- The paper presents ToolOmni, a unified agentic framework that decouples proactive retrieval from grounded execution to address open-world tool use challenges.
- It implements a two-stage training process combining supervised fine-tuning with GRPO-based reinforcement learning, achieving 78.29% NDCG and 54.13% SoPR.
- The approach demonstrates robust generalization to unseen tools and adversarial noise through iterative, decoupled optimization, outperforming existing retrieval and execution methods.
Motivation and Problem Landscape
The proliferation of large-scale, evolving tool repositories has rendered traditional approaches for tool-use reasoning by LLMs—including static embedding-based retrieval and parameter memorization—insufficient for open-world scenarios. Embedding retrieval models exhibit low accuracy due to superficial semantic matching when faced with massive tool sets, while parametric memory techniques are inflexible, cannot generalize to unseen tools, and require costly retraining upon repository updates. The paper introduces ToolOmni, a unified agentic framework that decouples proactive retrieval and grounded execution within an iterative reasoning loop to robustly enable open-world tool use.
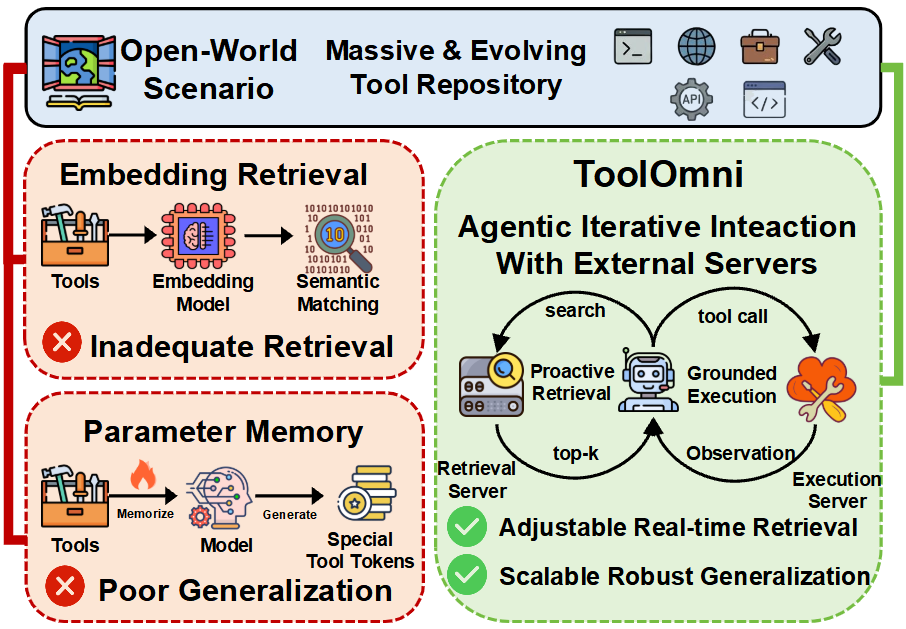
Figure 1: Motivation for ToolOmni—embedding retrieval and parametric memory fail for massive and evolving toolsets, whereas ToolOmni couples proactive retrieval and grounded execution for effective open-world tool use.
Framework Architecture
ToolOmni operates in two distinct phases. During Proactive Retrieval, the agent iterates with a retrieval server, dynamically curating relevant tool candidates via multi-turn interactions. This allows contextual query adaptation, efficient search refinement, and task-specific tool selection. In the Grounded Execution phase, the agent leverages the finalized tool set for reasoning and sequential tool invocation, generating answers grounded in the retrieved documentation. The decoupling facilitates independent reward optimization and rigorous process supervision, mitigating the interference between retrieval and execution reward signals.
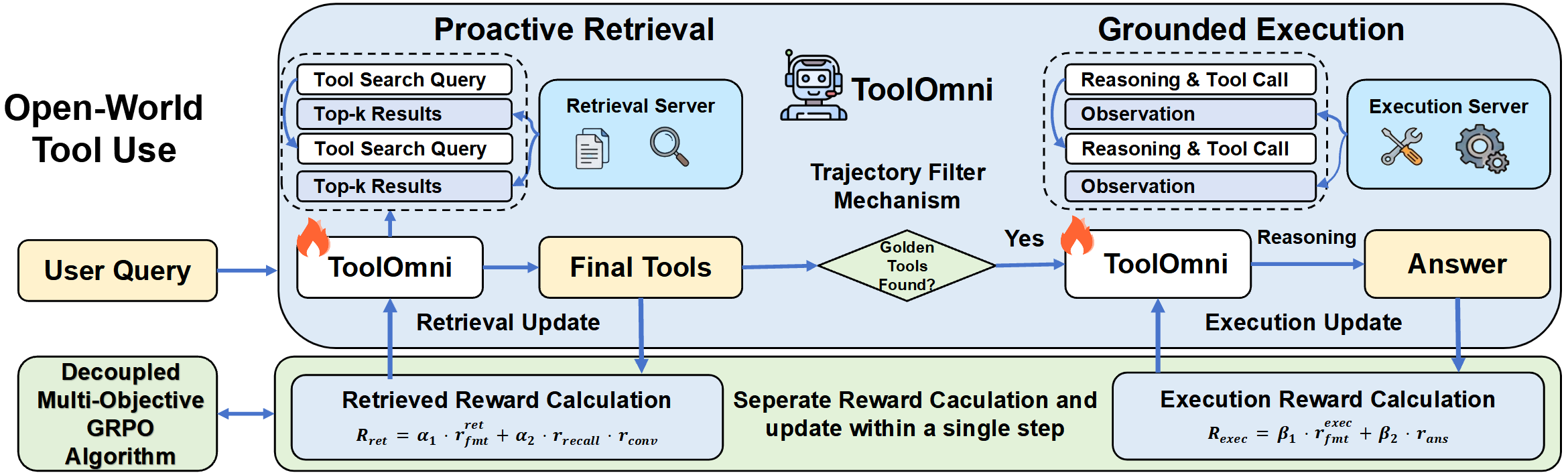
Figure 2: ToolOmni pipeline—Proactive Retrieval iteratively curates tool candidates; Grounded Execution reasons with retrieved tools to solve the task.
Learning Objectives and Optimization Strategy
The framework implements a two-stage training process:
Empirical Results and Strong Numerical Claims
ToolOmni is evaluated on the ToolBench benchmark, comprising over 16,000 APIs across varying complexity and generalization splits. Key empirical findings include:
- State-of-the-art retrieval performance: ToolOmni achieves an average NDCG of 78.29% in multi-domain settings, significantly surpassing baselines such as ToolRetriever and ToolGen in top-1 and top-3 accuracy, demonstrating superior capacity for pinpointing golden tools in massive repositories.
- End-to-end execution superiority: ToolOmni's average Solvable Pass Rate (SoPR) reaches 54.13% in realistic scenarios, outperforming GPT-3.5 pipeline baselines by +11.78% and unified generative models by +18%. Solvable Win Rate (SoWR) exhibits substantial improvements as well, indicating enhanced precision and coherence in answer generation.
- Robust generalization: ToolOmni maintains SoPR of 52.20% on unseen tools and 55.95% on category generalization, exceeding GPT-3.5 by +13.85%, evidencing strong transfer and meta-reasoning capabilities.
Robustness, Ablations, and Sensitivity Analysis
Robustness tests under adversarial retrieval noise and generalization splits reveal the adaptive reasoning capacities of ToolOmni, which leverages alternative functionally similar tools when ground-truth candidates are occluded. Ablation studies underscore the necessity of both SFT and RL: RL drives retrieval quality, SFT is crucial for execution robustness. The iterative retrieval mechanism yields an absolute gain of +4.5% NDCG@5 over static baselines. Decoupled multi-objective GRPO with trajectory filtering and separated gradient updates is pivotal for execution performance, avoiding destructive signal conflicts and hallucination shortcuts.
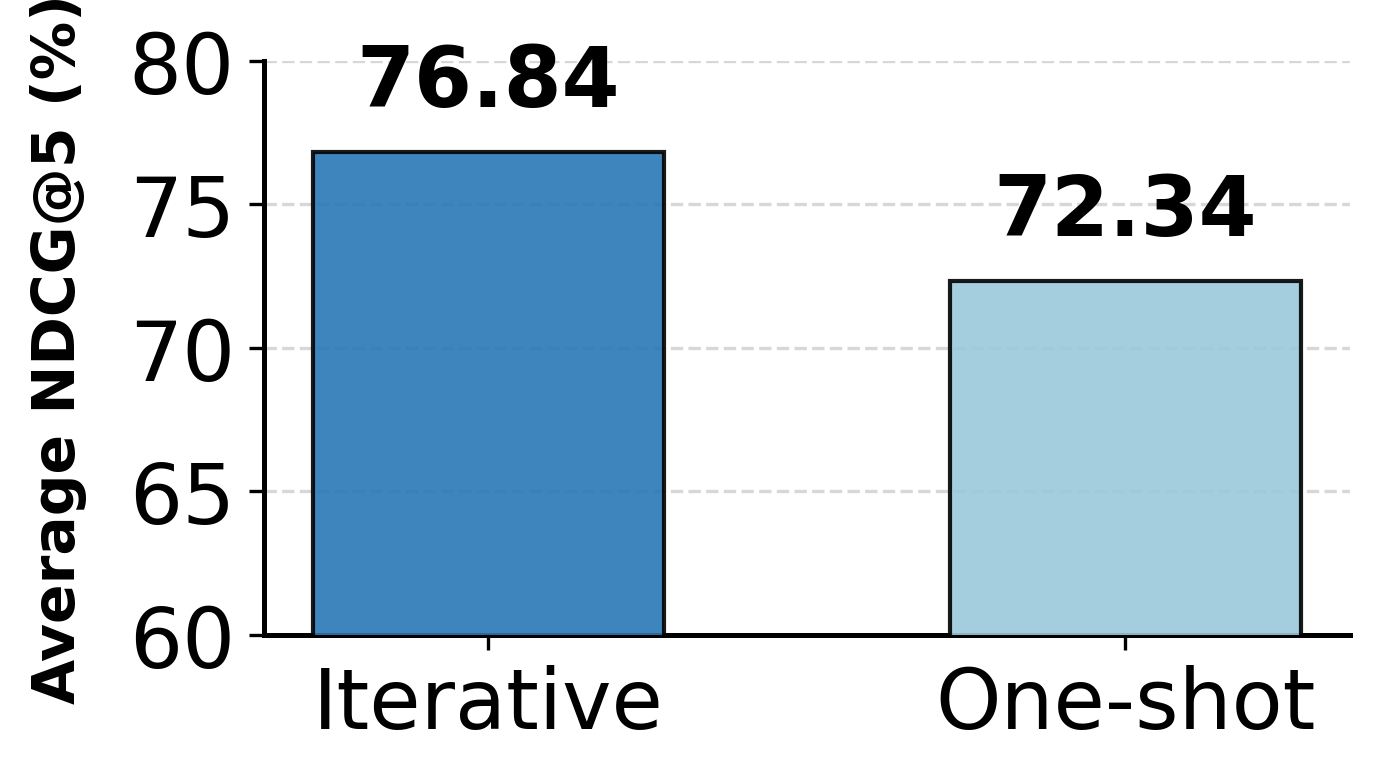
Figure 3: Ablation of training stages—integrating SFT and RL achieves optimal performance.
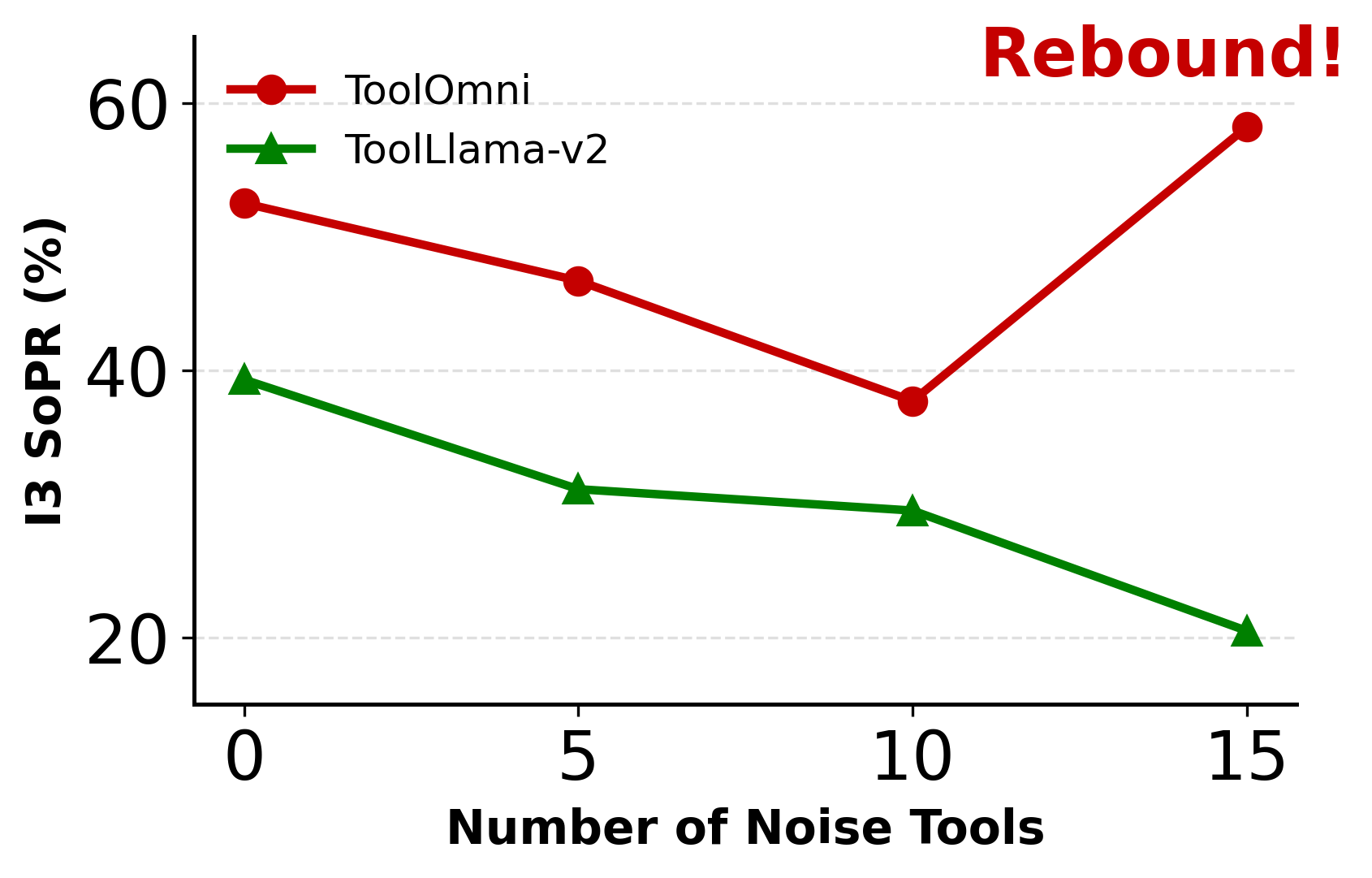
Figure 4: Robustness against adversarial retrieval noise on complex open-world tasks.
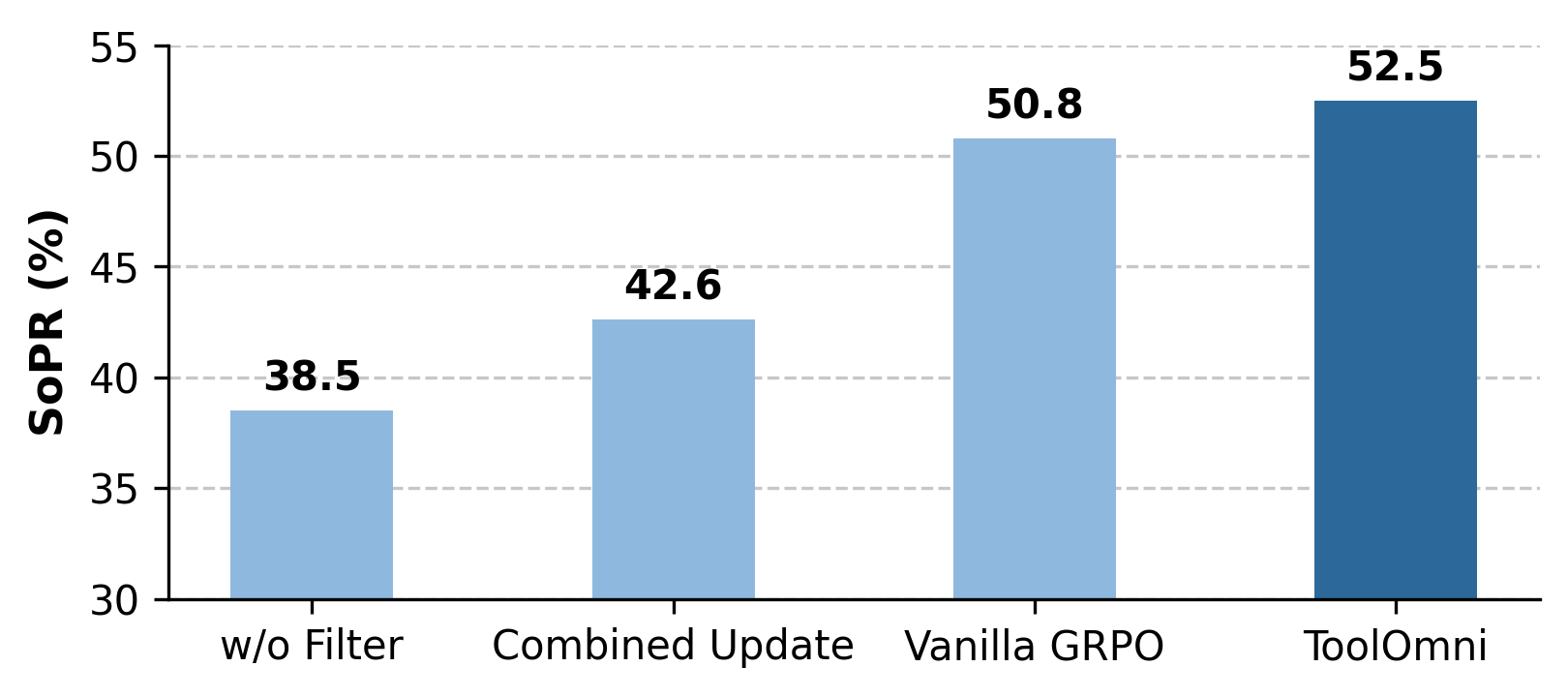
Figure 5: RL components ablation—decoupled optimization and trajectory filtering are essential for execution success.
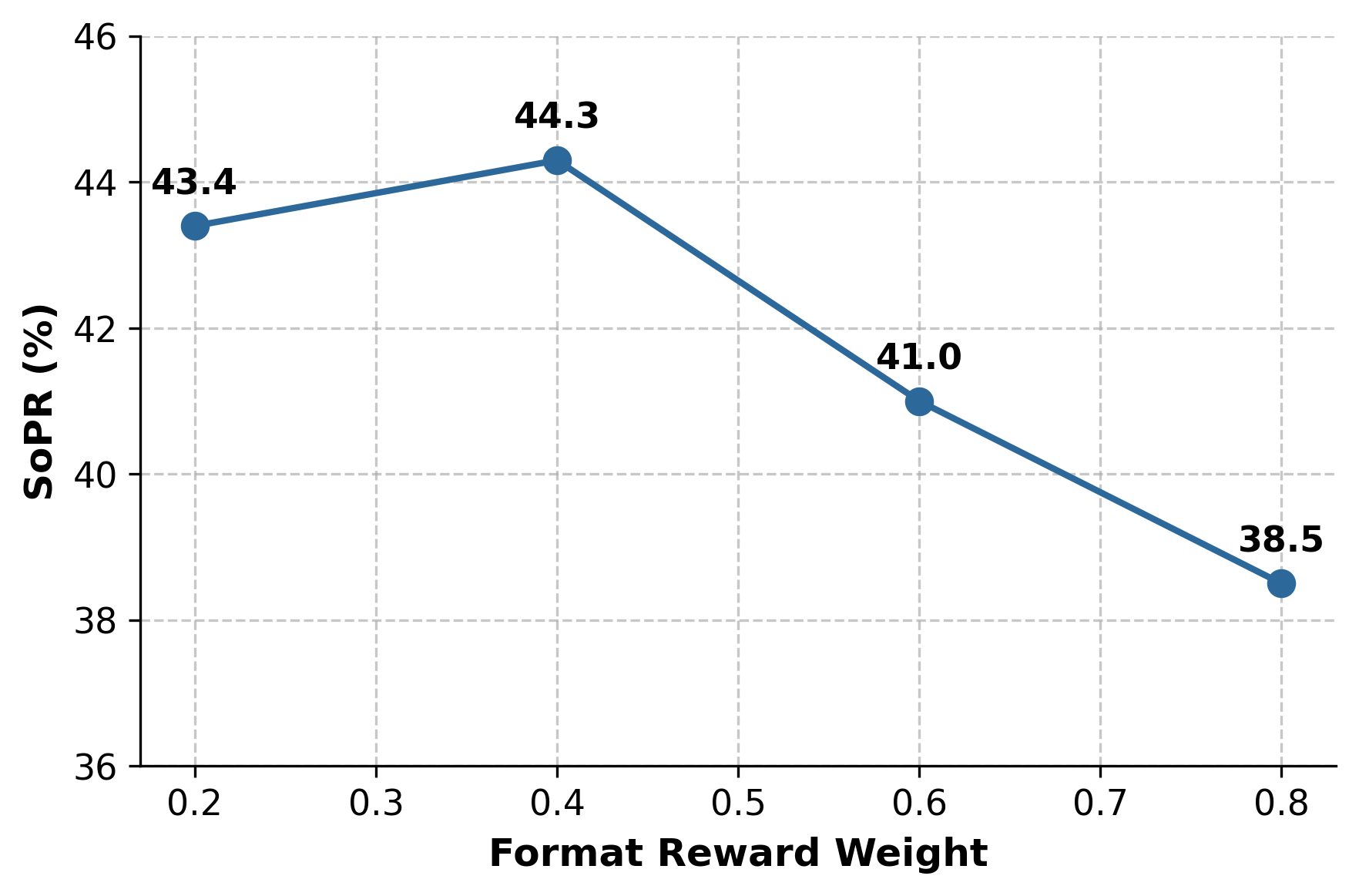
Figure 6: Sensitivity analysis—optimal format reward weighting enhances execution without stifling complex reasoning.
Practical and Theoretical Implications
Practically, ToolOmni enables scalable, robust tool reasoning in real-world, dynamic API landscapes, optimizing computational efficiency by trading inexpensive retrievals for fewer, higher-quality API invocations. Theoretically, the decoupling of retrieval and execution task signals via separate reward functions and optimization offers a powerful schema for RL fine-tuning in highly interdependent LLM scenarios. The agentic iterative design transcends passive pipeline architectures, learning transferable meta-skills for tool use, parameter inference, and error recovery that adapt seamlessly to novel domains.
Future Directions
Future efforts should extend ToolOmni’s framework to multimodal, heterogeneous toolsets and investigate scaling properties with larger foundation models. The rigidity of the cascaded paradigm could be relaxed to support dynamic tool chain discovery conditioned on intermediate execution feedback, further enhancing agentic flexibility and long-horizon planning.
Conclusion
ToolOmni represents a unified agentic approach for open-world tool use, integrating proactive retrieval and grounded execution with decoupled RL optimization. It delivers state-of-the-art retrieval and execution performance, robust generalization, and resilience to noise in massive, evolving repositories. The implications are substantial for scalable, adaptive LLM tool use and agentic reasoning in real-world dynamic environments.

