains in inference infrastructure
- What: Move inference away from memory-bandwidth-limited AR to compute-utilization-optimized dLLM with RCD.
- Why: Parallel decoding with residual recycling improves accuracy–throughput trade-offs; tokens-per-second comparable to baselines.
- Tools/products/workflows: Serving profiles with adjustable block sizes; autoscaling on GPUs (e.g., H100); A/B testing RCD vs. baseline on ParallelBench-like metrics.
- Assumptions/dependencies: Mature dLLM stacks; inference engines supporting block-wise remasking; ops readiness for new decoding policies.
- Sector: Academia/Research — Methodological adoption for reasoning studies and training efficiency
- What: Use entropy-weighted residuals to study high-entropy token roles; adopt decoupled two-stage training to bypass backprop-through-time.
- Why: Data-efficient conversion with ~1B tokens; small-to-large reference-to-target strategy; improved stability vs. hidden-state feedback.
- Tools/products/workflows: Reference-model generation; embedding-codebook alignment; ablation of α strategies; benchmark suites (GSM8K, MinervaMath, AIME).
- Assumptions/dependencies: Availability of pre-trained dLLMs; reproducible training pipelines; consistent evaluation to prevent contamination artifacts.
- Sector: Daily Life — Faster assistants for complex queries and homework help
- What: Personal assistants that respond faster to multi-step queries (calculations, planning).
- Why: Fewer iterations per answer while preserving reasoning quality; adjustable “confidence threshold” for speed vs. thoroughness.
- Tools/products/workflows: Mobile and web assistants with RCD decoding mode; user-controlled accuracy–latency sliders; uncertainty-aware hints.
- Assumptions/dependencies: On-device or cloud inference for diffusion LLMs; safety filters; user interface support for residual-driven explanations.
- Sector: Policy/Sustainability — Immediate energy efficiency improvements in inference fleets
- What: Reduce energy per request by operating at higher token-per-step with accuracy matched to AR baselines.
- Why: Parallel decoding and fewer steps at equivalent accuracy lower compute cycles; better utilization reduces idle/memory stalls.
- Tools/products/workflows: Energy dashboards; carbon accounting tied to decoding settings; procurement preferences for dLLM-capable stacks.
- Assumptions/dependencies: Real-world measurement of energy per token; workload mix with long-CoT tasks; governance for accuracy targets.
Long-Term Applications
The following opportunities need further research, scaling, or engineering to become production-ready. They extend RCD’s residual context mechanism to new modalities, system designs, or sectors.
- Sector: General-Purpose Assistants — AR-to-dLLM migration and platform standardization
- What: Replace AR decoding with RCD-augmented dLLMs for complex tasks across search, chat, and agent orchestration.
- Why: Better accuracy–latency Pareto frontiers; flexible control via confidence thresholds and residual temperature.
- Tools/products/workflows: Platform-wide “RCD mode”; standardized APIs for residual injection; SLA policies keyed to entropy profiles.
- Assumptions/dependencies: Broad availability of strong dLLM backbones; comprehensive evaluation across non-math domains; developer ecosystem buy-in.
- Sector: Robotics/Planning — Residual context for uncertainty-aware plan synthesis
- What: Use entropy-weighted residuals to propagate uncertainty and refine parallel action sequences in task planning.
- Why: High-entropy positions carry structured signals; residual injections can stabilize multi-step parallel plan decoding.
- Tools/products/workflows: Planning agents with masked diffusion rollouts; entropy-calibrated refinement; integration with simulators.
- Assumptions/dependencies: Diffusion-based plan generators; safety certification for embodied systems; robust grounding to sensory inputs.
- Sector: Multimodal AI (Healthcare, Vision, XR) — Extending RCD to perception and mixed embedding spaces
- What: Apply RCD to multimodal diffusion LLMs (e.g., visual reasoning, clinical documentation with images/charts).
- Why: Residual soft tokens built from modality-specific embedding codebooks could recover rich contextual signals across modalities.
- Tools/products/workflows: Perception-token extensions; temperature-aligned residuals per modality; multimodal reference models.
- Assumptions/dependencies: High-quality multimodal dLLMs; careful safety validation in regulated domains; cross-modal calibration and alignment.
- Sector: Hardware/Accelerators — Specialized support for residual computation and parallel denoising
- What: Architect accelerators or kernels optimized for entropy computation, residual soft-token aggregation, and block-wise KV reuse.
- Why: RCD introduces predictable residual operations that can be fused/accelerated to further reduce latency and energy.
- Tools/products/workflows: Compiler passes for residual injection; fused softmax–entropy–embedding ops; hardware counters for Pareto tuning.
- Assumptions/dependencies: Vendor support; sustained adoption of dLLM paradigms; co-design with inference engines.
- Sector: Tooling Ecosystem — RCD plugins and SDKs for inference/training stacks
- What: Standardize residual-context APIs for engines (Fast-dLLM, D2F, vLLM-like systems), plus training SDKs for two-stage pipelines.
- Why: Low-friction adoption with consistent residual temperature calibration, warm start, and α strategies.
- Tools/products/workflows: “Residual Context Adapter” modules; small-to-large reference-target recipe managers; evaluation harnesses (ParallelBench-like).
- Assumptions/dependencies: Cross-engine interoperability; best-practice guides for domain adaptation and residual tuning.
- Sector: Governance/Policy — Benchmarks and guidelines for parallel decoding and energy benefits
- What: Establish accuracy–latency–energy benchmarks and procurement standards for RCD-enabled services.
- Why: Evidence-based oversight for compute utilization and carbon impacts; transparency about accuracy shifts under different token-per-step.
- Tools/products/workflows: Public benchmark suites; reporting templates for accuracy and energy per SLA tier; auditing tools for residual calibration logs.
- Assumptions/dependencies: Community consensus on metrics; reproducibility infrastructure; collaboration with cloud providers.
- Sector: Scientific Discovery — Residual-guided reasoning agents for complex hypothesis generation
- What: Agents that maintain and refine soft hypotheses via entropy-weighted residuals across long CoT scientific workflows.
- Why: Residual context supports exploration of uncertain steps while preserving global coherence.
- Tools/products/workflows: Lab notebooks with uncertainty-aware steps; pipeline managers that tune residual temperature per phase.
- Assumptions/dependencies: Domain-specific finetuning; integration with external tools (symbolic solvers, databases); rigorous validation and error analysis.
- Sector: Consumer Applications — On-device RCD inference for complex tasks
- What: Mobile/edge assistants that deliver faster multi-step responses with limited memory bandwidth.
- Why: Parallel denoising and residual recycling reduce step counts and improve compute utilization on constrained hardware.
- Tools/products/workflows: Lightweight dLLMs tuned with RCD; edge-specific calibration profiles; hybrid cloud–edge fallback.
- Assumptions/dependencies: Efficient small dLLMs; hardware acceleration; privacy and safety constraints.
Cross-cutting assumptions and dependencies
- RCD relies on masked denoising dLLM architectures and access to the target model’s embedding codebook; applicability to purely autoregressive models is non-trivial and would require adaptation.
- A frozen reference model is needed for training and warm-start inference; quality and domain match of this model impact outcomes.
- Residual temperature and confidence thresholds require calibration for each domain to avoid under/over-weighting residuals.
- Gains reported are strongest on reasoning-heavy tasks; performance on other domains (chat, creative writing, multilingual) should be validated prior to mission-critical deployment.
- Operational feasibility depends on engines that support parallel decoding, remasking, and KV cache reuse; throughput and energy benefits may vary with workload mix and hardware.
Glossary
- Autoregressive (AR) models: A class of LLMs that generate tokens strictly left-to-right, one at a time. "Diffusion LLMs (dLLMs) have recently emerged as a promising alternative to purely autoregressive (AR) models"
- Backpropagation-through-time: A training technique that unrolls recurrent or iterative computations over time to compute gradients, often memory-intensive. "making backpropagation-through-time prohibitively expensive under realistic memory budgets."
- Bernoulli mask: A binary masking variable sampled from a Bernoulli distribution, used to decide whether a token is masked at a given step. "Here, is a binary mask"
- Block-wise dLLMs: Diffusion LLMs that decode multiple tokens in blocks per iteration rather than one-by-one. "state-of-the-art block-wise dLLMs rely on a ``remasking'' mechanism"
- Confidence threshold: A cutoff on prediction confidence used to decide which tokens to commit during decoding. "Results are reported at a confidence threshold of 0.85"
- Decoupled two-stage training pipeline: A training approach that separates residual signal generation (via a reference model) from residual utilization (via a target model). "RCD uses a decoupled two-stage training pipeline to bypass the memory bottlenecks associated with backpropagation."
- Denoising step: An iteration in diffusion decoding where the model refines masked tokens toward the final sequence. "Remasking happens during each denoising step"
- Diffusion LLMs (dLLMs): LLMs that generate text via iterative denoising within a masked space, enabling parallel token updates. "Diffusion LLMs (dLLMs) have emerged as a promising alternative to purely autoregressive LLMs"
- Embedding codebook: The matrix of token embedding vectors used to convert discrete token distributions into continuous representations. "RCD instead constructs residual context based on the model's own embedding codebooks"
- Entropy-Based Embedding Aggregation: A method that weights residual context by predictive entropy to extract reliable signals. "Entropy-Based Embedding Aggregation: For context selection and aggregation, prior approaches often reuse hidden states"
- KV-cache reuse: Reusing transformer key-value caches across diffusion steps to improve inference efficiency. "and supports KV-cache reuse."
- Logits: Pre-softmax scores output by the model representing unnormalized token likelihoods. "where are the output logits."
- Masked latent space: A continuous representation where tokens are initially masked and progressively denoised. "Diffusion-based LLMs treat text generation as a progressive denoising process within a masked latent space."
- Normalized Shannon entropy: Shannon entropy scaled to lie in [0, 1], used to modulate residual injection. "it introduces entropy-based aggregation, i.e., using normalized Shannon entropy with temperature-adjusted alignment"
- Pareto frontier: The set of optimal trade-offs between accuracy and computational cost (e.g., steps), where improving one metric worsens the other. "RCD consistently achieves a superior Pareto frontier"
- Pareto knob: A tunable control that trades off denoising steps against residual transmission to navigate accuracy–latency trade-offs. "A new Pareto knob:"
- Pass@1: An evaluation metric reporting the probability that the top single sampled answer is correct. "For AIME24/25, we use with 16-sample Pass@1 to ensure statistical robustness."
- Remasking: The inference strategy that resets low-confidence positions back to the mask token between iterations. "rely on a ``remasking'' mechanism that decodes only the most confident tokens and discards the rest"
- Residual Context Diffusion (RCD): A framework that recycles discarded token computations as residual context to improve diffusion decoding. "we propose Residual Context Diffusion (RCD)"
- Residual denoising mechanism: The process of injecting residual contextual vectors into masked positions to refine predictions across steps. "Overview of the residual denoising mechanism in Residual Context Diffusion (RCD)."
- Semi-autoregressive: A generation paradigm that combines block-wise parallel decoding with some autoregressive structure. "the SDAR family, a semi-autoregressive model family that decodes sequences in blocks"
- Shannon entropy: A measure of uncertainty in a probability distribution, used to weight residual contributions. "Here, is the standard Shannon entropy of predicted token"
- Soft tokens: Continuous embedding vectors formed by weighted sums of vocabulary embeddings, representing a mixture of discrete tokens. "Soft tokens are similar to the model's input embedding vectors that can represent a mixture state of multiple tokens."
- Temperature-Scaled Entropy Alignment: A calibration method that adjusts distribution sharpness via a temperature to align inference-time residual weights with training. "Temperature-Scaled Entropy Alignment."
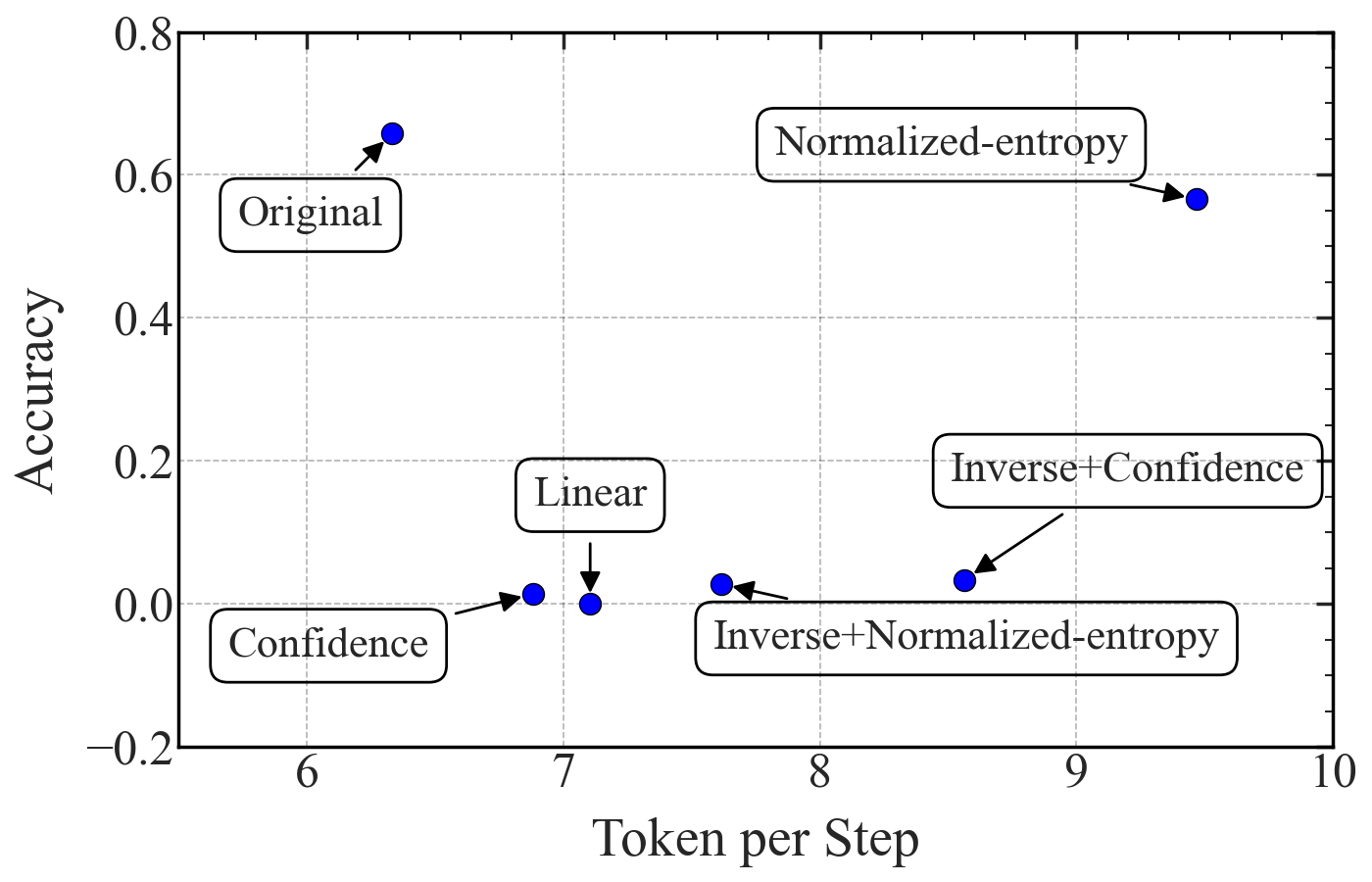
- Token per Step: The average number of tokens committed per diffusion iteration; a proxy for decoding parallelism. "Token per Step serves as a direct proxy for generation parallelism."
- Tokens per Second (TPSec): A throughput metric measuring how many tokens are generated per second during inference. "By aligning the throughput (Token per Second) of RCD and Sequential Denoising baselines"
- Top-m selection: Choosing the m most confident token positions to commit at each iteration. "The model selects the top- positions with the highest confidence to be ``committed'' or fixed."
- Warm Start: Initializing the residual stream during inference using a reference model to provide a strong starting context. "We address these through a ``Warm Start'' strategy"
Collections
Sign up for free to add this paper to one or more collections.