- The paper introduces a modular system that diagnoses and targets specific agent deficits by synthesizing tailored RL environments based on contrastive error analysis.
- It employs LoRA adapter RL optimized on capability-specific tasks, achieving significant gains such as a +14.1 percentage point improvement on key benchmarks.
- TRACE’s modular routing strategy effectively avoids adapter interference, ensuring rapid, sample-efficient skill acquisition and scalable agent self-improvement.
TRACE: Capability-Targeted Agentic Training
LLMs deployed in agentic and interactive environments must proficiently execute a diverse set of capabilities, such as structured data reasoning, tool call sequencing, and error recovery, to successfully complete varied downstream tasks. Standard approaches, including reinforcement learning (RL) directly in the target environment or large-scale training on generic synthetic data, suffer from inefficient credit assignment. These methods offer little granularity in attributing failure to underlying missing capabilities, often yielding sparse or entangled reward signals. Consequently, even large-scale RL or fine-tuning is highly sample-inefficient as the agent must implicitly infer which specific behaviors need to be corrected.
TRACE (Turning Recurrent Agent failures into Capability-targeted training Environments) is proposed to explicitly address this bottleneck. It implements an end-to-end pipeline that automatically (1) identifies core agent capability deficits from rollout data, (2) synthesizes capability-targeted, verifiable RL environments offering dense reward for exercising those deficits, and (3) incrementally improves the agent via LoRA-based RL for each deficit, activating adapters via a lightweight classifier at inference.
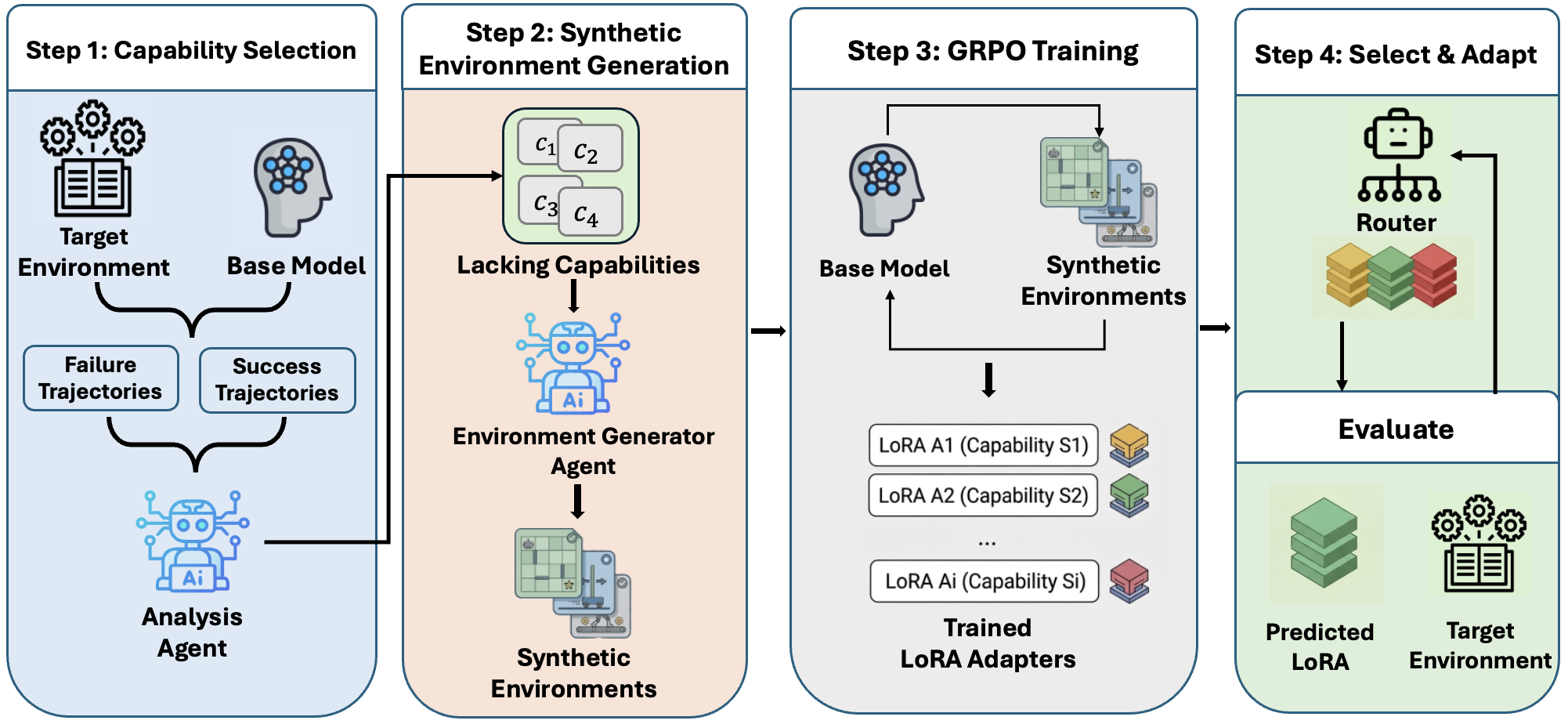
Figure 1: TRACE: An end-to-end system for automated environment-specific agent self-improvement, automatically identifying agent deficiencies and synthesizing tailored environment for each capability.
Automated Capability Deficit Identification
TRACE instantiates a systematic analysis pipeline. It collects successful and failed trajectories from agent rollouts in the target environment. An LLM-based analysis agent conducts contrastive analysis on tool calls, final states, and communications to construct a canonical dictionary of recurring, semantically distinct capabilities (e.g., "structured data reasoning", "precondition verification"). For each trajectory, the agent infers whether a capability is required, exercised, and correctly executed.
The analysis yields, for each capability, a contrastive error rate gap and failure coverage. Capabilities are ranked and prioritized for which (a) failures are significantly more common in unsuccessful rollouts than in successful ones, and (b) a substantial fraction of failures are explained by absence of this capability. To guarantee stability and robustness, this process is repeated across multiple random seeds and only recurrent, high-impact deficit categories are retained.
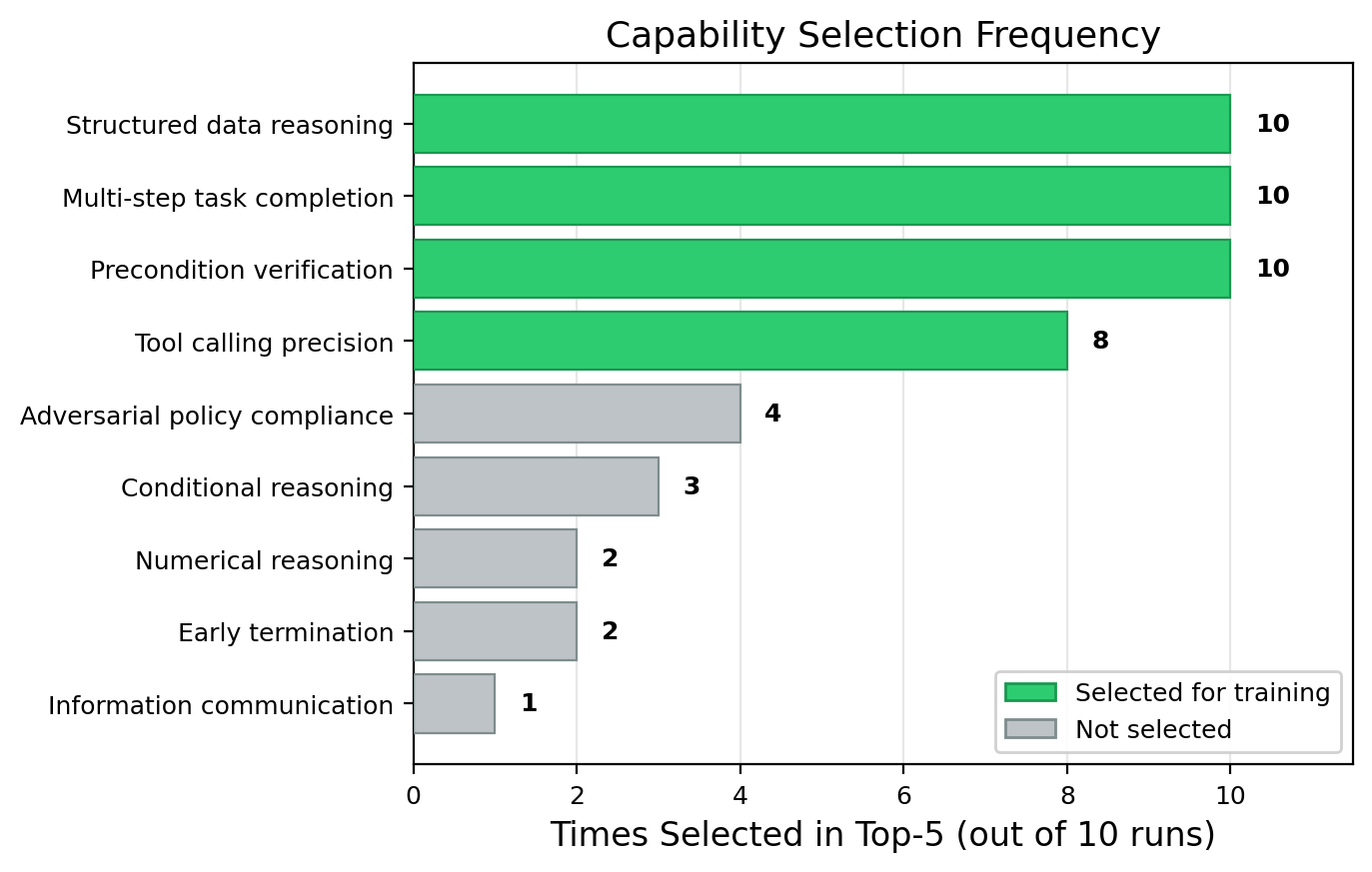
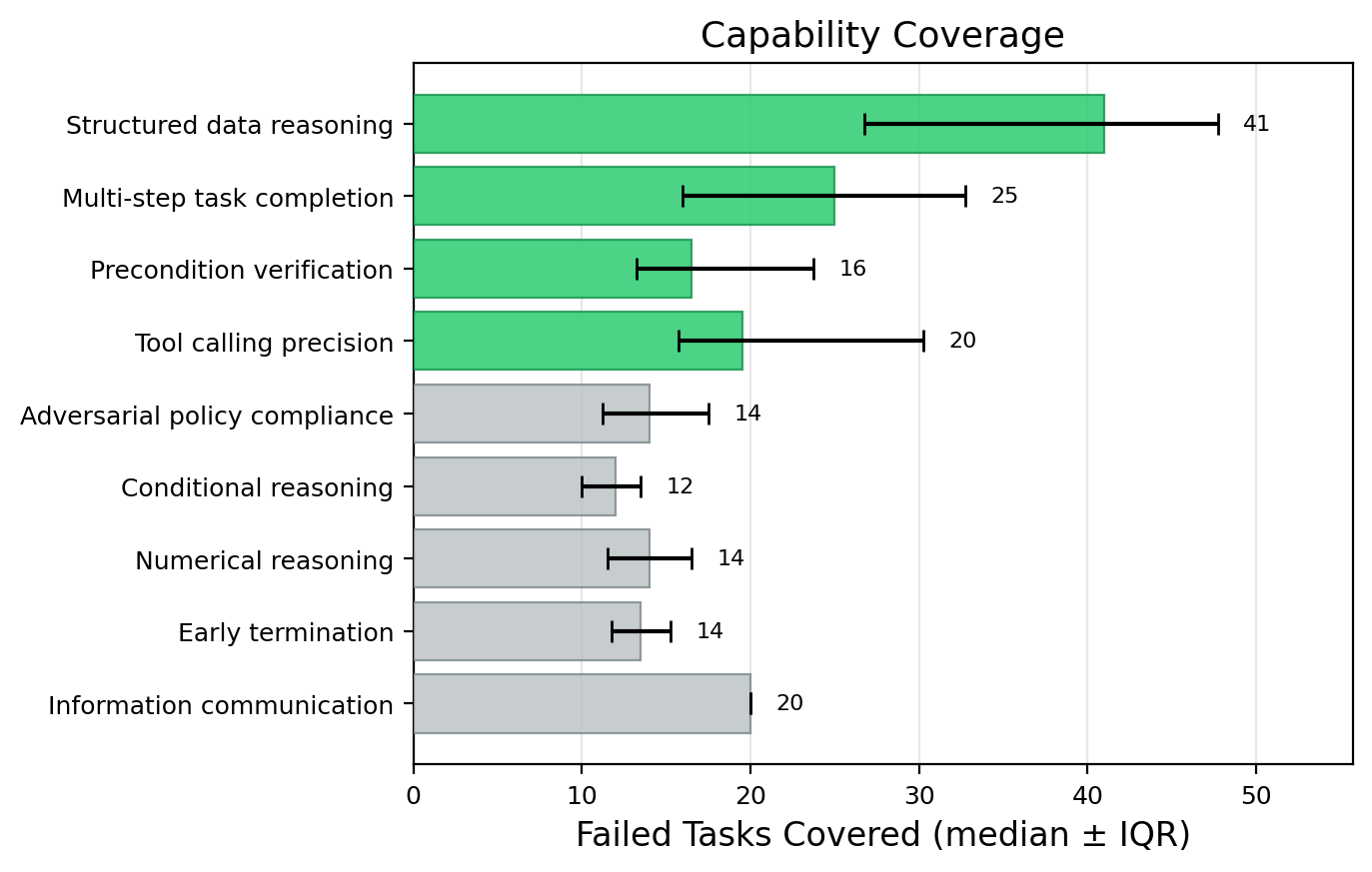
Figure 2: The analysis agent consistently selects the same top four deficits as principal missing capabilities, validating the robustness of the automatic identification pipeline.
Programmatic Synthesis of Capability-Targeted Training Environments
For each prioritized deficit, an LLM-based generation agent then synthesizes a verifiable, programmatically controlled environment specific to that capability. This environment encapsulates all realistic state and interface constraints of the target environment (e.g., tool APIs, input/output schemas) but isolates the desired skill as the bottleneck for success. Task instances are procedurally generated via deterministic seeding, ensuring endless diversity.
Crucially, reward is directly attributable to the exercise of the target capability—via explicit state verification, hash-matching, or automatic checking of correct tool protocols and result communication—thus providing dense training signals unattainable in the unmodified multi-capability environment. The synthesized environments enable scalable and robust RL for each targeted deficit, obviating the need for labor-intensive hand-crafted benchmarks or human annotation.
Efficient Capability Acquisition via LoRA Adapter RL
A separate LoRA adapter is initialized per deficit. Each adapter is optimized via a PPO-style RL algorithm on its respective synthetic environment, with the core backbone (e.g., Qwen3-30B-A3B) frozen. This approach exploits parameter-efficient adaptation by updating less than 5.3% of model parameters per skill, while preserving agent generality and avoiding catastrophic forgetting.
Notably, group-based reward normalization (GRPO) is employed to handle reward scale heterogeneity across environments and to stabilize training, leveraging batch-level trajectory variance. RL proceeds for a few steps (up to 40 iterations per adapter), leveraging strong reward signals for rapid competency gains.
Inference-Time Skill Routing and Composition
Rather than statically merging all adapters (which was empirically found to degrade or dilute per-capability gains), TRACE uses a training-free, lightweight routing strategy. At inference, the frozen base agent, supplied with the current task and an explicit enumeration of known capability categories and exemplar trajectories, selects the most relevant adapter by maximizing next-token logits over capability label tokens. Only the selected adapter is merged into the backbone for decoding; otherwise, the base model is used unmodified for out-of-distribution or unsupported tasks.
This method achieves optimal benefit from capability-specific training while eliminating adapter interference and avoiding the instability associated with standard adapter merging, task-vector arithmetic, or diffusion-style mixture approaches.
TRACE was evaluated on agentic benchmarks spanning both customer service and tool use: τ2-Bench and ToolSandBox. The ablation studies demonstrate:
- On τ2-Bench (customer service), TRACE achieved +14.1 percentage points higher overall pass rate than the base agent, and surpassed the strongest baseline (GEPA) by +7.4 points.
- On ToolSandBox (tool manipulation/testing), TRACE yielded a 0.141 improvement in mean similarity (trajectory match score) and +7 perfect completions (out of 129) over the base.
- Single-capability LoRA agents trained on isolated synthetic environments already outperform generalist synthetic approaches (AWM, ADP), even with fewer rollouts per environment.
When equated on total rollout budget, TRACE scales more efficiently than both general-purpose RL and prompt-optimization baselines (GEPA), showing monotonic improvement with further training while others plateau or even degrade with increased optimization.
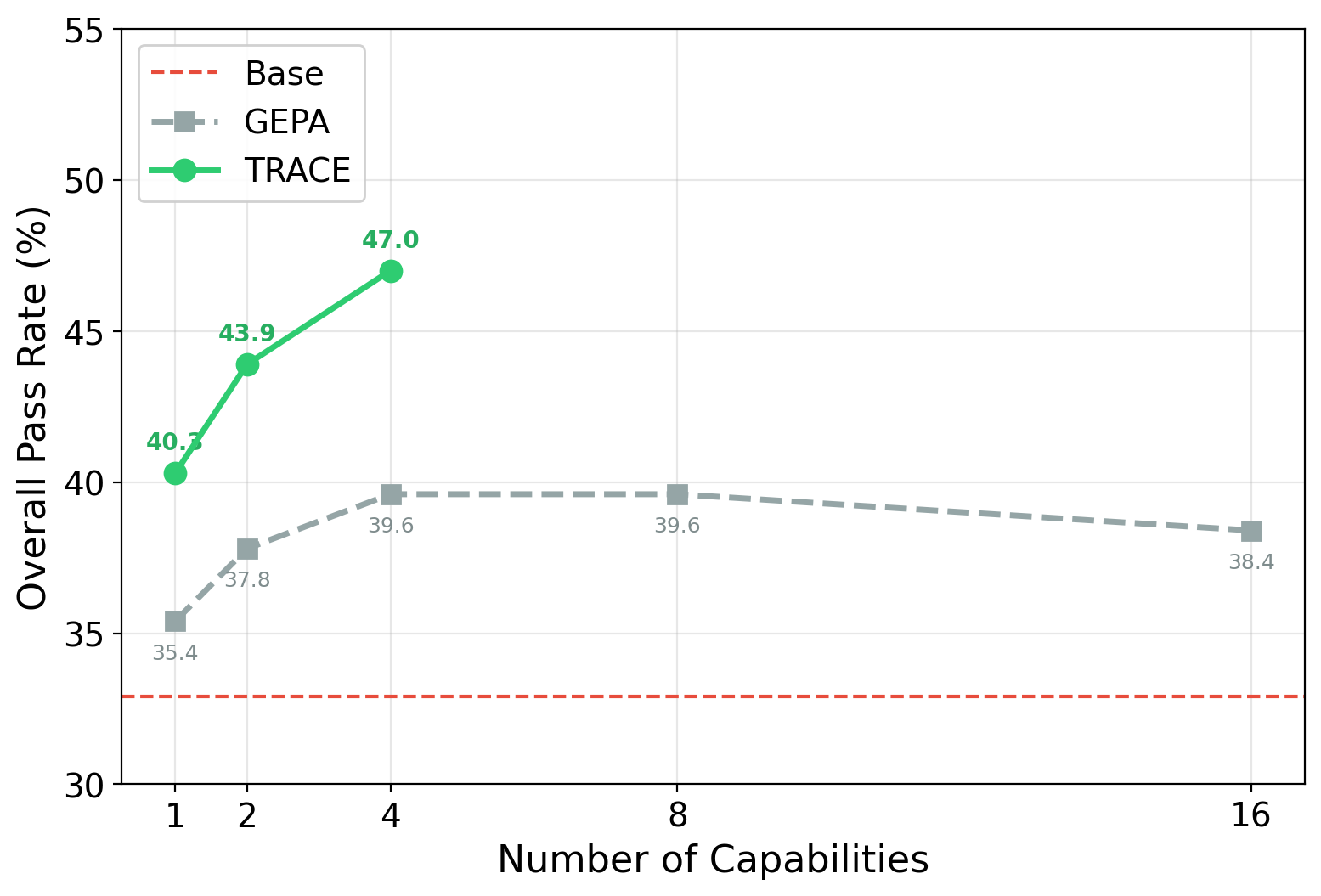
Figure 3: TRACE shows monotonic gains with additional capabilities, whereas prompt optimization (GEPA) saturates after four.
Analysis of Capability Distribution and Scaling
Contrastive analysis across 10 independent runs demonstrates that most environment failures are concentrated in a small, stable core of capabilities—chiefly "structured data reasoning," "multi-step completion," and "precondition verification." Together, these account for the majority of agent failures, supporting the claim that a narrow set of deficits drive most performance shortfall in structured agentic environments.
(Figure 2, again, emphasizes this stability and concentration.)
Further, performance scales efficiently as more adapters (up to 4) are added, with little marginal return beyond the principal deficits, quantifying the benefit of targeted intervention over blanket data scaling.
Adapter Consolidation vs. Routing
Empirically, attempts to consolidate all capability-specific adapters into a single model—whether via task-vector merging (CORE-TSV), multi-task RL, on-policy distillation, or SFT on the union of synthetic traces—result in either sub-optimal outcomes or even regression compared to individual adapters. Only TRACE's LoRA-per-capability plus classifier routing strategy preserves the full performance gains, supporting a modular, non-interfering composition paradigm.
Theoretical and Practical Implications
TRACE introduces a modular framework for the diagnosis and elimination of model-specific capability bottlenecks, uniquely coupling automatic contrastive analysis and programmatic environment synthesis. The empirical findings refute the default premise that blanket data scaling or direct RL suffices in complex multi-capability domains: explicit, capability-targeted environments and modular agent update yield superior and more sample-efficient generalization.
From a practical standpoint, TRACE enables self-improving agents to rapidly adapt to any new environment by autonomously discovering, targeting, and correcting their weakest links. This approach is immediately applicable to scalable agent deployment in code editing, workflow automation, and device control. The modular adapter composition admits straightforward extension via MoE-style routing architectures (Dou et al., 2023, Wu et al., 2024), supporting continuous accumulation of skills and lifelong learning under bounded compute.
Future Research Directions
Several avenues arise: tighter integration with MoE or dynamic router architectures for overlapping skills, more sophisticated skill discovery/abstraction pipelines, hierarchical capability modeling, and automated curriculum generation for adaptive agent development. Combining TRACE with cross-environment transfer can further accelerate agent mastery in broad, heterogeneous LLM agent deployment scenarios.
Conclusion
TRACE operationalizes a modular, end-to-end framework for automated, environment-specific LLM agent improvement. By precisely diagnosing missing capabilities from trajectory data, synthesizing dense-signal, verifiable RL environments, and incrementally acquiring skills via scalable LoRA adapters with inference-time routing, TRACE demonstrably surpasses existing RL, data scaling, and prompt-based approaches in efficiency and final performance. This methodology sets a paradigm for targeted, self-improving foundation agent training in complex multi-capability domains.