Teaching Thinking Models to Reason with Tools: A Full-Pipeline Recipe for Tool-Integrated Reasoning
Abstract: Tool-integrated reasoning (TIR) offers a direct way to extend thinking models beyond the limits of text-only reasoning. Paradoxically, we observe that tool-enabled evaluation can degrade reasoning performance even when the strong thinking models make almost no actual tool calls. In this paper, we investigate how to inject natural tool-use behavior into a strong thinking model without sacrificing its no-tool reasoning ability, and present a comprehensive TIR recipe. We highlight that (i) the effectiveness of TIR supervised fine-tuning (SFT) hinges on the learnability of teacher trajectories, which should prioritize problems inherently suited for tool-augmented solutions; (ii) controlling the proportion of tool-use trajectories could mitigate the catastrophic forgetting of text-only reasoning capacity; (iii) optimizing for pass@k and response length instead of training loss could maximize TIR SFT gains while preserving headroom for reinforcement learning (RL) exploration; (iv) a stable RL with verifiable rewards (RLVR) stage, built upon suitable SFT initialization and explicit safeguards against mode collapse, provides a simple yet remarkably effective solution. When applied to Qwen3 thinking models at 4B and 30B scales, our recipe yields models that achieve state-of-the-art performance in a wide range of benchmarks among open-source models, such as 96.7% and 99.2% on AIME 2025 for 4B and 30B, respectively.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI “thinking models” to use tools (like a Python calculator) while they reason, instead of only thinking in words. The authors show a full recipe for how to train such models so they know when to think in text, when to call a tool, and how to mix the two without forgetting their original skills.
What questions did the researchers ask?
They focused on simple, practical questions:
- How do we get a strong step-by-step thinking model to naturally use tools during its reasoning, not just at the very end?
- How do we keep its original no-tool reasoning skills from getting worse while it learns tool use?
- What training steps and settings make this learning stable and effective?
- How can we choose the right examples and the right moment to switch from copying a teacher (supervised learning) to practicing with a score (reinforcement learning)?
How did they study it?
They built a “full-pipeline recipe,” which is a careful plan from data collection all the way to final training. Here’s the idea in everyday terms:
Key ideas and terms in plain language
- Thinking model: An AI that solves problems step by step in text (like explaining its work).
- Tool: A helper the model can call, such as a Python runner, to do exact calculations, try out small cases, or search through possibilities.
- Interleaved reasoning: Switching between writing out thoughts and running tools multiple times during a solution, like a student who alternates between notes and a calculator.
- Supervised Fine-Tuning (SFT): Learning by copying from a “teacher” model’s example solutions.
- Reinforcement Learning with Verifiable Rewards (RLVR): Practice where the model tries to solve problems and gets a clear score (right/wrong), then learns from that feedback.
- pass@k: Letting the model try k times on the same problem and counting if any try is correct.
- Catastrophic forgetting: When learning a new skill (tool use) causes the model to forget an old skill (text-only reasoning).
- Stateful sandbox: A coding space where variables and results “stick around” across tool calls, like a notebook where you keep your work instead of starting from zero each time.
Step 1: Data engineering (picking good teachers and examples)
- Choose a teacher with a learnable tool style: They compared two advanced teacher AIs. One used many short, simple code snippets often; the other used fewer, long programs. The short-and-often style was easier for a smaller student model to copy and led to better learning.
- Ask the teacher to solve the right problems: They picked “tool-advantaged” problems—puzzles where tool use truly helps more than text-only thinking. This nudged the student to see when tools are genuinely useful.
- Mix tool and non-tool examples: If the student sees only tool-based solutions, it may start “pretending” to run code in text and waste tokens. Mixing in plain text solutions keeps its text-only skill sharp.
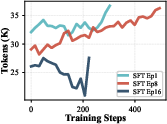
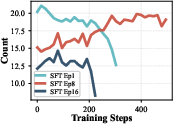
- Filter out overly long examples: Super long teacher answers can teach the wrong lesson (“longer is better”). Cutting them helped the student focus on substance, not length.
Step 2: Coordinating SFT and RL (when to switch)
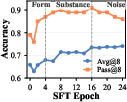
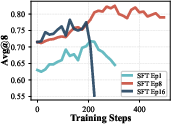
During SFT, the model’s learning goes through three phases:
- Form: It learns the format (how to call tools) but not yet why or when, so results can get worse and responses get too long.
- Substance: It starts using tools for real progress; accuracy rises.
- Noise: It begins overfitting to teacher quirks (like copying length), and improvements stall or drop.
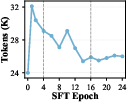
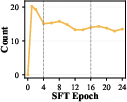
They watched two simple signals—pass@k and response length—to pick the best checkpoint to hand over to RL: late enough to get substance, but early enough to avoid noise.
Step 3: Stable RL training (practice with a score)
- Use hard problems: They trained on tough, competition-level math where text-only often fails, so the model feels a real need to call tools.
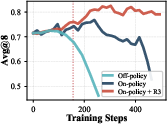
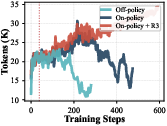
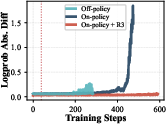
- Keep training stable: They used “on-policy” updates (learn from the exact attempts you just made) and aligned training with how the model behaves during solving (so it doesn’t get confused by mismatched data). This prevented the training from collapsing.
- No “tool bonus” trick: They didn’t bribe the model to use tools with extra reward. Instead, success (correct answers) naturally encouraged smart tool use.
What did they find, and why does it matter?
Here are the main takeaways and their importance:
- Naively turning on tools can hurt: If you just give a thinking model a code tool, it may barely use it—or use it at the wrong time—and performance can drop. Training the policy of when and how to use tools is essential.
- The teacher’s style matters a lot: Small, frequent code snippets were easier to learn and led to better, shorter, and more reliable solutions than rare, giant programs.
- Mixing tool and no-tool examples prevents forgetting: This keeps the model good at both.
- Watch pass@k and length, not just loss: These give a truer picture of readiness for RL and help avoid overfitting to superficial patterns.
- Stable RL is crucial: On-policy training and aligning practice with learning stabilized tool use over multiple turns.
- Big performance gains: Their trained models, called Trice-4B and Trice-30B, reached top results on math benchmarks (for example, about 96.7% and 99.2% on AIME 2025 with tools). The tool-using 30B model even beat much larger text-only reasoning models on tough tasks.
- More efficient answers: With tools, the model often solves problems with fewer tokens because code can compress long arithmetic or systematic checks into short snippets.
- Code as a “thinking aid,” not just a calculator: The model used code to explore patterns, test guesses, and search through cases—not only to compute final numbers.
- Transfers beyond math: Even though they trained on math, the interleaved reasoning habit improved results in science, coding, and knowledge tasks.
What’s the bigger impact?
- Smarter, more reliable problem solving: Models that know when to think and when to compute can tackle harder tasks with fewer mistakes.
- Better small models: A smaller model plus tools can outperform bigger models that only think in text, which can reduce costs and make powerful reasoning more accessible.
- Practical training recipe for others: The paper gives a clear, tested plan for building tool-using reasoning models without breaking their original skills.
- Broader use beyond math: The same approach can help in science, engineering, and programming—anywhere careful logic plus precise computation is needed.
In short, this work shows how to turn a strong “word thinker” into a flexible “thinker-with-tools,” and how to do it safely and effectively so the model becomes both smarter and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that future work could address:
- Generality beyond Python: The recipe is evaluated with a single stateful Python sandbox; it remains unclear how well it transfers to other tool types (retrieval, CAS/proof assistants, SMT solvers, web tools) and to heterogeneous multi-tool settings.
- Multi-tool orchestration: There is no study of tool selection, ordering, or scheduling policies when multiple tools are available, nor how to coordinate persistent state across tools.
- Gating policy quality: The work does not quantify or explicitly learn a gating policy for when to invoke tools vs. continue in text; metrics and training signals to calibrate “when to call” are missing.
- Robustness to tool failures: The system’s behavior under runtime errors, non-deterministic outputs, version differences (e.g., Python libraries), or sandbox outages is not analyzed; recovery and fallback strategies are unspecified.
- Security and safety of code execution: Sandbox security guarantees, resource limits (CPU, memory, I/O), and defenses against malicious or pathological code are not discussed.
- Reward design beyond verifiable math: The outcome-only verifiable reward works for math answers; it is unclear how to extend to tasks with fuzzy, delayed, or unverifiable objectives (e.g., scientific writing, open-ended coding).
- Sample/compute efficiency of RL: The need for fully on-policy updates and rollout routing replay suggests nontrivial compute overhead; the sample efficiency and cost–performance trade-offs are not quantified.
- Theoretical understanding of off-policy tool returns: While train–inference mismatch is observed, there is no formal analysis of why tool-return tokens destabilize RL or how to correct for this (e.g., off-policy estimators, credit assignment schemes).
- Alternative RL algorithms and objectives: Only GRPO-style on-policy training is explored; the effectiveness of PPO variants, off-policy RL, DPO/IPO-style objectives, or hybrid RLHF/RLVR setups remains unknown.
- Reward hacking and verifier robustness: The potential for exploiting answer verifiers (formatting, loopholes) or for “gaming” tool usage is not systematically stress-tested.
- Teacher dependence and generality: Teacher selection is based on two models and one interaction style; it is unclear how sensitive results are to teacher family, quality, coding style, or domain, and how to automate “learnability”-aware teacher selection.
- Tool-advantaged prompt selection bias: Filtering for tool-advantaged problems may bias the training/evaluation distribution; how this affects generalization to tasks where tools offer marginal gains is not assessed.
- Data efficiency of prompt selection: The method requires multiple with/without-tool rollouts per problem; a cheaper proxy for tool-advantage prediction or an online selection mechanism is not explored.
- Mixing ratio of TIR and text-only trajectories: Only a few compositions are reported; a principled or adaptive schedule for preventing catastrophic forgetting and optimizing dual-mode performance is missing.
- Overlong trajectory filtering: The 16K cutoff improves results, but there is no ablation on thresholds, length-aware curricula, or methods that disentangle “length-as-noise” from genuinely long but high-quality reasoning.
- SFT early stopping/selection: Pass@k and length guide checkpoint choice, but an automatic, generalizable criterion (with confidence intervals, variance control) is not formalized; portability of this heuristic to other domains remains untested.
- Train–inference mismatch diagnostics: The paper measures mismatch but does not propose standardized metrics or interventions (e.g., KL constraints on tool-return contexts, token-level weighting) to systematically reduce it.
- Stateful vs. stateless environments: While teacher styles differ, there is no controlled ablation of statefulness at inference for the student (e.g., portability to stateless executors or constrained state capacity).
- Error taxonomy and failure modes: A systematic analysis of common failure patterns (e.g., rounding/flooring bugs, mis-specified loops, stale state reuse, silent verifier pass) and targeted mitigations is absent.
- Resource-aware policies: The approach assumes generous limits (80K tokens, 128 calls); how to learn policies that adapt to tighter budgets (latency, tool-call caps, memory) is not studied.
- Real-world breadth and depth: Evaluation is math-heavy; transfer to practical domains (data analysis notebooks, scientific computing pipelines, system diagnostics) and long-horizon, multi-step projects is limited.
- Cross-session memory and persistence: The sandbox is per-problem; mechanisms for persistent memory across tasks or sessions (e.g., caching results, learned libraries) are not explored.
- Human interpretability and debugging: There is no user-centric evaluation of whether interleaved traces are interpretable, debuggable, or amenable to human-in-the-loop correction.
- Multilingual and multimodal TIR: The recipe’s applicability to non-English tasks or to vision/code hybrids (e.g., chart parsing → code) is not evaluated.
- Model scale boundaries: Results are shown at 4B and ~30B; behavior at sub-4B and >70B scales, and the interaction with native tool-use priors in larger models, remain open.
- Reproducibility gaps: Models and datasets are “coming soon” and many training hyperparameters, compute budgets, and implementation details (router configurations, rollout filters) are not yet available.
- Data leakage and contamination: Given competition-style benchmarks, safeguards against training overlap or indirect contamination (via teacher or public corpora) are not documented.
- Sandbox portability and determinism: Sensitivity to Python versioning, floating-point differences, library availability, and platform-specific behavior is unreported.
- Inference-time efficiency: Latency, parallelization of tool calls, and batching strategies for practical deployment are not quantified or optimized.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can leverage the paper’s TIR recipe and findings today, especially where secure code execution and verifiable evaluation are already available.
- Robust code-assistants that verify as they generate
- Sectors: software, DevOps, data engineering
- What it does: An assistant interleaves NL reasoning with short, stateful code snippets to explore, prototype, test, and verify during generation (e.g., generate a function, run unit tests, adjust based on outputs).
- Tools/workflows: IDE plug‑ins with a stateful Python sandbox; “interleaved reasoning engine” that preserves variables/functions across calls; response-length control; continuous pass@k sampling for higher correctness.
- Assumptions/dependencies: Secure, isolated execution (containers/sandboxes); latency tolerance for multiple short tool calls; organization policies for code execution.
- Data analysis copilots that compute, search, and validate
- Sectors: finance, operations, marketing analytics, healthcare research (non-clinical), scientific computing
- What it does: Assist with exploratory analysis by running small computations, enumerating cases, and validating hypotheses (e.g., portfolio back-of-the-envelope computations, A/B data checks, power analyses).
- Tools/workflows: Notebook integrations (Jupyter, VS Code) with persistent sandbox state; trajectories combining natural language and code; outcome-only verifiable checks on reporting steps.
- Assumptions/dependencies: Data access controls; reproducible verifiers for numeric/stat outputs; governance for code execution on enterprise data.
- More reliable STEM tutors and graders with live computation
- Sectors: education (K–12, higher ed, online learning)
- What it does: Tutors solve and explain math/physics/CS problems using code to compute examples, verify conjectures, and shorten error-prone hand calculations; graders verify student steps via executable checks.
- Tools/workflows: LMS/learning app integration with a stateful interpreter; mixed TIR/text SFT to retain explanations without over-reliance on code; length filters to prevent overly long outputs.
- Assumptions/dependencies: Safe runtime environments for students; clear boundaries on tool use to avoid “give-away” solutions; content-appropriate verifiers.
- Compliance-friendly analytics assistants with verifiable outputs
- Sectors: finance, auditing, public sector digital services
- What it does: Generate analyses with embedded, reproducible code cells and verifiable reward checks (e.g., reconciliation, sensitivity analysis) to produce auditable reasoning trails.
- Tools/workflows: RL with verifiable rewards (RLVR) on tasks with deterministic checks; exported “reasoning notebooks” that serialize code, outputs, and final answers.
- Assumptions/dependencies: Deterministic/verifiable scoring functions for tasks; audit logging for code/outputs; sandbox security.
- Internal model training improvements for AI teams
- Sectors: AI/ML platforms, model providers, large enterprises building LLMs
- What it does: Adopt the paper’s pipeline to teach in-house models interleaved tool use without catastrophic forgetting of text reasoning.
- Tools/workflows: Teacher selection for “learnable” tool patterns (high-frequency, lightweight snippets); tool-advantaged prompt mining; mixing TIR and text-only SFT data; length filtering; RL with on-policy updates and rollout routing replay (R3).
- Assumptions/dependencies: Access to a capable teacher (or equivalent OSS teacher trajectories); compute for SFT/RL; verifiable reward design and hard-task datasets.
- Safer, more stable RL pipelines for tool-using agents
- Sectors: agent platforms, enterprise automations
- What it does: Reduce RL collapse in multi-turn tool settings by initializing from an “RL-ready” SFT checkpoint, using outcome-only verifiable rewards, on-policy updates, and R3 to align training and inference.
- Tools/workflows: Pass@k and response-length diagnostics for checkpoint selection; on-policy GRPO-like updates; R3 integration.
- Assumptions/dependencies: Tasks with verifiable outcomes; ability to run on-policy training (higher compute/latency); monitoring for train–inference mismatch.
- Knowledge work assistants that avoid “text-only” arithmetic errors
- Sectors: consulting, legal research, procurement, general office productivity
- What it does: Drafts analyses (budgets, schedules, estimates) while offloading computations and combinatorial enumerations to code, reducing common calculation errors.
- Tools/workflows: Spreadsheet/BI integrations; interleaved code calls for calculators/enumerators; length constraints to keep outputs concise.
- Assumptions/dependencies: Integration with business tools; guardrails for sensitive data; user education on when and how tools are invoked.
Long-Term Applications
These use cases require further research, domain-specific integrations, scaling, or additional safeguards before broad deployment.
- Domain-specialized TIR agents across tooling ecosystems
- Sectors: healthcare (clinical decision support), biotech, engineering design, legal tech
- What it could do: Interleave reasoning with domain tools (e.g., solvers, EHR query APIs, cheminformatics libraries, CAD/CAE simulators) to explore hypotheses, verify rules, and run algorithmic searches.
- Tools/workflows: Stateful, policy-aware tool orchestration beyond Python; verifiable domain-specific reward functions; mixed-mode SFT (text + domain tools).
- Assumptions/dependencies: Regulatory approval (e.g., healthcare); rigorous validation and audit; high-fidelity simulators/verifiers; secure data access.
- Planning and optimization copilots that explore large solution spaces
- Sectors: supply chain, logistics, manufacturing, energy systems
- What it could do: Use code-critical algorithmic search (e.g., heuristics/metaheuristics) within the reasoning loop for scheduling, routing, or dispatch; verify candidate plans with simulators.
- Tools/workflows: Stateful optimization libraries; environment simulators with persistent state; RLVR tuned for safety constraints.
- Assumptions/dependencies: Reliable and fast simulators; cost/latency budgets for many tool calls; safety constraints encoded as verifiable checks.
- Robotics and embodied agents with verifiable tool-integrated reasoning
- Sectors: robotics, warehousing, field operations
- What it could do: Interleave task planning with simulator execution and sensor abstractions; verify plans via simulation before real-world execution.
- Tools/workflows: Bridge to robot control stacks and physics simulators; outcome-based verifiable rewards (e.g., goal achievement); on-policy RL to reduce distributional shift.
- Assumptions/dependencies: Real-time constraints; sim-to-real fidelity; strong safety and override mechanisms.
- Policy and governance frameworks for “verifiable reasoning trails”
- Sectors: public sector, regulated industries
- What it could do: Standardize requirements that AI systems produce executable, auditable reasoning artifacts (code + outputs) with verifiable rewards for critical decisions.
- Tools/workflows: Certification suites for RLVR systems; standardized sandboxing and logging; conformance tests for train–inference mismatch and stability.
- Assumptions/dependencies: Consensus on standards; availability of domain verifiers; privacy/security controls for logs and code.
- Curriculum and assessment that teach “thinking with tools”
- Sectors: education, workforce upskilling
- What it could do: Incorporate interleaved reasoning with code into teaching and testing (students or professionals solve problems using short code snippets within explanations).
- Tools/workflows: Interactive textbooks and exams with stateful execution; automated assessment via verifiable checks; mixed TIR/text-only pedagogy.
- Assumptions/dependencies: Infrastructure in classrooms/platforms; fair assessment design; preventing misuse or over-reliance on code.
- Research automation and AutoML-style “experimental loops”
- Sectors: R&D labs, quantitative research, bioinformatics
- What it could do: Agents that propose hypotheses, write code, run experiments, evaluate with verifiable metrics, and iterate—keeping an auditable chain of interleaved reasoning and execution.
- Tools/workflows: Pipelines integrating compute backends (e.g., cluster notebooks), data governance, and RLVR; checkpoint selection via pass@k and length metrics.
- Assumptions/dependencies: Task verifiers for research metrics; robust sandboxing and resource governance; human-in-the-loop oversight.
- Infrastructure for “stateful tool fabrics” and low-latency TIR at scale
- Sectors: AI platforms, cloud providers
- What it could do: Provide managed, secure, persistent sandboxes and routing services optimized for frequent, lightweight code calls; telemetry for train–inference alignment.
- Tools/workflows: Serverless sandboxes with state preservation; R3-aware training toolkits; pass@k-aware serving; budget-aware routing.
- Assumptions/dependencies: Cost-effective isolation at scale; strong security; developer ergonomics for integrating many tools.
- Safety and alignment methods that prefer verifiable outcomes over style
- Sectors: AI safety, model governance
- What it could do: Use outcome-only reward shaping with hard, verifiable tasks to reduce reward hacking and format overfitting; standardized checkpoints that balance “substance over form”.
- Tools/workflows: Libraries implementing on-policy RL, R3, and verifiable rewards; diagnostics for “form–substance–noise” SFT phases; guardrails against mode collapse.
- Assumptions/dependencies: Availability of verifiable tasks in target domains; compute for on-policy RL; broad measurement frameworks.
- Privacy-preserving, on-prem TIR for SMEs and sensitive workloads
- Sectors: healthcare providers, banks, defense/aerospace, legal firms
- What it could do: Deploy smaller Trice-style models (e.g., ~4B) on-prem that interleave reasoning with local sandboxes, enabling secure analytics and coding assistance without external data transfer.
- Tools/workflows: Lightweight stateful runtimes; curated tool-advantaged datasets for fine-tuning; length filters for predictable resource use.
- Assumptions/dependencies: Sufficient on-prem compute; secure isolation; curated domain datasets and verifiers.
Notes on feasibility across applications:
- Cross-domain transfer is promising but still benefits from domain-specific tools and verifiers; the paper’s gains were achieved with math-centric training.
- Reliable, secure sandboxes and deterministic/verifiable metrics are critical; many domains lack mature verifiers.
- On-policy RL and R3 improve stability but increase training and inference costs; organizations must budget for higher latency and compute.
- The authors note models and datasets are “coming soon”; immediate adoption may rely on replicating the recipe with available teachers and internal data.
Glossary
- advantage: In policy-gradient RL, a baseline-adjusted signal indicating how much better a sampled action (token) performed than expected. Example: "assigning an advantage to generated tokens"
- autoregressive error accumulation: Compounding mistakes across sequential token generation, especially in long code or CoT, leading to cascading failures. Example: "more vulnerable to autoregressive error accumulation"
- catastrophic forgetting: Abrupt loss of previously learned capabilities when fine-tuning on new data that overemphasizes a different mode. Example: "catastrophic forgetting of text-only reasoning capacity"
- cross-mode negative transfer: Harmful interference where learning in one mode (e.g., tool use) degrades performance in another (e.g., pure text reasoning). Example: "a cross-mode negative transfer"
- delayed-code pattern: A tool-use behavior where code is invoked only at the end as a verifier rather than interleaved during reasoning. Example: "delayed-code pattern"
- distributional shift: A mismatch between training and inference data distributions that destabilizes learning or performance. Example: "avoid additional distributional shifts"
- GRPO: A group-normalized REINFORCE-style policy-gradient method that normalizes rewards across multiple sampled responses to reduce variance. Example: "group-normalized variants such as GRPO"
- long-CoT: Long chain-of-thought supervision that encourages extended multi-step reasoning, but can introduce length-related issues. Example: "long-CoT SFT"
- mode collapse: Degenerate behavior in training where the model produces low-diversity or trivial outputs regardless of input. Example: "explicit safeguards against mode collapse"
- off-policy: Learning from trajectories that are not generated by the current policy, increasing instability in settings with tool feedback. Example: "off-policy updates"
- on-policy: Learning from trajectories sampled by the current policy, reducing mismatch and improving stability in TIR RL. Example: "fully on-policy training"
- outcome-based rewards: Reward signals that depend only on the final result (e.g., correctness) rather than intermediate formatting or steps. Example: "leverage outcome-based rewards only"
- outcome-only rewards: A strict form of outcome-based rewards that ignore process signals and reward only the final verified outcome. Example: "Under outcome-only rewards"
- pass@k: A metric measuring whether at least one of k sampled responses is correct; reflects exploration headroom and training progress. Example: "optimizing for pass@k and response length"
- policy-gradient methods: RL algorithms that adjust policy parameters in the direction that increases expected reward based on sampled trajectories. Example: "Policy-gradient methods estimate its gradient"
- REINFORCE: A classic policy-gradient algorithm that uses sampled returns to update the policy without a value function. Example: "With only a trajectory-level reward, REINFORCE can use"
- RL with verifiable rewards (RLVR): Reinforcement learning where rewards are computed by an external verifier that can check solution correctness. Example: "RL with verifiable rewards (RLVR)"
- rollout: A complete sampled trajectory (reasoning and tool interactions) from prompt to termination used for evaluation or training. Example: "tool-enabled rollouts"
- rollout routing replay (R3): A stabilization technique that reuses inference-time routing distributions during training to reduce mismatch. Example: "rollout routing replay (R3)"
- stateful sandbox: An execution environment that preserves variables, imports, and intermediate computations across tool calls. Example: "We use a stateful sandbox"
- supervised fine-tuning (SFT): Training a model on labeled trajectories to imitate desired behavior before RL. Example: "TIR supervised fine-tuning (SFT)"
- tool-advantaged problems: Tasks where access to tools (e.g., code execution) provides a clear performance advantage over pure text reasoning. Example: "tool-advantaged problems"
- tool-integrated reasoning (TIR): Interleaving natural-language reasoning with executable tool calls to enhance reliability and precision. Example: "Tool-integrated reasoning (TIR)"
- tool-return tokens: Tokens representing outputs or errors returned by an external tool, which the model must condition on despite being off-policy. Example: "tool-return tokens"
- trainâinference mismatch: A disparity between probabilities or behaviors during training versus inference that can destabilize RL. Example: "trainâinference mismatch"
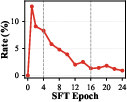
- truncation rate: The fraction of responses cut off by length limits, often signaling inefficient or looping reasoning. Example: "the truncation rate increases"
Collections
Sign up for free to add this paper to one or more collections.

