- The paper introduces OccuBench, a benchmark using Language World Models to evaluate AI agents on 100 real-world professional tasks.
- The methodology employs multi-turn simulations with domain-specific tool schemas and fault injections to measure task completion and environmental robustness.
- Results reveal cross-industry performance variations, emphasizing the need for domain-aligned agent selection and resilient error recovery.
Authoritative Essay on "OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models"
Introduction and Motivation
"OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models" (2604.10866) addresses a fundamental bottleneck in the evaluation of AI agents: the lack of coverage for high-value professional domains where no public environment, API, or real-world infrastructure is available. The paper introduces OccuBench—a benchmark comprising 100 real-world professional task scenarios spanning 10 industry categories and 65 specialized domains—enabled by Language World Models (LWMs). LWMs, instantiated through LLMs, serve as environment simulators that generate domain-specific tool responses and facilitate multi-turn agent evaluation beyond the reach of existing benchmarks.
The approach pivots evaluation from "environments with APIs" to "any domain the LLM can understand," drastically expanding coverage and enabling systematic assessment of agents in practical occupational roles from healthcare triage and nuclear safety monitoring to logistics and customs processing.
Benchmark Design and Methodology
OccuBench leverages LWMs, defined as LLMs configured with a system prompt encoding domain logic, a tool schema specifying callable functions, an initial state, and semantic state descriptions. This combination transforms the LLM into a stateful, interactive environment capable of simulating operational workflows and error feedback at the tool-response level.
Each evaluation instance is generated via a multi-agent synthesis pipeline: domain reference documents are constructed for diversity, task instructions are synthesized for solvability and discriminative difficulty, tool schemas emulate realistic operational interfaces (typically 5–6 tools per task), and solution plans are grounded for automated rubric-based verification. Fault injection is supported at evaluation time via prompt modifications, enabling controlled simulation of explicit errors (timeouts, HTTP 500), implicit degradation (truncated data, missing fields), and mixed faults. This yields two orthogonal evaluation dimensions: task completion and environmental robustness.
OccuBench's coverage enables unprecedented cross-industry profiling of agent capabilities. Evaluation of 15 frontier models across eight families reveals that no single model dominates across all industries—a stark contrast to conventional benchmarks restricted to narrow domains.
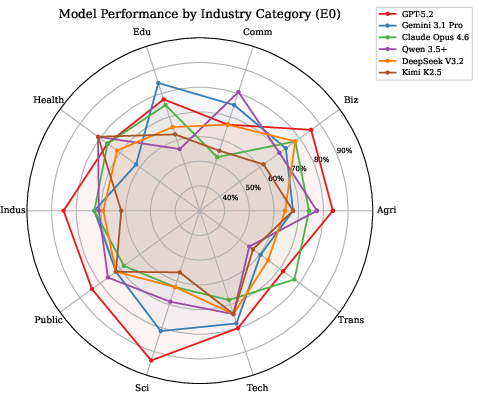
Figure 1: Radar chart visualizes cross-industry capability profiles for leading models, evidencing occupational specialization and unique strengths/weaknesses.
GPT-5.2 exhibits highest completion rates in Agriculture, Business, Science, and Industrial categories (average 79.6%), yet underperforms in Commerce relative to Qwen 3.5 Plus. Gemini 3.1 Pro excels in Education (84%) and Science (81%) but struggles in Healthcare. Qwen 3.5 Plus leads Commerce and Healthcare (both 81%) yet trails in Education. Open-source models (Qwen 3.5 Plus, DeepSeek V3.2) are highly competitive, sometimes outperforming closed-source alternatives.
OccuBench's cross-industry diagnostics provide actionable insights for domain-aligned agent selection and highlight the limitations of general aggregate metrics.
Environmental Robustness and Fault Injection
The evaluation under environmental faults reveals severe limitations in agent resilience to real-world noise. Explicit error injection (E1) prompts retry behaviors and moderate performance drop; implicit faults (E2), which lack overt signals, cause substantially larger declines as most agents fail to independently detect data degradation. The robustness metric, defined as the minimum completion rate across all faulted environments normalized to clean performance, ranges as low as 0.63 (Kimi K2.5) and only reach 0.87 for the strongest agents.
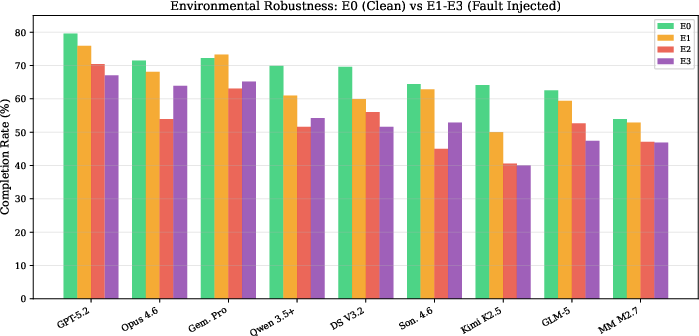
Figure 2: Completion rates under clean and fault-injected environments, highlighting sensitivity to implicit and mixed environmental noise.
Fault ablation analyses confirm that increased fault count and duration further exacerbate performance degradation. The results underscore the necessity for robust error-detection and recovery mechanisms in agent design for deployment in noisy enterprise environments.
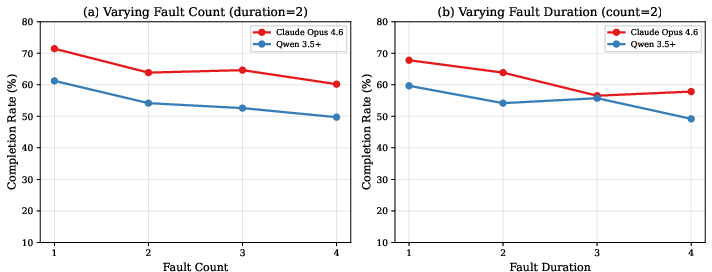
Figure 3: Fault parameter ablation demonstrates deepening performance decline with rising fault severity (count/duration) under mixed faults.
Scaling, Generational Progress, and Reasoning Effort
OccuBench enables systematic scaling analysis: larger variants universally outperform smaller siblings (gaps up to 11%), newer generations show consistent improvement, and increased inference-time reasoning effort substantially boosts task completion rates.
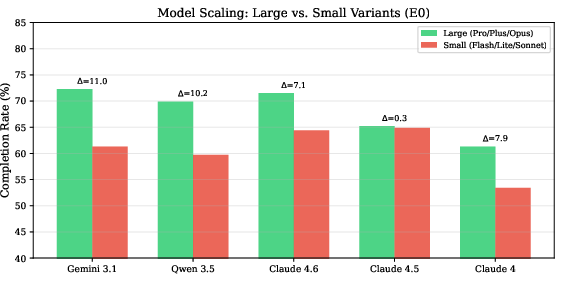
Figure 4: Scaling effect—large models outperform small variants across all families, demonstrating direct correlation between scale and occupational task efficacy.
Claude Opus consistently improves across three generations (+10.2% from v4 to v4.6). Models supporting configurable reasoning depth (e.g., GPT-5.2) benefit markedly from higher effort levels (a 27.5-point gain from minimal to maximal reasoning effort).
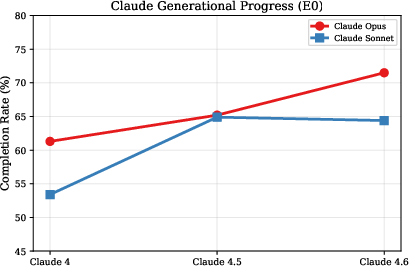
Figure 5: Generational improvements in the Claude family; Opus shows monotonic growth, Sonnet slight regression post-v4.5.
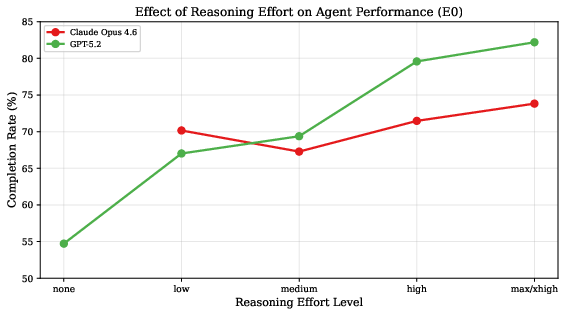
Figure 6: Higher reasoning effort translates to monotonic agent performance improvements, with distinct trends for GPT-5.2 and Claude Opus 4.6.
Simulator Quality and Evaluation Reliability
Cross-simulator evaluations reveal that strong agents may not serve as high-fidelity environment simulators. GPT-5.2, though ranking first as an agent, produces the lowest simulation quality. Simulator-induced artifacts—fabricated state, omitted entities, spurious rule enforcement—result in invalid agent trajectories and false failures, violating the environment contract and undermining evaluation reliability.
Pairwise ranking agreement between capable simulators (e.g., Qwen 3.5 Plus vs. Gemini-3-Flash-Preview) reaches 85.7%, confirming that with a sufficiently capable LWM, agent rankings are stable and reproducible.
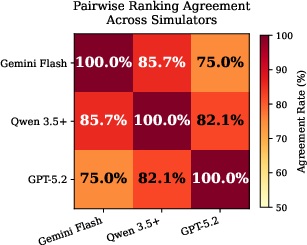
Figure 7: Pairwise ranking agreement across simulators quantifies relative ordering preservation; high agreement between capable simulators validates OccuBench's ranking reliability.
Simulator quality must be verified; otherwise, evaluators must re-validate task solvability when switching underlying LWMs.
Industry-Level Difficulty and Case Study Analysis
Industry difficulty analysis corroborates alignment between domain complexity and agent performance. Business and Public Service tasks yield higher completion rates due to procedural regularity, while Transportation and Education pose greater obstacles (average scores <60%) owing to multi-constraint optimization and nuanced reasoning demands.
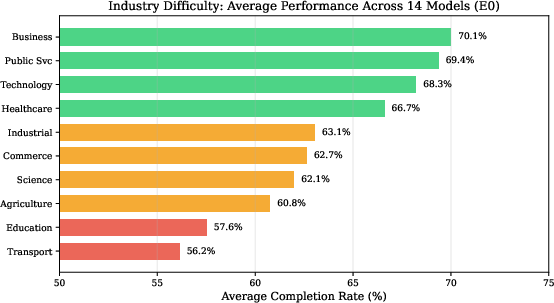
Figure 8: Average completion rate by industry category—Transportation and Education are the most challenging for agents.
Case studies in Logistics, Agriculture, Industrial, and Business domains highlight differentiators in reasoning, verification, and procedural ordering. Agents that proactively monitor constraints, complete verification steps, and respect domain-specific procedural dependencies outperform those that rely on naive tool use or accept degraded data at face value.
Case studies also expose agent failure modes under fault injection: resilient agents systematically retry or verify, while fragile agents halt prematurely or propagate incorrect inferences from incomplete observations.
Implications and Future Directions
OccuBench establishes a rigorous framework for evaluating agentic AI across practical occupational domains, moving beyond prototype benchmarks restricted to web browsing or isolated APIs. The approach has profound implications for both the deployment of professional agents and the continued development of LLMs as environment simulators:
- Practical: Organizations should select agent models by occupational domain, not aggregate leaderboard scores. Robustness to implicit environmental faults must be considered for production readiness.
- Theoretical: LWM-based simulation enables infinite task diversification and calibration, but depends critically on simulator fidelity and alignment to domain logic.
- Future Work: Integration of real domain data (not just domain logic) will improve evaluation sample realism. Hybrid approaches combining LWM simulation with access to enterprise systems or sandboxed APIs can further bridge the gap to real-world deployment. Agent architectures that explicitly incorporate data quality detection and adaptive recovery may outperform current models in faulted environments.
Conclusion
OccuBench, via Language World Models, breaks the evaluation bottleneck for agentic AI in real-world professional tasks. It enables scalable, rich, and nuanced benchmarking across the "untestable majority" of occupational domains, facilitating multidimensional profiling, revealing environmental resilience gaps, and grounding evaluation in directly actionable occupational roles. The results from 15 frontier models demonstrate that cross-domain capability, fault robustness, scaling trends, and simulator fidelity are essential axes for future agentic evaluation and development.
The framework provides a path to more realistic agent benchmarking, guiding the next generation of AI agent design, selection, and deployment across enterprise, governance, healthcare, logistics, and research domains.

