- The paper introduces the STITCH framework, a novel two-stage filtering method that enhances data efficiency in training agentic code LLMs.
- The paper details a dual process of macro-level statistical filtering and micro-level semantic segmentation to isolate high-signal training data.
- The paper demonstrates significant performance improvements across Python, Java, and ArkTS benchmarks with substantially reduced training data.
Extending the Less-Is-More Hypothesis to Agentic and Coding LLMs
Introduction
"Yet Even Less Is Even Better For Agentic, Reasoning, and Coding LLMs" (2604.00824) rigorously investigates the data efficiency of LLMs in long-horizon, agentic software engineering scenarios. Challenging the prevailing paradigm of scaling data and model size, this work extends the "Less-Is-More" hypothesis—originally articulated in mathematical reasoning contexts—to agentic learning, code generation, and multi-turn tool-use. The authors present a novel curation framework, STITCH (Sliding-memory Trajectory Inference and Task Chunking Heuristic), which systematically filters agentic trajectories to prioritize high-signal training data, demonstrating substantial performance gains with markedly reduced annotation cost across code-centric benchmarks in Python, Java, and ArkTS/HarmonyOS.
Unified Data Construction and the Less-Is-More Training Paradigm
The core architectural contribution is a modular end-to-end pipeline, predicated on the insight that agentic performance can be unusually sensitive to the quality and structural alignment of training trajectories. The pipeline consists of:
- SandForge: This module transitions real-world GitHub events into standardized task units by extracting, validating, and structuring repository states, issue contexts, and patch/test deltas as agent-executable tasks. The abstraction ensures traceability, environment specification, and executability, serving as the backbone for reproducible, large-scale trajectory collection.
- Agentic Trajectory Collection: Diverse agent architectures are deployed to interact autonomously within these task instances, outputting multi-turn trajectories—sequence data encompassing environment manipulations, tool invocation traces, exception handling, and code diffs.
- STITCH Two-Stage Filtering: STITCH critically addresses the central bottleneck: agentic trajectories are data-heavy, noisy, and expensive to curate. The two-stage curation pipeline performs:
- Macro-level Statistical Filtering: Features are automatically discovered and weighted via Logistic Regression, filtering low-reward, repetitive, or logically incoherent global trajectories.
- Micro-level Semantic Segmentation: Remaining candidates are chunked using a Map-Reduce abstraction with sliding memory windows, enabling context-aware evaluation and fine-grained extraction of high-quality decision-critical trajectory segments, even from globally suboptimal runs.
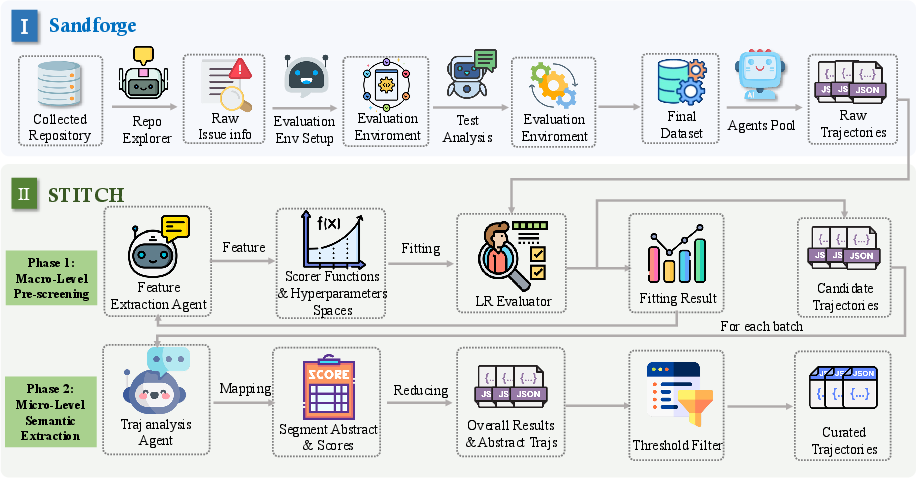
Figure 1: Schematic overview of the framework—real GitHub issues are transformed into structured agentic tasks, with STITCH filtering trajectories via macro/micro analysis for training.
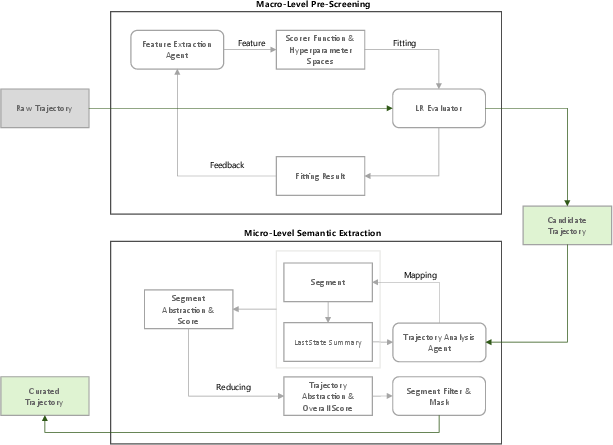
Figure 2: Visualization of the two-stage STITCH curation process: macro-level pre-screening (above) followed by micro-level chunk-based semantic analysis (below).
This architecture is explicitly designed to decouple signal from token volume and maximize data utility, regardless of agent, programming language, or downstream fine-tuning methodology.
Automated Feature Discovery and Curation Dynamics
To operationalize trajectory filtering, the authors formalize trajectory quality as a weighted composition of scenario-abstract scoring primitives: bounded linear reward (for productivity heuristics), proportional reward (e.g., tool success ratios), and threshold decay penalties (efficiency/turn limits). Feature extraction and weight assignment are automated:
- A feature extraction "agent" proposes, evaluates, and revises feature sets, with orthogonal dimensions for code production, tool use diversity/success, token efficiency, and error recovery.
- Logistic Regression is trained with binary supervision (trajectory success/failure), providing interpretable feature importances mirroring empirical agentic success.
- The resultant model's coefficients are mapped onto scoring hyperparameters for macro-filtering; this dynamic adjustment is key to robust, scenario-agnostic application.
Global macro-filtered candidates then undergo micro-level scoring. Heuristic trajectory segmentation (aligned with context-preserving split points) together with LLM-as-a-judge segment analysis extracts high-fidelity behavior fragments. This enables isolation of high-value, tightly-coherent agentic reasoning and tool use even in otherwise unproductive traces.
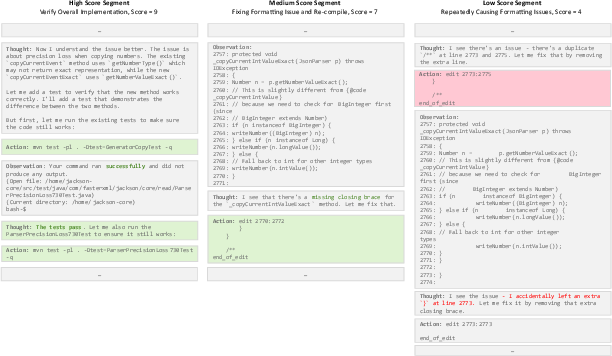
Figure 3: Scored samples from curated trajectories—exemplifying high, medium, and low-quality local behaviors as detected post-STITCH.
Empirical Results and Comparative Analysis
Extensive benchmarks are run across Python (SWE-bench Verified), Java (Multi-SWE-bench), and ArkTS/HarmonyOS agentic datasets. Experiments rigorously control for test leakage (e.g., disabling direct git history inspection and web fetches) and focus on code execution, patch generation, compilation correctness, and final task resolution.
Python
Across models ranging from 30B up to 355B, STITCH-cured training data consistently yields substantial absolute and relative resolve rate improvements versus vanilla reject-sampling fine-tuning (RFT). Relative improvement is maximized with smaller models (e.g., 30B: up to +63.16%), with diminishing but non-negligible gains as models scale.
Java
STITCH achieves a +16.67% relative improvement with MiniMax-M2.5 on CodeArts-Agent in Multi-SWE-bench(Java). Notably, STITCH-trained open-source models approach or surpass competitive proprietary baselines (GPT-5.2, Claude 3.7 Sonnet).
ArkTS/HarmonyOS
Markedly, with only ~1,000 STITCH-curated ArkTS agentic traces, compilation pass rate increases from 42.77% to 61.31% (+43.34%) and UI Preview pass from 31.54% to 44.05% (+39.66%). The qualitative analysis attributes these gains to improved compliance with ArkTS-specific static typing and migration rules, and superior rendering of UI intent in functional tasks.
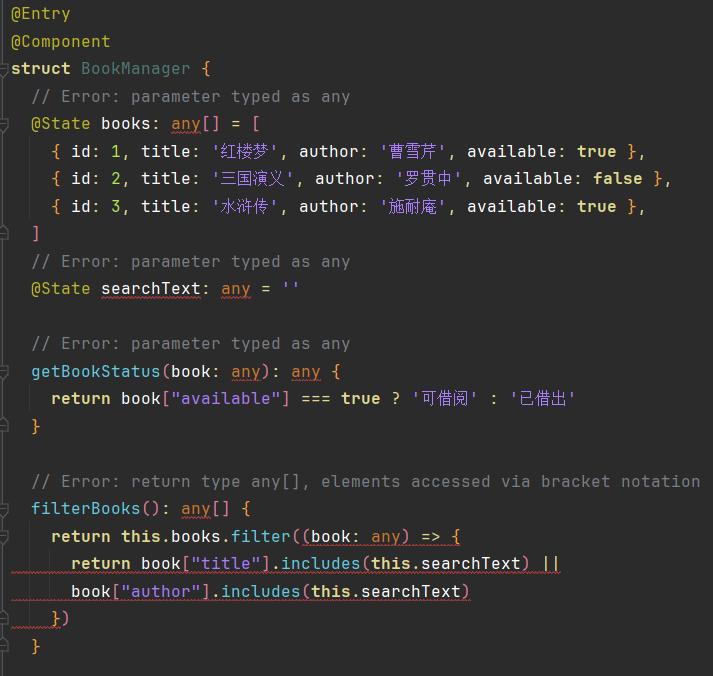
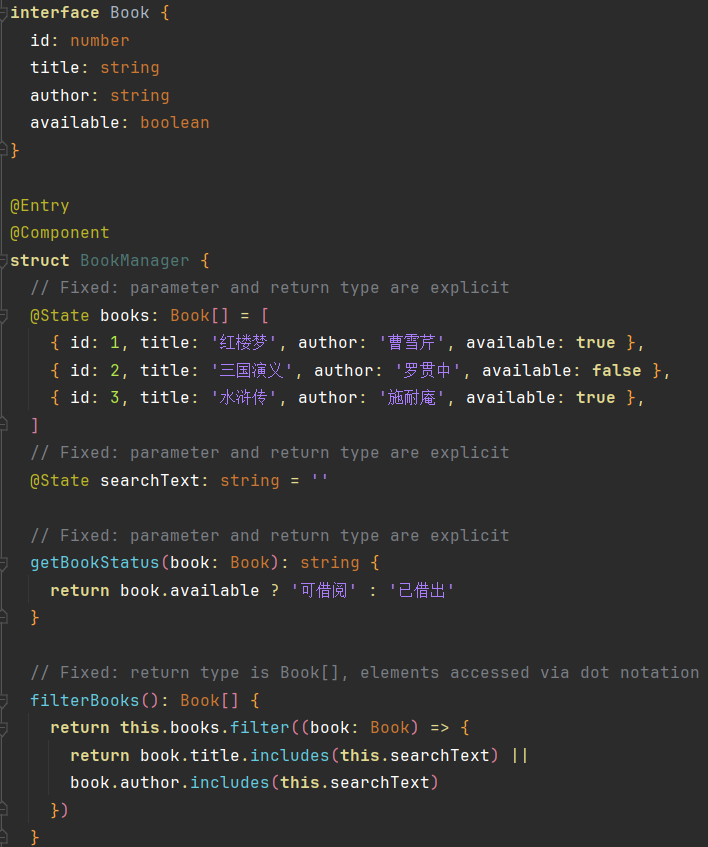
Figure 4: Code output comparison—unfiltered training yields non-compliant code, whereas STITCH-trained models produce ArkTS-compliant, compiling code for the same requirement.

Figure 5: UI rendering comparison—the base model fails at visual fidelity and layout; the STITCH-trained model delivers functionally and aesthetically superior output.
Theoretical and Practical Implications
This work’s central claim—well-curated, minimal, high-quality data can induce strong agentic generalization in code agents—directly counters the trend towards indiscriminate data scaling. On the theoretical frontier, the generalization of the Less-Is-More hypothesis from synthetic mathematical reasoning to long-horizon, noisy, real-world agentic code-generation is strongly validated.
Practically, the data and computational cost savings are substantive:
- The use of STITCH radically lowers trajectory annotation costs, making participation in state-of-the-art agent benchmarks feasible for smaller teams.
- The end-to-end pipeline and curation heuristics have been instantiated across agent types (function-calling, ReAct-style, etc.) and languages, demonstrating robust portability and minimizing the need for custom, hand-tuned benchmarks.
- The approach generalizes to low-resource language settings (e.g., ArkTS), with significant impact for emerging or industrial-verticalized code ecosystems.
Prospective Directions
- The data-centric, agentic segmentation paradigm may unlock more efficient multitask, multilingual, and multimodal agent training.
- The formalization of feature discovery and scoring could be extended to reinforcement learning from segmented rollouts, ranking, and online continual curation.
- The separation and evaluation of local high-value trajectory fragments suggest new directions in hierarchical or curriculum-style agent pretraining.
Conclusion
The study robustly establishes that trajectory quality is a dominating factor in training agentic code LLMs, even—indeed especially—when dataset cardinality is aggressively reduced. STITCH’s coarse-to-fine segmentation and semantic evaluation pipeline delivers consistent, reproducible, and dramatic gains in agentic code generation and reasoning, across tasks, scales, architectures, and languages. The evidence presented substantially advances the theoretical terrain on data efficiency and practical best practices in the training of code-centric LLM agents.

