\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Abstract: As LMs evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “OneMillion‑Bench (short for$1M‑Bench), a big test to see how well AI “language agents” can handle real professional work—like tasks a lawyer, doctor, scientist, engineer, or financial analyst would do. Instead of quiz questions, these are long, multi‑step jobs that need careful research, clear reasoning, and following strict rules. Each task is given a real money value, based on how long a human expert would take and what they’re paid, and all tasks together add up to more than $1 million—hence the name.
What questions are the researchers trying to answer?
They focus on a few easy‑to‑understand goals:
- Can today’s AI agents do expert‑level work that creates real value, not just pass tests?
- How well can they search for reliable information, reason through tough problems, communicate clearly, and follow instructions and rules?
- Which professional areas (Law, Finance, Healthcare, Natural Science, Industry) are easiest or hardest for AI?
- Does giving AI web search tools help—or sometimes make things worse?
- How far are AIs from meeting the standards a human expert would be held to?
How did they test this?
Think of it like grading a real-world school project with a detailed rubric instead of a multiple‑choice test.
- 400 expert‑made tasks: Professional experts created tasks across five fields—Law, Finance, Healthcare, Natural Science, and Industry. The tasks are realistic, open‑ended, and require steps like finding trusted sources, resolving conflicting information, applying domain rules, and making trade‑offs.
- Real money value: Each task gets a dollar value = estimated expert time × hourly wage (based on labor statistics and industry reports). Total value is over $1M. This shows how much useful work an AI could do in practice.
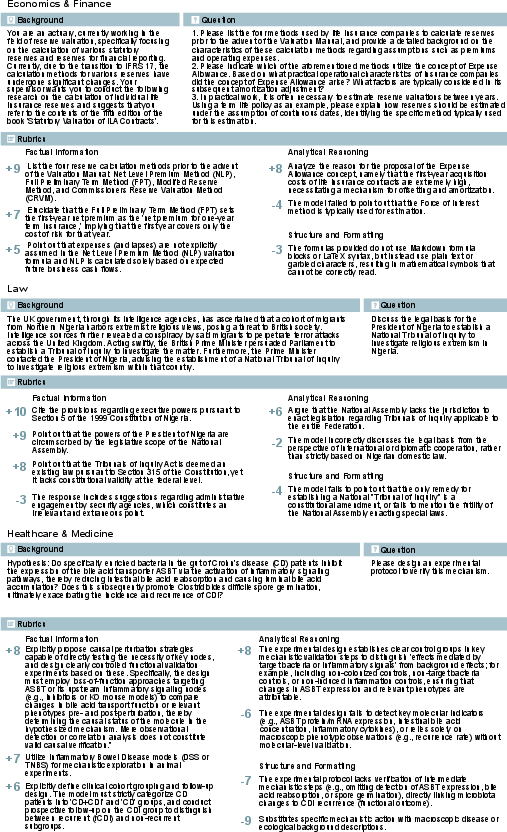
- Clear scoring rubrics (Expert Score): Each task has a rubric that checks:
- Factual accuracy (did you get the facts right and cite sources?),
- Logical coherence (does your reasoning make sense?),
- Practical feasibility (would your plan work in the real world?),
- Professional compliance (did you follow the rules and instructions?).
- Scores run from 0 to 1. There’s also a Pass Rate: the share of tasks where an AI scores at least 0.7 (a “good enough for a pro” bar).
- Some rubric items can deduct points for serious mistakes (like unsafe medical advice or breaking legal rules).
- Skill tags: Each task also checks specific abilities:
- Web search (finding trustworthy info),
- Reasoning (why/how thinking),
- Verbalization (clear, well‑structured writing),
- Instruction following (sticking to constraints).
- Careful quality control: Tasks go through three stages—creation with a reference solution and rubrics; peer review by another expert; and a final audit if needed. They test tasks against strong AI systems and remove those that are too easy (everyone gets them) or too hard (no one can make progress).
- Bilingual and local: 200 tasks are in English and 200 in Chinese, with Chinese tasks tailored to local laws and practices (not just translations). This checks if AI can handle different languages and regional rules.
What did they find, and why does it matter?
Here are the big takeaways, explained simply:
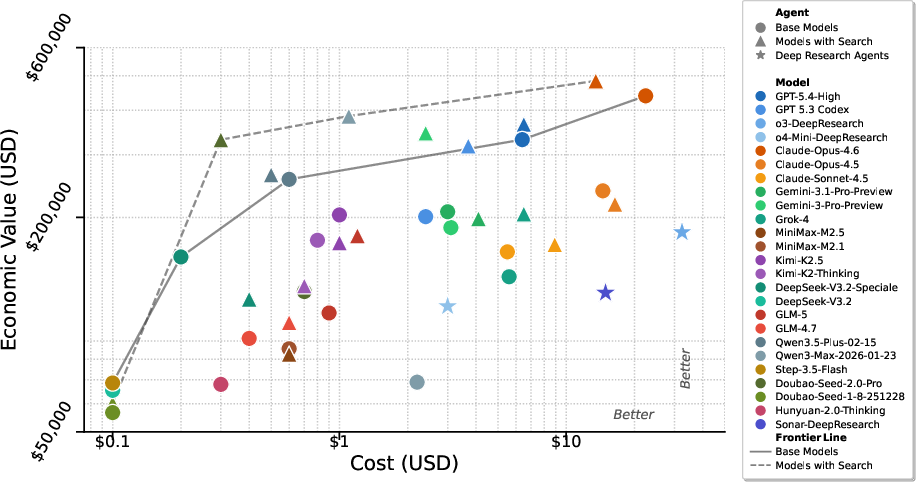
- The best generalist models lead, especially with web search—but not always: Top AI systems did best, and adding web search often improved their performance because they could look up recent or precise facts. But for some models, search introduced noisy or conflicting info and actually made them worse.
- “Deep research” agents aren’t automatically better: Special agents designed for very long, complex research didn’t consistently beat the strongest general‑purpose models with search turned on.
- Partial credit is common; full expert‑level passes are rarer: Many models scored okay across rubrics but still failed to cross the “pass” line for lots of tasks. In other words, they often did some things right but not enough to meet expert standards.
- Some fields are harder than others: Finance tasks tended to be tougher; Healthcare and Law sometimes yielded higher scores for top models. This shows real differences in difficulty across domains.
- Language matters—and it depends on the model: Some AIs performed similarly in English and Chinese; others struggled more in one language. This shows bilingual strength varies by system.
- What skills are strongest or weakest?
- Formatting and structure are generally easier for AIs—they can produce neat, well‑organized reports.
- Factual accuracy and deeper reasoning are harder—they’re more likely to slip on details or logic.
- Instruction following is fragile—some models do well, others drift off task, especially when juggling lots of evidence from the web.
Why it matters: These results show that while AIs are getting better at sounding professional, consistently delivering truly expert‑level, reliable, and safe work—especially under strict rules—remains challenging.
What’s the bigger impact?
- A clearer yardstick for “real value”: By tying tasks to actual labor cost, the benchmark turns AI ability into something concrete—how much useful work (in dollars) a system could deliver.
- Better training targets: The detailed rubrics and skill tags tell researchers exactly where to improve—fact‑checking, reasoning, evidence use, and staying within instructions.
- Safer, more trustworthy AI: Negative penalties for unsafe or non‑compliant outputs push systems toward professional responsibility.
- Practical readiness across regions: The bilingual, locally grounded tasks help ensure AI is useful not just in English or Western contexts, but also under different laws and norms.
In short, $1M‑Bench moves beyond test‑style questions to measure whether AI can handle real expert work that has real‑world value. It shows progress, highlights important gaps, and gives a practical roadmap for building AIs that are not just clever, but reliable and genuinely useful in professional settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, structured to guide future research.
- Economic valuation methodology
- Lack of rigor in expert-time estimation: only 2–3 senior experts per task; no interquartile ranges, calibration sessions, or inter-rater reliability reported for time estimates.
- No sensitivity analysis of “economic value” to wage/time assumptions, seniority level, or regional variations; absence of PPP adjustments and cross-country comparability guidance.
- Unclear formula for per-model “Economic Value” in results (e.g., whether it sums task values gated by pass, scales by Expert Score, or uses another mapping).
- Rubric validity, reliability, and scoring procedure
- No evidence of inter-rater agreement (e.g., Cohen’s kappa) for rubric application or human- vs. LLM-judging consistency checks.
- “Automated scoring” is claimed but evaluation agent, procedure, and safeguards against judge-model bias or self-judging are unspecified.
- Rationale and calibration of asymmetric rubric weights (−20 to +10) are not justified; no ablations showing impact of weight choices or negative-penalty magnitude on rankings.
- No construct validity studies (e.g., correlations with blinded expert grades) to show that rubric scores reflect real professional competence.
- Threshold for Pass Rate (0.7) is arbitrary; no justification or sensitivity analysis across thresholds.
- Task design and representativeness
- Benchmark size (400 items) may be insufficient to robustly cover the breadth/depth of five domains; no power analysis or variance estimates to justify coverage.
- Selection bias from “adversarial validation” (keeping tasks that current frontier models fail) may overweight transient weaknesses and risk rapid obsolescence.
- Limited domains and workflows (e.g., missing software engineering, education, operations, public sector, sales/marketing, HR, etc.); unclear coverage of cross-functional, interdisciplinary tasks.
- Semi–open-ended tasks could have many valid approaches; no evidence that rubrics accommodate alternative correct reasoning paths without undue penalty.
- Multilingual and cross-cultural comparability
- The Chinese subset is not a translation but a different set; comparability between Global and CN scores is ambiguous without aligned task pairs or difficulty equating.
- No analysis of rubric equivalence across languages, cross-lingual bias, or language-specific annotator consistency.
- Wage anchoring differs by region but lacks a framework for comparing “economic value” across languages/cultures.
- Retrieval and web-search scaffolding
- “Impact of Web Search Scaffolds” section is incomplete; implementation details (query planning, source ranking, deduplication, conflict resolution) are missing.
- Reproducibility risk due to dynamic web content and link rot; no frozen corpora, snapshotting, or canonical source lists to stabilize evaluation over time.
- No ablations relating retrieval quality metrics (precision/recall, authority scores) to rubric outcomes; unclear why search helps some models and harms others.
- Agent configuration and evaluation fairness
- Deep research agents are few (3) and may be under-configured; absence of standardized budgets (tokens, steps, wall time), tool limits, or compute parity across systems.
- No disclosure of system prompts, temperature/top‑p, retry logic, or tool-calling policies; reproducibility and fairness are hard to assess.
- Unknown extent to which vendor-specific features (e.g., proprietary browsing, post-processing) affect outcomes.
- Statistical reporting and robustness
- No confidence intervals, bootstrap estimates, or significance testing for score differences and leaderboard rankings.
- No analysis of score stability across multiple runs or seeds for stochastic models.
- Tooling and modality limitations
- Evaluation is largely text+web-search; many professional workflows require spreadsheets, code execution, databases, PDFs, diagrams, or multimodal inputs—these are not assessed.
- Absence of environment interaction (APIs, EHRs, contract management systems, modeling tools) limits claims about “practical readiness.”
- Safety, ethics, and compliance evaluation
- Negative rubrics penalize unsafe or non-compliant behavior, but there is no systematic red-teaming or measurement of harm reduction versus productivity.
- No analysis of whether penalties align with industry risk models, legal liabilities, or institutional policies in different jurisdictions.
- Lifecycle, maintenance, and versioning
- Professional rules and regulations evolve; no update cadence, versioning policy, or deprecation protocol to keep tasks and rubrics current.
- No mechanism to detect and mitigate model overfitting to public benchmark leakage over time.
- Data availability and licensing
- Data release status, licensing terms, and access to full rubrics/reference answers are unclear; restrictions could limit community validation and extension.
- Economic interpretation and external validity
- It is not shown that surpassing the 0.7 rubric threshold correlates with real client acceptance, billability, or reduced human review time.
- No user studies or field trials to validate that benchmark gains translate into measurable workplace productivity or cost savings.
- Error analysis depth
- Limited qualitative analysis of model failure modes per domain/rubric (e.g., systematic hallucinations, misapplication of regulations); no taxonomy to guide targeted improvements.
- Long-horizon reasoning and planning
- Despite claims about multi-step tasks, the benchmark does not evaluate persistent state, interruptions, or multi-session planning typical in real professional projects.
- Generalization and transfer
- No experiments testing robustness to distribution shifts (new regulations, unseen industries), adversarial inputs, or high-noise evidence environments.
- Calibration and confidence
- Models’ self-uncertainty estimates and calibration versus rubric outcomes are not measured; no guidance on when to defer to a human.
- Cost-efficiency analysis
- Absent evaluation of agent performance per dollar of inference/compute cost; unclear trade-offs between capability and operational expense in real deployments.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s benchmark design, metrics, and empirical findings.
- Model and agent selection for professional tasks
- Use $1M-Bench domain- and rubric-level scores (Expert Score, Pass Rate) to pick the best model/agent per workflow (e.g., legal drafting vs. healthcare guideline synthesis vs. financial analysis).
- Sectors: healthcare, law, finance, industry/operations, R&D.
- Tools/products/workflows: AI procurement scorecards; domain-specific acceptance tests; “bench-certified” internal model catalogs.
- Assumptions/Dependencies: Access to the benchmark and evaluation harness; scores are representative of in-house data distributions; licensing permits internal benchmarking.
- ROI and business-case estimation for AI deployments
- Translate benchmark “Economic Value” (time × wage) into projected labor-cost savings and task coverage, to prioritize use cases with high value density.
- Sectors: consulting, shared services, finance, legal ops, hospital admin, R&D PMOs.
- Tools/products/workflows: Value heatmaps by domain; portfolio planning dashboards; pilot scoping templates.
- Assumptions/Dependencies: Wage anchoring and time estimates match local markets and organization-specific processes.
- Risk and compliance gating via negative rubrics
- Enforce guardrails aligned with professional norms using the benchmark’s negative-penalty rubrics (e.g., citation requirements, confidentiality, regulatory compliance).
- Sectors: healthcare (clinical safety/compliance), law (professional conduct), finance (regulatory reporting), enterprise governance.
- Tools/products/workflows: Pre-deployment red-teaming; automated compliance checks; “no-go” policies for unsafe behaviors.
- Assumptions/Dependencies: Rubric coverage maps to internal risk frameworks; policy updates tracked to prevent rubric drift.
- Human-in-the-loop (HITL) triage and routing using “near-miss” detection
- Combine Pass Rate thresholds (e.g., ≥0.7 Expert Score) with “near-miss” signals to auto-route borderline outputs for human review, while fast-tracking confident cases.
- Sectors: legal review queues, medical documentation, financial research notes, manufacturing SOP updates.
- Tools/products/workflows: Triage routers; reviewer dashboards; escalation playbooks.
- Assumptions/Dependencies: Reliable calibration of model scores; reviewer availability; defensible thresholds by domain.
- Web-search usage policy and retrieval QA
- Operationalize the finding that web search helps strong agents but can hurt weaker ones: define toggling policies, retrieval quality filters, and evidence-ranking steps.
- Sectors: all evidence-heavy domains (law, finance, healthcare, R&D).
- Tools/products/workflows: Search gating rules; source whitelists/blacklists; citation completeness checks; retrieval deduplication and conflict resolution.
- Assumptions/Dependencies: Stable access to high-quality sources; model/tool integration supports citations and provenance.
- Localization and bilingual readiness checks
- Use the Global vs. CN subsets to validate local compliance, terminology, and culturally specific workflows before regional rollout.
- Sectors: multinational legal/finance operations, cross-border healthcare policy analysis, localized industrial standards.
- Tools/products/workflows: “Localization packs” of prompts, references, and rubrics; regional readiness reviews.
- Assumptions/Dependencies: Up-to-date local regulations; internal data localized; bilingual model capabilities.
- MLOps quality monitoring with rubric-type telemetry
- Track performance by capability tags (Factual Information, Analytical Reasoning, Instruction Following, Structure/Formatting) to catch regressions (e.g., search-induced formatting drift, reasoning drops).
- Sectors: enterprise AI platforms, model governance teams.
- Tools/products/workflows: Continuous evaluation pipelines; canary suites; alerting on rubric-type deltas; A/B tests with and without search.
- Assumptions/Dependencies: CI/CD integration for models; compute budget for continuous evals; stable benchmark APIs.
- Process-based training signals and fine-tuning data
- Convert rubric-aligned evaluations into supervised or reinforcement signals (e.g., process supervision, reward modeling) to improve instruction following and factuality.
- Sectors: model providers, enterprise AI labs.
- Tools/products/workflows: Rubric-to-reward converters; auto-grader pipelines; process-tracing exemplars.
- Assumptions/Dependencies: Rights to use benchmark tasks for training; careful avoidance of train-test leakage.
- Vendor claims auditing and procurement due diligence
- Independently validate vendor models/agents against $1M-Bench; require Pass Rate and per-domain minimums as part of RFPs/SLAs.
- Sectors: public sector, regulated industries, large enterprises.
- Tools/products/workflows: RFP templates referencing benchmark thresholds; third-party attestation or internal re-tests.
- Assumptions/Dependencies: Vendors permit benchmarking; alignment on scorecards and thresholds.
- Professional upskilling and usage playbooks
- Train staff to exploit agent strengths (e.g., structuring, instruction following) and mitigate weaknesses (e.g., factual retrieval, multi-step reasoning); standardize prompts requiring citations and constraint checklists.
- Sectors: legal, finance, healthcare administration, operations, research teams.
- Tools/products/workflows: Prompt libraries with citation mandates; reasoning checklists; “when to escalate” job aids.
- Assumptions/Dependencies: Adoption of standardized prompts; cultural acceptance of HITL and escalation paths.
- Consumer-facing guidance for high-stakes tasks
- Provide practical advice on when to trust AI assistants (e.g., avoid unsupervised clinical/financial decisions), which features to enable (e.g., require citations), and when to consult a professional.
- Sectors: daily life (tax prep, contract templates, medical guideline lookup).
- Tools/products/workflows: Consumer “trust checklists”; evidence-first prompt templates.
- Assumptions/Dependencies: Access to assistants with citation capabilities; user awareness of limitations.
Long-Term Applications
These use cases likely require further research, scaling, or organizational and regulatory development.
- Standards and certification programs for professional AI agents
- Establish domain-specific minimum Pass Rate thresholds and rubric coverage as prerequisites for certification (e.g., “bench-certified legal drafting assistant”).
- Sectors: healthcare, law, finance; standards bodies and regulators.
- Tools/products/workflows: Independent certification labs; standardized audit protocols; public registries.
- Assumptions/Dependencies: Multi-stakeholder consensus on thresholds; periodic re-certification to track model drift.
- Insurance, liability, and safe-harbor frameworks
- Use benchmarked risk profiles (negative rubrics, Pass Rate by domain) to price AI usage insurance and define safe-harbor practices for organizations adopting certified agents.
- Sectors: insurance, legal, healthcare systems, financial services.
- Tools/products/workflows: Risk-adjusted premiums; liability clauses tied to certified usage; audit logs anchored to rubrics.
- Assumptions/Dependencies: Legal recognition of benchmark-based standards; robust logging and provenance.
- Marketplace and pricing tied to verified “Economic Value”
- Commercialize agent services with outcome-based pricing indexed to validated economic value delivered on benchmark-like tasks.
- Sectors: B2B AI marketplaces, consulting automation platforms.
- Tools/products/workflows: “Pay-for-verified-output” contracts; value meters tied to rubric-pass tasks; performance bonds.
- Assumptions/Dependencies: Reliable generalization from benchmark to real work; low gaming risk; trustworthy third-party verification.
- End-to-end autonomous workflows in regulated domains
- Deploy agents that carry out multi-step, citation-backed workflows (e.g., drafting regulatory filings, generating clinical documentation with guideline alignment), with automated checkpointing against rubrics.
- Sectors: healthcare (documentation, prior auth support), finance (regulatory reporting), law (contract lifecycle).
- Tools/products/workflows: Rubric-aware workflow engines; tool-use planners; continuous evidence validation; human override layers.
- Assumptions/Dependencies: Stable tool integrations (EHR, ERP, CLM); acceptance by regulators; robust failure containment.
- Rubric-driven model training at scale (process-based RL)
- Train models using rubric-weighted, process-sensitive objectives (including negative penalties) to improve factuality, reasoning, and instruction adherence beyond benchmark performance.
- Sectors: foundation model developers, research labs.
- Tools/products/workflows: Process reward models; curriculum learning using rubric-tag stratification; iterative eval-train loops.
- Assumptions/Dependencies: Large-scale compute; careful prevention of overfitting to benchmark rubrics.
- Public-sector workforce planning and impact assessment
- Use domain-level “Economic Value” metrics to project automation potential, plan reskilling programs, and design AI adoption roadmaps across agencies.
- Sectors: government, education, public health.
- Tools/products/workflows: Sectoral impact models; reskilling curricula co-designed with rubrics; capability roadmaps by domain.
- Assumptions/Dependencies: Up-to-date wage/time baselines; realistic mapping from benchmark tasks to civil-service workflows.
- Educational accreditation and assessment modernization
- Align professional training and exams with rubric-based, process-focused evaluation that rewards evidence use, reasoning chains, and compliance with constraints.
- Sectors: higher education, professional licensing.
- Tools/products/workflows: Rubric-aligned assessments; mixed human/AI grading; competency badges linked to benchmark dimensions.
- Assumptions/Dependencies: Accreditation body buy-in; integrity mechanisms preventing AI misuse by students.
- Dynamic, regulation-aware localization engines
- Maintain continuously updated, region-specific rubrics and sources (e.g., China-specific healthcare insurance policies, cybersecurity law) for real-time compliance in cross-border operations.
- Sectors: multinational enterprises, cross-border legal and financial services.
- Tools/products/workflows: Regulation-change monitors; automated rubric/version updates; jurisdiction-aware agent routing.
- Assumptions/Dependencies: Authoritative, machine-readable regulatory feeds; governance for rubric updates.
- Safety science for domain-specific agent behavior
- Formalize and extend negative rubric mechanisms into comprehensive safety taxonomies and measurable risk thresholds for agent behavior in high-stakes contexts.
- Sectors: healthcare, aviation/industrial safety, finance (systemic risk).
- Tools/products/workflows: Domain hazard libraries; incident learning loops; standardized “unsafe behavior” ontologies.
- Assumptions/Dependencies: Cross-industry agreement on safety metrics; integration with incident reporting systems.
- Governance-by-benchmark in model lifecycle management
- Gate model promotion, rollback, and retirement decisions on sustained benchmark performance (overall and per rubric type), including detection of search-induced regressions.
- Sectors: enterprise AI platforms, regulated industries.
- Tools/products/workflows: Policy-as-code for benchmark thresholds; release gating; audit trails for regulators.
- Assumptions/Dependencies: Organizational maturity in MLOps; benchmarks kept current with evolving tasks.
- Advanced tooling: Real-time “Agent QA Copilot”
- A runtime module that scores agent outputs against rubrics in-flight, flags likely failures (e.g., missing citations, instruction violations), and auto-injects corrective prompts or escalates to humans.
- Sectors: all professional agent deployments.
- Tools/products/workflows: Streaming evaluators; structured feedback hooks; self-correction policies linked to rubric tags.
- Assumptions/Dependencies: Low-latency evaluators; reliable proxy metrics that correlate with Expert Score; careful UX to avoid over-correction.
- Benchmark-informed regulation and consumer protection
- Require transparent publication of domain Pass Rates and rubric coverage for consumer-facing AI tools making professional claims; establish minimum disclosure standards.
- Sectors: consumer legal/finance/health apps; app stores.
- Tools/products/workflows: Labeling standards; compliance attestations; third-party test results in product listings.
- Assumptions/Dependencies: Policy adoption; neutral testing infrastructure; mitigation of test gaming.
Notes on Cross-Cutting Assumptions and Dependencies
- Benchmark fidelity: Real-world workflows and regulations evolve; rubrics and sources must be maintained to prevent drift and gaming.
- Generalization: Scores on $1M-Bench are proxies; organizations should run “shadow” evaluations on their own data before full deployment.
- Data governance: Evidence retrieval must respect privacy, licensing, and data residency constraints.
- Human oversight: Especially in healthcare and law, outputs should be reviewed by qualified professionals until certification and liability frameworks are established.
- Cost-benefit: Model inference costs and latency, not covered by the benchmark, must be weighed against “Economic Value” gains for net ROI.
Glossary
- Actuary: A finance/insurance professional who uses mathematics to evaluate risk and value, especially for insurance reserves and policies. "a senior actuary auditing a life-insurance reserve valuation under IFRS 17;"
- Adversarial validation: A validation step where tasks are tested against strong models to ensure they are non-trivial and discriminative. "implement the concurrent adversarial validation."
- Agentic capabilities: The abilities of LLMs to act as autonomous agents performing multi-step reasoning, tool use, and decision-making. "the agentic capabilities of LMs have scaled"
- Agentic scaffolds: Procedural frameworks that structure an agent’s planning, retrieval, and reasoning to improve task performance. "Agentic scaffolds have become the de facto foundation that affects task performance."
- Bidirectional truncation: Dataset filtering that removes items that are too easy or too hard to preserve discriminative power. "filtered the candidate dataset with bidirectional truncation by removing or revising tasks at both extremes"
- Bilinguality: The property of supporting two languages in a benchmark or system design, often with localized content. "Bilinguality Integrated with Local Culture."
- Constraint satisfaction: Ensuring that a solution or process explicitly meets all stated constraints and requirements. "precise retrieval, traceable justification, and careful constraint satisfaction."
- Deep Research Agents: Specialized systems optimized for long-context research and complex reasoning workflows. "Deep Research Agents (3 agents):"
- Employer Costs for Employee Compensation (ECEC): A U.S. Bureau of Labor Statistics statistic that measures total employer compensation, including wages and benefits. "BLS Employer Costs for Employee Compensation (ECEC) release for June 2025"
- Expert Score: A rubric-based metric defined by domain experts to assess how well a generation satisfies professional criteria. "we introduce Expert Score, a rubric-based measurement to assess the degree to which a generation fulfills professional criteria."
- Factual hallucinations: Model-generated statements that are not grounded in evidence and are factually incorrect. "unsafe and harmful generation, factual hallucinations and lapses in expected foundational competencies"
- Frontier agents: State-of-the-art LLM systems used as strong baselines for validation. "tested against a series of frontier agents"
- IFRS 17: An international accounting standard governing the reporting of insurance contracts. "under IFRS 17;"
- Indicator function: A mathematical function that outputs 1 if a condition is met and 0 otherwise, used here for pass/fail criteria. "where \mathds{1}[\cdot] denotes the indicator function"
- Long-horizon agents: Agents designed to handle extended, multi-step tasks requiring sustained reasoning and tool use. "long-horizon agents capable of multi-step reasoning and tool use"
- Occupational Employment and Wage Statistics (OEWS): A BLS dataset providing employment and wage estimates by occupation and region. "the latest Occupational Employment and Wage Statistics (OEWS) from the U.S. Bureau of Labor Statistics"
- Overhead multiplier: A factor applied to wage-only figures to approximate total compensation including benefits. "we apply an overhead multiplier of $1.3$ only when a source reports wages and salaries"
- Reward hacking: Exploiting weaknesses in an evaluation metric to appear to perform well without genuinely meeting task goals. "diverse rubric morphologies without reward hacking"
- Rubric-based evaluation protocol: An assessment approach that scores outputs against predefined, expert-designed criteria. "We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance"
- Rubric weights: Weighted importance assigned to rubric criteria, including asymmetric negative penalties for violations. "asymmetric rubric weights ranging from -20 to 10"
- Rubrics tag: A label associating each rubric with a capability category (e.g., search, reasoning, verbalization, instruction following). "we affiliate a rubrics tag indicating the agentic capability required to finish the task."
- Time-invariant: Describes tasks whose correct answers should remain stable over time. "time-invariant with consistent answer over time."
- Vanilla models: Baseline models evaluated without external tools such as web search. "Vanilla Models (17 models):"
- Verbalization: An evaluation dimension focusing on clarity, structure, style, and professionalism of the response. "Verbalization: It focuses on the logical flow, organizational structure, language style, and overall readability"
- Wage Anchoring: The practice of grounding task valuations in external wage data sources and methodologies. "Wage Anchoring."
- Web search scaffolds: Retrieval-oriented frameworks and procedures integrated into agents to structure web search and evidence use. "Comparison of web search scaffolds."
Collections
Sign up for free to add this paper to one or more collections.