Visually-grounded Humanoid Agents
Abstract: Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Visually-grounded Humanoid Agents — A simple explanation
1) What is this paper about?
This paper shows how to create digital people (humanoids) who can see, think, and move on their own inside realistic 3D worlds built from real videos. Instead of just “playing back” pre-recorded animations, these digital people look around from their own point of view, make plans, and walk toward goals while avoiding obstacles—much like real humans would.
2) What questions are the researchers trying to answer?
The team focuses on three big questions:
- How can we turn ordinary videos of real places into detailed 3D worlds that digital people can move around in?
- How can we give digital people the ability to “see” from their own eyes and plan smart paths toward goals (like “go to the restaurant” or “walk to the car”)?
- Can these digital people act safely and successfully in many different places, not just a single, specially prepared scene?
3) How does their system work? (Simple breakdown)
Think of the system as having two layers—like a stage and the actors:
- World Layer (the stage):
- From regular videos of a street or room, the system builds a 3D model of the place. Imagine making a tiny virtual city by stacking lots of soft, glowing dots (these are called “3D Gaussians”) that together form buildings, sidewalks, trees, and more.
- It also figures out what each thing is (semantics), such as “bench,” “restaurant sign,” or “trash can.” This is like adding labels to everything so the agent knows what to look for.
- “Occlusion-aware” means it’s careful when some objects are hidden behind others—like noticing a hydrant behind a parked car—so the scene labels are accurate and not mixed up.
- The world includes invisible collision shapes so agents don’t walk through walls or bump into cars.
- Agent Layer (the actors):
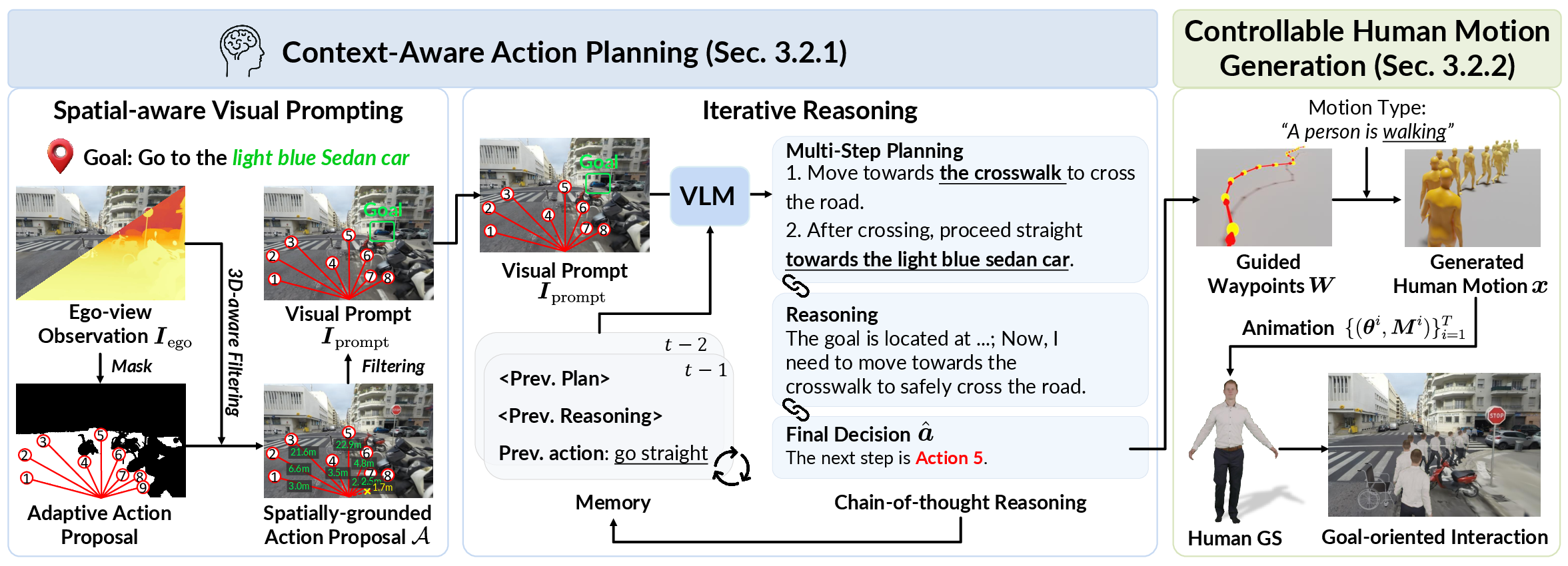
- Vision: Each digital person sees the world from a first-person view (like wearing a GoPro), with both color and depth (how far things are)—similar to how a game character “sees” the world.
- Planning: A vision-LLM (an AI that understands both images and words) helps the agent pick what to do next. The researchers add “spatial visual prompts,” like drawing safe directions on the image, and “goal highlighting,” like putting a box around the target. This helps the AI reason about space and choose a safe, sensible direction.
- Iterative reasoning: Instead of deciding once and hoping for the best, the agent rethinks the plan step by step—like a student checking their work as they go—so it can handle long walks, turns, and blocked paths.
- Motion: After deciding “walk this way,” a motion generator (think: a tool that turns plans into lifelike moves) creates full-body animations so the avatar walks naturally to the next waypoint.
In everyday terms: the system builds a lifelike stage from video, gives the digital person eyes and a memory, suggests safe directions on-screen, and then turns those choices into realistic body movements.
4) What did they find, and why does it matter?
The researchers tested their agents in different 3D environments—both outdoor streets and indoor spaces—and created tasks like:
- Simple Navigation (go to a visible place),
- Obstacle Navigation (reach a goal while avoiding barriers),
- Social Navigation (move safely among other moving people),
- Multi-Goal (visit several landmarks in order).
Key results:
- Higher success rates: Their agents reached the goals much more often than strong existing methods.
- Fewer collisions: They avoided bumping into things and people more reliably.
- Better long trips: The step-by-step (iterative) reasoning helped with long, tricky routes, even when the goal was far away or temporarily hidden.
- Stronger scene understanding: Their way of labeling objects in large outdoor 3D worlds (with occlusion-aware tricks) beat other methods, making the environment more reliable for navigation.
Why this matters:
- It shows we can fill any 3D world with digital people who act on their own in believable ways, not just follow scripts. That’s useful for games, movies, virtual reality, training robots, or simulating crowds safely.
5) What’s the bigger impact?
This work is a step toward digital humans who understand their surroundings and act purposefully—like going to a specific store, crossing a busy plaza, or navigating a crowded lobby—without needing hand-written instructions. With better, more realistic agents:
- Virtual worlds can feel more alive and interactive.
- Robots can learn from human-like behavior in safe simulations before operating in the real world.
- Researchers can study human-centered navigation and social behaviors at scale.
The authors plan to open-source their data, code, and models, encouraging others to build on this foundation and explore skills beyond navigation, like conversation and richer physical interactions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- World reconstruction: Quantify scalability (runtime, memory, and Gaussian count) of the occlusion-aware semantic pipeline as scene size and view count grow; provide complexity analysis and resource bounds.
- Dependency on 2D segmentation: Assess robustness to SAM failures (under/over-segmentation, outdoor floor/traversability errors, thin objects) and explore alternative or learned 2D/3D segmentation to reduce reliance on SAM.
- Sparse/occluded supervision: Characterize minimal view coverage needed for reliable 3D instance features; study failure modes under extreme occlusions and limited viewpoints, and propose recovery strategies.
- Open-vocabulary labeling quality: Evaluate VLM-based instance naming beyond mIoU/mAcc (e.g., label precision/recall, synonym consistency, cross-scene consistency, multilingual robustness); analyze hallucination and ambiguity handling.
- Physical fidelity of the world: Integrate or benchmark against physics (friction, gravity, collision response) beyond static collision meshes; measure the impact on agent behavior and safety.
- Dynamic environments: Extend reconstruction to dynamic scenes (vehicles, crowds, moving objects, weather/time-of-day changes) and test agent robustness under temporally evolving geometry/semantics.
- Traversability estimation: Replace heuristic SAM-based ground segmentation with geometry-aware models (slope, stairs, curbs) and dynamic obstacle reasoning; quantify gains in safety and goal completion.
- Agent sensor realism: Inject realistic noise in RGB-D, camera pose, and latency; study robustness to degraded sensing and ego-motion drift; evaluate need for active perception (head scanning, look-around).
- Localization and mapping: Remove reliance on simulator ground-truth pose by adding visual odometry/SLAM; compare local-only reasoning to global/topological mapping for long-horizon tasks.
- Use of world-layer semantics in planning: Move beyond purely VLM-based selection by integrating 3D semantic maps directly into planning (graph search, mesh routing, occupancy grids); compare hybrid planners to VLM-only approaches.
- Baselines beyond VLN: Benchmark against classical navigation stacks (SLAM + global/local planners, kinodynamic + social force models) and modern geometric planners to contextualize gains.
- Action discretization: Analyze sensitivity to number/orientation of directional primitives and step size; compare to continuous control policies and adaptive direction sampling.
- Runtime and real-time feasibility: Report per-step latency and throughput of VLM prompting and motion diffusion; profile bottlenecks and trade-offs with VLM query frequency and prompt complexity.
- Iterative reasoning limits: Quantify memory horizon, prompt growth, and degradation over long episodes; investigate compact/structured memory or visual memory maps to prevent forgetting or prompt bloat.
- Failure recovery and uncertainty: Add confidence estimates for VLM decisions, detect hallucinations, and design fallbacks (e.g., conservative local planner) when visual/text cues conflict.
- Social navigation: Model and evaluate multi-agent norms (proxemics, right-of-way, group interactions), trajectory forecasting of others, and negotiation; move beyond simple collision avoidance in SocialNav.
- Multi-agent coordination: Test scenarios with multiple autonomous agents (not scripted distractors), measuring coordination metrics, fairness, and emergent behaviors.
- Physical motion realism: Incorporate contact-aware control (foot-ground contacts, slip avoidance, balance), dynamics constraints, and measure motion quality (foot-skate, pose realism) with standard metrics.
- Manipulation and affordances: Extend beyond navigation to object interactions (door opening, sitting with correct contacts, grasping), define tasks and metrics, and link semantics to affordance-aware control.
- Language generalization: Evaluate instruction diversity (compositional, ambiguous, multi-step, distractors), paraphrase robustness, and cross-lingual performance; quantify how visual prompting scales with linguistic variability.
- Moving and occluded targets: Add benchmarks for tracking and reaching moving/occluded goals; measure re-planning speed and success under persistent occlusion.
- Benchmark scale and diversity: Expand scenes across cities, cultures, terrains, day/night, weather; publish larger-scale ground-truth semantics (3D instance labels) to standardize evaluation beyond 240 curated samples.
- Avatars and population diversity: Increase avatar count and diversity (age, body types, clothing/occlusion, assistive devices), and study the impact on planning and social compliance.
- Planning–execution interface: Compare waypoint-guided diffusion to alternative low-level controllers (model predictive control, RL policies) and analyze stability in narrow passages and tight maneuvers.
- Head, gaze, and attention: Add head/gaze control for improved perception and social signals; evaluate its effect on collision avoidance and social acceptability.
- Energy/safety constraints: Introduce explicit safety margins and energy-aware objectives; evaluate formal guarantees (e.g., control barrier functions) for zero-collision operation.
- Robustness to adversarial or rare events: Test VLM susceptibility to adversarial visual prompts and unusual signage/landmarks; develop defenses or validation layers.
- Sim-to-real transfer: Articulate requirements and gaps for deploying the agent on physical humanoids (sensing, latency, dynamics), and evaluate transferability with hardware-in-the-loop tests.
- Reproducibility and cost: Report training/inference costs for world+agent layers (GPU hours, memory), and provide scaling rules to guide adoption in resource-constrained settings.
Practical Applications
Below are actionable applications derived from the paper’s methods and findings, grouped by deployment horizon. Each item lists likely sectors, what can be done, potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Digital pre-visualization and crowd simulation in real locations
- Sectors: Media/entertainment, gaming, advertising, events
- What: Reconstruct a venue or streetscape from video and populate it with autonomous, visually grounded digital humans for pre-viz, shot planning, and gameplay prototyping without manual scripting.
- Tools/workflow: 3DGS-based scene reconstruction with occlusion-aware semantics; animatable Gaussian avatars; VLM planner with spatial visual prompting; motion diffusion for full-body animation; export to Unity/Unreal via collision meshes and camera paths.
- Assumptions/dependencies: High-quality monocular video of the space; compute/GPU for 3DGS optimization and VLM/diffusion inference; rights to scan and use the location; static or slowly changing environments for best fidelity.
- Urban planning and pedestrian flow studies
- Sectors: Urban planning, architecture, civil engineering, transportation
- What: Evaluate walkability, wayfinding, and bottlenecks by simulating autonomous pedestrian navigation toward semantically labeled landmarks (e.g., crosswalks, bus stops) in reconstructed city blocks.
- Tools/workflow: Occlusion-aware semantic scene reconstruction to produce instance-level landmarks; agent-layer navigation benchmark to run “SimNav/ObstNav/SocialNav” scenarios; analytics on success rates, path lengths, collisions.
- Assumptions/dependencies: Sufficient semantic coverage and accuracy (open-vocabulary VLM annotations); representative capture of crowd obstacles; policies for using city imagery; validation against real counts.
- Store layout and signage A/B testing
- Sectors: Retail, wayfinding/UX, facilities management
- What: Assess how autonomous agents find products, counters, or exits in a reconstructed store; test alternative shelf/signage placement by measuring navigation success and collision rates.
- Tools/workflow: Reconstruct store from walkthrough videos; tag shelves/displays with open-vocab labels; run multi-goal tasks; iterate designs in sim before real changes.
- Assumptions/dependencies: Clear visibility of objects for 2D→3D lifting; stable lighting and occlusion handling; privacy-safe capture after-hours.
- Training and safety drills in digital twins
- Sectors: Aviation, logistics/warehousing, manufacturing, campus security
- What: Author scenarios where agents navigate to safe zones or equipment while avoiding static/dynamic obstacles; generate repeatable drills and performance metrics.
- Tools/workflow: World Layer to reconstruct facilities and extract collision meshes; Agent Layer to script high-level goals and run autonomous behaviors; outcome dashboards (SR/SPL/CR).
- Assumptions/dependencies: Realistic motion fidelity is sufficient for navigation and spacing tasks but not physical manipulation; scenario authoring tools; compliance with safety and privacy rules.
- Human-aware autonomous driving and ADAS testing (pedestrian simulation)
- Sectors: Automotive, AV/ADAS simulation
- What: Populate reconstructed street scenes with pedestrians exhibiting goal-directed, egocentric behaviors to test perception and planning stacks.
- Tools/workflow: Integrate Gaussian avatars and agent planner into existing driving sims (e.g., CARLA plugins or bridge exporters); vary locomotion style (walk/run/slow) to stress AV.
- Assumptions/dependencies: Integration bridges for mesh/collision export; synchronization with vehicle dynamics; validation that agent behaviors approximate real pedestrian responses.
- Synthetic, annotated datasets for vision and embodied AI
- Sectors: Software/AI, academia
- What: Generate egocentric RGB-D trajectories with semantic labels and collision annotations for training navigation, segmentation, and long-horizon reasoning models.
- Tools/workflow: Use World Layer for semantic instance masks and open-vocab tags; Agent Layer to produce diverse paths; export sequences with camera intrinsics/extrinsics and SMPL parameters.
- Assumptions/dependencies: Domain gap to real-world; licensing of underlying models (SAM, Qwen2.5-VL); dataset documentation and governance.
- Social VR scenes and telepresence set dressing
- Sectors: AR/VR, collaboration, ed-tech
- What: Add believable autonomous bystanders and guides to reconstructed classrooms, campuses, or offices to improve immersion and orientation for remote participants.
- Tools/workflow: Reconstructed spaces from smartphone videos; low-latency playback of pre-baked agent trajectories; light-weight inference for on-device or server-side.
- Assumptions/dependencies: Latency budgets; privacy in shared spaces; stable rendering pipelines for Gaussian or mesh conversions in VR engines.
- Event and facility crowd management rehearsal
- Sectors: Public safety, venue operations, sports/entertainment
- What: Simulate ingress/egress, queue formation, and signage efficacy using autonomous pedestrians in reconstructed arenas and concourses.
- Tools/workflow: Multi-goal navigation tasks across consecutive landmarks (e.g., gate→concourse→seat); measure PR/PPL; iterate signage and staffing plans.
- Assumptions/dependencies: Representative capture at scale; generalization of agent behavior to high-density scenarios may require parameter tuning.
- Benchmarking and reproducible research on embodied humanoids
- Sectors: Academia, R&D labs
- What: Use the open-source benchmark (scenes, avatars, tasks) to evaluate planning algorithms, memory mechanisms, and low-level motion controllers under standardized metrics.
- Tools/workflow: Baseline comparisons (NaVILA, NaVid, Uni-NaVid) plus ablations of visual prompting and iterative reasoning; plug-in alternate planners/controllers.
- Assumptions/dependencies: Availability of the released code/models/data; compute resources for training-free inference at scale.
- Rapid NPC generation for location-based games
- Sectors: Gaming, location-based entertainment
- What: Build game-ready NPCs with plausible, scene-aware behaviors from a quick capture of real-world play areas (malls, campuses).
- Tools/workflow: Pipeline for fast 3DGS reconstruction + semantic tagging; export to game engines; light gameplay scripting layered atop autonomous primitives.
- Assumptions/dependencies: Rights for capture and redistribution; run-time conversion of Gaussian scenes to engine-friendly meshes.
Long-Term Applications
- Sim-to-real transfer for humanoid and mobile robots
- Sectors: Robotics (service/assistive), warehousing, healthcare
- What: Transfer agent planning (spatially grounded VLM reasoning + iterative memory) to real robots for human-aware navigation and future manipulation.
- Tools/workflow: Domain randomization and sensor-model alignment; mapping egocentric RGB-D to robot perception; low-level controllers for legged/wheeled platforms.
- Assumptions/dependencies: Physics realism and contact modeling beyond current avatar motion; safety certification; robust sim2real strategies.
- City-scale social simulations with thousands of agents
- Sectors: Smart cities, transportation planning, policy
- What: Evaluate policy interventions (new crosswalks, signal timing, curb management) using large populations of autonomous humanoids in semantically rich digital twins.
- Tools/workflow: Scalable 3DGS or hybrid LoD representations; multi-agent coordination and traffic coupling; calibration with observed flows.
- Assumptions/dependencies: Computation and memory scaling; data-sharing agreements with municipalities; validation against longitudinal datasets.
- On-device assistive navigation for the visually impaired
- Sectors: Healthcare, accessibility, mobile software
- What: Deliver egocentric, step-by-step guidance grounded in visual context and open-vocab goal recognition in unfamiliar environments.
- Tools/workflow: Compressed VLMs with spatial prompting; SLAM + lightweight semantics on edge; haptic/audio feedback loops.
- Assumptions/dependencies: Reliable real-time perception on mobile hardware; robust to clutter, lighting, motion blur; regulatory approval for assistive tech.
- Conversational, socially competent humanoid agents
- Sectors: Education, therapy, entertainment, retail
- What: Combine embodied planning with dialogue and social norms to enable guides, docents, or store associates that communicate and navigate jointly.
- Tools/workflow: Integration with LLM dialogue, emotion/intent recognition, proxemics-aware motion; multi-agent social policies.
- Assumptions/dependencies: Safety and alignment in open-domain conversation; cultural and accessibility considerations; data for social behavior modeling.
- Human–robot collaboration and HRI evaluation
- Sectors: Manufacturing, logistics, service robotics
- What: Use autonomous digital humans to stress-test robot policies for human-aware path planning, handover zones, and shared workspace safety before deployment.
- Tools/workflow: Co-simulation with robot stacks; procedural generation of human tasks and densities; metrics for near misses and comfort zones.
- Assumptions/dependencies: Fidelity of human motion and reaction; regulatory and ethical review for decision policies.
- Digital twin operations for smart buildings and campuses
- Sectors: PropTech, facilities, energy management
- What: Predict occupant flows to optimize signage, cleaning routes, elevator dispatch, and HVAC zoning based on simulated human trajectories.
- Tools/workflow: Continuous update of semantic twins; “what-if” scenario runners; coupling with BMS and IoT data.
- Assumptions/dependencies: Persistent data integration; privacy-preserving pipelines; model drift as usage patterns change.
- Emergency planning and evacuation policy testing
- Sectors: Public safety, emergency management
- What: Evaluate evacuation routes, muster points, and messaging strategies using autonomous agents in digital replicas of buildings and public spaces.
- Tools/workflow: Scenario library (fire, flood, security); dynamic hazards and blocked areas; performance metrics vs regulatory standards.
- Assumptions/dependencies: Validation against drills; modeling of panic and herding behaviors beyond current navigation; stakeholder governance.
- Foundation models for long-horizon embodied reasoning
- Sectors: AI research, software
- What: Curate large-scale egocentric datasets with multi-step goals and open-vocabulary semantics to train VLMs/LLMs with stronger spatial/memory capabilities.
- Tools/workflow: Automated generation of multi-goal tasks; aligned text–trajectory pairs; curriculum from easy to complex environments.
- Assumptions/dependencies: Compute and storage; dataset licensing; avoiding synthetic–real overfitting artifacts.
- Adaptive optimization of wayfinding and signage via closed-loop simulation
- Sectors: Transportation hubs, hospitals, campuses
- What: Iteratively redesign sign placement/graphics to maximize agent success and minimize detours/collisions in complex facilities.
- Tools/workflow: Optimization-in-the-loop over semantic landmarks; A/B variant testing; visual analytics dashboards.
- Assumptions/dependencies: Behavioral realism for novel signage; stakeholder buy-in and retrofit budgets.
- Insurance risk assessment and hazard mitigation
- Sectors: Insurance, workplace safety
- What: Identify slip/trip hazards, blind corners, and high-conflict zones by analyzing agent collision hot spots in reconstructed sites.
- Tools/workflow: Site scans + agent simulation; hazard heatmaps and recommendations; pre/post remediation testing.
- Assumptions/dependencies: Legal acceptance of simulated evidence; calibration to incident reports; liability considerations.
Cross-cutting assumptions and dependencies
- Data capture quality: Monocular video must sufficiently cover geometry and appearance; severe motion blur or lighting changes reduce reconstruction and semantic accuracy.
- Compute and scalability: 3D Gaussian Splatting optimization, VLM inference, and motion diffusion require GPUs; city-scale scenarios need memory and parallelization strategies.
- Semantics and open-vocabulary accuracy: Automated annotations via VLMs may mislabel rare or occluded objects; human-in-the-loop QA may be needed for high-stakes use.
- Representation conversion: Many production engines require meshes; pipelines to convert Gaussians to meshes and maintain collision fidelity are necessary.
- Dynamic vs static environments: Current pipeline best fits mostly static scenes; rapidly changing environments need frequent re-capture or online updates.
- Legal and ethical constraints: Location scanning, identity/privacy, and rights to deploy digital humans must be addressed; safety and alignment for interactive agents are essential.
Glossary
- 3D Gaussian Splatting (3DGS): A differentiable rendering technique that represents scenes as collections of 3D Gaussians for fast, photorealistic reconstruction and rendering. "3D Gaussian Splatting (3DGS)~\cite{kerbl20233dgs}"
- 3D instance segmentation: The task of identifying and labeling individual object instances in 3D space. "This automatic workflow boosts the accuracy of 3D instance segmentation"
- back-projection: The process of mapping 2D image coordinates back into 3D space using depth information. "These paths are then back-projected into 3D points~ using depth maps"
- Chain-of-Thought (CoT) prompting: A prompting strategy for LLMs that encourages step-by-step reasoning. "inspired by Chain-of-Thought (CoT) prompting~\cite{wei2022cot}, adapted to incorporate visual information"
- coarse-to-fine codebook discretization: A two-stage clustering/quantization approach that first groups features coarsely (e.g., by geometry) and then refines them to discrete codes for consistent instance labeling. "we use a coarse-to-fine codebook discretization strategy"
- contrastive learning: A representation learning paradigm that pulls similar examples together and pushes dissimilar ones apart in feature space. "we enforce feature consistency via contrastive learning:"
- differentiable rendering: Rendering methods that are differentiable end-to-end, allowing optimization of scene parameters from images. "Advances in differentiable rendering, particularly NeRF~\cite{mildenhall2021nerf} and 3D Gaussian Splatting (3DGS)~\cite{kerbl20233dgs}, have revolutionized scene reconstruction."
- ego-centric RGB-D observation: First-person visual input that includes both color (RGB) and depth (D) channels. "the agent receives an ego-centric RGB-D observation $\boldsymbol{I}_{\text{ego} \in \mathbb{R}^{H \times W \times 4}$"
- feed-forward model: A model that processes inputs in a single pass without iterative optimization at inference time. "SceneSplat~\cite{li2025scenesplat} introduces a generalizable, feed-forward model for scene understanding."
- Gaussian primitives: Parametric Gaussian elements used to represent geometry, appearance, and semantics in 3DGS-based scene or avatar models. "each modeled as a collection of Gaussian primitives~\cite{hu2024gaussianavatar, moon2024exavatar}"
- Level-of-Detail modeling: Techniques that vary model complexity with viewing conditions to balance speed and quality at different scales. "or Level-of-Detail modeling~\cite{lu2024scaffold, ren2024octree, jiang2025horizon}"
- motion diffusion model: A generative model that synthesizes motion sequences by denoising from noise under constraints (e.g., waypoints, text). "then condition a motion diffusion model to synthesize full-body motion"
- NeRF: Neural Radiance Fields; a neural rendering method that represents scenes as volumetric radiance and density fields. "particularly NeRF~\cite{mildenhall2021nerf}"
- occlusion-aware masks: Segmentation masks explicitly accounting for occluders to isolate visible regions of target instances. "We introduce occlusion-aware masks and view selection to boost segmentation accuracy"
- occlusion-aware semantic scene reconstruction: A pipeline that reconstructs 3D scenes with semantics while handling occlusions to improve segmentation and labeling. "via an occlusion-aware semantic scene reconstruction pipeline,"
- open-vocabulary scene understanding: Semantic understanding that is not limited to a fixed label set and can generalize to arbitrary text queries. "augment 3DGS with semantic features for open-vocabulary scene understanding."
- perceptionâaction loop: A closed loop coupling perception, decision-making, and action execution for embodied agents. "This layer provides a perceptionâaction loop, coupling observation, decision, and motor control into a unified cycle."
- quantization loss: A loss that penalizes the difference between continuous features and their discretized (quantized) counterparts. "The quantization loss "
- SMPL: A parametric 3D human body model used to represent body shape and pose for animation. "The final motion is converted to SMPL parameters for animation"
- Spatial-Aware Visual Prompting: A visual prompting technique that encodes traversability, candidate directions, and goal cues to ground VLM planning. "Spatial-Aware Visual Prompting, which {discretizes} and {emphasizes} candidate directions"
- training-free guidance mechanism: An inference-time control strategy for diffusion models that steers generation toward constraints without additional training. "we incorporate a training-free guidance mechanism~\cite{liu2024programmable, karunratanakul2024dno}"
- visibility score: A metric estimating how visible a target cluster/instance is from a given view to select informative training frames. "we pre-compute an occlusion-aware visibility score for each cluster-view pair."
- Vision-and-Language Navigation (VLN): Tasks and models where an agent navigates environments following natural language instructions grounded in vision. "Vision-and-Language Navigation (VLN) models~\cite{liu2024citywalker, roth2024viplanner}"
- vision-LLM (VLM): A multimodal model jointly processing visual and textual inputs for tasks like reasoning or planning. "we leverage the semantic reasoning ability of VLMs in a training-free, zero-shot way"
- zero-shot: Performing a task without task-specific training or fine-tuning, relying on generalization from prior knowledge. "in a training-free, zero-shot way"
Collections
Sign up for free to add this paper to one or more collections.