FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Abstract: Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces FinSearchComp, a big, open-source “test” designed to see how well AI assistants (like chatbots) can search for and understand real financial information. Finance is hard because the data is often time-sensitive (like stock prices), detailed (like exact numbers from company reports), and spread across many sources. FinSearchComp gives AI agents realistic tasks that mirror what professional financial analysts do every day, and then measures how close these AIs are to human experts.
What are the main questions the paper asks?
The researchers wanted to know:
- Can AI assistants find the right financial information on the open web, especially when it changes quickly?
- Can they check and combine facts from different sources and time periods to answer careful, detailed questions?
- Does giving AIs access to web search or special financial tools (plugins) make a big difference?
- Do AIs trained in different countries perform better on local markets (like U.S. vs. Greater China)?
- How close are today’s best AIs to expert-level performance on realistic analyst tasks?
How did they study it?
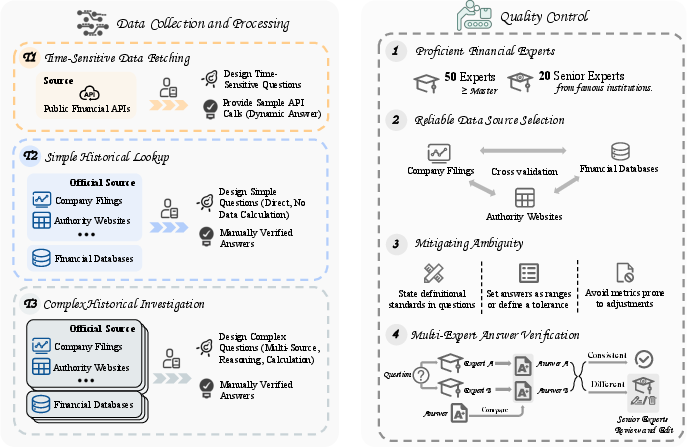
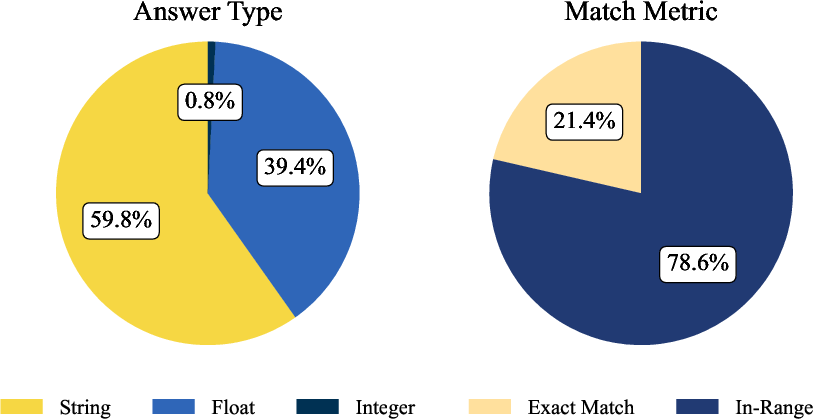
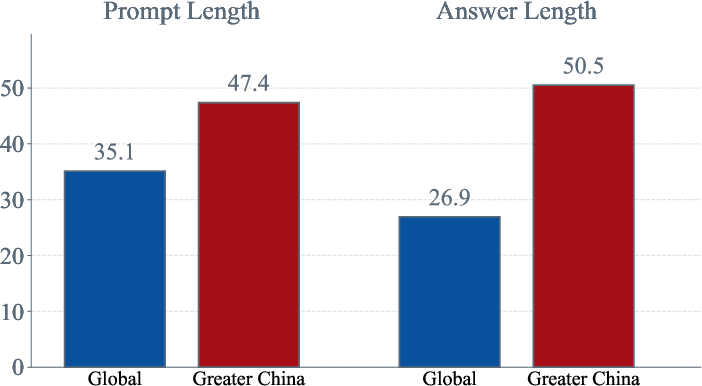
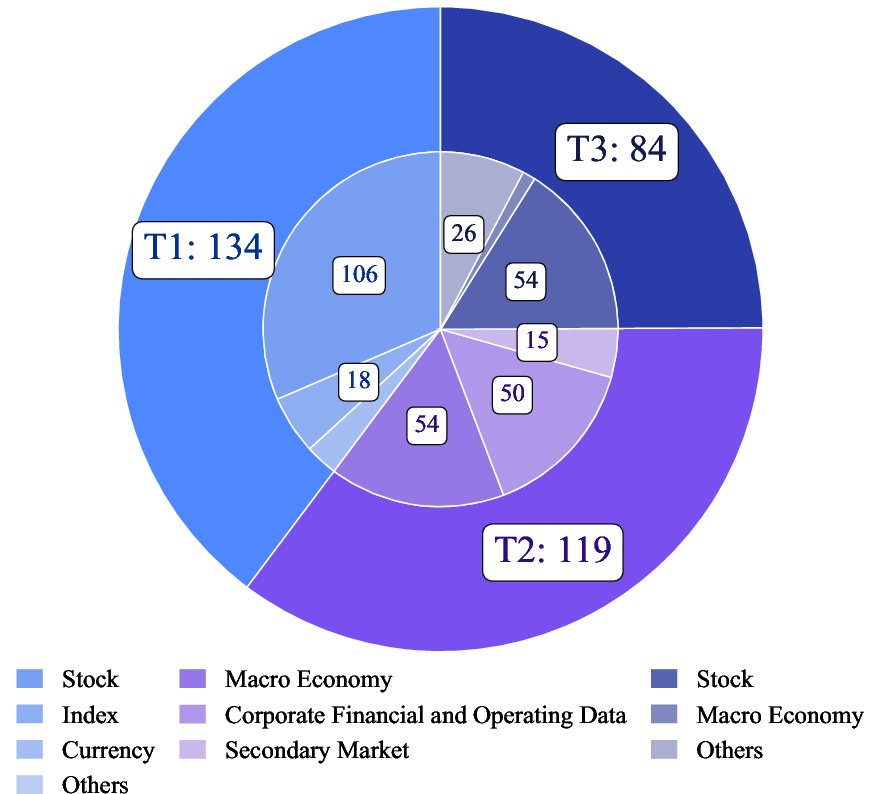
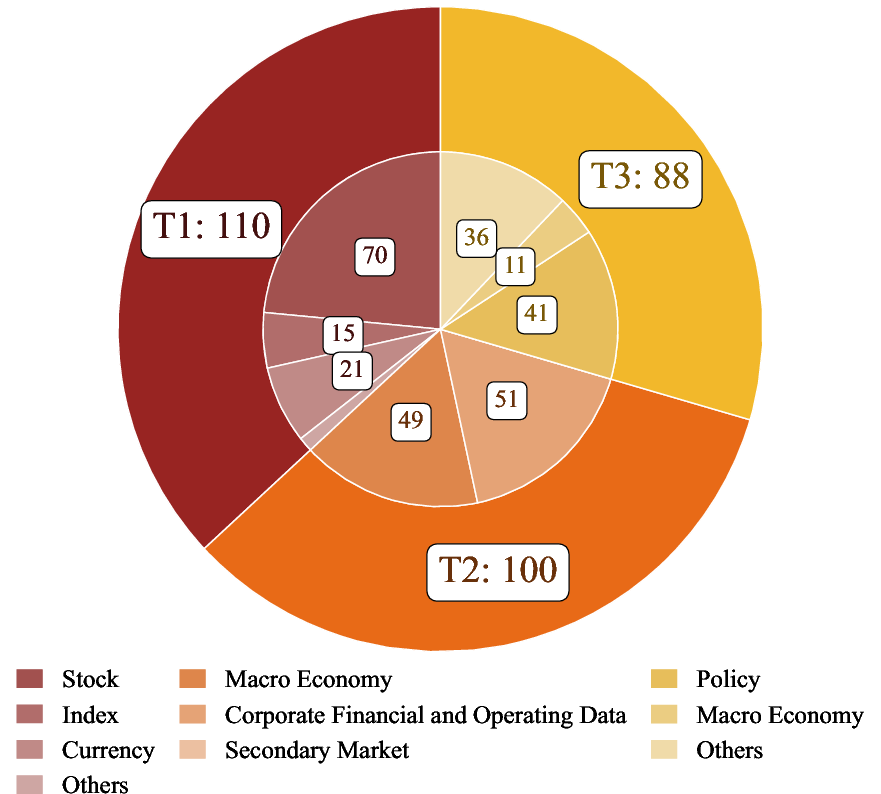
They built a benchmark (a standardized test) with 635 carefully checked questions. The questions cover two regions: Global (mostly Western markets) and Greater China, and are written in English and Chinese. Each question has one clear answer and is designed to be realistic and fair. To make this happen:
- 70 professional financial experts helped write and verify questions and answers. They used high-quality sources like company filings, government websites, and trusted financial databases.
- Every question went through multi-stage quality checks to remove ambiguity, set reasonable “tolerance” ranges (to allow tiny differences like rounding), and ensure answers are correct.
- The benchmark tests three types of tasks that match real analyst work:
- Time-Sensitive Data Fetching: fresh, fast-changing numbers (like “IBM’s latest closing price”).
- Simple Historical Lookup: a single, exact fact from the past (like “Starbucks’ total assets as of Sept 27, 2020”).
- Complex Historical Investigation: multi-step questions across long time periods that require stitching together data from different sources (like “Which month since 2010 had the biggest one-month rise in the S&P 500?”).
- They evaluated 21 AI models (some with web access, some via APIs) and compared them to human experts. An “AI judge” was used to grade answers against the rules, with human spot checks to confirm reliability.
Think of it like a realistic scavenger hunt where the AI has to:
- Find fresh info (today’s score).
- Retrieve exact past facts (stats from a specific season).
- Combine many stats over time to draw conclusions (which month was the biggest win streak).
What did they find?
Key results:
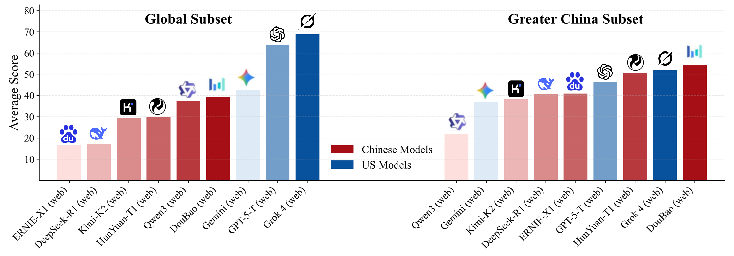
- On the Global set, Grok 4 (web) scored highest, with about 68.9% accuracy. That’s close to, but still below, human experts (about 75%).
- On the Greater China set, DouBao (web) scored best, but all AI models were still far below human experts (humans were around 88.3%).
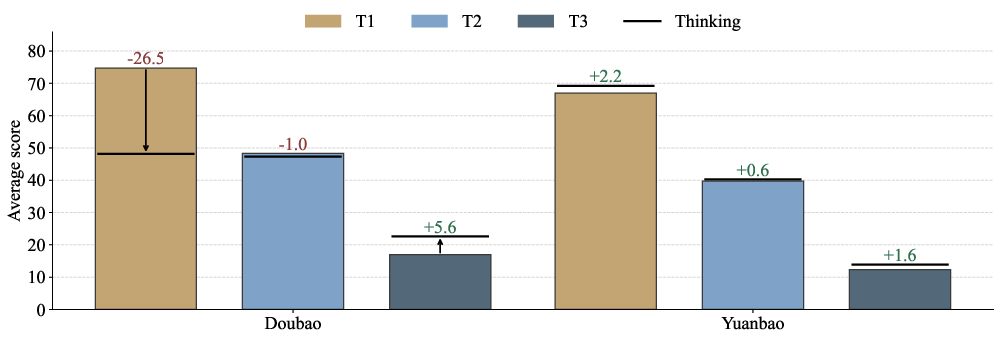
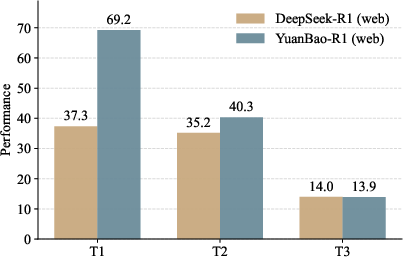
- AIs that can use web search or financial plugins perform much better, especially on time-sensitive tasks. Models without search basically fail on “fresh” questions.
- Common mistakes include:
- Using outdated info instead of the newest numbers.
- Mixing up units or currencies.
- Misreading calendars (like fiscal year vs. calendar year).
- Not digging deep enough to verify sources.
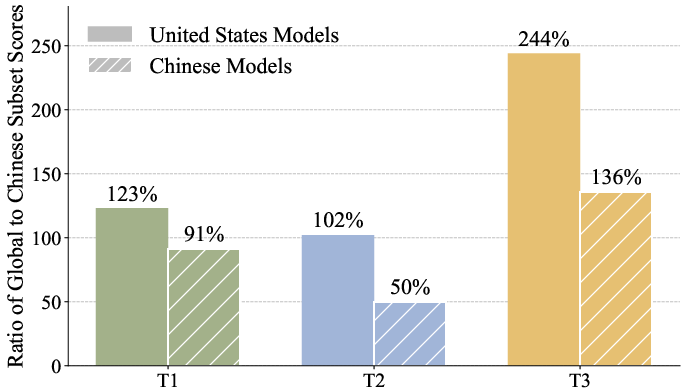
- “Home advantage” matters: U.S.-origin models tend to do better on global/Western data; Chinese-origin models tend to do better on Greater China data. Language, training data, and local data sources likely play a role.
Why is this important?
Finance decisions rely on accurate, up-to-date information. If an AI gives the wrong price, misreads a report, or mixes currencies, it can lead to bad choices. FinSearchComp acts like a tough, realistic field test to show how well AIs handle real analyst tasks—not just trivia. It helps researchers and companies see where AIs are strong and where they’re fragile, so they know what to improve.
Implications and impact
- For AI developers: The benchmark points to clear areas to fix—like better freshness awareness, deeper search, smarter use of plugins, and stronger time/currency handling.
- For financial analysts: As AIs improve on these tasks, they could save significant time on data fetching and checking, letting analysts focus more on judgment and strategy.
- For broader fields: The skills tested here—finding fresh info, verifying point-in-time facts, and combining evidence over time—are also vital in journalism, public policy, science, and more.
- Overall: Some top AIs are getting close to experts on certain tasks, but they still struggle with full real-world complexity. FinSearchComp gives a high-quality, open tool to track progress and push toward more reliable, expert-level AI helpers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research and benchmark development:
- Lack of process-level evaluation: the benchmark scores only the final answer (0–1), without assessing search planning quality, step-by-step reasoning, citation use, or evidence reconciliation strategies that lead to the answer.
- No standardized source-citation requirement: models are not required to provide verifiable URLs/timestamps for each claim, limiting auditability and the ability to diagnose correctness “by construction.”
- LLM-as-a-judge details under-specified: the identity, version, and configuration of the judging model(s) are not disclosed, preventing replication and raising concerns about potential bias (e.g., self-judging or family-judging effects).
- Limited judge validation: agreement with human labels is reported on “roughly 400 instances per dataset,” but no per-task, per-language, or per-format breakdowns, confidence intervals, or failure analyses of judge errors are provided.
- Binary scoring for multi-part outputs: complex tasks that require tables/lists are graded 0–1, with no partial credit scheme for partially correct multi-row/multi-field answers, potentially under-informative for model diagnostics.
- Tolerance design opaque: the paper does not specify how error bounds/ranges are set per metric and asset class, how they are validated, or whether they are calibrated for discriminative power and fairness across tasks and markets.
- Potential leniency in T1 acceptance: for some instruments, answers within the intraday high-low range are deemed correct; this may over-credit imprecise outputs and weaken difficulty comparability across assets.
- Reproducibility of T1 unclear: T1 relies on market-close timing and live APIs but does not standardize timezones, data vendors, or exact query windows for all models on the same day, risking non-comparable runs across a 20-day test window.
- Uncontrolled tool heterogeneity: “web-based products” and proprietary financial plugins differ widely; without a standardized tool track, performance differences may reflect tool access rather than agent capability.
- No dual-track design: the benchmark lacks a controlled “standardized-tool” track (fixed browser + fixed data APIs) alongside the open-world track to separate agent competence from tool privilege.
- Dataset size and coverage: 635 items across two markets and three task types may be insufficient for stable leaderboards; the paper does not provide task-weighting rationale, per-topic item counts, or power analyses.
- Topic/market breadth gaps: limited coverage of fixed income (yields, curves, credit), derivatives (Greeks, implieds), corporate actions at scale, fund flows, private markets, and regulatory disclosures beyond SEC/CN/HK/TW.
- Cross-lingual generalization under-explored: the benchmark includes English and Chinese, but there is no controlled cross-lingual test (e.g., English prompts requiring Chinese sources), nor analysis of translation/code-switching failure modes.
- Temporal versioning of gold answers: for T2/T3 items susceptible to restatements/revisions (e.g., macro series, refiled financials), the paper does not specify freeze dates, data vintages, or mechanisms to update labels over time.
- Provenance transparency: it is unclear whether every gold answer is accompanied by a canonical source list (URLs, filing IDs, versions, retrieval dates), which is essential for future verification and maintenance.
- Memorization vs. search confound: T2/T3 could be solved from parametric memory; the paper does not include contamination analysis, anti-leakage design (e.g., post-training cut-off items), or “future-dated” tasks to isolate true retrieval ability.
- Human baseline methodology: no details on time limits, tools, instructions, or inter-human variance are provided; the relatively low human accuracy on the global subset is not explained via item difficulty or ambiguity audits.
- Statistical rigor of model comparisons: no confidence intervals, significance tests, or multi-run variability are reported; differences of a few percentage points may be within noise.
- Tool-usage telemetry absent: the benchmark does not release browsing/action logs, making it hard to analyze search depth, tool selection errors, or effective strategies across models.
- Adversarial/robustness testing missing: models are not challenged with conflicting, stale, or misleading sources, nor with prompt-injection/malicious pages—key stressors for real-world financial search.
- No ablations on search strategy: beyond one case study, there is no systematic analysis of query formulation, re-querying, rank bias, or source selection policies and how they impact accuracy.
- Limited fairness of evaluation infrastructure: models with proprietary plugins may access fresher/cleaner data than others; the benchmark does not normalize or disclose access parity, creating potential fairness concerns.
- Maintenance plan unspecified: there is no stated process for refreshing T1 items, revising T2/T3 labels after restatements, rotating hidden test items, or preventing benchmark overfitting over time.
- Explanation quality not evaluated: the benchmark focuses on numeric correctness and does not assess narrative synthesis, uncertainty communication, or financial-standards adherence (e.g., GAAP vs non-GAAP explanation).
- Currency/unit normalization stress tests are narrow: while cited as failure modes, there is no explicit sub-benchmark isolating unit/currency pitfalls (e.g., denomination shifts, split-adjustments) with controlled difficulty.
- Market origin analysis is correlational: the “home-field” effect (US vs China models) is observed but not causally probed via controlled toolsets, mirror tasks with matched sources, or language/tool ablations.
- Data-access reproducibility: some gold answers reportedly come from professional databases; reproducibility is limited if those sources are paywalled and not mirrored with public provenance.
- Ethical/compliance considerations unaddressed: the benchmark does not discuss compliance constraints (e.g., licensing, usage restrictions), data privacy, or potential conflicts in using proprietary feeds.
- Generalization beyond finance: while finance is positioned as a proving ground, the paper does not test transfer to other domains with similar constraints (e.g., law, medicine) to validate claims about broader cognitive skills.
- Complexity metrics absent: task “complexity” is described qualitatively; there is no formal metric (e.g., required hops, sources, temporal span, unit conversions) to quantify and control difficulty within and across tasks.
- Leaderboard governance unclear: no policy is provided on disclosure of tools/data used by submissions, run documentation, or audit procedures to ensure comparability and integrity.
Collections
Sign up for free to add this paper to one or more collections.

