- The paper introduces DYPO, a unified SFT-RL framework that dynamically routes samples to balance SFT bias and RL variance for improved reasoning stability.
- It employs multi-teacher distillation and a Group Alignment Loss that mitigates supervisory bias and stabilizes RL gradients.
- Empirical results demonstrate gains, with up to a 4.8% accuracy improvement in in-distribution tasks and a 16.7% boost in out-of-distribution performance.
Dynamic Policy Optimization (DYPO): Bias-Variance Resolution in Unified SFT-RL Post-Training
Introduction and Motivation
LLM performance on robust multi-step reasoning tasks has been profoundly shaped by advances in post-training strategies. The two dominant paradigms—Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL)—offer contrasting advantages and limitations: SFT yields stable, low-variance optimization but introduces strong fitting bias via exposure to static demonstration data; RL enables bias reduction through interactive reward-driven learning, but suffers from high gradient variance, especially as reward signals become sparse or noisy. Naive unification strategies, commonly based on loss weighting or binary stage switching, inadequately resolve the fundamental statistical conflict between high-bias and high-variance objectives, and typically fail to adaptively route samples by their informational value.
This work introduces Dynamic Policy Optimization (DYPO), whose central contribution is a unified optimization framework that deploys instance-level routing of data to SFT or RL objectives based on dynamic difficulty grading. DYPO seeks to both structurally mitigate RL gradient variance and SFT bias, achieving a tractable compromise that improves generalization and stability across standard and out-of-distribution (OOD) reasoning benchmarks (2604.08926).
Framework Architecture
DYPO is based on three core methodological components:
- Dynamic Difficulty Grading: Group rollouts are used to separate prompts into Easy, Hard, and Mid categories, enabling targeted dispatch of samples to SFT or RL optimization regimes.
- Multi-Teacher Distillation: In the Hard regime (where the model uniformly fails to solve the problem), multiple teacher models generate distinct reasoning traces to reduce the idiosyncratic bias imposed by single-teacher SFT. This multi-source aggregation provably reduces overall bias magnitude, enhancing the robustness of policy initialization.
- Variance-Reduced RL via Group Alignment Loss (GAL): In the Mid regime (where generated responses exhibit variable correctness), RL optimization is stabilized by augmenting traditional Group Relative Policy Optimization (GRPO) with a contrastive loss that directly rewards correct rollouts while demoting failures, tightly bounding the RL gradient variance.
The systems-level data flow and pathway routing of DYPO are depicted in the following schematic.
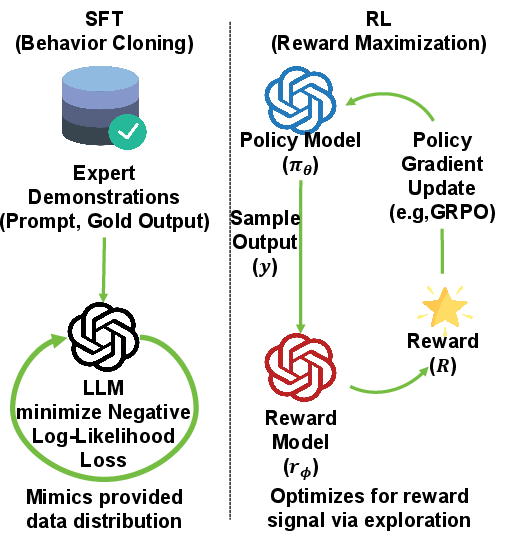
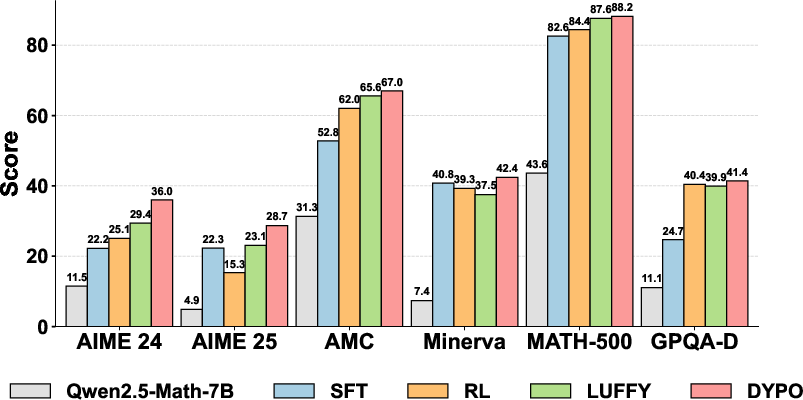
Figure 1: Data flow outlining Dynamic Policy Optimization, including sample grading and targeted dispatch to optimization submodules.
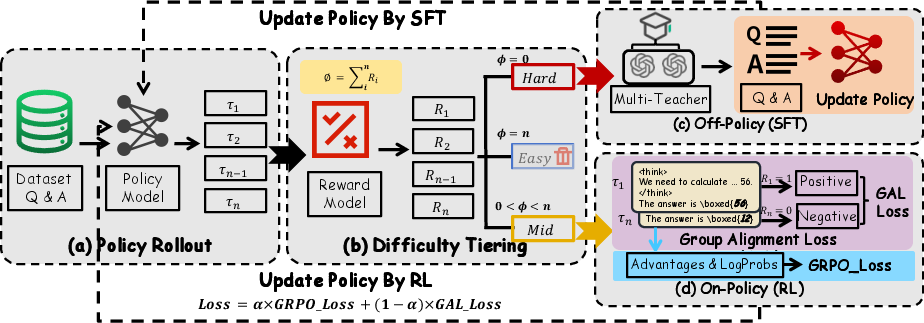
Figure 2: The DYPO framework employs dynamic grouping of samples for routing between SFT (Hard), RL (Mid), and exclusion (Easy) objectives.
Methodological Innovations
Dynamic Difficulty Grading
For each mini-batch, policies generate k rollouts per query. Three cases are recognized:
- Easy: All rollouts are correct; queries are omitted from loss computation for efficiency.
- Hard: All rollouts fail; SFT resumes, but with supervision from multiple teachers to reduce fitting bias.
- Mid: Rollouts include both successes and failures; GRPO and GAL are jointly applied.
This instance-level separation ensures that gradient updates are concentrated where learning is maximally informative while minimizing noisy gradient contributions from trivial or unsolvable examples.
Multi-Teacher SFT and Bias Reduction
Where traditional SFT is dominated by teacher-specific bias—leading to model trajectories overly close to particular teacher idiosyncrasies—DYPO employs trajectory sampling from m distinct teacher models. The bias variance decomposition demonstrates that this combination reduces the expected squared supervisory bias by a $1/m$ factor relative to the single-teacher baseline, with systematic bias as the irreducible minimum.
Group Alignment Loss: RL Variance Minimization
In the RL regime, standard GRPO involves high variance due to unbounded, group-standardized reward advantage scaling. GAL recasts the learning signal as a bounded contrastive loss: correct samples “pull” policy gradients, while failures “push” away, with pairwise log-probability differences relative to the reference policy. The variance of the GAL gradient estimator decays with learning progress and the discrimination margin, ensuring that as the model sharpens preference discrimination in rollouts, the RL objective becomes increasingly stable.
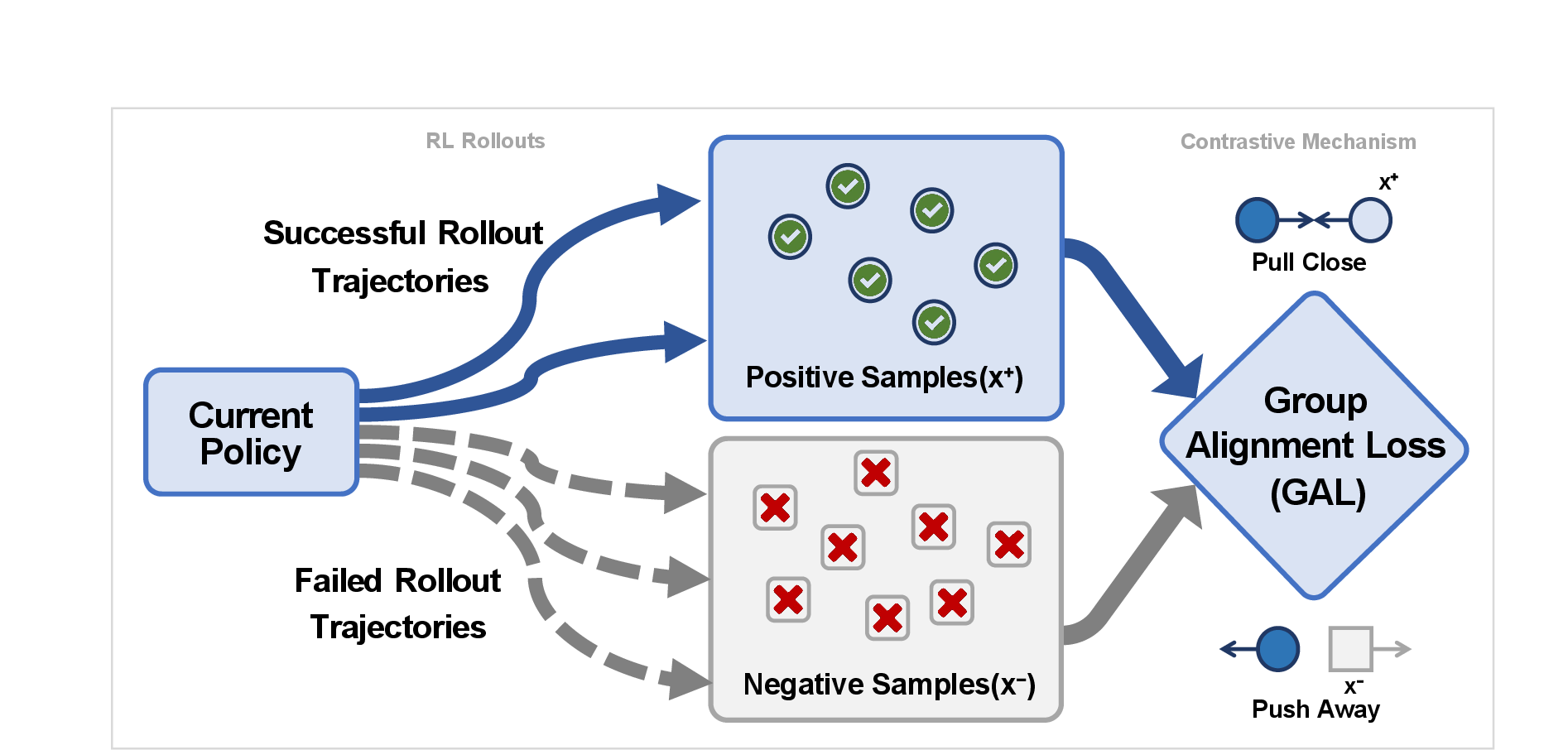
Figure 3: The GAL contrastive mechanism, contrasting correct and incorrect reasoning trajectories to efficiently guide policy gradients.
Numerical Results and Analysis
DYPO achieves consistent and substantial numerical improvements over both traditional sequential SFT-RL pipelines and advanced unified training baselines.
- In-distribution benchmarks: On Qwen2.5-Math-7B, DYPO outperforms SRFT and CHORD by margins up to 4.8% in average accuracy.
- Out-of-distribution generalization: On the GPQA-D benchmark, the system delivers a +16.7% improvement over the SFT baseline, demonstrating the transferability of reasoning capacity.
- Robustness to teacher scale: DYPO consistently improves accuracy even when only weak teacher models are available, with sample routing and RL-based exploration compensating for limitations in the supervision signal.
The ablation protocol reveals that the most significant performance increases are achieved by the introduction of dynamic grading and GAL, especially on the most challenging reasoning categories. Notably, the variance of policy gradients is empirically reduced, resulting in smoother and more reliable convergence.
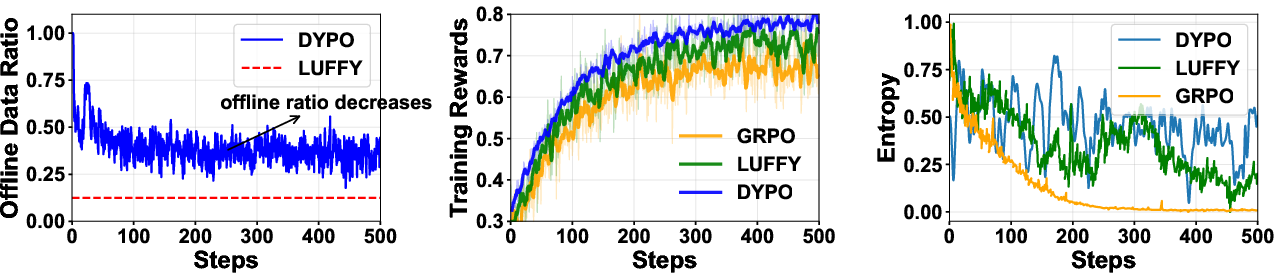
Figure 4: Left: progression of the offline data ratio as policy confidence grows; Mid: increase in training reward; Right: maintained policy entropy, indicating sustained diversity throughout RL-guided exploration.
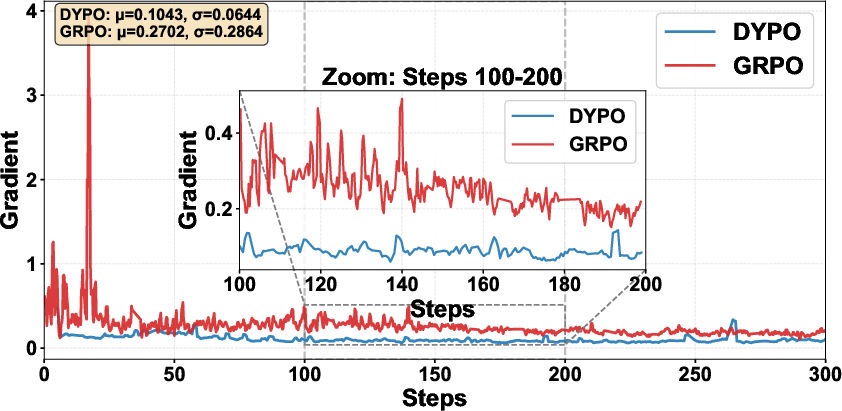
Figure 5: Empirical comparison of gradient norm variance; DYPO maintains gradient smoothness, in contrast to the volatility exhibited by GRPO.
Theoretical and Practical Implications
DYPO provides rigorous analytical substantiation that mixing objectives in unified SFT-RL post-training without structural bias/variance mitigation is fundamentally suboptimal. By leveraging difficulty-aware routing and statistically founded loss construction, DYPO minimizes error propagation and sample inefficiency inherent in sequential or naïve fusion approaches.
From a broader perspective, this instance-level adaptivity marks a paradigm shift from fixed, stagewise LLM post-training to dynamic and self-refining regret-minimization. The bias and variance reduction guarantees permit more aggressive exploration and sample efficiency, which is increasingly necessary as reasoning tasks and benchmarks grow in both complexity and diversity.
Prospects and Future Directions
DYPO’s framework is agnostic to LLM architecture, teacher model selection, and may support further generalizations such as open-ended creative generation or curriculum learning. Extensions to online sample selection, adaptive rollout sizing, and reward shaping for qualitative tasks present promising avenues. The continuing trend toward dynamic data curation, difficulty-aware supervision, and structured objective integration in LLM optimization is likely to build on principles formalized in this work.
Conclusion
DYPO establishes a new unified training paradigm that systematically addresses the inherent bias-variance conflict at the heart of SFT and RL. Through dynamic difficulty grading, multi-teacher distillation, and variance-controlled RL, it achieves significant gains in sample efficiency, optimization stability, and out-of-distribution performance. DYPO’s analytic and practical advances position it as a strong foundation for future LLM post-training architectures.