APEX-Agents
Abstract: We introduce the AI Productivity Index for Agents (APEX-Agents), a benchmark for assessing whether AI agents can execute long-horizon, cross-application tasks created by investment banking analysts, management consultants, and corporate lawyers. APEX-Agents requires agents to navigate realistic work environments with files and tools. We test eight agents for the leaderboard using Pass@1. Gemini 3 Flash (Thinking=High) achieves the highest score of 24.0%, followed by GPT-5.2 (Thinking=High), Claude Opus 4.5 (Thinking=High), and Gemini 3 Pro (Thinking=High). We open source the APEX-Agents benchmark (n=480) with all prompts, rubrics, gold outputs, files, and metadata. We also open-source Archipelago, our infrastructure for agent execution and evaluation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “APEX-Agents”
What is this paper about?
This paper introduces APEX-Agents, a big test (a “benchmark”) to see how well AI “agents” can do real, complicated office work—like what investment banking analysts, management consultants, and corporate lawyers do. Instead of giving AI short trivia questions, APEX-Agents gives them longer tasks that take planning, math, reading documents, and using different apps (like spreadsheets, slide decks, emails, and PDFs) inside a realistic, computer-like workspace.
The main idea: build a realistic virtual office with real files and tools, then ask AI agents to finish professional tasks from start to finish—and measure how often they get everything right.
What questions were the researchers asking?
They focused on a few simple questions:
- Can AI agents complete complex, real-world office tasks that usually take a human 1–2 hours?
- How do different AI agents compare on the same tasks?
- How consistent are agents—do they get it right just once, or regularly?
- Where do they fail, and why?
- Can we build a fair, repeatable way to test these skills that other researchers can use?
How did they test the AI agents?
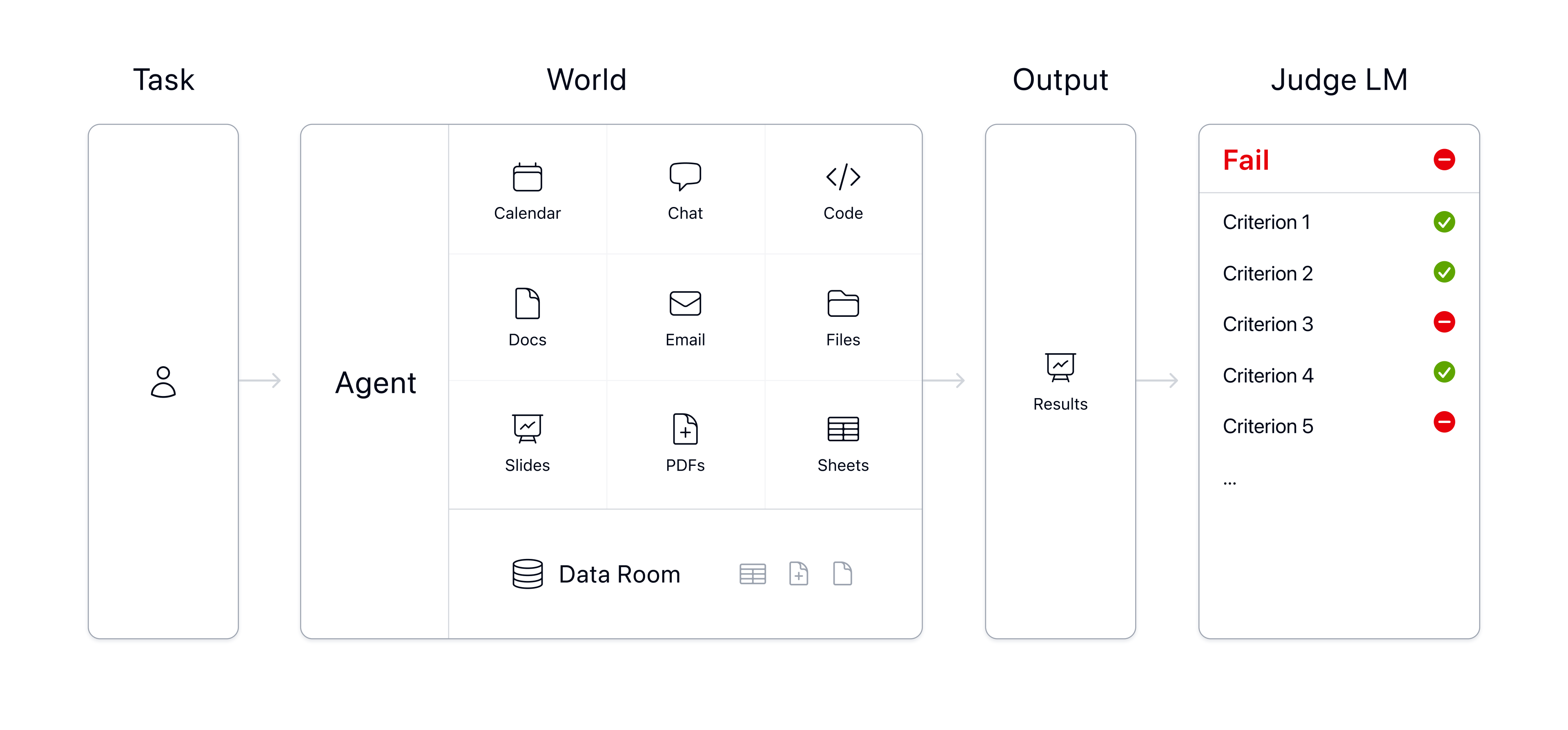
Think of it like setting up a realistic “virtual office” and then sending AI agents in to work.
- Building “worlds” (virtual offices): Experts (real bankers, consultants, and lawyers) created 33 detailed project environments called “worlds.” Each one has lots of files (about 166 per world on average), emails, spreadsheets, PDFs, slides, and tools like Calendar, Documents, Spreadsheets, Presentations, PDF reader, and even a code tool for calculations. Web search was turned off so results are reproducible.
- Writing the tasks: Those same experts designed 480 realistic tasks that match their real jobs. Example: “Find a company’s P/E ratio using numbers from these specific files, and round to two decimal places.” Most tasks ask for a short answer in the console; some require creating or editing a spreadsheet, document, or slide deck. Experts estimated each task would take an experienced human about 1–2 hours.
- Creating fair grading: Each task has a short checklist (“rubric”) of must-haves, like “Did the answer use the right model?” or “Is the number rounded correctly?” A task only “passes” if it meets all the checklist items. Experts also wrote “gold” answers to show exactly what a correct solution looks like.
- Running the agents: Eight different AI agents tried every task eight times each (to check consistency). Each run was limited to 250 steps so agents wouldn’t get stuck forever.
- Judging results: A separate AI model (Gemini 3 Flash, with conservative settings) graded each answer against the rubric. The judging model was tested against human labels and was very accurate (about 98.5% on a test set), though tiny score differences under 1 percentage point should be treated carefully.
- Human baseline checks: For 20% of tasks, new experts (who didn’t write the tasks) completed them from scratch to make sure the tasks were doable and the rubrics were fair. That worked well and helped catch small issues.
What did they find, in plain language?
Big picture: Today’s best agents can sometimes do these complex tasks, but they aren’t reliable yet.
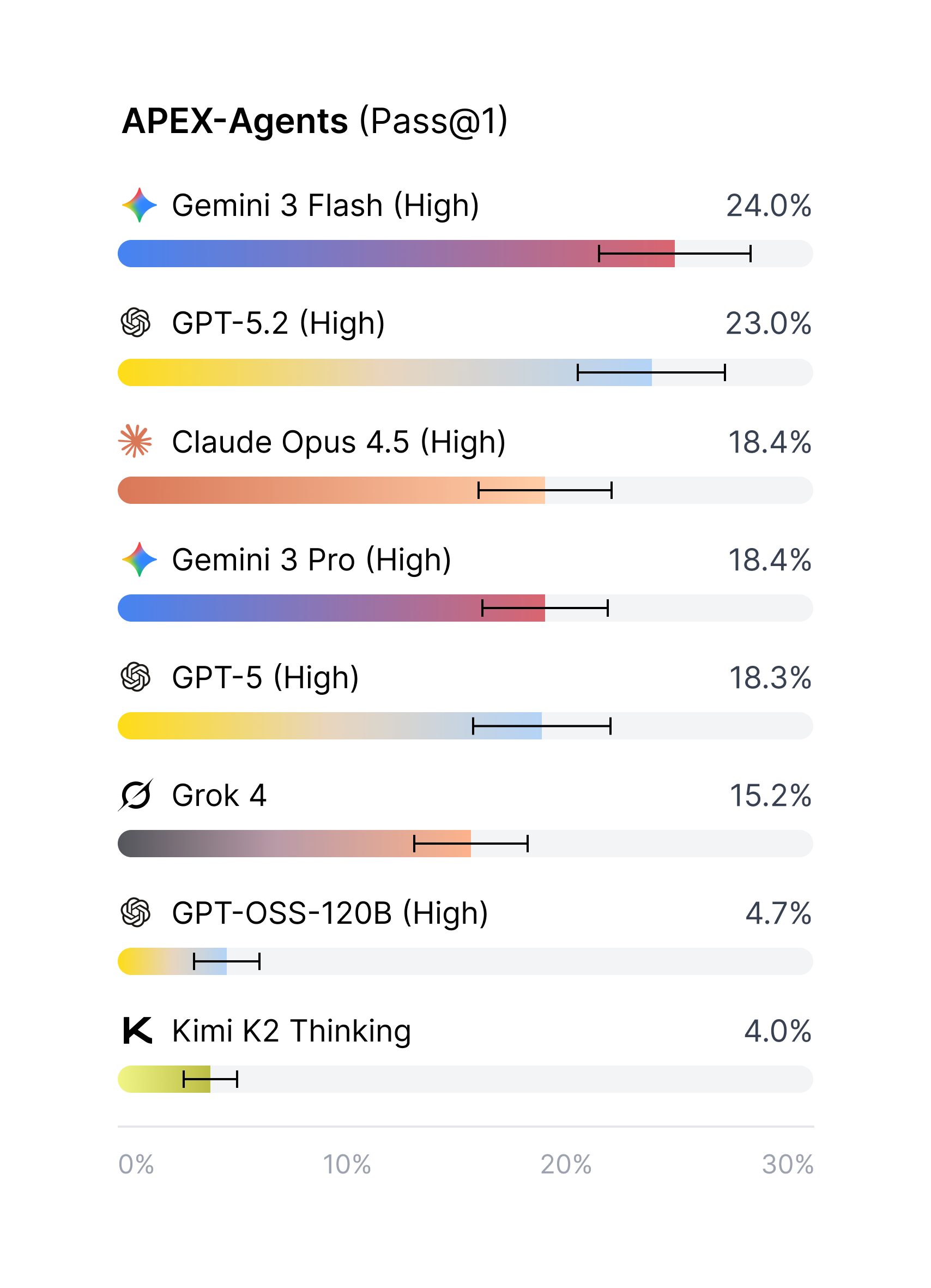
- Overall pass rates are low on the first try:
- Best first-try score (Pass@1) was 24.0% (Gemini 3 Flash).
- GPT-5.2 got 23.0%.
- Claude Opus 4.5 and Gemini 3 Pro were both 18.4%.
- Two open-source models scored under 5%.
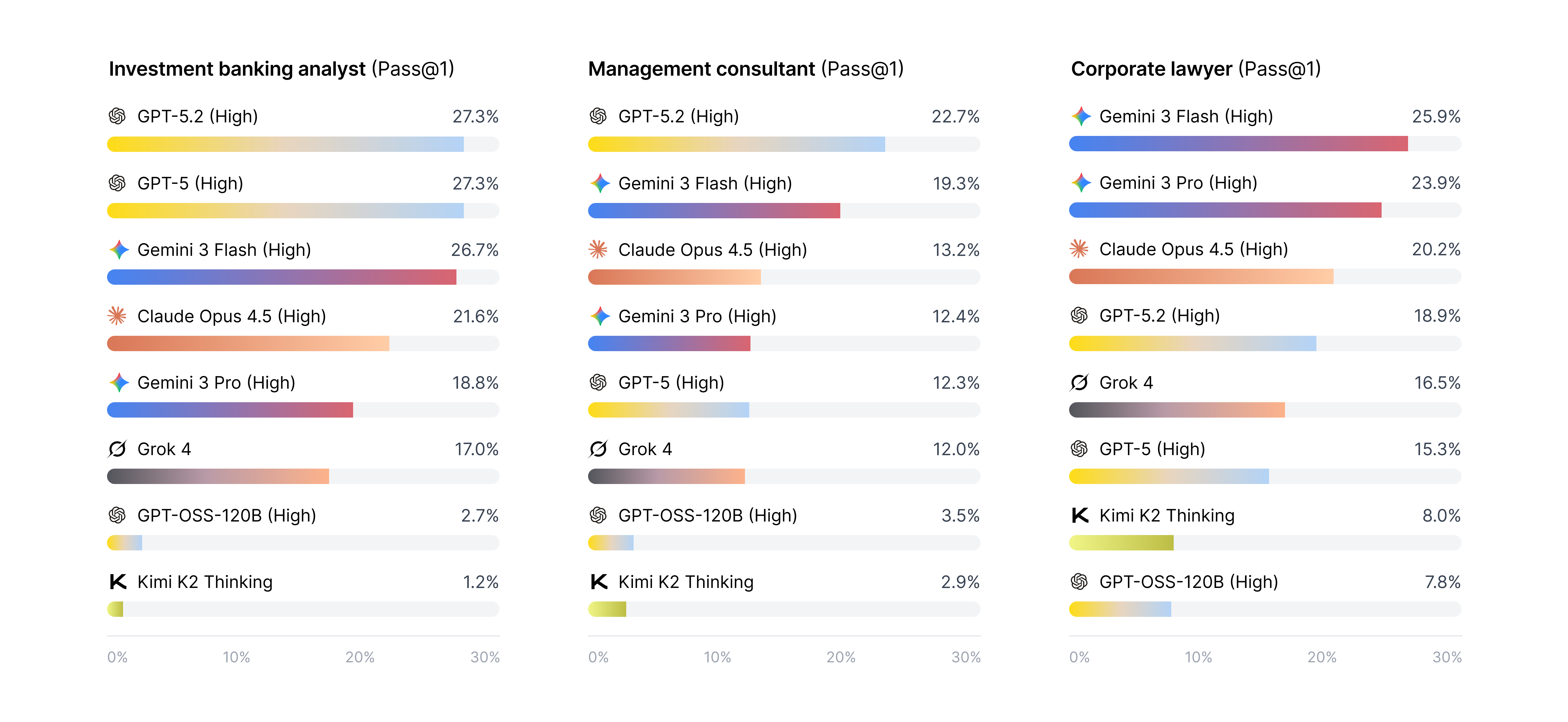
- By job type:
- Investment banking tasks: top score 27.3% (GPT-5 and GPT-5.2).
- Management consulting tasks: top score 22.7% (GPT-5.2).
- Legal tasks: top score 25.9% (Gemini 3 Flash).
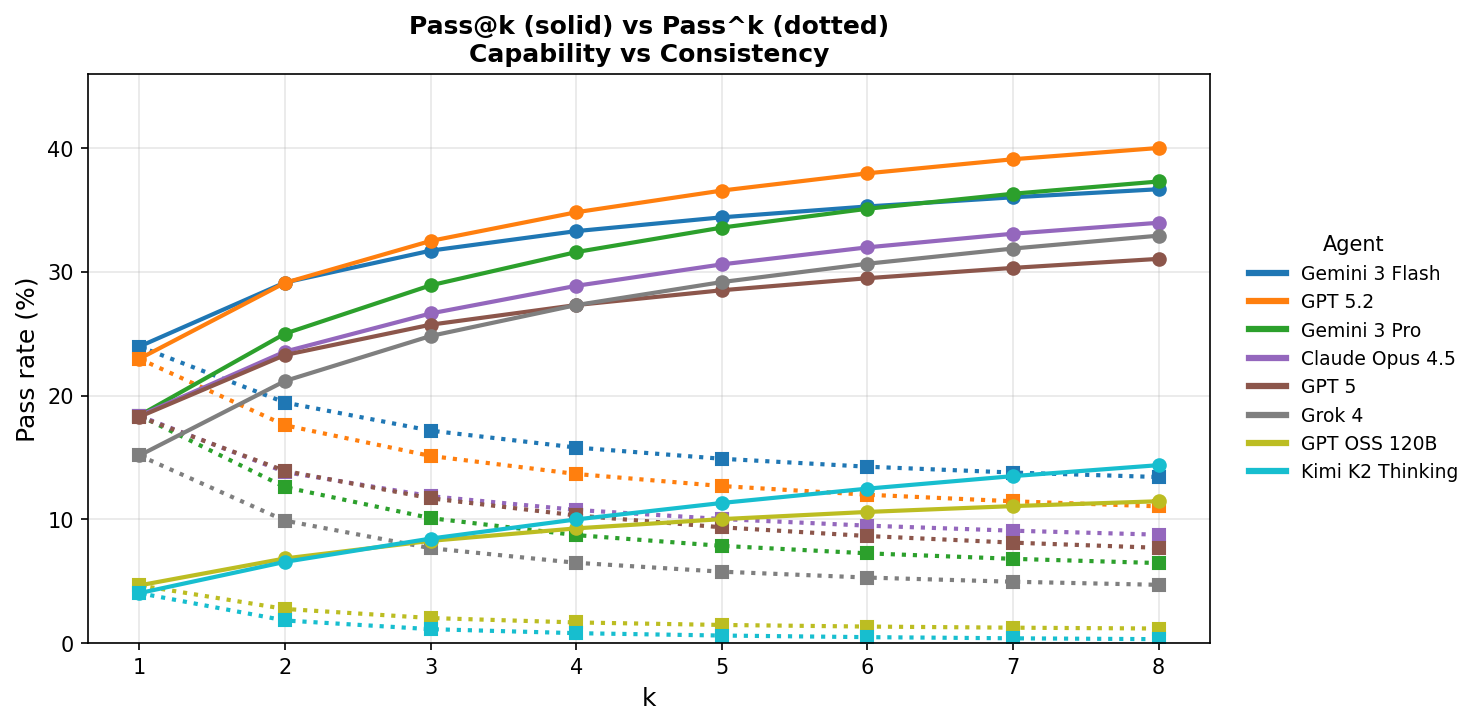
- “Try more than once” helps, but not enough:
- If you let an agent try 8 times and count a win if it passes at least once (Pass@8), the top score rises to about 40.0% (GPT-5.2). That’s better, but still far from dependable.
- If you require the agent to pass every single time across 8 tries (Pass8), the best score is only 13.4% (Gemini 3 Flash). This shows inconsistency is a big problem.
- Partial progress is common:
- Even when agents don’t fully pass, they often get some parts right. Average “partial credit” (percent of checklist items met) is much higher than Pass@1, suggesting they can produce useful pieces of work but miss a crucial detail.
- How they use tools matters:
- Successful runs tend to use fewer steps and fewer total tool calls (less “doom looping”).
- Code execution is used a lot, but passing runs avoid overusing repeated, unhelpful actions.
- Some agents use many more tokens and steps than others without better results—so more effort doesn’t always mean better outcomes.
- Types of failures:
- Many runs score zero on strict grading because if even one must-have is missing, the whole task fails.
- Some agents get stuck and hit the 250-step limit, especially the weaker open-source ones.
- Unwanted file deletions were rare but happened in a small number of runs for a few agents.
- The judge model is dependable:
- It matched human graders very closely on a test set, so the scores are trustworthy overall.
- Open-source vs. closed-source:
- In this benchmark, the closed-source agents clearly outperformed the two open-source ones tested. There’s a noticeable performance gap.
Why does this matter?
- Real-world relevance: These tasks look like actual projects at banks, consulting firms, and law practices. Passing them means the AI did real work, not just answering a short question.
- Honest picture: The results show that even top agents are far from reliably completing complex, multi-step, multi-app tasks. They can help, but you can’t count on them to get everything right every time.
- Open resources: The authors released the full benchmark (all tasks, files, rubrics, correct answers) and the agent-testing infrastructure (called Archipelago) so anyone can test and improve agents in a realistic way.
What could happen next?
- For researchers and builders:
- Use APEX-Agents to train and test better planning, tool use, and error-checking strategies.
- Focus on consistency, not just occasional wins—make Passk go up, not just Pass@k.
- Improve agents’ ability to avoid unproductive loops and to finish tasks cleanly.
- For companies:
- Be cautious about relying on agents for high-stakes professional work. They can assist and draft, but they’re not yet reliably end-to-end.
- Expect value from partial progress (summaries, initial analysis, draft models), but keep humans in the loop.
- For the field:
- As this benchmark grows (more worlds, deeper tasks), it can track real progress toward trustworthy, end-to-end AI work in professional settings.
In short: APEX-Agents is like a realistic obstacle course for office AIs. Today’s best agents can sometimes make it to the finish line, but not often enough and not consistently. The benchmark gives everyone a fair, open way to measure improvements and push toward agents that can truly handle complex, long, cross-application work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several points unresolved; future work should address the following:
- Realism of work settings: Tasks prohibit clarifications (“You cannot ask for help”) and use single-turn prompts, while professional services often require multi-turn communication, stakeholder alignment, and iterative revision; quantify performance impacts when enabling multi-turn dialogue, human-in-the-loop feedback, and customer clarification.
- Web access and external data: Evaluations disable web search and constrain tasks to in-world files, limiting ecological validity; measure how enabling web tools, live data, and external enterprise systems (APIs, CRMs, data rooms, compliance tools) changes capability, consistency, and failure modes.
- Tool ecosystem breadth: Worlds expose a limited set of apps/tools (with specialized finance tools only in 2 worlds); test generalization across broader, heterogenous enterprise stacks (email clients, BI dashboards, ETL pipelines, code repos, auth/permissions, regulatory/compliance systems), and assess tool-transfer robustness.
- Harness and prompt design bias: All models are run with a single ReAct toolbelt and one system prompt; perform ablations with model-optimized harnesses, different agent paradigms (planner-executor, verification-first, program-synthesis), and prompt variants to isolate harness effects from model capability.
- “Thinking” and configuration parity: Reasoning settings and “max tokens” differ across models (and appear inconsistently documented in Table 9); standardize and report comparable budgets (context window, step caps, token limits, temperature) and rerun to evaluate fairness and sensitivity.
- Step budget and loop behavior: A hard cap of 250 steps may truncate otherwise solvable trajectories; conduct sensitivity analyses on step caps, introduce adaptive loop detection/termination, and quantify the pass-rate vs. step-budget curve.
- Judge model dependence and self-preference: Grading relies on a single closed-source judge (Gemini 3 Flash) with a small ground-truth set (n=60 tasks, 249 criteria); replicate with multi-judge ensembles (including open models), larger human labels, and adversarial cases to characterize false positives/negatives and judge bias, especially toward models on the leaderboard.
- Statistical assumptions: Significance tests assume task independence, yet tasks share worlds and assets; use hierarchical models or clustered bootstrapping at the world level to account for intra-world correlation and re-evaluate significance.
- Human baseline comparability: The baselining study checks task feasibility/time on 20% of tasks but does not report human pass@k or criterion-level accuracy; establish matched human baselines (Pass@1/Pass@8/Passk, mean criterion score, cost/time) to calibrate agent performance against experienced professionals.
- Productivity and cost-efficiency: Token counts are reported, but not wall-clock latency or dollar cost; add time and cost metrics to quantify the capability–efficiency frontier, and evaluate cost-normalized performance (e.g., passes per $ and per minute).
- Task value weighting: Pass@1 treats all tasks uniformly despite heterogeneous estimated hours and business value; report weighted metrics (e.g., by estimated hours, workflow importance, dollar impact) to reflect real-world productivity significance.
- Rubric coverage and value capture: Criteria are “must-haves” and may miss quality, risk, and economic value (e.g., strategic soundness, legal defensibility, stakeholder readability); develop complementary graded rubrics and expert quality ratings to capture utility beyond binary completion.
- Selection bias in task creation: Tasks were iterated adversarially using outputs from frontier agents (GPT-5, Claude, Gemini); quantify and mitigate potential bias (e.g., held-out task creators, blinded iteration, out-of-sample worlds) and test whether tasks overfit current agents’ failure modes.
- Domain scope: Benchmark covers investment banking, consulting, and corporate law only; expand to adjacent high-value functions (tax, audit, procurement, finance FP&A, operations, marketing, HR, compliance) to test breadth of agentic utility.
- World fidelity and dynamics: Many worlds use fictional scenarios and static assets; introduce dynamic changes (late-breaking data, shifting goals, stakeholder pushback), realistic constraints (permissions, access failures), and multi-day dependencies to better approximate live engagements.
- Memory and multi-task continuity: Agents execute tasks in isolation; evaluate persistent memory across sequences of related tasks, cross-task state management, and the ability to carry context across a multi-day project plan.
- Collaboration: The worlds simulate teams, but agents don’t coordinate; assess multi-agent collaboration (role specialization, handoffs, shared plans), and human–AI team workflows with explicit coordination costs and benefits.
- Safety and reliability: Only unwanted file deletions are tracked (0.12%); instrument broader failure and harm modes (overwrite/corruption, privacy breaches, mis-sends, misfilings, data exfiltration), and evaluate guardrails, rollback, and recovery mechanisms.
- File-output performance gap: Agents underperform on tasks requiring file creation/editing; isolate root causes (tool UX, file format constraints, path handling, write permissions) and test targeted improvements (file validators, schema enforcement, template-guided editing).
- Consistency improvements: The drop from Pass@8 to Pass8 indicates instability; systematically test verification, self-checking, reflection, and programmatic validators to increase run-to-run consistency, and quantify gains.
- Failure-mode taxonomy: Beyond “timeout/zero/partial,” detailed error taxonomies (wrong source, miscalc, misreference, tool misuse, path errors, format mismatches) are missing; build and release a labeled failure dataset to guide targeted method development.
- Workflow-level reporting: Results by job are provided, but not by workflow type; report per-workflow performance (e.g., DCF, LBO, contract review, legal research) to identify method-specific gaps and prioritize domain-tailored tools.
- Reproducibility of closed-source evaluations: API behaviors and “thinking” settings may change over time; version and pin model configs, release exact prompts/traces, and provide reproducibility scripts with checksums for worlds and tools.
- Token-budget sensitivity: Large differences in token usage suggest efficiency disparities; run controlled experiments with fixed token/step budgets across models to assess fairness and efficiency–accuracy trade-offs.
- Effects of specialized data tools: Only two IB worlds include SEC and fixed-income tools; compare performance with/without such domain-specific tools, and test portability across data providers (EDGAR alternatives, Bloomberg-like proxies).
- Clarification benefits: Disallowing clarifications is known to increase errors on ambiguous tasks; design a controlled study enabling scoped clarifications (customer role-play responses) to quantify the productivity lift vs. risk of prompt injection.
- Dataset splits and generalization: No dev/test split or out-of-domain evaluation is described; create train/dev/test partitions, out-of-world tasks, and cross-world transfer tests to measure generalization and reduce overfitting to specific worlds.
- Economic impact linkage: The benchmark evidences technical capability but not downstream business outcomes (e.g., revenue uplift, error cost, legal risk); conduct field studies mapping Pass@k and mean criterion score to concrete productivity and quality metrics in live deployments.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that leverage the paper’s findings, methods, dataset, and open-source infrastructure.
- Enterprise agent QA and model selection (sectors: software, finance, legal, consulting)
- Use APEX-Agents and Archipelago to build a pre-deployment sandbox that mirrors internal workflows (documents, spreadsheets, emails, PDFs, code execution) and gate releases with Pass@1/Pass@8 thresholds.
- Products/workflows: “Agent Regression Suite,” “Model Selection Pipeline,” “APEX-style QA dashboards.”
- Assumptions/dependencies: Ability to replicate enterprise environments as containerized “worlds;” secure handling of internal data; judge model generalization to domain specifics.
- Procurement and vendor due diligence (sectors: enterprise IT, finance, legal)
- Standardize RFPs around APEX-style metrics (Pass@1, Pass@8, Passk) and rubric-based grading to compare agent vendors fairly.
- Products/workflows: “APEX-compliant benchmarking as a service,” contract SLAs referencing Pass@k bands.
- Assumptions/dependencies: Benchmarks cover relevant task distributions; calibration of rubrics to company priorities; awareness that small differences (<1 pp) may be statistically ambiguous.
- Agent orchestration cost and efficiency optimization (sectors: software/DevOps, energy/cost control)
- Use token and tool-use analytics (steps, tool calls, completion tokens) to set run-time policies: step caps, loop detection, toolbelt pruning, and model choice for cost/latency trade-offs.
- Products/workflows: “Agent Cost Governor,” “Toolbelt Auditor,” “Loop Detector.”
- Assumptions/dependencies: Production instrumentation similar to Archipelago; transferability of efficiency patterns from benchmark to in-house tooling.
- Automated output verification and guardrails (sectors: compliance, legal, regulated industries)
- Adopt rubric-based verifiers and “final_answer” gating to catch incomplete/unsafe outputs and prevent destructive actions (e.g., unwanted file deletion).
- Products/workflows: “Verifier Gate for multi-app agents,” “Before/After diff checks,” “No-delete policy enforcement.”
- Assumptions/dependencies: Reliable artifact extraction (e.g., Reducto or equivalents); judge accuracy in domain-specific contexts; principle-of-least-privilege access.
- Agent training and finetuning with rubric supervision (sectors: AI vendors, ML ops)
- Use CC-BY dataset (prompts, rubrics, gold outputs, metadata) for supervised finetuning and RL with verifiers to improve planning and cross-application tool use.
- Products/workflows: “Rubric-driven curriculum,” “Pass@k-aware training loops.”
- Assumptions/dependencies: Compute availability; domain adaptation of tasks; careful treatment of closed-source model biases in grading.
- Academic research on agent reliability and evaluation (sectors: academia, standards bodies)
- Investigate capability vs. consistency (Pass@k vs. Passk), failure modes (timeouts, zero scores), and tool-use correlations with success.
- Products/workflows: Reproducible studies using Archipelago; new metrics and statistical tests (McNemar + BH correction).
- Assumptions/dependencies: Access to closed/open models; alignment between benchmark tasks and research scope.
- Policy and governance for claims verification (sectors: government, regulators, enterprise risk)
- Require APEX-style evidence for marketing claims about productivity; publish standardized performance disclosures (Pass@1, Pass@8, mean criteria score).
- Products/workflows: Procurement guidelines, “Agent Performance Disclosure” templates, audit checklists.
- Assumptions/dependencies: Agreement on benchmark representativeness; mitigation of judge self-preference; periodic revalidation.
- Education and workforce upskilling (sectors: higher education, corporate training)
- Use “worlds” as case-based labs in business, finance, and law curricula; evaluate students and human-agent collaboration via rubrics.
- Products/workflows: “Digital case labs,” “APEX coursework,” rubric-aligned assignments.
- Assumptions/dependencies: Curriculum mapping; safe, anonymized data; instructor familiarity with rubric grading.
- Human-in-the-loop triage of partial outputs (sectors: all knowledge work)
- Since agents often achieve partial credit, implement review UIs that highlight unmet criteria and guide humans to “finish the last mile.”
- Products/workflows: “Rubric-driven review pane,” “Criteria gap highlighter.”
- Assumptions/dependencies: Integrations with document/spreadsheet editors; training reviewers on rubric interpretation.
- Personal agent QA harness for professionals (sectors: daily knowledge work)
- Individuals adopt lightweight APEX-inspired rubrics for their own agent tasks; run multiple attempts (best-of-n) and gate acceptance on criteria checks.
- Products/workflows: “Personal rubric builder,” “Multi-run supervisor.”
- Assumptions/dependencies: Access to an agent runner and artifact extractor; basic rubric design skills.
Long-Term Applications
Below are use cases that require further research, scaling, integration, or maturation of agent reliability and consistency.
- Production-grade professional service agents (“APEX-certified”) (sectors: finance, law, consulting)
- Deploy cross-application assistants that consistently complete 1–2 hour tasks (DCF, comps, contract review, market sizing) with self-verification before handoff.
- Products/workflows: “APEX-certified assistants,” escalation protocols, integrated Calendar/Mail/Data Room workflows.
- Assumptions/dependencies: Higher Pass@1 and Passk, robust domain connectors (EHRs, SEC data, contract repositories), organizational buy-in.
- Enterprise “digital twins” for knowledge work (sectors: software/IT, data governance)
- Generate company-specific “worlds” that reproduce data rooms, tool stacks, and workflows for continuous eval, training, and safe dry-runs.
- Products/workflows: “Enterprise Sandbox Builder,” policy-compliant containerization, role-based access.
- Assumptions/dependencies: Privacy-preserving world generation; secure orchestration (Kubernetes/Modal); legal approvals.
- Agent SLAs and insurance products (sectors: enterprise procurement, insurance)
- Use Pass@k/Passk to define correctness SLAs, attach premiums, and price risk around agent execution variability.
- Products/workflows: “Agent Reliability Insurance,” SLA contracts referencing benchmark metrics.
- Assumptions/dependencies: Stable, widely accepted metrics; actuarial models; legal frameworks for liability.
- Regulatory standards and certification (sectors: standards bodies, government)
- Formalize APEX-style benchmarks for conformity assessment; certify systems that meet minimum reliability and safety bars across domains.
- Products/workflows: “Benchmark-based certification,” lab testing protocols, sector-specific extensions (healthcare, public sector).
- Assumptions/dependencies: Multi-stakeholder consensus; expanded coverage beyond investment banking/consulting/law; independent judging systems.
- Large-scale RL with verifiers to improve consistency (sectors: AI labs, model vendors)
- Train agents end-to-end against rubric-backed tasks to reduce doom-looping, optimize tool use, and increase consistency across runs.
- Products/workflows: “Verifier-in-the-loop RL,” tool-use curriculum, consistency regularizers.
- Assumptions/dependencies: Significant compute; robust telemetry; careful safety controls.
- Marketplace for tasks, worlds, and agent challenges (sectors: platforms, open research)
- Curate and monetize domain-specific worlds; reward agent improvements with public leaderboards and bounties.
- Products/workflows: “APEX Challenge Hub,” “Task/World Exchange.”
- Assumptions/dependencies: Quality control; governance; sustainable incentives; privacy-preserving task curation.
- Human-agent collaboration frameworks that operationalize partial credit (sectors: all knowledge work)
- Redesign workflows to accept partially correct outputs as building blocks, with rubric-guided handoffs and progressive verification.
- Products/workflows: “Criteria-aware collaboration pipelines,” “Progressive verification gates.”
- Assumptions/dependencies: UI/UX changes; organizational retraining; cultural acceptance of iterative agent outputs.
- Energy and sustainability management for AI agents (sectors: energy, finance)
- Convert token/step metrics into energy and cost footprints; set carbon budgets and optimize agents for “green runs.”
- Products/workflows: “Green Agent settings,” carbon-aware scheduling, cost-carbon dashboards.
- Assumptions/dependencies: Accurate token-to-energy mapping; model-level energy telemetry; enterprise ESG integration.
- Cross-domain extensions (healthcare, robotics, education tech)
- Apply the worlds/rubrics/judge methodology to EHR workflows, lab result synthesis, robotic task planning, or adaptive learning systems.
- Products/workflows: Domain-specific worlds (EHR sandbox, clinical guideline tools), safety verifiers, task-specific judges.
- Assumptions/dependencies: Domain data availability; stringent privacy/compliance; hardware/tool integrations for non-desktop tasks.
- Credentialing and assessment in education and professional licensing (sectors: higher ed, continuing education)
- Use APEX-like worlds to certify practitioner competence (human and human-agent teams), aligning assessments to real work artifacts.
- Products/workflows: “APEX-aligned credentials,” capstone evaluations with rubric judges.
- Assumptions/dependencies: Accreditation body acceptance; localized tasks; reliable judges across cohorts.
Glossary
- APEX-Agents: A benchmark for evaluating whether AI agents can perform long-horizon, cross-application professional tasks. "We introduce the AI Productivity Index for Agents (APEX-Agents), a benchmark for as- sessing whether AI agents can execute long- horizon, cross-application tasks..."
- APEX Survey: A survey of professionals used to inform the design of worlds and tasks in the benchmark. "This approach is inspired by findings from the APEX Survey (Section 2)..."
- Archipelago: Open-source infrastructure for running and evaluating AI agents in containerized environments. "Archipelago is open-source infrastructure for run- ning and evaluating AI agents against RL envi- ronments."
- Answer tokens: The subset of completion tokens that constitute the final answer produced by an agent. "Answer tokens are a subset of completion tokens."
- Baselining study: A validation step where independent experts execute tasks to check completeness, rubric fairness, and time estimates. "3.5. Baselining study"
- Benjamini-Hochberg correction: A multiple testing procedure that controls the expected false discovery rate. "A Benjamini-Hochberg correction con- trols the false discovery rate at 5%."
- Bootstrapping: A resampling method used to estimate confidence intervals for Pass metrics. "We compute 95% confidence intervals using task-level bootstrapping: we resample tasks with replacement (n = 480) and recompute the task-uniform mean over 10, 000 resamples."
- CC-BY license: An open license allowing redistribution and adaptation with attribution. "The APEX-Agents dataset is on Hugging Face with a CC-BY license.2."
- Compliance Program Review: A legal workflow assessing organizational compliance controls and policies. "Compliance Program Review"
- Confusion matrix: A table summarizing the judge model’s classification outcomes against ground truth. "Table 2: Confusion matrix for the judge model, eval- uated against human-labeled ground truth (n = 747 labels, based on n = 249 criteria)."
- Criterion: A self-contained, binary-gradable requirement in the rubric that must be met for task completion. "with each criterion graded independently by a judge model."
- DCF: Discounted Cash Flow, a valuation method projecting and discounting future cash flows. "Use the implied share price in the DCF model and diluted EPS..."
- Debt Model: A financial modeling workflow focused on debt structures and impacts. "Debt Model"
- Doom looping: An agent repeatedly using unproductive tools or steps, leading to timeouts. "Kimi K2. Thinking, which often doom loops, timing out 29.8% of trajectories."
- Due Diligence: A legal workflow for comprehensive review of documents and facts before transactions or litigation. "Due Diligence"
- EBITDA: Earnings Before Interest, Taxes, Depreciation, and Amortization—a common financial performance metric. "e.g., an updated EBITDA)."
- Edgar SEC: A data application providing access to U.S. SEC filings and market information. "Two investment banking worlds also have Edgar SEC, an application for data on Equities and Financial Markets..."
- EPS (diluted EPS): Earnings Per Share adjusted for potential dilution from securities like options or convertibles. "Use the implied share price in the DCF model and diluted EPS from the annual financials dated 12/23/2025."
- False discovery rate: The expected proportion of false positives among rejected hypotheses in multiple testing. "A Benjamini-Hochberg correction con- trols the false discovery rate at 5%."
- Fixed Income Markets: Markets for debt securities such as bonds and loans. "and an application for data on Fixed In- come Markets, adding 187 tools."
- Frontier agents: State-of-the-art AI agent models at the forefront of capabilities. "contributors selected from a pool of frontier agents (GPT-5, Claude Opus 4.5, Gemini 3. Pro)..."
- Gold outputs: Expert-produced correct answers used as references for grading tasks. "For each task, experts also created gold outputs."
- Grading target: A specification in the rubric indicating which artifact or output type to grade. "Each criterion also has a 'grading target', which specifies the type of output required by the prompt."
- Ground truth eval set: A labeled dataset produced by experts to validate the judge model’s accuracy. "we constructed a ground truth eval set of labels for 60 tasks (20 per job), comprising 249 criteria."
- Hugging Face: A platform hosting the open-source benchmark dataset. "The APEX-Agents dataset is on Hugging Face with a CC-BY license.2."
- Judge model: An LM used to automatically grade agent outputs against rubrics. "we use Gemini 3. Flash, with thinking set to low, as the judge."
- LBO: Leveraged Buyout, a transaction financed significantly with debt to acquire a company. "LBO"
- LiteLLM: A wrapper library to standardize API calls across different model providers. "LiteLLM is used as a wrapper to handle calls uniformly."
- McNemar's exact test: A statistical test for paired nominal data to compare two models’ pass/fail outcomes. "We use McNemar's exact tests to evaluate whether Pass@1 differences between agents are statistically significant."
- Merger Model: A financial workflow for modeling the effects of corporate mergers. "Merger Model"
- Model Context Protocol: A gateway standard through which multiple applications are exposed to agents. "exposes multiple applications through a unified Model Con- text Protocol gateway"
- Motion Drafting: A legal workflow preparing formal motions for court proceedings. "Motion Drafting"
- O*NET: Occupational Information Network codes classifying job roles. "including 58 financial and investment an- alysts (O*NET 13-2051), 77 management consul- tants (O*NET 13-1111), and 92 lawyers (O*NET 23-1011)."
- P/E ratio: Price-to-Earnings ratio, valuing a company by its share price relative to EPS. "Reply back to me with the P/E ratio for KVUE..."
- Pass8: Consistency metric indicating the agent produced a correct output on every one of eight attempts. "We also report Pass8, which assesses consistency by measuring whether the agent produces a correct output on ev- ery attempt out of eight."
- Passk: Consistency metric generalizing Pass8 to k attempts, estimated via sampling. "For k < 8, we estimate Passk per task by sampling without replacement from each agent's observed runs."
- Pass@1: Leaderboard metric; probability an agent meets all criteria in a single run. "The APEX-Agents leaderboard uses Pass@1, the proportion of tasks where the agents' outputs meet all criteria."
- Pass@8: Capability ceiling metric; whether an agent passes at least once across eight runs. "Beyond the leaderboard, we report Pass@8 as an indicative ceiling..."
- Positive-class F1: The harmonic mean of precision and recall for the positive class. "Accuracy is 98.5%, precision is 96.7%, recall is 98.1%, and Positive- class F1 is 97.4%."
- ReAct paradigm: An agent framework interleaving reasoning and acting in a loop with tools. "We use a looped toolbelt, following the ReAct paradigm: Reasoning and Acting are interleaved in a single loop."
- Reducto: A tool for extracting file contents used during grading. "The content of files is extracted using Reducto.4."
- Risk Assessment: A legal workflow identifying and evaluating potential legal or compliance risks. "Risk Assessment"
- SAM: Serviceable Addressable Market—the portion of TAM targeted by a company’s products/services. "Market Sizing, TAM, SAM"
- Sensitivity Analysis: An analysis assessing how outcome varies with changes in key assumptions. "Sensitivity Analysis"
- Sim-to-real gap: The performance difference between simulated evaluations and real-world execution. "existing agentic evals have a large sim-to-real gap..."
- TAM: Total Addressable Market—the overall revenue opportunity for a product or service. "Market Sizing, TAM, SAM"
- Trajectory tokens: Input tokens sent to the model per API call, including system prompt and context. "Token usage is split into trajectory tokens (tokens sent from Archipelago... to the agent per API call...)"
- Valuation Analysis: A financial workflow for determining the value of assets or companies. "Valuation Analysis"
Collections
Sign up for free to add this paper to one or more collections.