- The paper demonstrates that pairing a trainable diffusion model with a reasoning-based verifier enables continual self-improvement in generative agents.
- It introduces a dual-scale memory system combining short-term in-context memory and long-term replay buffers to enhance semantic alignment and prevent forgetting.
- Empirical results reveal significant performance gains on benchmarks, with notable improvements in compositional reasoning, numerical accuracy, and attribute fidelity.
Continual Intelligence Growth in Generative Agents: The SuperIntelliAgent Framework
Introduction
The paper "Towards Continuous Intelligence Growth: Self-Training, Continual Learning, and Dual-Scale Memory in SuperIntelliAgent" (2511.23436) introduces a unified agentic learning pipeline that operates in a closed loop to achieve continual self-improvement for generative models. In this framework, a trainable small diffusion model (learner) is paired with a frozen, large reasoning-based verifier (LLM), forming a minimal, infrastructure-agnostic unit for intelligence accumulation. This approach directly addresses data scarcity, static training regimes, and brittle generalization in current foundation models by transforming normal inference into ongoing adaptation via self-supervised, preference-driven learning.
Methodology: Autonomous Preference Data and Dual-Scale Memory
SuperIntelliAgent formalizes autonomous self-training through explicit learner–verifier interaction. For each prompt, the learner synthesizes an output (e.g., an image); the verifier then decomposes the prompt into structured semantic conditions and evaluates the generation against these criteria via cross-modal entailment scores. The verifier further produces stepwise critique feedback, enabling the learner to refine its output over several iterations until all conditions are met. This No→Yes trajectory produces negative–positive preference pairs used for Direct Preference Optimization (DPO).
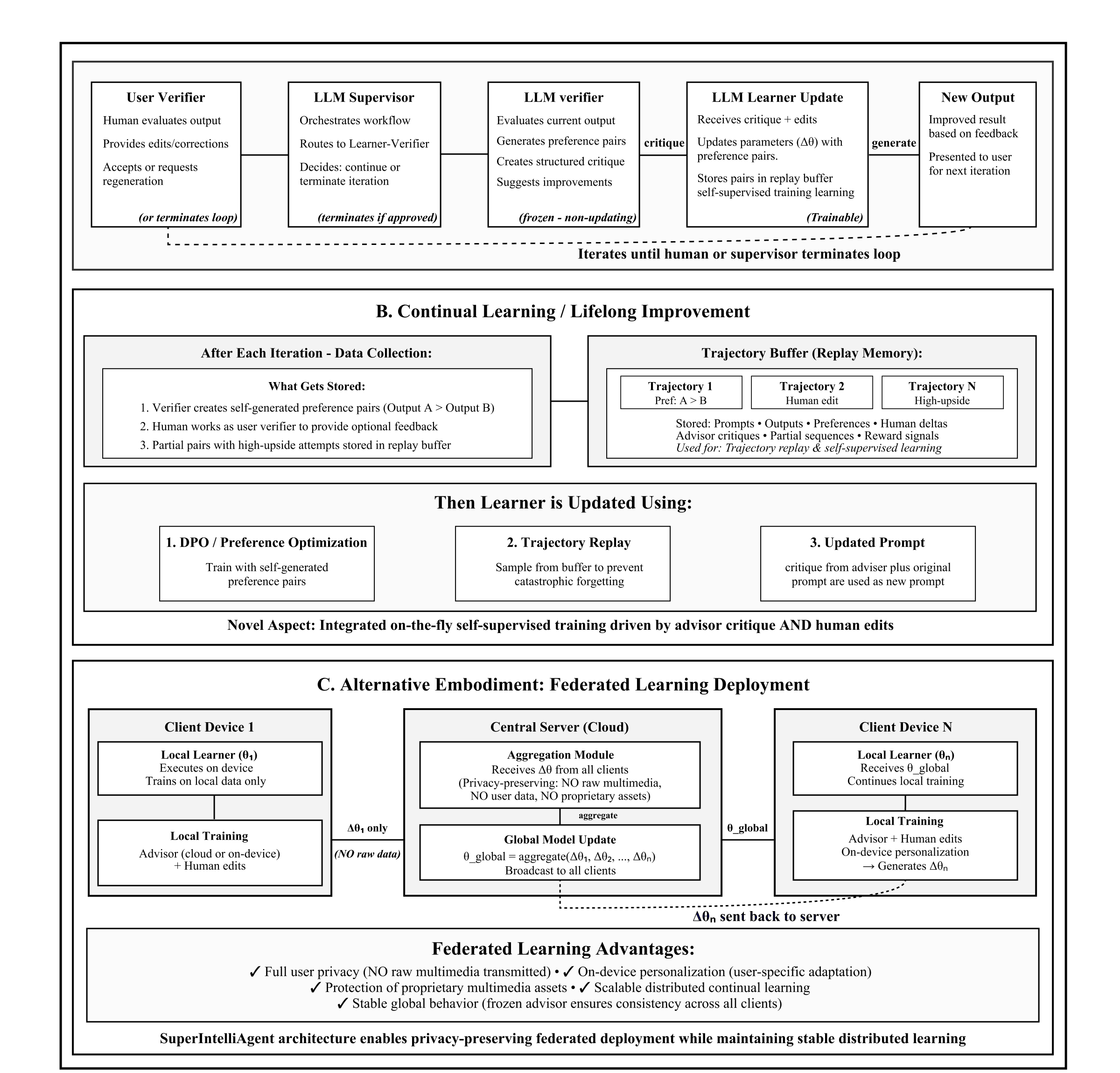
Figure 1: Overview of the SuperIntelliAgent pipeline, showing candidate output generation, semantic auditing, and asynchronous DPO-based adaptation.
A dual-scale memory system underpins this process:
- Short-term, in-context memory: Maintains reasoning traces and feedback within each iterative refinement cycle, improving sample-level semantic alignment.
- Long-term, consolidated memory: Stores progress traces and DPO pairs in a replay buffer, which are selectively replayed during fine-tuning to anchor incremental learning and accelerate curriculum adaptation.
Parameter-efficient LoRA updates allow for rapid, stable online fine-tuning even during inference, thus avoiding catastrophic forgetting and enabling lifelong adaptation.
Asynchronous Training Pipeline
SuperIntelliAgent decouples inference and model adaptation via asynchronous threads. While the learner and verifier continually generate new preference pairs from incoming prompts, training proceeds concurrently on batches of buffered pairs using a diffusion-compatible DPO loss. This asynchronous loop guarantees that inference and learning remain stable and efficient, enforcing bounded lag between generation and parameter updates.
Empirical results show that only a small fraction of prompts require adaptation—fine-tuning is triggered exclusively on hard samples where verifier feedback reveals room for improvement. Despite sparse supervision, substantial performance gains are observed in all benchmark settings.
Empirical Results: Quantitative Improvements and Scaling
SuperIntelliAgent was evaluated on GenEval, DPG-Bench, and T2I-CompBench, benchmarks for compositional, attribute-aligned text-to-image generation. The framework delivers consistent improvements over static baselines, both for small (Janus-1.3B) and larger (Janus-Pro-7B) diffusers.
- On GenEval, Janus-1.3B improves from 58.41% to 69.62% (Δ+11.21) and Janus-Pro-7B from 76.31% to 83.54% (Δ+7.23) after continual self-training.
- Largest gains are observed in counting, object relations, and position categories, supporting the claim that structured verifier feedback directly enhances compositional reasoning and numeracy.
- On DPG-Bench and T2I-CompBench, the framework achieves similar relative improvements despite training on less than 5% of all samples.
- Scaling analysis confirms that larger learners benefit disproportionately from continual learning, especially in challenging relational and numeracy tasks.










Figure 2: Qualitative comparisons of Janus outputs before and after continual SuperIntelliAgent training on GenEval prompts; spatial, attribute, and object coherence are consistently enhanced.










Figure 3: SuperIntelliAgent leads to visually accurate and compositionally robust outputs across complex DPG prompts, illustrating substantially improved detail adherence, relational grounding, and photorealistic fidelity.






Figure 4: Outputs for multi-object T2I prompts show more faithful object identities, distinct color bindings, and effective disambiguation after continual learning compared to the static baseline.
Theoretical and Practical Implications
SuperIntelliAgent formalizes self-supervised agentic learning by demonstrating that paired feedback with partial-history replay creates richer learning signals and complex adaptive curricula compared to monolithic preference optimization. This agent coupling is posited as a minimal reliable unit of growing intelligence, generalizable not only to vision but to multimodal, code, and math tasks via the same pipeline.
From a practical standpoint, SuperIntelliAgent integrates seamlessly with existing agentic orchestration frameworks (e.g., Semantic Kernel, AutoGen), providing plug-and-play ability for deployed models to evolve during normal usage. In production, this enables creative platforms (e.g., Vicino) to personalize generative outputs and align them with user-specific or studio-specific criteria, with empirical evidence for sustained quality and semantic gains.
The federated extension further allows distributed continual learning across diverse environments while retaining privacy via local LoRA adapter updates only. This architecture supports personalization and scalable intelligence growth across large user bases.
Limitations and Future Directions
The framework’s efficacy for weakly-supervised continual learning depends on the quality of verifier-generated preference signals. While LLM annotations are efficient for scale, they introduce annotation noise (10–40% error rate), particularly in nuanced cases compared to human curation. Hybrid strategies, combining rapid LLM annotation with selective human verification, are recommended for high-stakes deployment.
Future developments in agentic systems will likely build on this synergy, extending to more expressive preference models, richer experience replay strategies, and generalizing self-supervised continual learning to symbolic and multimodal domains. Federated architectures will also gain traction as privacy-aware model evolution becomes critical in production environments.
Conclusion
SuperIntelliAgent exemplifies a practical agentic pipeline for continual generative intelligence growth via tightly coupled learner–verifier interaction, dual-scale memory, and autonomous self-supervised preference synthesis. Empirically, the system delivers strong compositional, semantic, and attribute alignment improvements over static baselines with minimal, annotation-free supervision. This approach realizes infrastructure-agnostic, lifelong optimization in deployed models and suggests agentic pairing as a scalable minimal unit for sustained intelligence development. The implications extend to broad classes of AI systems, motivating future research in modular, self-evolving agent architectures.