- The paper introduces DR3-Eval, a benchmark that rigorously evaluates deep research agents in realistic, multimodal research tasks using static sandboxes.
- It employs a divergent-convergent process to generate task-specific corpora with supportive, distractor, and noise documents, ensuring fine-grained evaluation.
- Experimental results reveal persistent issues such as evidence hallucination and instruction-following challenges, highlighting the need for robust multimodal synthesis.
DR3-Eval: Advancing Multimodal, Realistic, and Reproducible Deep Research Evaluation
Current state-of-the-art Deep Research Agents (DRAs) are expected to autonomously complete complex, long-horizon research workflows that extend far beyond traditional QA, encompassing strategic planning, multimodal information retrieval, iterative evidence evaluation, and structured, citation-grounded report generation. However, existing evaluation protocols for DRAs are either brittle (due to reliance on dynamic web sources and ambiguous queries) or insufficiently realistic (clean, text-only, or synthetic tasks), thus failing to simultaneously capture real-world complexity, reproducibility, and verifiability.
DR3-Eval seeks to resolve this by introducing a benchmark that is both grounded in authentic, user-provided, multimodal research artifacts and built upon a per-task, static research sandbox. This framework allows for rigorous, repeatable, fine-grained evaluation of DRAs’ abilities to retrieve, synthesize, and ground information amidst controlled distractors and noise.
DR3-Eval Framework and Architecture
The benchmark is constructed with three interlocking pillars: (1) task generation from real-world multimodal user files and queries devised via a divergent-convergent keyword mechanism, (2) building for each task an associated static sandbox corpus with realistic distributions of supportive, distractor, and noise documents, and (3) a multidimensional evaluation suite capturing both evidence acquisition and analytical report quality.
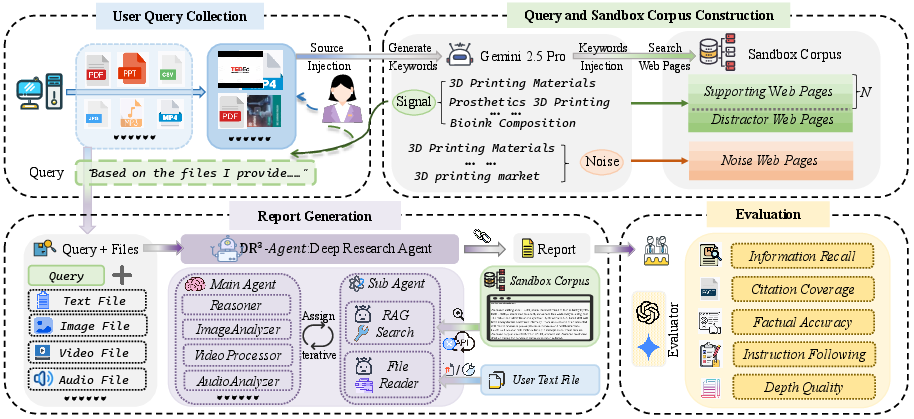
Figure 1: Overview of DR3-Eval, showing data construction, hierarchical multi-agent DRA design, and the evaluation protocol.
Data Construction and Task Grounding
The dataset is built by recruiting domain-diverse participants (undergraduate/graduate students) to provide multimodal research resources (text, pdf, spreadsheets, images, video, audio), sanitized for privacy. The topics span a broad disciplinary range across Technology, Economy, and Humanities, decomposed into 13 sub-domains, creating 100 tasks (50 English, 50 Chinese).
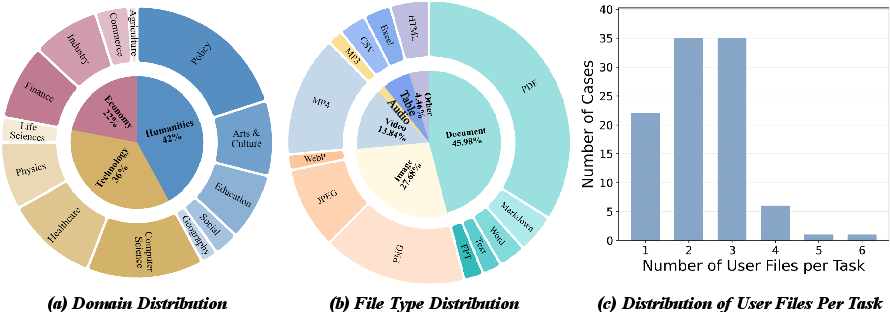
Figure 2: Distributions of domains, modalities, and file counts in DR3-Eval tasks.
A distinctive divergent-convergent process is used for search path engineering: high-level, conceptually varied “signal” (core evidence) and “noise” (distractor) keywords are generated. The retrieval corpus for each task is then populated via web-scale crawling using these keywords, followed by stringent manual curation and tripartite classification: supportive evidence, contextually misleading distractors, and noise. This enables controlled signal-to-noise adjustment and verifiable solution paths.
Sandbox Corpus and Semantic Distribution
The sandbox architecture provides a configurable, context-length-scaled evaluation environment enabling systematic analysis of DRA robustness under realistic information overload and ambiguity.
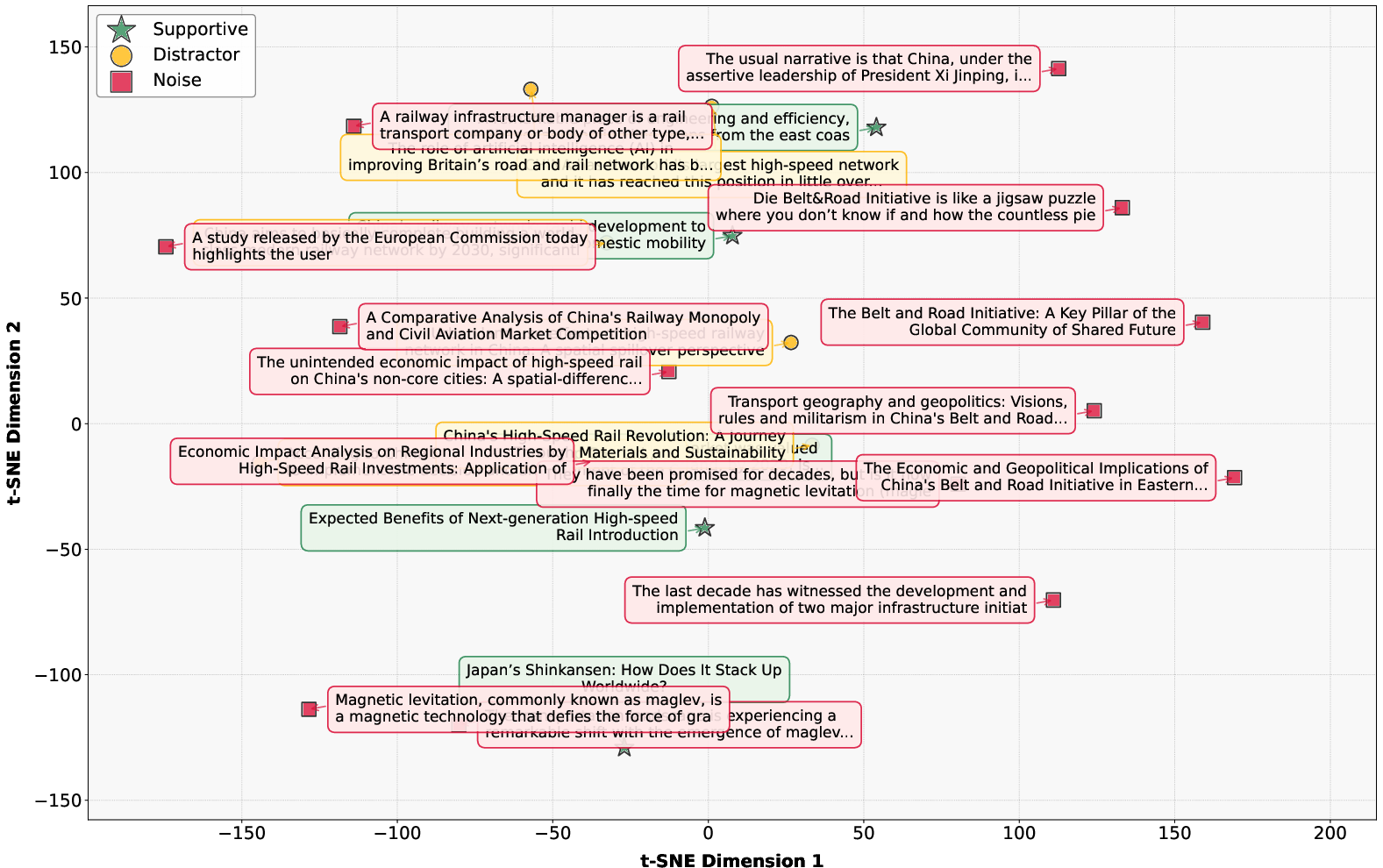
Figure 3: t-SNE projection demonstrates semantic diversity and clustering among supportive, distractor, and noise web pages.
Task Design and Quality Control
Queries are constructed in reverse from ground-truth documents, ensuring every research task admits a unique, fully evidence-grounded solution. Explicit controls eliminate tasks with shortcut solvability, ambiguous objectives, or direct answer retrievability—resulting in a high-purity, low-ambiguity benchmark.
Hierarchical Multi-Agent Architecture for DR3-Eval
The reference DRA system (DR3-Agent) is operationalized atop the MiroFlow multi-agent framework, with a perception-augmented main agent and lightweight sub-agents orchestrating sandbox retrieval (iterative dense retrieval with query refinement using ReAct-style prompting) and fine-grained multimodal file parsing.
This architecture is necessary to bridge the cross-modal, cross-source grounding required by DR3-Eval, allowing fused reasoning across user files and evidence in the sandbox corpus. The sub-agent memory separation and summarization mitigate main context bottlenecks, supporting efficient hierarchical decomposition of retrieval and synthesis subtasks.
Multidimensional Evaluation Protocol
DR3-Eval introduces a five-metric suite:
- Information Recall (IR-UF/IR-SC): Granular coverage of atomic, manually validated insights from (UF) user files and (SC) sandbox corpus.
- Citation Coverage (CC): Proportion of gold-standard required sources (supportive docs and user files) explicitly and correctly cited.
- Factual Accuracy (FA): Automated, claim-by-claim verification against ground evidence (textual and non-textual).
- Instruction Following (IF): Rubric-based checklist compliance derived from the explicit and implicit requirements of the query.
- Depth Quality (DQ): LLM-expert-judged analytic and logical depth of the generated report.
Strong alignment between LLM-as-judge outcomes and human expert judgments is empirically demonstrated (Pearson r=0.78, Spearman 30).
Experimental Results and Failure Mode Analysis
Experiments benchmark competitive proprietary and open-source LLM-based DRAs (Claude Sonnet 4, GLM-4.7, Gemini-2.5-Pro, GPT-4.1, Qwen3-series, among others). Notable outcomes include:
- High task difficulty and low model saturation: Even the best-performing model (Claude Sonnet 4) achieves only moderate scores, with significant performance degradation as context length (noise) increases.
- Scaling law persistence: Larger model variants consistently outperform smaller counterparts.
- Instruction following–factual accuracy decoupling: Several models (e.g., Qwen3-235B-A22B, GPT-4.1) “please” the rubric yet hallucinate or fail to retrieve sufficient supporting evidence, a clear indicator of shallow evidence integration.
Failure-type attribution reveals persistent hallucination as the dominant error, followed by retrieval and reasoning failures, highlighting the ongoing brittleness in LLMs’ evidence adherence, especially under complex, distractor-rich reasoning chains.
Benchmark Stability and Design Validity
Evaluation stability is confirmed through variance analysis, bootstrap re-ranking, and cross-judge consistency, all showing low volatility and high ranking robustness. Citation and evidence utilization in sandbox-only and live web settings are closely matched, validating the “closed world” design as a faithful proxy for real-web complexity.
Implications and Future Directions
DR31-Eval constitutes a step-change in DRA benchmarking by:
- Enabling controlled, repeatable, and fine-grained evaluation of retrieval and synthesis under real-world multimodal, noisy, and ambiguous research contexts.
- Illuminating critical failure modes—especially evidence hallucination—that are obscured by text-only or QA-style tasks.
- Providing a framework extensible to other research domains, modalities, and agentic architectures, catalyzing the robust, transparent development of research agents.
- Supporting the development and assessment of new agent architectures for context management, evidence routing, and cross-modal reasoning—areas where current approaches show persistent failure.
DR32-Eval also advances the conversation on environmental and privacy aspects of LLM evaluation, encouraging sustainable, static benchmarking practices and rigorous data de-identification in multimodal settings.
Conclusion
DR33-Eval (2604.14683) sets a new bar for realistic, reproducible, and multimodal benchmarks for DRAs in the report-generation paradigm. Its hybrid of user-grounded, authentically complex tasks, static yet semantically-rich sandboxes, and comprehensive evaluation signals critical research directions for agent robustness, hallucination mitigation, and cross-modal reasoning. It will serve as a foundation for advancing the evaluation and reliable deployment of truly autonomous research systems.