- The paper demonstrates that shifting compute from generation to verification significantly increases deep search agent accuracy.
- It outlines sequential and parallel scaling strategies, including Budget Forcing and verifier-based aggregation to optimize performance.
- The study shows that Heavy variants of open-source models can rival commercial systems on challenging benchmarks.
Test-Time Scaling of Deep Search Agents via Asymmetric Verification
Introduction
This paper presents a comprehensive study of test-time scaling (TTS) for deep search agents, focusing on the interplay between sequential and parallel scaling strategies and the exploitation of asymmetric verification. The authors systematically analyze how scaling compute at inference—either by lengthening agentic trajectories (sequential scaling) or by generating and verifying multiple candidate solutions in parallel (parallel scaling)—can be optimized for complex information-seeking tasks. The central insight is that, for many deep search problems, verification is substantially less computationally demanding than generation, enabling more efficient scaling by shifting compute from search to verification.
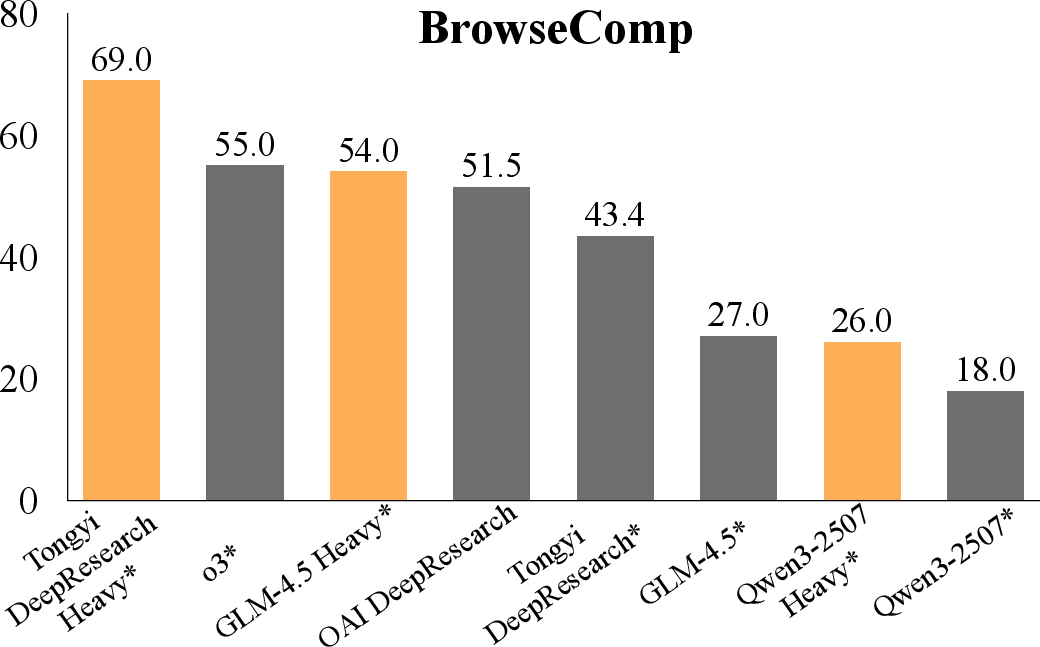
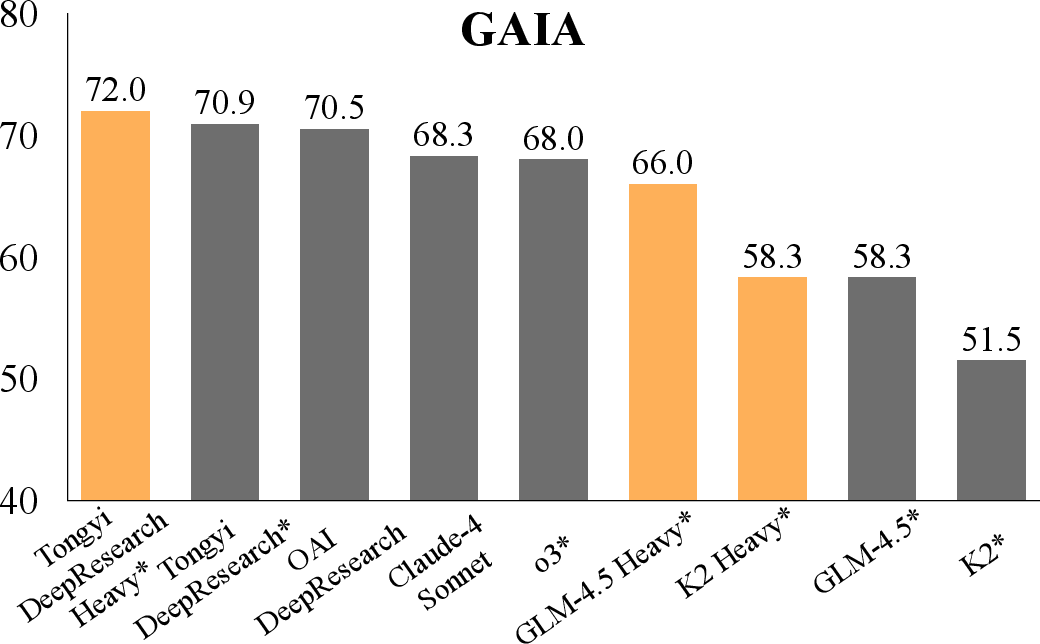
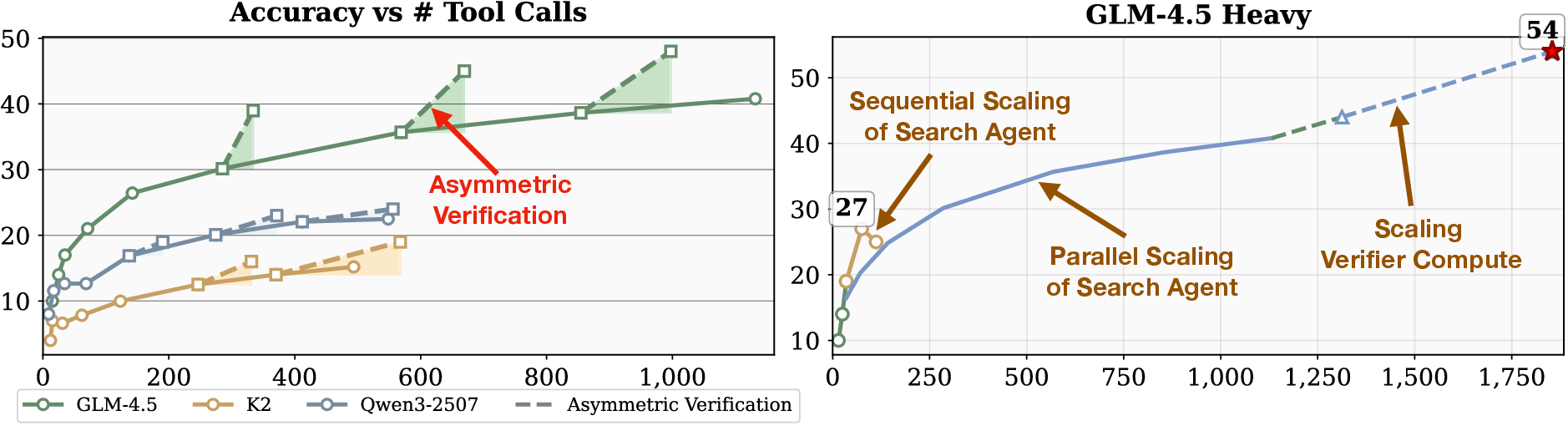
Figure 1: Top: Accuracy of various models on BrowseComp and GAIA, including improvements from test-time scaling. Bottom left: Accuracy on BrowseComp as a function of tool calls, contrasting search agent scaling (solid) and verifier allocation (dashed). Bottom right: Strategies for extending GLM-4.5 to its Heavy variant on BrowseComp.
Deep Search Agent Framework and Scaling Strategies
The agentic framework is based on ReAct, where the search agent iteratively reasons, executes actions (either generating answers or invoking search tools), and processes observations from the web. The search tool integrates web search and browsing, with an auxiliary model (K2) responsible for content extraction and query refinement. The study employs challenging benchmarks (BrowseComp, BrowseComp-zh, GAIA, xbench-DeepSearch) and open-source models (GLM-4.5, K2, Qwen3-2507, Tongyi-DeepResearch).
Sequential Scaling
Sequential scaling is implemented via two methods:
Budget Forcing substantially increases tool usage and Pass@1 accuracy (e.g., GLM-4.5 improves from 19% to 27%, Qwen3-2507 from 8% to 18%). However, performance saturates and may degrade with excessive trajectory length, indicating limitations in long-range reasoning coherence.
Parallel Scaling
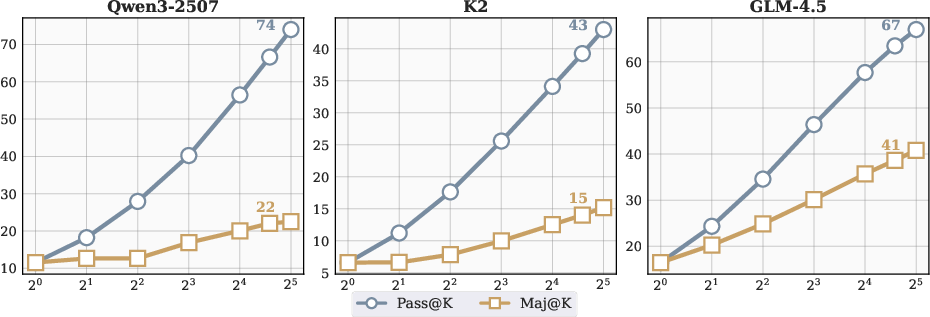
Parallel scaling generates multiple independent solution trajectories and aggregates outputs via:
Parallel scaling rapidly increases Pass@K accuracy (GLM-4.5: 16% to 67% for K=1 to 32), but Maj@K lags, revealing a gap between exploration and exploitation. This motivates the introduction of external verification to improve candidate selection.
Asymmetric Verification and Verifier Scaling
The paper formalizes the concept of asymmetric verification: for many tasks, verifying a candidate solution is much less costly than generating it. In deep search, forward search requires extensive exploration, while verification only needs to check well-defined conditions, often via simple web queries.
The verifier agent shares the same architecture as the search agent but is prompted to evaluate candidate answers and assign confidence scores. Verification is scaled both sequentially (budget forcing) and in parallel (multiple verification trajectories per candidate).
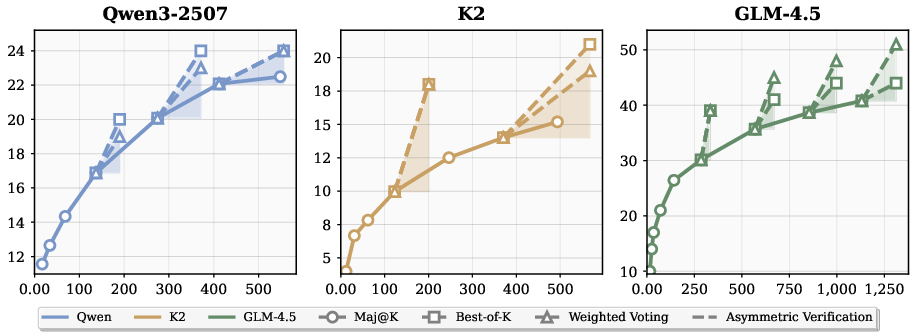
Figure 4: Parallel scaling results on BrowseComp, showing Maj@K growth for search agent scaling (solid) and Best-of-K/Weighted Voting after verifier introduction (dashed).
Verifier-based aggregation yields superior accuracy-cost trade-offs. For GLM-4.5, increasing search compute from Maj@8 (35.7%) to Maj@32 (40.8%) requires ~560 additional tool calls, while adding a verifier boosts accuracy to 45% with only ~100 extra calls. Similar patterns are observed for K2 and Qwen3-2507.
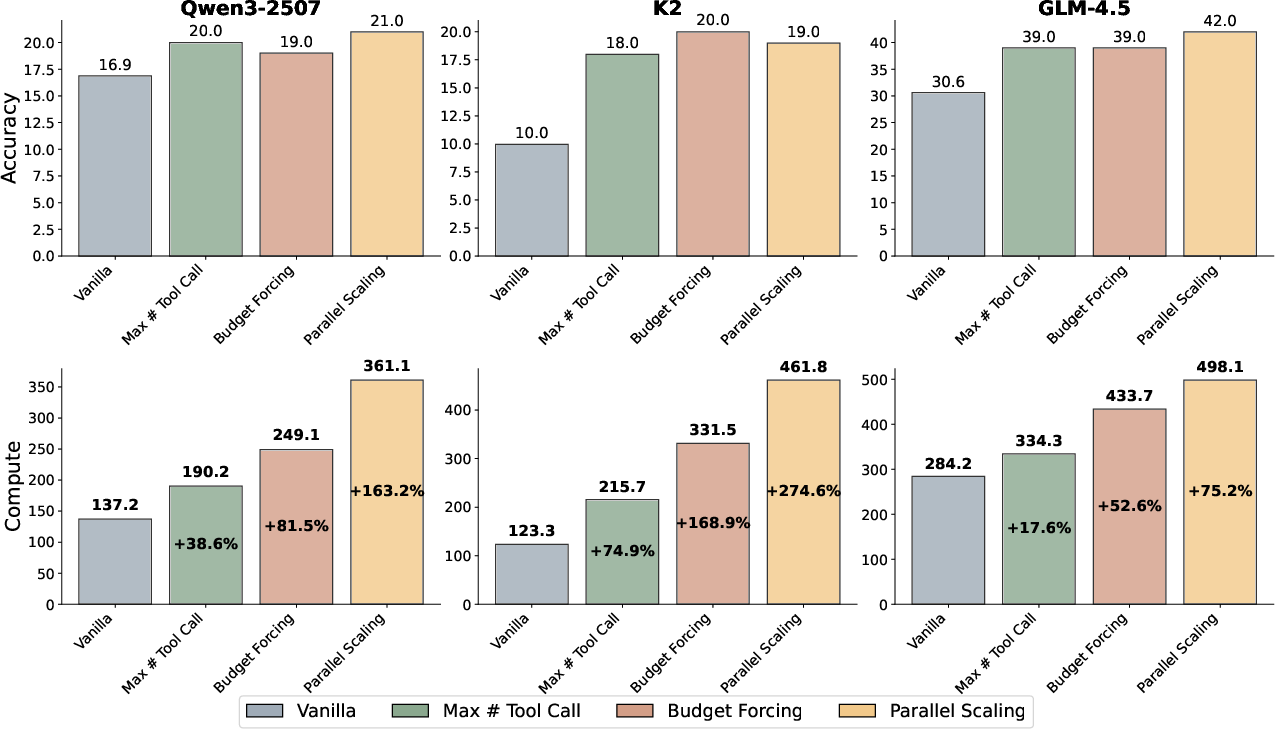
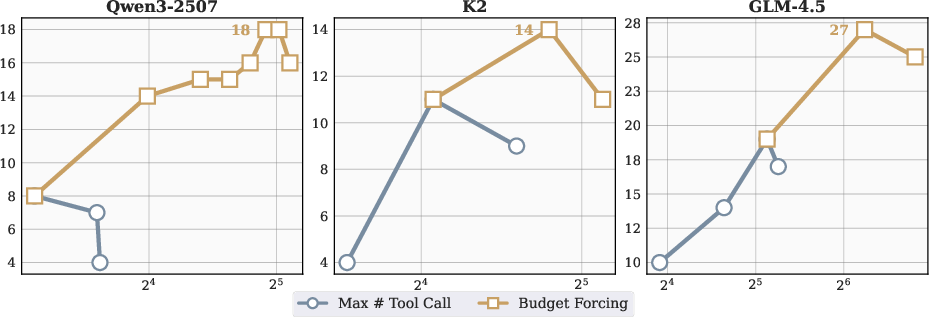
Figure 5: Comparison of strategies for scaling verifier computation across models, showing accuracy and corresponding tool calls for vanilla, Max # Tool Call, Budget Forcing, and Parallel Scaling.
Scaling verifier compute further raises performance ceilings, with gains dependent on model and strategy. For K2, budget forcing increases accuracy from 10% to 20%. For GLM-4.5, parallel scaling with Best-of-8 achieves 42% accuracy.
Heavy Variants and Benchmark Results
By combining sequential and parallel scaling for both search and verifier agents, the authors construct "Heavy" variants of open-source models. These variants achieve performance comparable to leading commercial systems across multiple benchmarks.
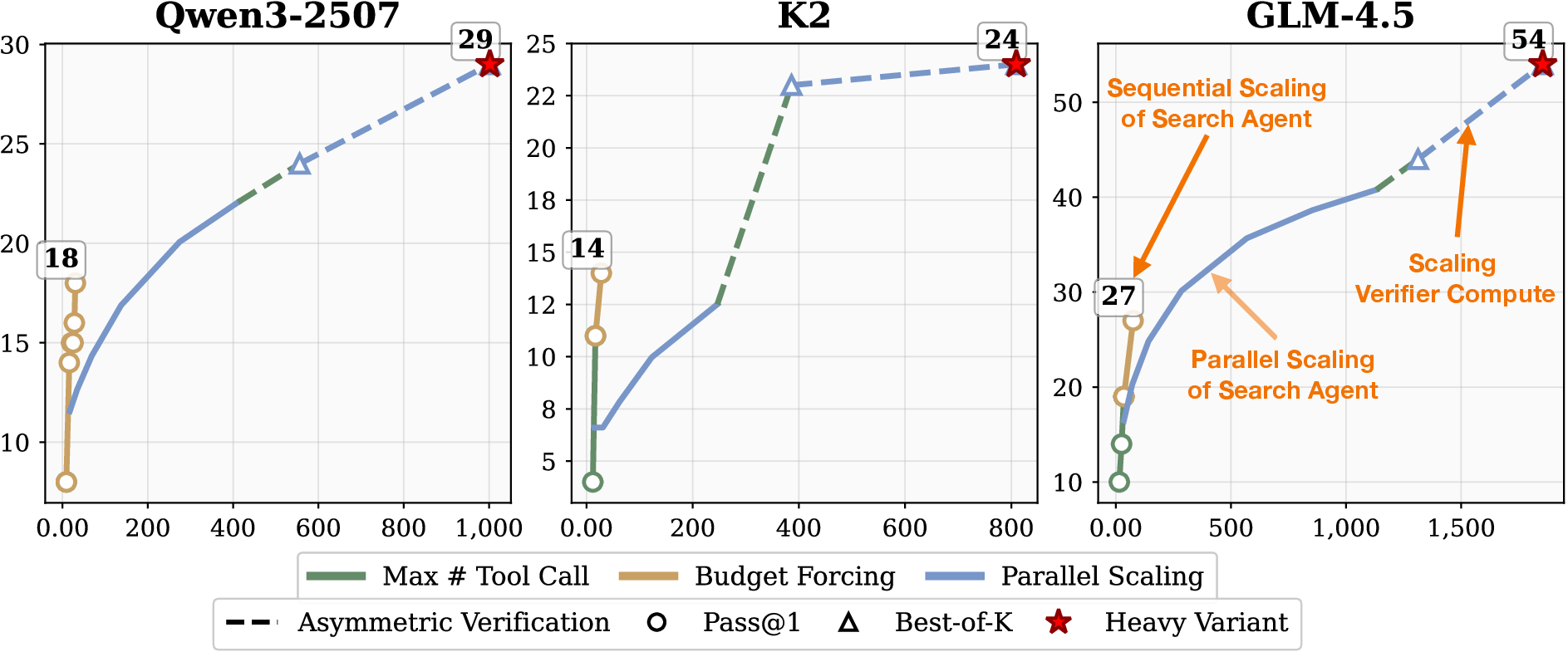
Figure 6: Scaling test-time compute for different models on BrowseComp, showing accuracy as a function of tool calls.
GLM-4.5 Heavy attains 54.0% accuracy on BrowseComp, 49.0% on BrowseComp-zh, 66.0% on GAIA, and 68.0% on xbench-DeepSearch. Tongyi-DeepResearch Heavy reaches 69% on BrowseComp. The introduction of verifiers accelerates performance gains, with parallel scaling of the verifier yielding consistent improvements.
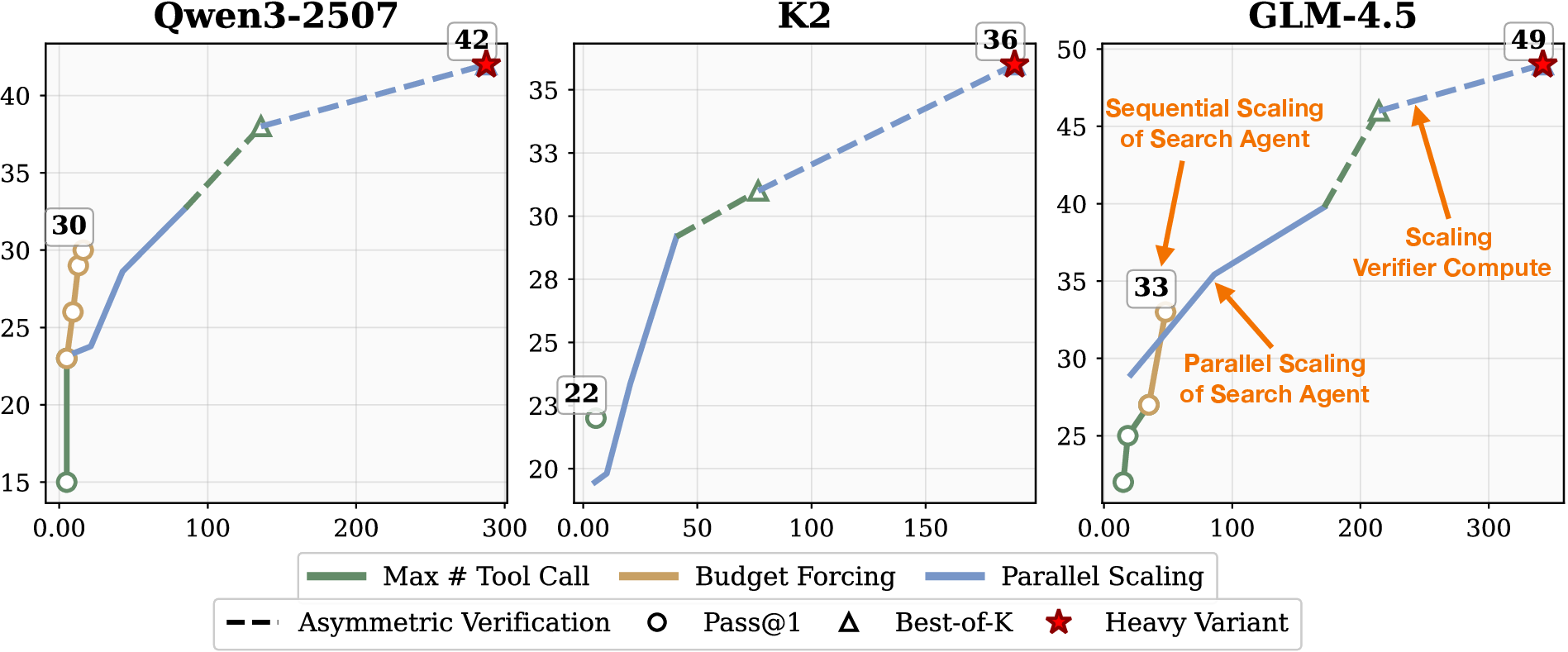
Figure 7: Scaling test-time compute for different models on BrowseComp-zh, showing accuracy as a function of tool calls.
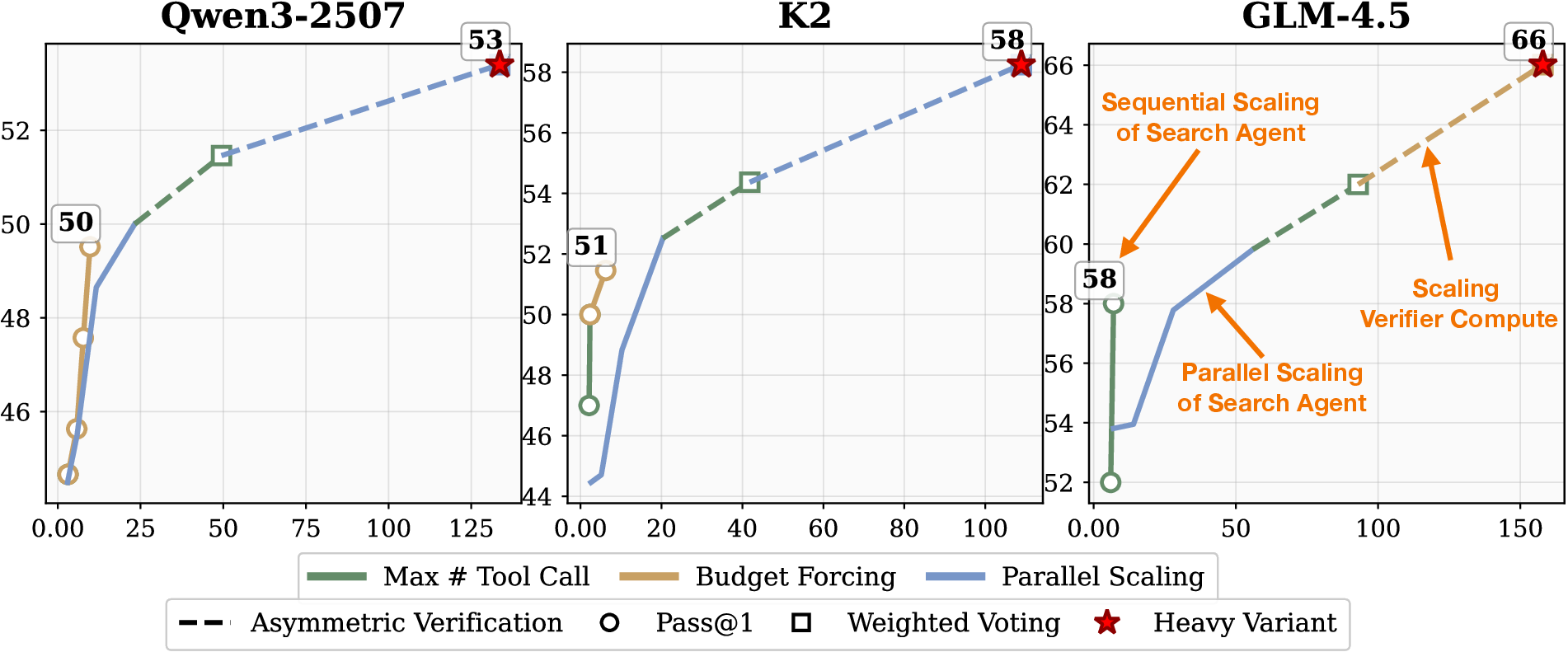
Figure 8: Scaling test-time compute for different models on GAIA, showing accuracy as a function of tool calls.
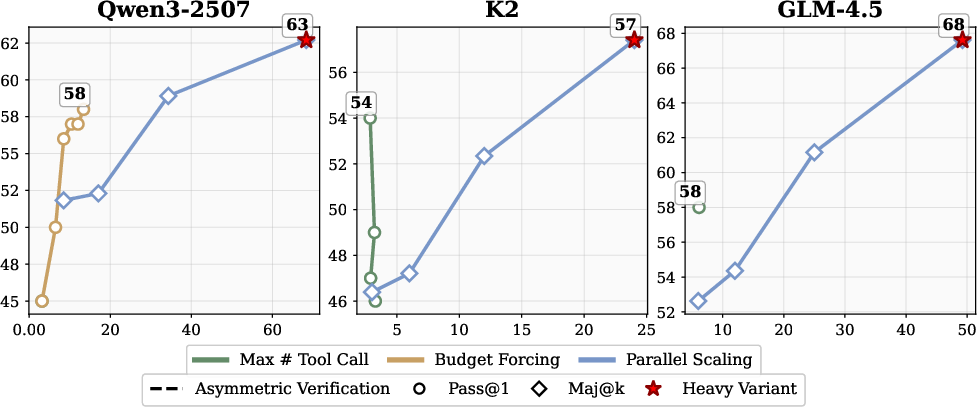
Figure 9: Scaling test-time compute for different models on xbench-DeepSearch, showing accuracy as a function of tool calls.
On xbench-DeepSearch, where search and verification are equally difficult, verifier scaling offers minimal improvement, highlighting the importance of task-specific asymmetry.
Implementation Considerations
The study demonstrates that compute allocation should be guided by the asymmetry between search and verification. For tasks with strong verification asymmetry, shifting compute to verifiers yields higher accuracy per unit cost. The choice of scaling strategy (sequential vs. parallel), scaling target (search vs. verifier), and aggregation metric (Pass@K, Maj@K, Best-of-K, Weighted Voting) should be tailored to model characteristics and compute budgets.
The agentic framework is modular, enabling straightforward adaptation of scaling strategies. System prompts for both search and verifier agents are critical for controlling tool usage and agent behavior. Budget Forcing and parallel sampling can be implemented via prompt engineering and batch inference, respectively.
Implications and Future Directions
The findings have significant implications for the design of agentic search systems. Efficient test-time scaling via asymmetric verification enables open-source models to match or exceed commercial systems on complex benchmarks. The results suggest that future systems should integrate verification more deeply, potentially applying verifiers at each search step or using them to guide search trajectories.
Further research may explore training agents to internalize verification capabilities, enabling end-to-end reasoning and verification during inference. The paradigm of compute-optimal scaling—allocating resources based on task-specific asymmetry—can be generalized to other domains beyond deep search.
Conclusion
This paper provides a rigorous analysis of test-time scaling for deep search agents, demonstrating that leveraging asymmetric verification enables substantial performance gains with modest compute increases. By systematically combining sequential and parallel scaling for both search and verifier agents, open-source models can be transformed into Heavy variants that rival commercial systems on challenging information-seeking tasks. The study establishes a framework for compute-optimal scaling and highlights the importance of verification asymmetry in agentic system design, paving the way for more efficient and powerful AI agents.