- The paper introduces soft-masking, which blends MASK token embeddings with top-k predictions to retain valuable context during iterative decoding.
- The method achieves lower perplexity and improved MAUVE scores on benchmarks like HumanEval and MBPP, demonstrating its efficacy in coding tasks.
- Empirical results on models such as Dream-7B show that soft-masking enhances both speed and accuracy with minimal modifications to existing MDLM architectures.
Soft-Masked Diffusion LLMs
Introduction
The paper "Soft-Masked Diffusion LLMs" introduces an innovative method to enhance masked diffusion LLMs (MDLMs) by implementing a technique known as soft-masking (SM). Diffusion models have demonstrated promising potential in language modeling due to their advantages in generating responses efficiently. Unlike traditional autoregressive (AR) models that rely on sequential token predictions, MDLMs benefit from bidirectional modeling and accelerated sampling capabilities. However, existing diffusion models make binary decisions when decoding masked tokens, often retaining or completely replacing them, thereby discarding valuable predictive information. The proposed SM technique addresses this limitation by incorporating a continuous feedback mechanism that retains contextual information across decoding steps.
Soft-Masking Mechanism
The soft-masking approach represents a novel integration into the MDLM framework. The central concept involves blending the embedding of the MASK token with the embeddings of the top-k predicted tokens from previous decoding steps. By doing so, the model is provided with a richer informational prior that propagates context beyond a single decoding step.
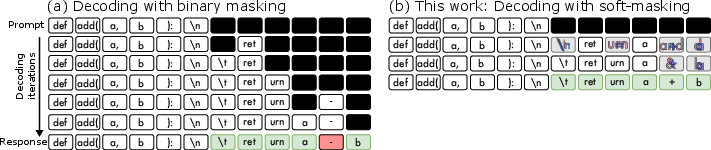
Figure 1: Illustrative answer generation using masked diffusion LLMs (MDLMs) via iterative decoding with (a) standard binary masking or (b) our proposed soft-masking. Our soft-masking enriches the feedback for the next decoding step by superposing the masked tokens with the previously predicted top-k candidates, enabling more accurate and faster generation.
Implementation and Training
Implementing soft-masking within MDLMs involves minimal adaptation of existing architectures, primarily integrating three additional parameters that are learned alongside the model's other parameters. The training methodology adapts a pretrained MDLM to incorporate SM, allowing it to leverage the enriched feedback during iterative decoding.
The primary advance of SM is its ability to dynamically blend the mask token's embedding with previous step predictions, thus preserving valuable contextual clues that enhance the model’s generative capabilities. SM's introduction aims at reducing perplexity scores and improving MAUVE scores, both indicators of output quality and diversity.
Empirical Results
Extensive experimentation reveals the advantages of soft-masking across both small and large-scale models, including Dream-7B and Dream-Coder-7B, particularly on downstream coding tasks. The results consistently demonstrate that SM outperforms traditional binary masking, showing improvements in coding benchmarks such as HumanEval and MBPP. These gains are particularly pronounced in high-throughput settings with limited decoding iterations.
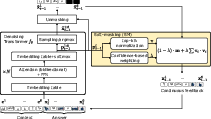
Figure 2: Iterative denoising in MDLMs using the proposed soft-masking (SM). Given a context, the aim is to predict the answer via iterative denoising of an initially fully masked response. Here, a bidirectional Transformer (f_\theta) performs a single denoising step. This output is passed through an unmasking function that, based on the Transformer's token probabilities, determines which tokens remain masked.
Computational Efficiency and Scaling
Despite the benefits of soft-masking, one computational trade-off is the additional forward pass required during training, which increases the computational complexity. However, SM integrates seamlessly with existing MDLM efficiency enhancements, such as dynamic unmasking strategies, caching, and confidence-aware blockwise decoding. These integrations further improve text generation quality while leveraging SM’s continuous feedback.
Conclusion
Soft-masking enhances masked diffusion models by providing a richer feedback mechanism that utilizes continuous information from previous decoding steps, thereby maintaining context. The paper illustrates how SM can be effectively integrated into existing diffusion models, leading to performance improvements in language generation and code synthesis tasks. Future research directions may focus on exploring reinforcement learning-based methods to further capitalize on continuous feedback mechanisms, aiming to reduce computational overhead while leveraging the enriched context provided by SM.
Implications and Future Directions
The implications of adopting soft-masking are significant for advancing model efficiency and quality in limited-resource settings. Future research could explore integrating machine learning techniques like reinforcement learning to optimize the soft-masking process, potentially allowing for even more efficient training architectures that use continuous feedback systems.