- The paper introduces a unified reward-gated framework that dynamically switches between reinforcement learning and supervised fine-tuning based on reward signals.
- It employs per-instance loss selection to leverage high-quality demonstrations when RL fails to provide a learning signal, boosting sample efficiency and stability.
- Empirical results on benchmarks like GSM8K and MetaMath demonstrate significant performance gains in both dense and sparse reward environments.
SuperRL: A Unified Framework for Reward-Gated Integration of RL and Supervised Fine-Tuning in LLM Reasoning
Introduction and Motivation
SuperRL addresses a central challenge in post-training LLMs for complex reasoning: the integration of reinforcement learning (RL) and supervised fine-tuning (SFT) in environments with varying reward densities. While RL enables exploration and generalization by learning from both successes and failures, it is notoriously sample-inefficient and unstable under sparse reward regimes. Conversely, SFT leverages high-quality offline demonstrations but is limited to imitation, often failing to generalize beyond the provided data. Existing two-stage SFT+RL pipelines suffer from catastrophic forgetting and inefficient use of supervision, motivating a more adaptive, unified approach.
SuperRL proposes a reward-gated, per-instance switching mechanism that dynamically selects between RL and SFT updates based on the presence of nonzero reward in sampled rollouts. This design aims to maximize sample efficiency, stability, and generalization by leveraging the strengths of both paradigms without introducing additional hyperparameters or complex scheduling.
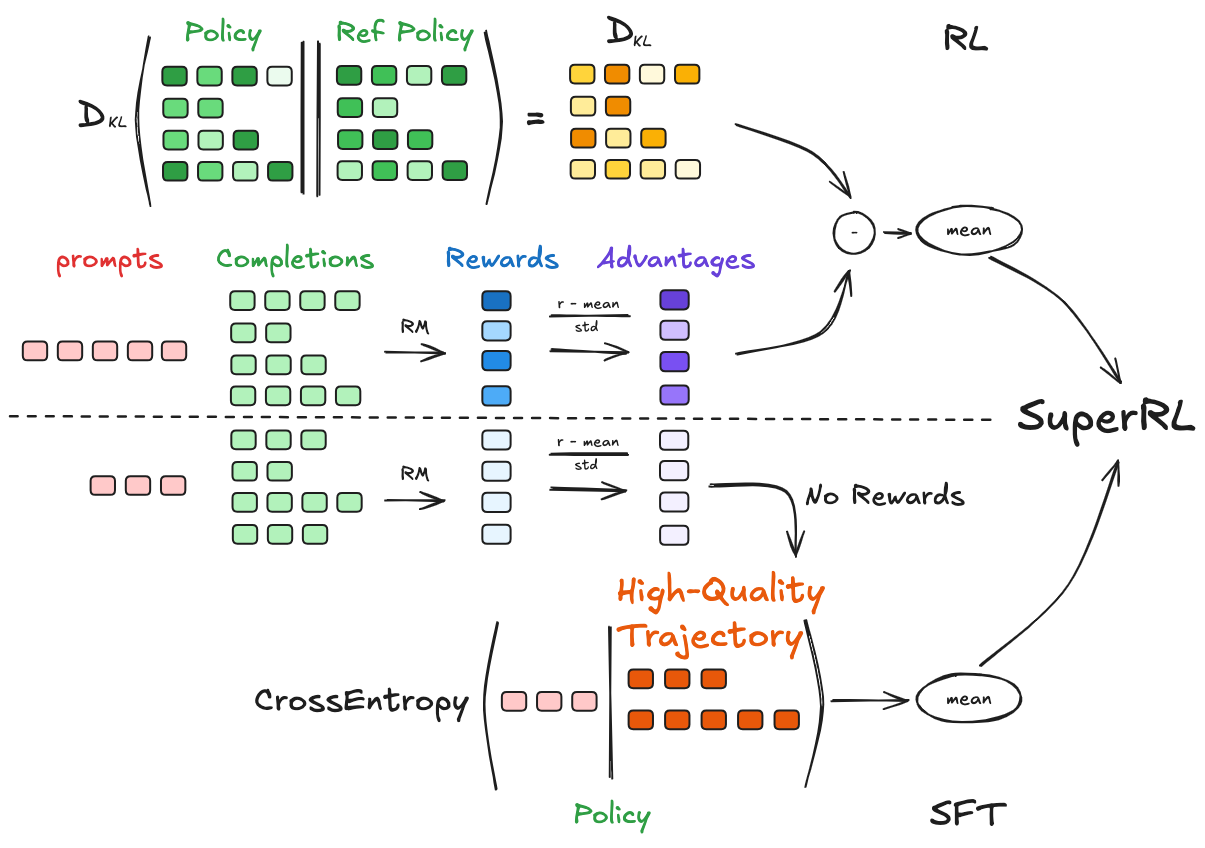
Figure 1: Overview of SuperRL. The framework adaptively combines RL and SFT based on reward signal, applying policy gradients when any rollout receives nonzero reward and falling back to SFT otherwise.
Methodology
Reward-Guided Loss Selection
For each training instance x, K trajectories y~1,…,y~K are sampled from the current policy πθ(⋅∣x), and their rewards R(x,y~k) are computed. If any trajectory yields a nonzero reward, a standard policy gradient update (e.g., PPO, GRPO) is applied. If all rewards are zero, the model performs SFT using available expert demonstrations. This is formalized as:
LSuperRL(θ;x)=(1−c(x))LSFT(θ;x)+c(x)LPG(θ;x)
where c(x)=1(maxkR(x,y~k)>0).
This instance-level, reward-gated switch is hyperparameter-free and data-driven, ensuring that SFT is only triggered when RL provides no learning signal, thus preserving exploration while preventing stagnation in sparse-reward settings.
Design Variants
Two relaxations are explored:
- Advantage-Gated Switching: RL is triggered only if any trajectory has strictly positive advantage Ak=R(x,y~k)−b(x), where b(x) is a baseline. This is more selective, filtering out uninformative or misleading reward signals.
- Uncertainty-Weighted Hybrid Fusion: A continuous, learnable fusion of RL and SFT losses, weighted by learned log-variance scalars, allowing the model to adaptively balance the two objectives.
Empirical Evaluation
Benchmarks and Experimental Setup
SuperRL is evaluated on a suite of reasoning benchmarks, including GSM8K, MetaMath, PRM12K, OpenR1, LIMO, and HiTab, covering both dense and sparse reward regimes. Multiple model families (Qwen2.5, LLaMA 3.x, DeepSeek-R1 Distilled) and sizes (0.5B–8B) are used to ensure robustness across architectures and scales.
Training Dynamics and SFT Activation
SuperRL demonstrates adaptive SFT activation patterns: SFT is heavily used in early training, especially on hard or sparse-reward datasets (e.g., LIMO), and fades as the policy improves. This adaptivity is critical for bootstrapping learning in challenging regimes and is reflected in the SFT trigger statistics.
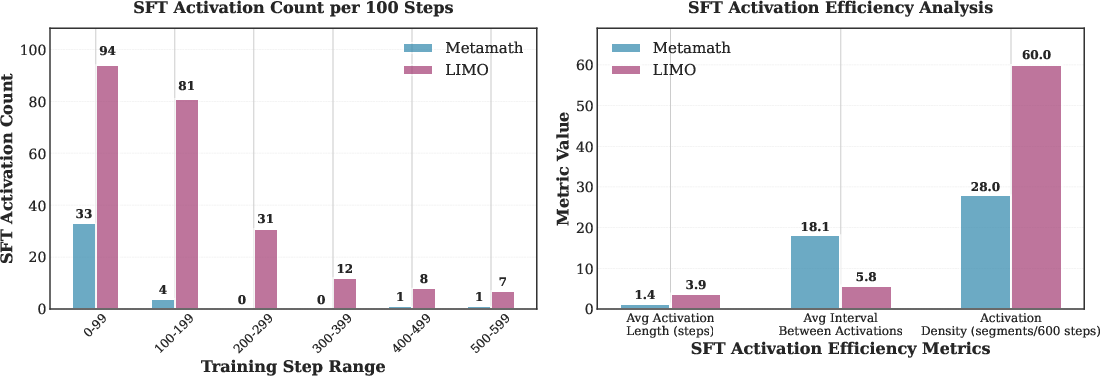
Figure 2: SFT activation patterns and efficiency. LIMO exhibits denser and more sustained SFT activation, indicating higher reliance on supervision in sparse-reward, hard-exploration settings.
SuperRL consistently outperforms vanilla RL and two-stage SFT+RL across most benchmarks, with the largest gains observed in settings with moderate to high reward sparsity. For example, on GSM8K, SuperRL achieves a final Reward Mean@1 of 0.774 (7.9% improvement over RL), and on MetaMath, a 13.3% gain is observed. On LIMO, SuperRL delivers a 229% improvement in dense reward settings.
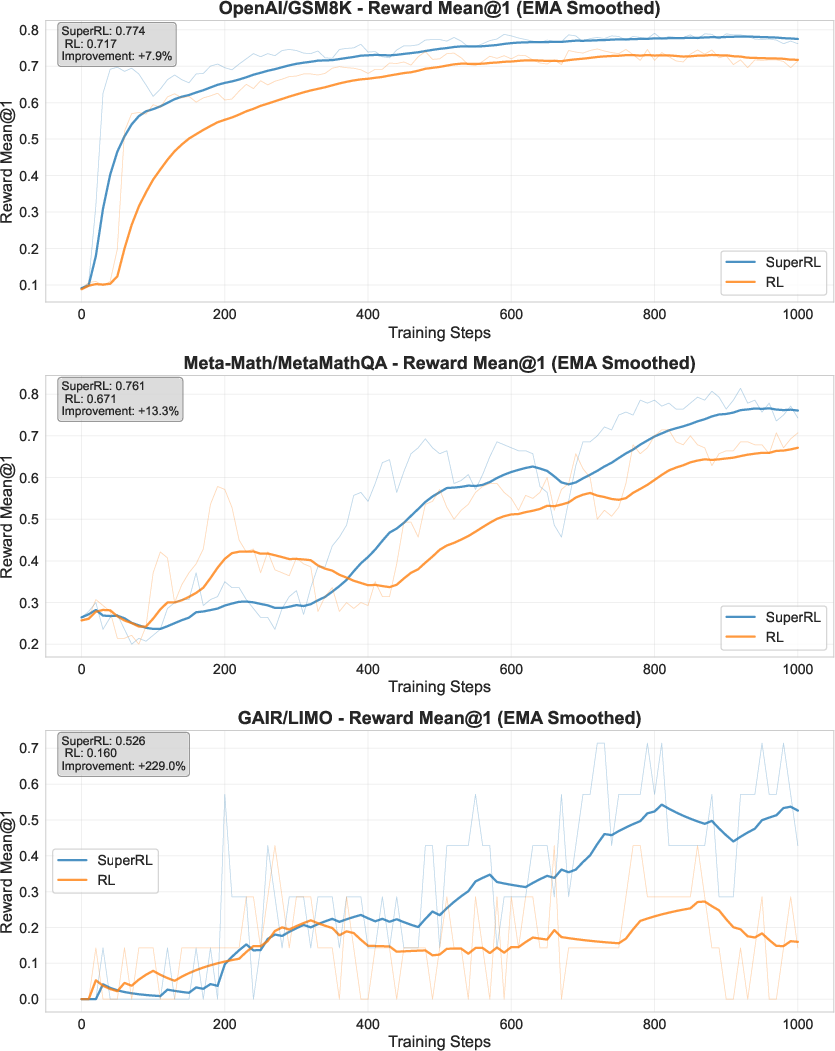
Figure 3: Training curve on GSM8K (dense reward). SuperRL achieves higher and more stable performance than RL, with a clear divergence as training progresses.
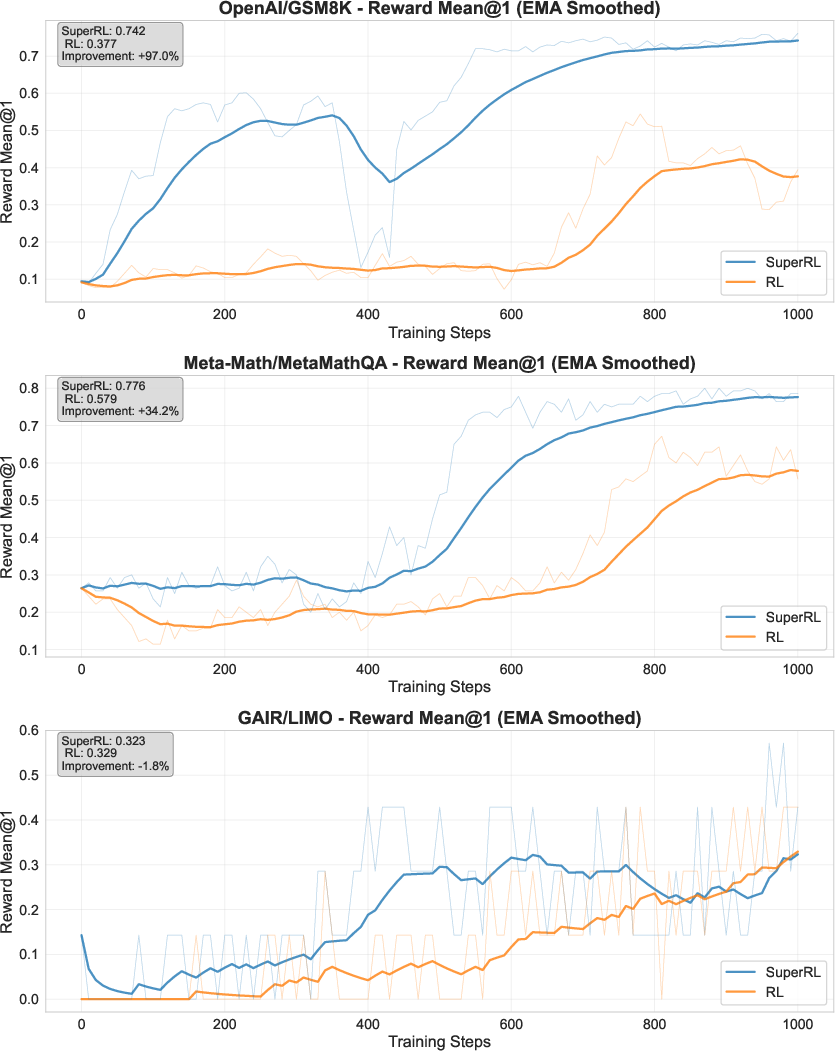
Figure 4: Training curve on OpenR1 (sparse reward). SuperRL maintains a significant edge over RL, demonstrating robust learning under sparse supervision.
Cross-dataset generalization analysis further demonstrates that SuperRL-trained models transfer better to out-of-domain tasks, except in cases where the training data is extremely limited or highly filtered (e.g., LIMO, HiTab), where longer SFT exposure or more selective gating may be beneficial.
Stability and Entropy Analysis
SuperRL reduces entropy variance and range compared to RL, indicating more stable optimization. However, excessive SFT fallback can over-constrain exploration, particularly in ultra-sparse or small datasets, suggesting a need for careful balance between exploration and imitation.
Hybrid Variants
Advantage-gated and uncertainty-weighted hybrids offer marginal improvements in specific scenarios (e.g., LIMO, HiTab) but generally underperform compared to the original reward-gated SuperRL, which achieves the best trade-off between simplicity, stability, and generalization.
Implementation Considerations
- Integration: SuperRL can be implemented as a lightweight wrapper around standard RL training loops, requiring only per-instance reward checks and access to offline demonstrations.
- Computational Overhead: The fallback to SFT does not introduce significant computational cost, as SFT updates are only triggered when RL fails to provide a gradient signal.
- Scalability: The framework is compatible with large-scale distributed training and can be applied to any model family supporting policy gradient updates and SFT.
- Reward Design: Binary or shaped rewards can be used, but reward observability and quality are critical for effective gating.
- Data Requirements: Access to high-quality demonstrations is assumed for SFT fallback; in domains lacking such data, synthetic or self-improving traces may be necessary.
Implications and Future Directions
SuperRL demonstrates that simple, reward-gated integration of RL and SFT can substantially improve reasoning performance, sample efficiency, and generalization in LLMs. The approach is robust across architectures, scales, and reward regimes, and is particularly effective in sparse-reward or hard-exploration settings. However, limitations remain in ultra-sparse or domain-specific tasks, where more proactive or uncertainty-aware fallback strategies may be required.
Future research directions include:
- Proactive or learned gating schedules that adapt to both reward sparsity and demonstration density.
- Fully unified objectives that softly interpolate between SFT and RL signals.
- Extension to interactive, agentic, or long-horizon environments.
- Integration with test-time search or planning methods for further robustness.
Conclusion
SuperRL provides a principled, practical, and broadly applicable framework for unifying RL and SFT in LLM reasoning. By leveraging reward-gated, per-instance switching, it achieves superior performance, stability, and generalization across diverse reasoning benchmarks, while maintaining simplicity and scalability. The framework opens new avenues for adaptive training paradigms that blend exploration, supervision, and search in large-scale LLMs.