- The paper presents the TInR-U framework that internalizes tool knowledge by embedding dedicated tool tokens and using bidirectional knowledge alignment.
- It achieves an 18.13% improvement in Exact Match accuracy on out-of-domain tasks through a training pipeline combining supervised fine-tuning and reinforcement learning.
- The study demonstrates scalability by maintaining constant inference efficiency even as the tool inventory grows, simplifying internal tool recall.
Motivation and Context
Modern LLMs exhibit advanced reasoning and task-solving capabilities, but their performance degrades in scenarios requiring external tool utilization, such as dynamic knowledge updates or actionable interaction with diverse tool APIs. Traditionally, Tool-Integrated Reasoning (TIR) frameworks address this by supplying external tool documentation to LLMs at inference, but these approaches suffer from heterogeneous documentation, context length constraints, and severe inference inefficiency. The paper "TInR: Exploring Tool-Internalized Reasoning in LLMs" (2604.10788) investigates an alternative paradigm: Tool-Internalized Reasoning (TInR), with the central thesis of embedding tool knowledge and usage protocols directly into model parameters to obviate external documentation at inference.
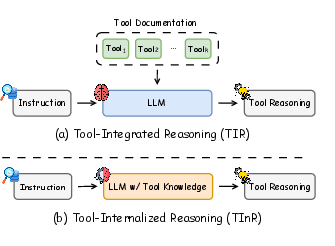
Figure 1: Conceptual comparison between Tool-Integrated Reasoning (TIR) and Tool-Internalized Reasoning (TInR), illustrating the internalization of tool knowledge within LLMs as opposed to reliance on external documentation.
TInR-U Framework: Technical Design and Training Pipeline
The proposed TInR-U framework is tailored to fulfill two primary requirements:
- Tool Internalization: Encoding fine-grained tool semantics—functionalities and invocation schema—into LLM parameters, leveraging a tokenization strategy that assigns unique tool tokens to each tool.
- Tool-Reasoning Coordination: Integrating internalized tool tokens with stepwise natural language reasoning, enabling adaptive tool selection and invocation during multi-turn problem-solving.
The three-phase training pipeline is as follows:
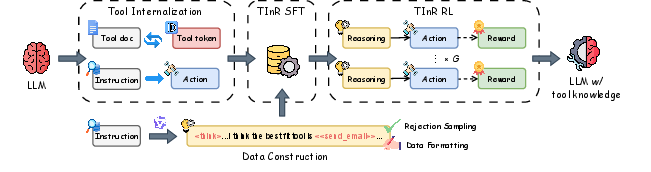
Figure 2: Schematic of the TInR-U pipeline, showing tool internalization (with bidirectional knowledge alignment), supervised warm-up, and reinforcement learning.
- Phase 1: Tool Internalization
- Expansion of model vocabulary to include dedicated tool tokens.
- Bidirectional Knowledge Alignment (BKA): Model learns to map documentation to tokens (memorization), reconstruct documentation from tokens (recall), and perform direct tool usage grounding. The combined loss LPhase 1=Lmemorization+αLrecall+βLusage ensures robust tool embedding.
- Phase 2: SFT Warm-up
- High-quality TInR datasets are generated by rejection sampling and data formatting (tool names replaced by tokens in reasoning traces), followed by supervised fine-tuning to align reasoning to internalized tool representations.
- Phase 3: RL for TInR
- Reward-driven optimization using Group Relative Policy Optimization (GRPO), incorporating structural and correctness rewards. The reward function combines trajectory format validation and Jaccard-based parameter correctness.
This architecture is model-agnostic and compatible with multiple backbone LLMs (Qwen, LLaMA, Mistral).
Empirical Evaluation and Ablation Studies
Experiments on ToolACE, xLAM, and BFCL datasets, across both in-domain and out-of-domain splits, yield strong quantitative gains for TInR-U. In out-of-domain tool calling, TInR-U attains a relative improvement of 18.13% on Exact Match over prior state-of-the-art baselines. In all settings, TInR-U surpasses both retrieval-based and agentic tool-use pipelines.
Ablation studies underscore the importance of BKA, RL optimization, and the multi-component internalization objectives. Removing BKA or RL induces substantial performance drops. Notably, the two-step tool call design (token assignment followed by parameter grounding) substantially simplifies internal tool recall and improves parameter accuracy.
Efficiency and Scalability
Inference efficiency is a critical concern for large-scale deployment, especially as toolset sizes increase. Comparisons between ToolRL (TIR method) and TInR-U reveal substantial scalability advantages:
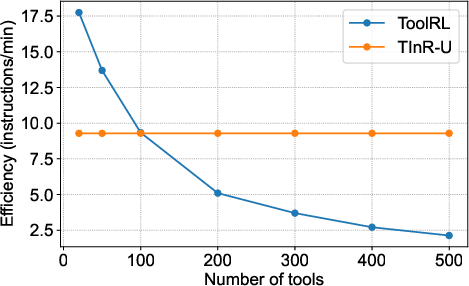
Figure 3: TInR-U maintains constant inference efficiency even as tool set size grows, outperforming ToolRL whose efficiency degrades with increasing prompt length.
TInR-U's architecture eliminates prompt expansion for tool documentation, enabling nearly constant throughput (instructions/min), making it highly suitable for industrial environments with extensive tool inventories.
Comparative and Theoretical Analyses
TInR-U's atomic token-based internalization outperforms semantic, numeric, and hierarchical indexing alternatives. Comparisons with DeepAgent (agent-style tool retrieval) confirm TInR-U’s superior accuracy and efficiency. Multi-turn and continual learning experiments show robust generalization and adaptability, with only mild performance decay on previous tasks after vocabulary extension and retraining.
Case studies evidence schema-consistent reasoning and minimal hallucination, highlighting the practical utility of bidirectional alignment in maintaining structural fidelity.
Implications and Future Directions
Theoretical analysis indicates that bidirectional alignment ensures semantic grounding at the embedding level and aligns tool discrimination with generative reasoning. The model’s insensitivity to hyperparameter selection and hardware configuration further attests to the robustness of TInR-U.
The practical implications are clear: models equipped with TInR-U can be deployed in settings with large or evolving tool inventories, with minimal inference latency and reduced pipeline complexity compared to retrieval or agentic systems.
On the theoretical side, TInR enables nuanced representation learning beyond mere discrimination, fostering deeper internal schema formation in LLMs.
Outstanding future research directions include:
- Extending TInR-U to multi-modal tool integration (vision, speech, robotics).
- Addressing more complex zero-shot tool update scenarios with stronger continual learning mechanisms.
- Investigating the limits of tool knowledge internalization vis-à-vis model capacity and catastrophic forgetting.
Conclusion
"TInR: Exploring Tool-Internalized Reasoning in LLMs" delivers a rigorous framework and empirical validation for internalizing tool knowledge within LLMs. TInR-U achieves state-of-the-art performance and efficiency, decisively solving several longstanding drawbacks of tool-integrated approaches. The work paves the way for scalable and robust LLM deployment in real-world agentic and tool-rich settings, while opening new avenues for multimodal and continual tool reasoning research.