- The paper presents DGPO, which decouples probability gradient decay at clipping boundaries to prevent divergence and ensure stable training.
- It employs a bilateral mechanism using polynomial decay on the low-IS side and reciprocal decay on the high-IS side to balance exploration and exploitation.
- Empirical results on DeepSeek-R1 models demonstrate DGPO’s superiority over traditional hard and soft clipping methods in mathematical reasoning benchmarks.
Decoupled Gradient Policy Optimization: Advancing Stable Exploration in RLVR for LLMs
Introduction and Motivation
Reinforcement Learning with Verifiable Rewards (RLVR) has become the dominant post-training paradigm for aligning LLMs with task objectives, notably in mathematical reasoning domains. However, the intersection of policy stability and sustained exploration remains an unresolved bottleneck for scalable RLVR optimization. Standard approaches such as Generalized Reward Policy Optimization (GRPO) employ hard trust region clipping of importance sampling (IS) ratios, enforcing update stability at the cost of vanishing gradients for out-of-bound tokens, leading to entropy collapse and stunted exploration. More recent "soft clipping" techniques (e.g., CISPO, GPPO, CE-GPPO) attempt to mitigate these effects by allowing gradient flow outside the trust region. However, these methods rely on gradients of log-probabilities, which diverge as probabilities approach zero, inducing catastrophic instability—especially at the left (low-IS) boundary.
The discussed paper posits a paradigm shift: advancing the probability gradient, rather than the log-probability gradient, as the primary optimization primitive for RL in LLMs. This theoretical realignment motivates the introduction of Decoupled Gradient Policy Optimization (DGPO), a novel algorithm deploying a bilateral, decoupled decay mechanism for probability gradient weights across IS boundaries. DGPO achieves a principled balance between exploration and stability, rigorously resolves weight divergence, and empirically outperforms all strong baselines in mathematical reasoning tasks across DeepSeek-R1-Distill-Qwen model scales.
From Log-Probability to Probability: Rethinking the RL Primitive
Classical policy gradient estimation in RL, based on the log-derivative trick, has led to a research focus on ∇θlogπθ. However, the authors argue, and formally show, that RL objective maximization (for binary rewards) aligns directly with maximizing token probabilities (πθ), whereas Supervised Fine-Tuning (SFT) maximizes the log-probability lower bound. This subtle but fundamental divergence means probability itself is a more natural primitive for RLVR optimization in LLMs. Since probabilities are bounded and symmetric over (0,1) (in contrast to log-probabilities, which are unbounded and asymmetric), the design of stable, symmetric gradient updates is far more tractable in probability space.
The DGPO Algorithm
DGPO generalizes the IS ratio-based gradient update by introducing boundary-aware, decoupled decay for probability gradients:
- Left (Low-IS, Negative Advantage) Boundary: Employs a polynomial decay of the gradient weight as a function of the probability, preventing divergence as probabilities vanish.
- Right (High-IS, Positive Advantage) Boundary: Applies a reciprocal radical decay, sustaining exploration for high-IS tokens without inducing instability.
This decoupled design directly targets the "exploration vs. stability" tradeoff that undermines previous approaches. Importantly, DGPO ensures continuity and smoothness of the gradient estimator at clipping boundaries via analytically derived continuity constants, eliminating abrupt transitions and minimizing estimation bias with respect to the true policy gradient.
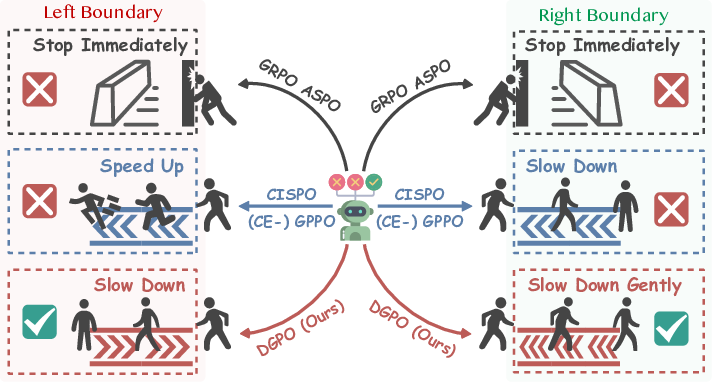
Figure 1: Schematic of DGPO mechanism relative to prior hard and soft clipping approaches, resolving the exploration-stability conflict through controlled boundary decay.
DGPO's generalized gradient weight function WDGPO depends on hyperparameters n (polynomial power, left) and m (radical degree, right), providing flexibility for entropy and exploration control across model scales.
Analysis: Theoretical Properties
DGPO achieves three central goals:
- Exploration Preservation: By retaining non-vanishing, adaptively decayed gradient weights for out-of-bound tokens, DGPO avoids premature entropy collapse, unlike GRPO and ASPO, and sidesteps the instability of CISPO/GPPO at low probabilities.
- Bias Minimization: DGPO's bias with respect to the true policy gradient is analytically minimized for in-boundary and boundary cases, with strict, formal ranking demonstrating its superiority for practical settings (especially for n=1).
- Symmetric, Controlled Entropy Dynamics: Decoupled hyperparameters n and m allow precise tuning of exploration and exploitation tradeoffs, balancing aggressive exploration with training stability for models of different capacity.
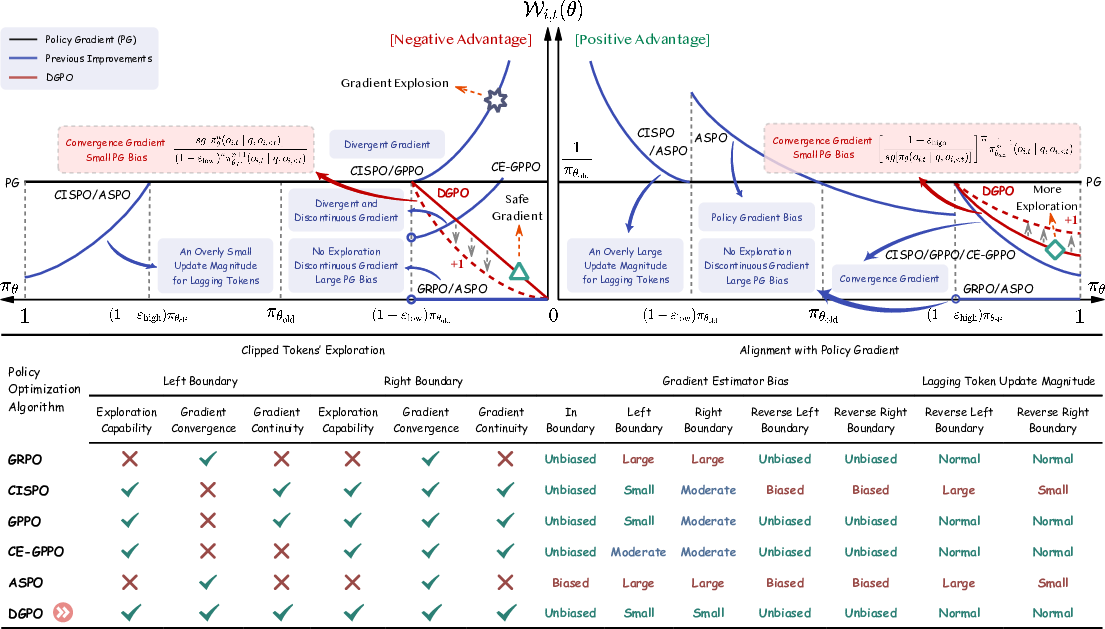
Figure 2: Comparative theoretical dynamics of gradient weights in DGPO, GRPO, CISPO, GPPO, CE-GPPO, and ASPO—the superior stability and consistency of DGPO are apparent.
Empirical Evaluation
Comprehensive experiments were conducted with DeepSeek-R1-Distill-Qwen-1.5B/7B/14B models on multiple math reasoning benchmarks (AIME24, AIME25, AMC23, MATH500, Minerva, OlympiadBench). The comparative results (Avg@32 and Pass@32 metrics) demonstrate that DGPO consistently and robustly outperforms all baselines, including hard and soft clipping algorithms.
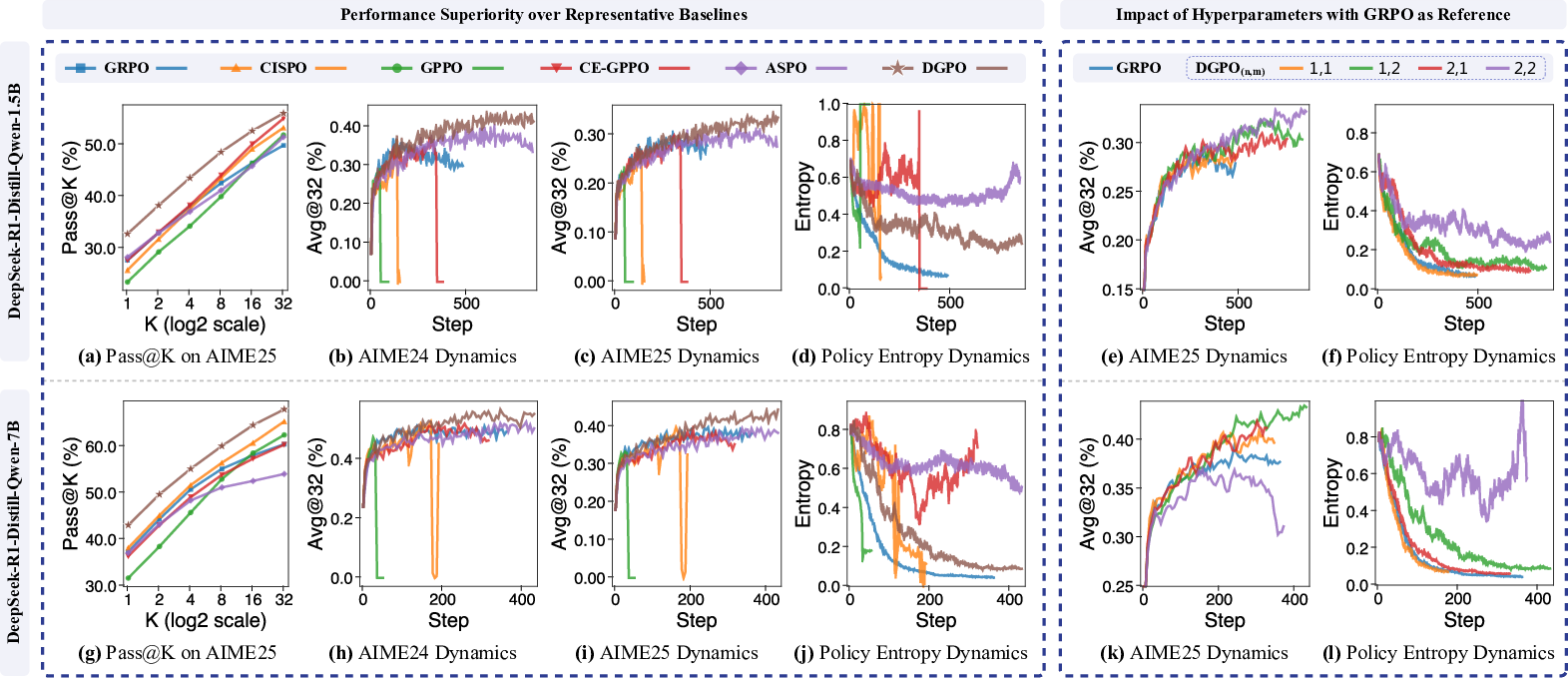
Figure 3: Training dynamics and performance comparison: DGPO demonstrates superior Pass@K and Avg@32 on AIME tasks, as well as stable entropy dynamics, across both 1.5B and 7B model scales.
Numerically, DGPO improves average Avg@32 by +4.3% (1.5B) and +3.1% (7B) over GRPO, and achieves the top results on virtually all tested benchmarks. Notably, DGPO prevents the training collapse observed in CISPO/GPPO/CE-GPPO at the left boundary, and avoids the entropy drop and underexploration seen in GRPO.
Hyperparameter Sensitivity and Scaling
Systematic analysis across n and m reveals that:
- Increasing n or m raises exploration and entropy but may induce instability at large model scales (e.g., n=m=2 on 7B yields unstable entropy).
- n=1, m=2 emerges as a robust, conservative baseline across all tested models, supporting scalable and transferable hyperparameterization.
- DGPO's efficacy extends up to 14B parameter models, maintaining improvement over GRPO on all metrics.
Mechanistic Visualization
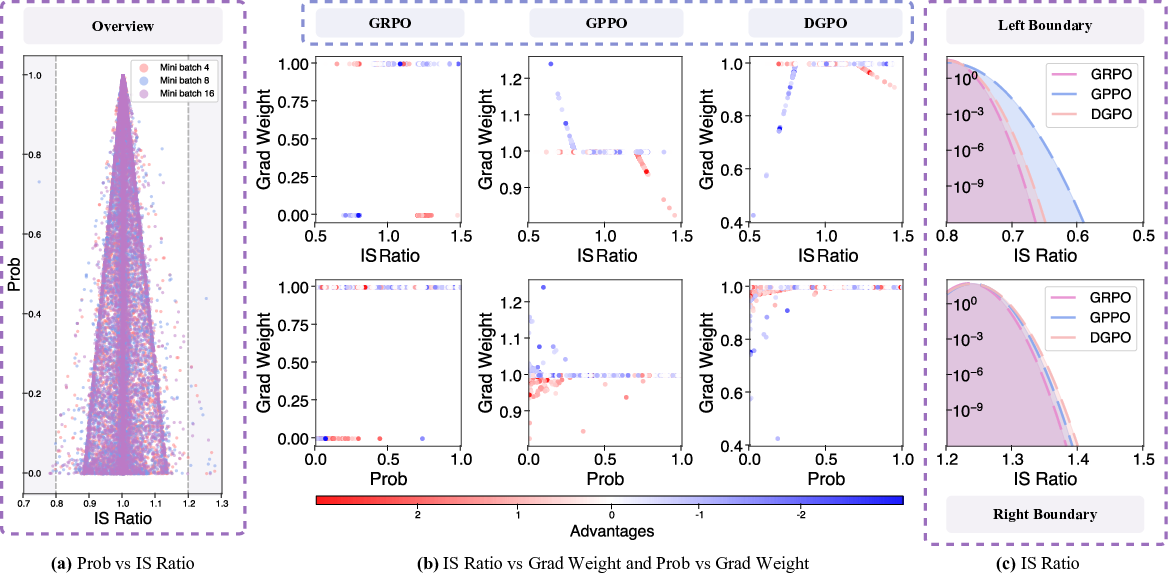
Figure 4: Visualization of probability and gradient weight distributions: DGPO maintains convergent, non-divergent boundary gradients and broader, more effective exploratory distributions than GRPO and GPPO.
DGPO achieves a unique balance between sufficient ratio support for exploration (wider IS ratio distribution) and suppression of pathological divergence at low probabilities—key to its stability.
Implications and Broader Impact
DGPO addresses previously unresolved algorithmic instabilities in RLVR post-training of LLMs, enabling theoretically-grounded, bias-minimized, and stable RL with verifiable rewards. By shifting the optimization focus from log-probability to probability, it offers a new lens for the design of trustworthy RL objectives in LLM alignment. The approach empirically scales across model sizes and supports practical, interpretable hyperparameter control of the exploration-exploitation tradeoff.
While the present work is demonstrated for mathematical reasoning—where verifiable, rule-based rewards are available—the analytic principles of probability gradient design and decoupled decay are generally extensible to other domains, contingent upon the structure of reward signals. Future research directions include extending DGPO's analytic framework to settings with sparse or subjective rewards, as well as exploring its role in large-scale instruction tuning and open-ended reasoning. The paradigm shift toward probability-based RL objectives could inform advances in both algorithmic stability and sample efficiency in LLM post-training.
Conclusion
DGPO establishes probability, rather than log-probability, as the correct optimization primitive for RL with verifiable rewards in LLMs, resolving the fundamental instability of soft clipping approaches. By implementing a bilateral, decoupled decay of probability gradient weights at IS boundaries, DGPO achieves simultaneous stability, minimal policy gradient bias, and sustained exploration, resulting in consistent empirical gains across benchmarks and model scales. This work provides both rigorous theoretical analysis and strong practical guidelines for scalable post-training of reasoning-competent LLMs.
References
For full bibliographic details and related works, see (2603.14389).

