- The paper introduces an agentic multimodal pipeline that combines planning, evidence retrieval, and incremental synthesis to generate cohesive, evidence-rich reports.
- The paper demonstrates significant improvements in narrative coherence and citation integration through recurrent context management and relevance-aware filtering.
- The paper validates its approach on the M²LongBench benchmark, showing marked gains in evidence selection precision and overall report quality.
Introduction
Deep-Reporter addresses the limitations of text-centric long-form generation models, introducing a unified agentic framework for multimodal long-form composition. The approach orchestrates planning, targeted retrieval of both text and visual evidence, and structured synthesis, thereby grounding lengthy, expert-grade reports in verifiable, information-dense multimodal sources. This direction responds to the emerging need for automated generation pipelines capable of replicating the evidence integration and cross-modal reasoning that characterize high-quality research artifacts and professional reports.

Figure 1: Comparison of paradigms in long-form report generation. Deep-Reporter (c) achieves high coherence and factuality by retrieving and integrating real-world visual evidence, overcoming the fragmentation and hallucinations of prior approaches.
Methodology
Agentic Multimodal Pipeline
Deep-Reporter decomposes the challenging multimodal generation task into three coordinated agentic components: Planning, Agentic Multimodal Search and Filtering, and Checklist-Guided Incremental Synthesis with Recurrent Context Management.
- Sectional Planning with Dual-Granularity Checklists: A Planner decomposes the report into a hierarchical structure of sections and semantic anchors (fine- and coarse-grained), generating explicit checklists for each section to ensure comprehensive narrative coverage and factual rigor.
- Agentic Multimodal Search & Filtering: For each section, Deep-Reporter executes dual-stream agentic search—narrative queries for text, and visual queries for charts, figures, and diagrams—against a multimodal retrieval backend, followed by rigorous relevance-aware filtering to isolate evidence that directly supports checklist items.
- Incremental Synthesis & Recurrent Context Management: A Reporter agent incrementally composes the narrative, leveraging a recurrent context mechanism that propagates both a compressed global summary and verbatim section-level history. This design maintains long-range report coherence and smooth local transitions across extensive contexts, mitigating context window overflow and cross-section drift. Visual evidence is consistently interleaved into the narrative via citation-based transcription, enabling fine control over image placement and supporting evidence traceability.
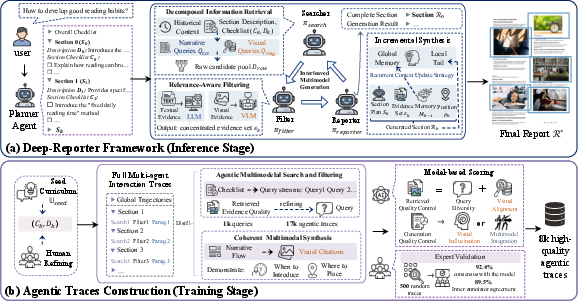
Figure 2: Deep-Reporter architecture. Multi-agent orchestration for planning, multimodal search/filtering, and incremental report writing. Right: the data synthesis pipeline curates expert traces for post-training open-weight models.
Dataset Construction and Training
To activate agentic multimodal reasoning capabilities lacking in existing LLMs, an expert-in-the-loop curation pipeline was developed to produce 8,000 high-quality agentic traces. The process involved:
- Diverse domain/task sampling and expert refinement of checklists and outlines.
- Autonomous execution/trace distillation of the agentic framework to capture interleaved multimodal search and synthesis logic, including retrieval, evidence selection, and visual citation strategies.
- Strict quality control, employing strong LLMs/VLMs for automatic trace filtration, verification of visual evidence alignment, detection/removal of hallucinations, and manual expert reviews, yielding a high-precision supervision corpus.
This dataset enables effective post-training of open-weight models, through both SFT and DPO, with SFT yielding superior multimodal action conditioning.
M2LongBench: A Rigorous Multimodal Benchmark
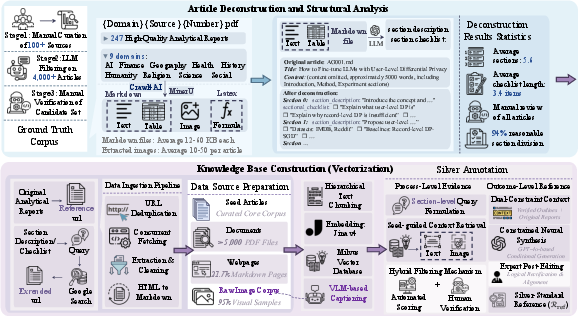
Deep-Reporter necessitates a testbed capable of holistic multimodal evaluation. M2LongBench was designed as a comprehensive, domain-diverse benchmark comprising 247 tasks with ground-truth blueprints, each annotated with exhaustive structural checklists and an average of 102 ground-truth images and 168 text chunks as evidence.
The core features are:
Experimental Results
Agentic Multimodal Retrieval and Filtering
Extensive ablation studies revealed that raw retrieval alone does not distinguish between competitive agentic frameworks; performance gains are centralized in the filtering and selection stages. Notably:
- Deep-Reporter’s searcher-filter design boosts precision at the evidence filtering stage, compressing large candidate sets (∼156 per task) to concentrated high-value evidence (∼81), raising selection precision (Qwen3-8B: Image selection, 8.3 → 45.0 after SFT).
- Post-training (SFT) significantly amplifies image selection/placement capabilities, which are otherwise almost absent in base or DPO-only variants.
Quantitative evaluation demonstrated that Deep-Reporter’s agentic orchestration yields order-of-magnitude improvements over strong baselines:
- Output length and narrative structure metrics: Naïve RAG outputs are truncated (∼2k tokens) and shallow (overall 5.2), while Deep-Reporter produces >4k token, highly coherent multimodal reports (overall 27.2 base, up to 37.9 after SFT).
- Sectional and citation-level multimodal integration: Section content quality rises from 6.4 (baseline) to 41.7 (Deep-Reporter + Qwen3-32B + SFT), with robust improvement in citation richness, coherence, placement, and clarity.
- Ablations indicate that relevance-aware filtering and explicit recurrent context management are complementary—removing either disproportionately harms context-sensitive (full report) or evidence-grounding (section content) metrics.
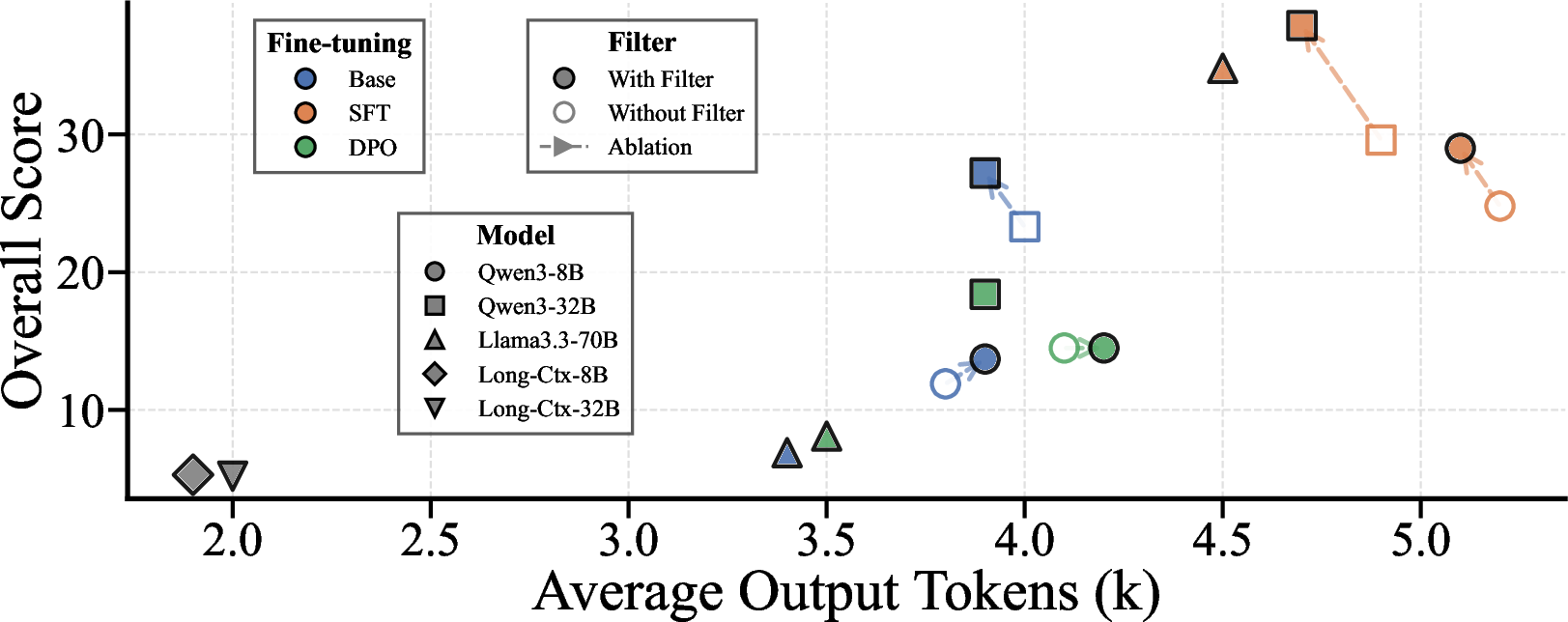
Figure 4: Overall generation metrics vs. output length, highlighting Deep-Reporter’s capacity for high-quality, extended multimodal reports.
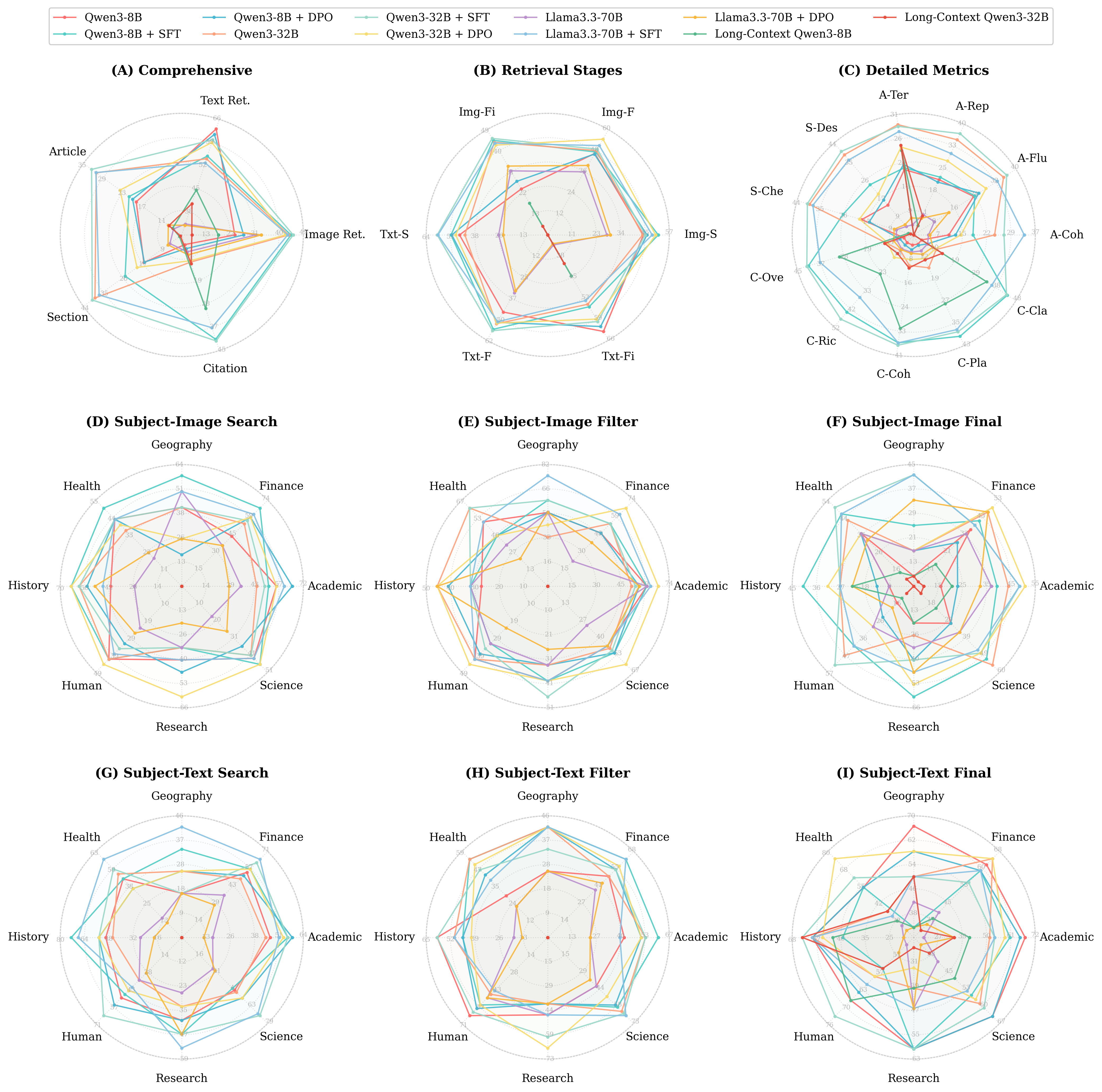
Figure 5: Model performance evaluation: holistic and stage-wise breakdowns, including subject-specific retrieval across modalities and pipeline stages.
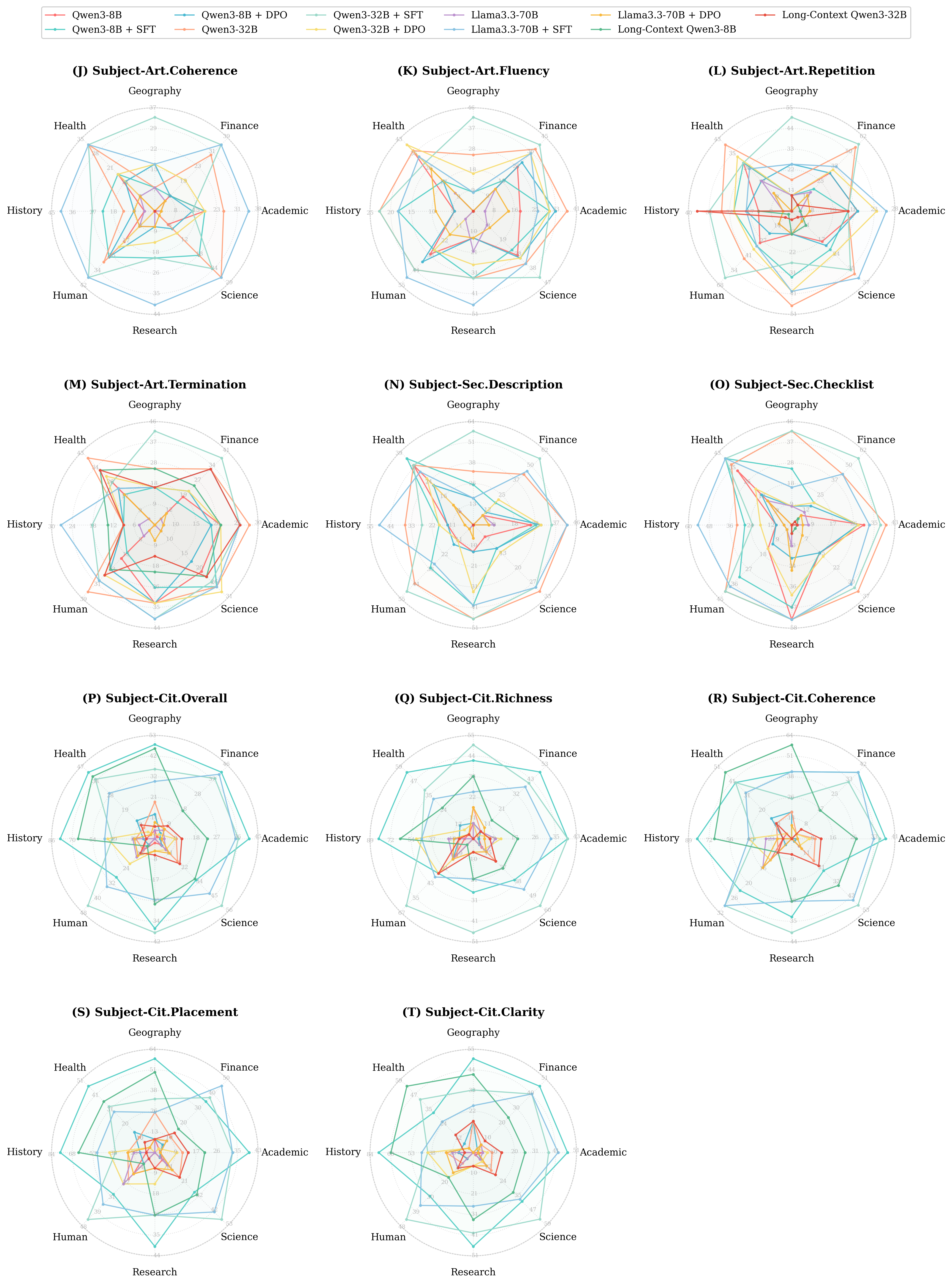
Figure 6: Subject/domain-specific generation quality, showing significant cross-domain variability and metric-specific performance patterns.
Training Objective Analysis
SFT consistently outperforms DPO for this regime, demonstrating that sparse multimodal actions (visual citation/insertion) benefit from dense, token-level supervision over preference-based, trajectory-level optimization.
Efficiency and Practical Considerations
Filter-based relevance estimation incurs significant inference latency (∼10 minutes per report, dominant cost is filtering). However, SFT-improved models retain inference efficiency, and quality-latency trade-offs can be navigated by adjusting retrieval/filter budgets or deploying lightweight classifiers.
Implications and Future Directions
Deep-Reporter’s results establish the criticality of fine-grained agentic architectures for grounded multimodal research automation. Architectures lacking both explicit evidence selection (filtering) and contextual memory (recurrent management) suffer from severe context degradation and inability to perform reliable multimodal synthesis. The high reliance on structured action supervision (SFT > DPO) suggests RL-based approaches require dense reward signal engineering for compositional, cross-modal tasks. The M2LongBench design will likely serve as a template for future multimodal research and evaluation platforms, especially where unified access and transparency are required.
On the practical axis, Deep-Reporter highlights the importance of modular pipelines for deployable research assistants: model components (searcher, filter, reporter) and sandbox infrastructure can be incrementally scaled/updated for new domains, languages, or evidence modalities. Potential future developments include online RL optimization, multilingual capability extension, and tighter integration with knowledge graphs or domain-specific retrieval APIs.
Conclusion
Deep-Reporter advances the frontier of grounded, agentic multimodal report generation, establishing new best practices for both system design and evaluation. The framework delivers robust, highly factual long-form narratives tightly interleaved with visual evidence, with empirical superiority demonstrated on a new, rigorous multimodal benchmark. The modular and extensible design of both Deep-Reporter and M2LongBench provide a reproducible foundation for future research in agentic, evidence-driven content creation systems.