- The paper introduces SimpleTIR, which filters void turns to prevent gradient explosions and misaligned credit assignment in multi-turn tool-integrated RL.
- It formulates multi-turn reasoning as a hierarchical MDP and employs Group Relative Policy Optimization to achieve stable, scalable training.
- Empirical results on challenging math benchmarks demonstrate state-of-the-art performance, highlighting robust design and diverse reasoning patterns.
The paper addresses the instability and performance collapse observed when training LLMs for multi-turn Tool-Integrated Reasoning (TIR) using Reinforcement Learning (RL). In TIR, LLMs interact with external tools (e.g., Python interpreters) to enhance their reasoning capabilities, particularly for tasks requiring computational accuracy or external knowledge. However, multi-turn TIR introduces a feedback loop where tool outputs, often out-of-distribution (OOD) relative to the model's pretraining data, are fed back into the model, compounding distributional drift and leading to the generation of low-probability tokens. This drift results in catastrophic gradient norm explosions and misaligned credit assignment, severely destabilizing RL training.
The authors formalize multi-turn TIR as a Hierarchical Markov Decision Process (MDP), with a high-level policy governing conversational turns and a low-level policy generating tokens within each turn. The unified policy is optimized using Group Relative Policy Optimization (GRPO), with feedback token masking to ensure correct credit assignment.
Analysis of Training Instability
The core technical insight is that multi-turn TIR amplifies the emergence of low-probability tokens due to OOD tool feedback. These tokens, when present in the model's generations, cause two major issues:
- Gradient Explosion: The policy gradient with respect to pre-softmax logits is highly sensitive to the importance sampling ratio and the probability assigned to sampled tokens. For negatively-rewarded trajectories, the importance ratio can become unbounded if the old policy assigned a very low probability to a token, leading to gradient spikes. Additionally, the probability-dependent term in the gradient norm sustains large gradients when the policy is confident but assigns low probability to the sampled token.
- Misaligned Credit Assignment: Sparse, terminal rewards penalize entire trajectories for failures in later turns, even if early turns exhibited correct reasoning. This dynamic discourages multi-turn strategies and causes the policy to collapse toward single-turn generations.
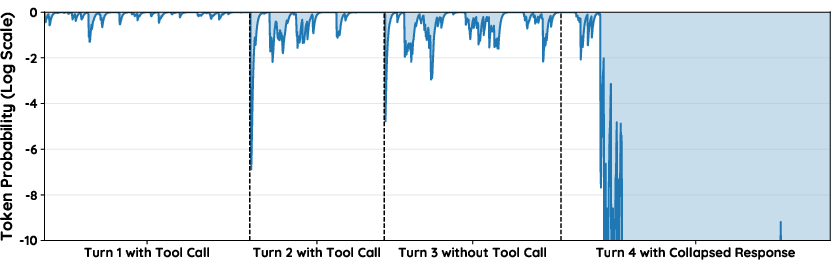
Figure 1: Visualization of token probabilities in a multi-turn TIR trajectory. Distributional drift from tool feedback in early turns leads to a collapse in token probabilities in later turns.
The SimpleTIR Algorithm
To address these issues, the authors introduce SimpleTIR, a trajectory filtering algorithm that stabilizes multi-turn TIR training. The key idea is to identify and filter out trajectories containing "void turns"—turns where the LLM response fails to produce either a complete code block or a final answer. Void turns are indicative of distributional drift and high generation stochasticity, often resulting from premature end-of-sequence tokens or incomplete responses.
During policy updates, SimpleTIR inspects each trajectory and masks the policy loss for any trajectory containing a void turn, effectively removing it from the batch before the GRPO update. This approach blocks harmful, high-magnitude gradients and corrects misaligned credit assignment by ensuring successful early turns are not penalized for later collapse.
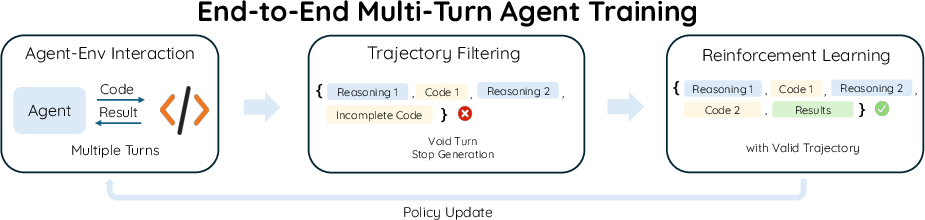
Figure 2: An overview of SimpleTIR. During the policy update, SimpleTIR identifies and filters out entire trajectories that contain a void turn—an LLM response that fails to produce either a complete code block or a final answer.
Implementation details include avoiding chat templates to prevent OOD special tokens, prepending tool outputs with a standardized prefix, and strictly terminating LLM generation after a complete code block is formed.
Empirical Results
SimpleTIR is evaluated on challenging mathematical reasoning benchmarks (AIME24, AIME25, Math500, Olympiad, AMC23, Hmmt 25) using the Qwen2.5-7B and Qwen2.5-32B base models. The method achieves state-of-the-art performance among Zero RL approaches, notably elevating the AIME24 score from a text-only baseline of 22.1 to 50.5 for Qwen2.5-7B. Ablation studies confirm that alternative filtering criteria (high importance ratio, low token probabilities) fail to resolve instability, while void turn filtering in SimpleTIR yields stable training curves and superior scores.
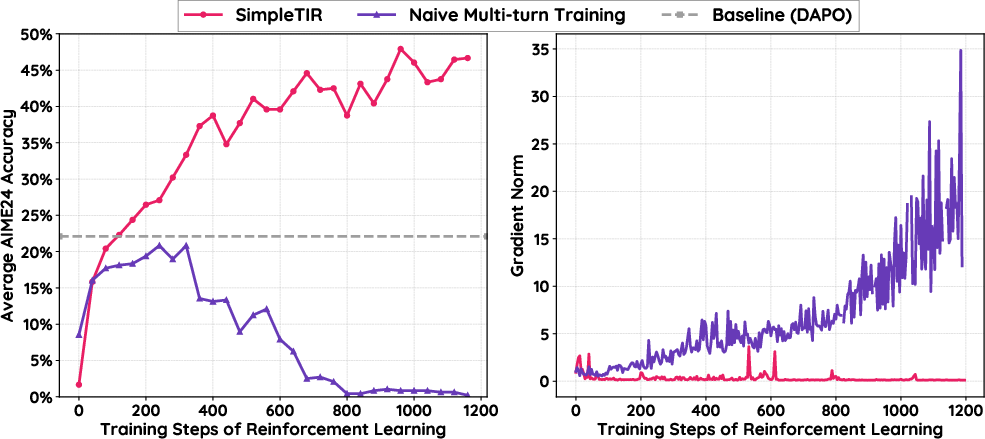
Figure 3: Starting from Qwen2.5-7B base model, the training dynamics of SimpleTIR are highly stable, with well-behaved gradient norms and clear performance gains over baselines.
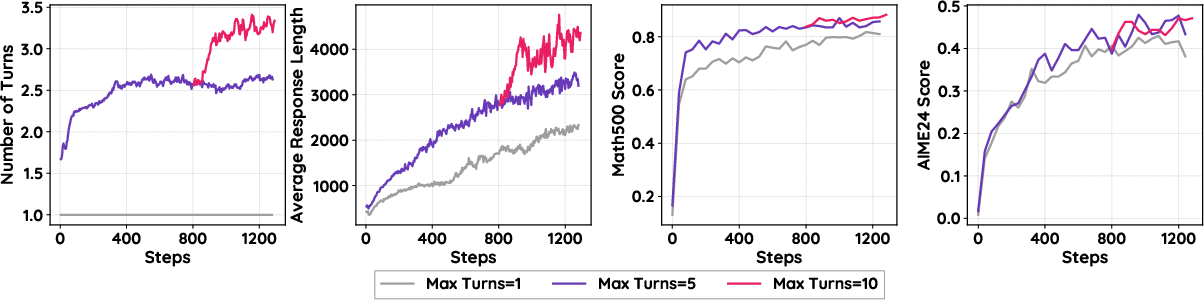
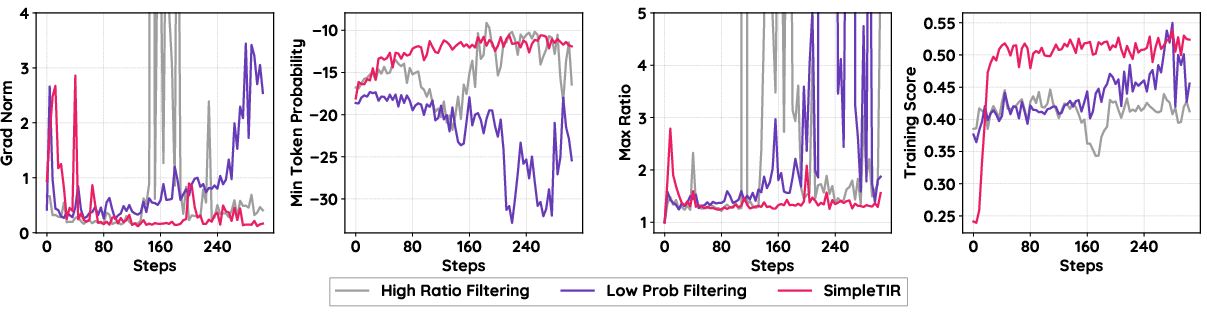
Figure 4: Training curves for SimpleTIR with different maximum number of turns. Scaling the number of interaction turns improves performance and response length for certain tasks.
Emergence of Diverse Reasoning Patterns
A notable advantage of SimpleTIR under the Zero RL paradigm is the emergence of diverse and sophisticated reasoning patterns, such as cross-validation, progressive reasoning, and self-correction. Unlike cold-start SFT approaches, which constrain the model to predefined strategies, SimpleTIR encourages the model to discover novel behaviors by reinforcing useful patterns from pretraining.
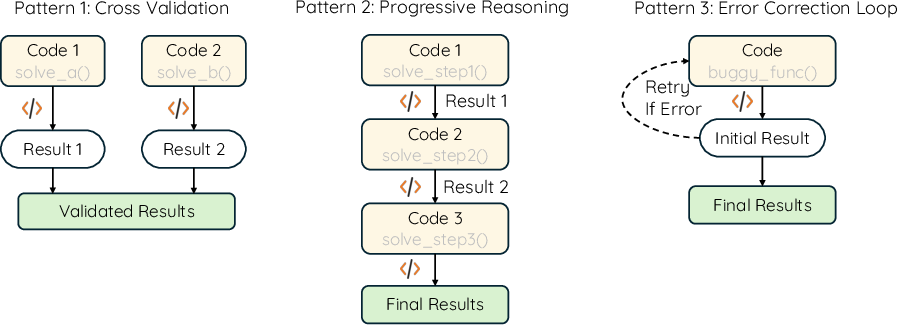
Figure 5: Demonstration of three reasoning patterns observed in responses generated by SimpleTIR.
Quantitative analysis shows that SimpleTIR-32B exhibits higher frequencies of progressive reasoning and error correction compared to ReTool, substantiating the claim that Zero RL with TIR preserves greater diversity in reasoning strategies.
Implementation Considerations
- Computational Requirements: Training requires highly parallelized code execution environments (e.g., sandbox fusion) to handle large batch sizes and long-context rollouts.
- Scalability: The method scales with the number of interaction turns, but practical limits (e.g., 10 turns) are imposed due to compute and memory constraints.
- Deployment: SimpleTIR is plug-and-play and can be integrated into existing RL training pipelines with minimal modifications. The trajectory filtering rule is agnostic to the underlying RL algorithm and orthogonal to other stabilization techniques (entropy regularization, IS ratio control).
- Limitations: The void turn heuristic is tailored to multi-turn TIR and may not generalize to other domains. Rollout efficiency and asynchronous reward calculation remain open challenges.
Theoretical and Practical Implications
The work provides a principled solution to the instability of multi-turn TIR RL, demonstrating that targeted trajectory filtering can enable stable, scalable, and diverse reasoning in LLM agents without reliance on human-annotated data. The empirical results support the theoretical analysis of gradient dynamics and credit assignment, and the methodology is extensible to other tool-use scenarios.
Future developments may focus on generalizing the void turn heuristic, improving rollout efficiency, and exploring fully asynchronous RL pipelines for agentic LLMs. The approach also motivates further research into credit assignment and distributional shift mitigation in hierarchical RL for LLMs.
Conclusion
SimpleTIR presents a robust framework for end-to-end RL training of multi-turn TIR agents, achieving stable learning dynamics and strong performance on mathematical reasoning tasks. By filtering trajectories with void turns, the method directly addresses the root causes of instability in Zero RL settings and fosters the emergence of diverse reasoning behaviors. These results highlight the potential of RL-driven, tool-integrated LLMs for scalable and reliable multi-turn reasoning, with implications for future agentic AI systems.