Understanding Tool-Integrated Reasoning
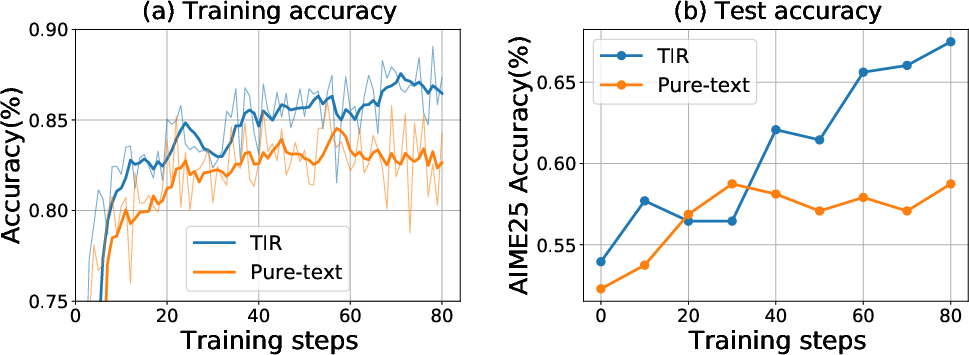
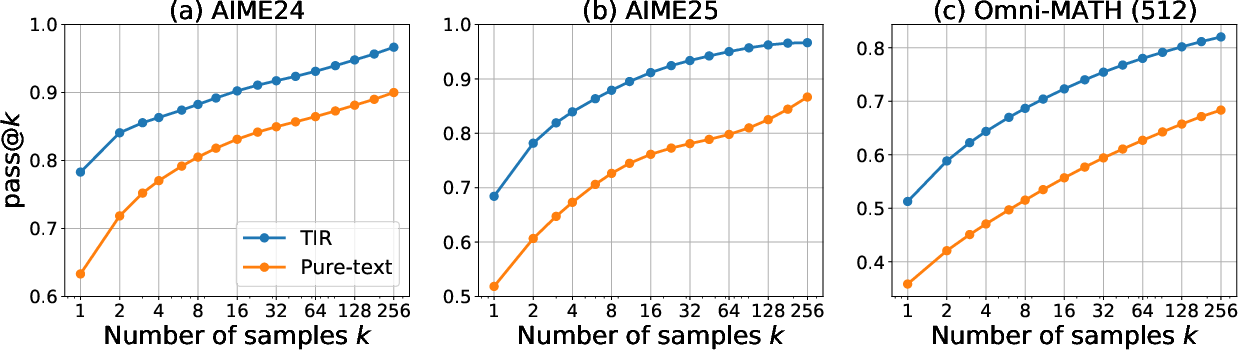
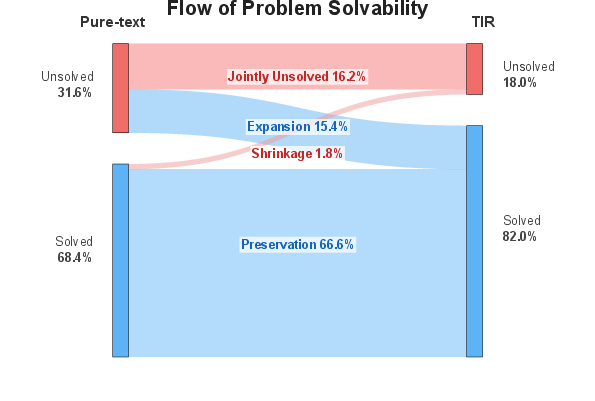
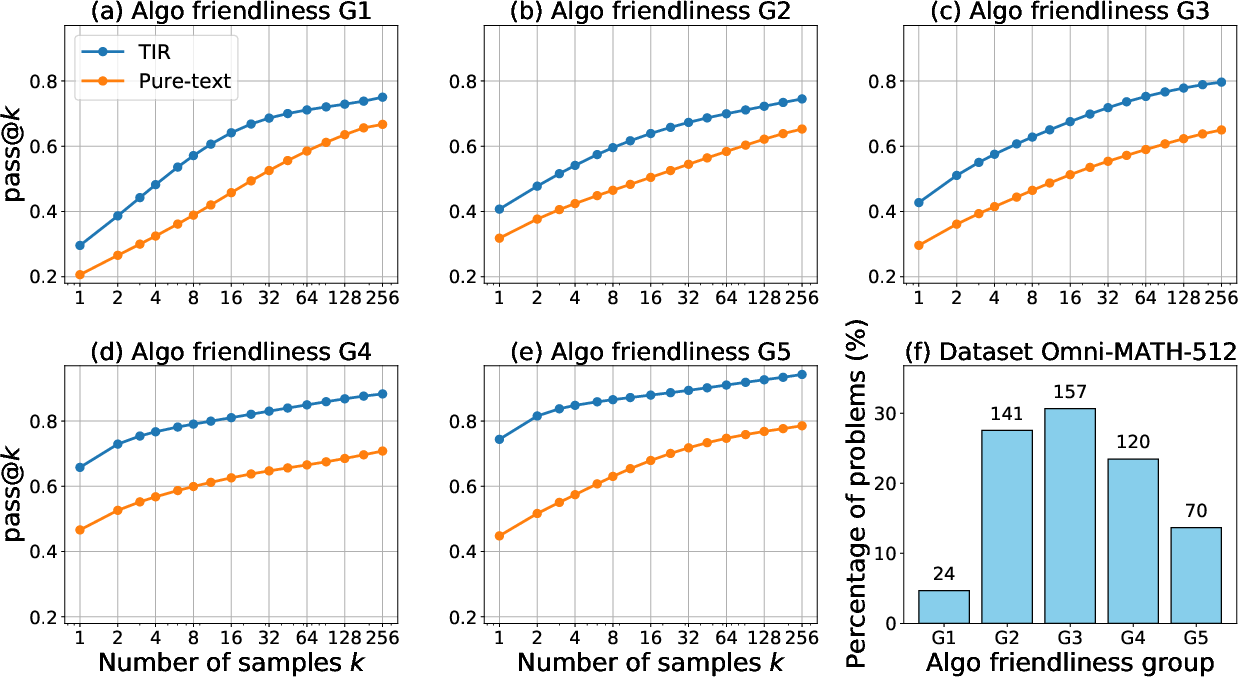
Abstract: We study why Tool-Integrated Reasoning (TIR) makes LLMs more capable. While LLMs integrated with tools like Python code interpreters show great promise, a principled theory explaining why this paradigm is effective has been missing. This work provides the first formal proof that TIR fundamentally expands an LLM's capabilities. We demonstrate that tools enable a strict expansion of the model's empirical and feasible support, breaking the capability ceiling of pure-text models by unlocking problem-solving strategies that are otherwise impossible or intractably verbose. To guide model behavior without compromising training stability and performance, we also introduce Advantage Shaping Policy Optimization (ASPO), a novel algorithm that directly modifies the advantage function to guide the policy behavior. We conduct comprehensive experiments on challenging mathematical benchmarks, leveraging a Python interpreter as the external tool. Our results show that the TIR model decisively outperforms its pure-text counterpart on the pass@k metric. Crucially, this advantage is not confined to computationally-intensive problems but extends to those requiring significant abstract insight. We further identify the emergent cognitive patterns that illustrate how models learn to think with tools. Finally, we report improved tool usage behavior with early code invocation and much more interactive turns with ASPO. Overall, our work provides the first principled explanation for TIR's success, shifting the focus from the mere fact that tools work to why and how they enable more powerful reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
- Sector: Software/AI; Use case: Ship LLMs with a first-class code interpreter by default to break the pure-text capability ceiling; Tools/products/workflows: Embed a sandboxed Python (or WASM) runtime, log tool I/O, adopt a “insight → code → verify” reasoning template; Assumptions/Dependencies: Deterministic, secure sandbox; resource limits and timeouts; tool output trusted or validated.
- Sector: Software Engineering; Use case: Test-first coding assistants that invoke unit tests early and iteratively; Tools/products/workflows: Apply ASPO to reward earlier test execution and hypothesis-checking during code synthesis; Assumptions/Dependencies: Project environment setup, test harness availability, dependency management.
- Sector: Data Science/BI; Use case: Analytical copilots that programmatically compute (not narrate) transformations, statistics, and visualizations; Tools/products/workflows: Notebook-style agents that offload loops/DP/search to code and return verified results; Assumptions/Dependencies: Governed data access, secure execution, reproducible environments.
- Sector: Education; Use case: Math/STEM tutors that transform insight into computation, explore hypotheses via code, and offload tedious algebra; Tools/products/workflows: Tutor prompts that alternate reasoning and executable snippets, auto-check answers via code; Assumptions/Dependencies: Vetted problem sets, safe libraries, age-appropriate guardrails.
- Sector: Assessment/EdTech; Use case: Autograders that verify student solutions by executing property tests/symbolic checks; Tools/products/workflows: Pass@k evaluation for robustness; rubric routing by “algorithmic friendliness” to determine when code verification is warranted; Assumptions/Dependencies: Deterministic tests, plagiarism and code-safety controls.
- Sector: Finance; Use case: Copilots for risk analytics, scenario backtesting, and reconciliation that verify calculations with code; Tools/products/workflows: Python/pandas-backed reasoning with early code invocation; durable audit trails of tool calls/outputs; Assumptions/Dependencies: Compliance guardrails, version-pinned libraries, PII protection.
- Sector: Healthcare; Use case: Verifiable medical calculators and guideline checks (e.g., dosing, scores) executed as code rather than prose; Tools/products/workflows: Controlled interpreter with validated clinical libraries; ASPO encouraging verification before final recommendations; Assumptions/Dependencies: Regulatory approval, model/tool validation, offline/edge modes for privacy.
- Sector: Enterprise Knowledge/Agents; Use case: Retrieval + code agents that explore and verify claims by running computations on retrieved data; Tools/products/workflows: Early code calls to prototype calculations, then finalize with validated pipelines; Assumptions/Dependencies: Source trust, latency budgets, content provenance logging.
- Sector: LLM Training; Use case: Stable behavior shaping with ASPO to encourage desired behaviors (early tool use, mandatory verification, citation insertion) without destabilizing GRPO/PPO; Tools/products/workflows: ASPO drop-in for group-normalized advantage pipelines; Assumptions/Dependencies: Correct advantage accounting, clip bounds, high-quality reward signals for correctness.
- Sector: Safety/Reliability; Use case: Reduce hallucinations by requiring a code-based verification step prior to finalization; Tools/products/workflows: Policy that withholds final answers until a verification tool call succeeds; Assumptions/Dependencies: Tool reliability, fallback paths, cost/latency acceptance.
- Sector: Product/UX; Use case: “Executable scratchpad” chat modes that support hypothesis → snippet → observation loops; Tools/products/workflows: UI affordances for running snippets, displaying outputs/plots, and logging trials; Assumptions/Dependencies: Sandboxing, rate limits, streaming outputs.
- Sector: Evaluation/QA; Use case: Capability tracking with pass@k curves and stratification by “algorithmic friendliness” to detect true support expansion; Tools/products/workflows: Evaluation harnesses that sample across k and group tasks by friendliness scores; Assumptions/Dependencies: Labeling consistency for friendliness rubric, sampling budgets.
Long-Term Applications
- Sector: Multi-Tool Orchestration; Use case: Agents that route among solvers (CAS, MILP, SAT, simulators) using an “algorithmic friendliness” router; Tools/products/workflows: Planner selecting tools early (ASPO-shaped) and verifying outputs cross-tool; Assumptions/Dependencies: Reliable adapters, cost-aware routing, tool compatibility.
- Sector: Standards/Policy; Use case: Regulatory expectations for “verifiable-by-tool” reasoning in high-stakes domains (health, finance, public services); Tools/products/workflows: Audit trails of tool calls, deterministic environments, reproducibility mandates; Assumptions/Dependencies: Industry consensus, certification frameworks, legal acceptance of computational evidence.
- Sector: Education Policy; Use case: Curricula that teach “thinking with tools” (insight-to-computation, exploration-by-code) and assess via executable artifacts; Tools/products/workflows: Classroom sandboxes, graded notebooks, code-backed proofs; Assumptions/Dependencies: Device access, teacher training, equitable infrastructure.
- Sector: Scientific Discovery; Use case: Agents that generate hypotheses, run in-silico experiments (simulations), and iteratively refine theories via code; Tools/products/workflows: Closed-loop simulation orchestration, early exploration bias (ASPO) to accelerate discovery; Assumptions/Dependencies: High-fidelity simulators, data licensing, compute availability.
- Sector: Robotics/Autonomy; Use case: Planners that invoke simulators/trajectory optimizers early in reasoning to validate strategies; Tools/products/workflows: Tool-integrated decision pipelines with real-time constraints; Assumptions/Dependencies: Low-latency tool execution, safety certification, sim-to-real transfer.
- Sector: Energy/Operations Research; Use case: Optimization agents for grid scheduling, logistics, and bidding that delegate computation to solvers; Tools/products/workflows: Early solver invocation, programmatically verified constraints; Assumptions/Dependencies: Access to operational data, strong safety constraints, reliable solvers.
- Sector: Legal/GovTech; Use case: Decision aids that compute statutory thresholds and verify eligibility/risk via code-backed checks; Tools/products/workflows: Transparent code artifacts and logs for audits, pass@k for contentious cases; Assumptions/Dependencies: Judicial/governmental acceptance, explainability requirements.
- Sector: Model Architecture; Use case: Pretraining and posttraining that natively model tool tokens, memories of tool traces, and cost-aware tool policies; Tools/products/workflows: Architectures with tool-usage priors and budgeted planning; Assumptions/Dependencies: Large-scale training data with tool traces, efficient schedulers.
- Sector: Tool Reliability & Supply Chain; Use case: Verified interpreters, pinned numeric stacks, and reproducibility fingerprints for every tool call; Tools/products/workflows: Build-time attestation and runtime provenance; Assumptions/Dependencies: Secure supply chains, package signing, reproducible builds.
- Sector: Task Routing & Procurement; Use case: Marketplaces that score workloads by “algorithmic friendliness” and route to TIR systems when efficiency or correctness gains are predicted; Tools/products/workflows: Classifiers calibrated to business KPIs and cost; Assumptions/Dependencies: Robust scoring models, telemetry on outcomes.
- Sector: Cost/Latency Governance; Use case: Controllers that optimize pass@k sampling and tool usage under budgets to maximize ROI; Tools/products/workflows: Budget-aware policy optimization and adaptive k; Assumptions/Dependencies: Reliable cost models, latency SLAs, policy evaluation loops.
- Sector: Privacy-Preserving TIR; Use case: On-device or enclave-executed tool calls for sensitive data domains; Tools/products/workflows: SGX/TEE-backed execution, ephemeral environments; Assumptions/Dependencies: Hardware support, performance overheads, attestation.
- Sector: Safety-Critical Alignment; Use case: Generalized ASPO to enforce safety properties (mandatory verification, citation proofs, tool gating) without destabilizing learning; Tools/products/workflows: Advantage shaping libraries with policy-level guarantees; Assumptions/Dependencies: High-quality signals for “safe/correct,” careful clip calibration.
Collections
Sign up for free to add this paper to one or more collections.

