Active Intelligence in Video Avatars via Closed-loop World Modeling
Abstract: Current video avatar generation methods excel at identity preservation and motion alignment but lack genuine agency, they cannot autonomously pursue long-term goals through adaptive environmental interaction. We address this by introducing L-IVA (Long-horizon Interactive Visual Avatar), a task and benchmark for evaluating goal-directed planning in stochastic generative environments, and ORCA (Online Reasoning and Cognitive Architecture), the first framework enabling active intelligence in video avatars. ORCA embodies Internal World Model (IWM) capabilities through two key innovations: (1) a closed-loop OTAR cycle (Observe-Think-Act-Reflect) that maintains robust state tracking under generative uncertainty by continuously verifying predicted outcomes against actual generations, and (2) a hierarchical dual-system architecture where System 2 performs strategic reasoning with state prediction while System 1 translates abstract plans into precise, model-specific action captions. By formulating avatar control as a POMDP and implementing continuous belief updating with outcome verification, ORCA enables autonomous multi-step task completion in open-domain scenarios. Extensive experiments demonstrate that ORCA significantly outperforms open-loop and non-reflective baselines in task success rate and behavioral coherence, validating our IWM-inspired design for advancing video avatar intelligence from passive animation to active, goal-oriented behavior.
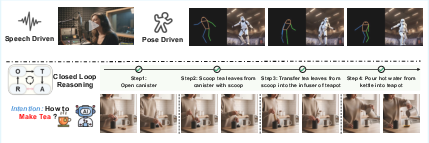


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper is about making video avatars—animated people in videos—behave more like smart helpers and less like puppets. Today’s avatars can follow simple instructions like “wave” or “lip-sync to this speech,” but they don’t really plan ahead or adapt when things go wrong. This paper introduces a new test and a new system that help avatars set goals, plan multiple steps, check their own work, and fix mistakes—so they can finish complex tasks on their own.
The main questions the authors ask
- How can we move from “passive” avatars (that just react to a prompt) to “active” avatars (that think, plan, and complete goals)?
- How can an avatar keep track of what has happened so far when it only sees the videos it just generated (not the full “true” world)?
- How can it predict what will happen next and choose the right next action—even when video generation is a bit random and may not match the plan exactly?
How they approached the problem
A new challenge to test “active” avatars: L-IVA
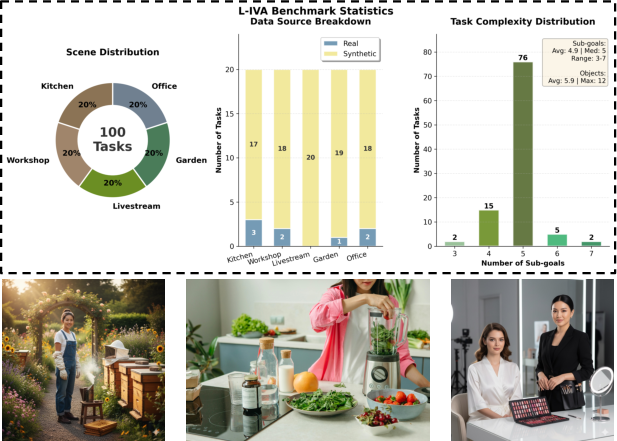
The authors introduce L-IVA (Long-horizon Interactive Visual Avatar), a set of tasks where an avatar must complete multi-step goals in a video. Think of tasks like “host a product demo,” “repot a plant,” or “prepare a snack”—each needs several steps with objects and careful ordering. Unlike typical video tests that judge one clip’s look, L-IVA checks whether the avatar can finish the whole goal across multiple clips.
Why this is hard:
- The avatar only “sees” what it just generated (like watching your own last video), not the full world. That’s called partial observability.
- Video generation models are random: the same instruction can produce different visuals each time.
- Actions are open-ended (described in natural language), not simple robot moves like “turn joint by 10 degrees.”
To handle this, the authors model the problem like playing a game while only getting glimpses of the screen: the avatar builds a mental guess of the world and updates it as it goes.
The avatar’s “brain”: ORCA
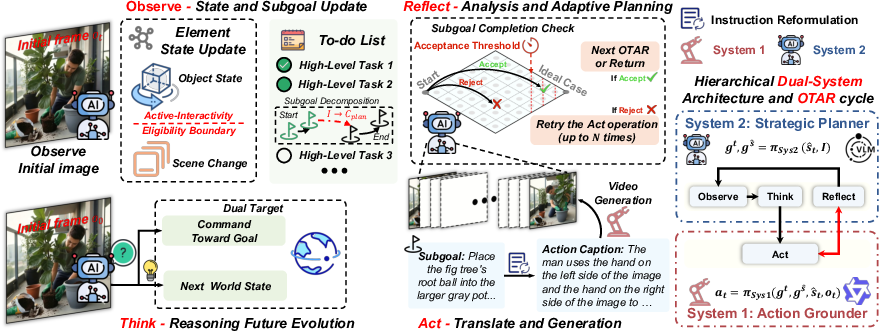
The authors propose ORCA (Online Reasoning and Cognitive Architecture), a think-and-check system inspired by how people reason. It has two big ideas:
- A closed loop called OTAR: Observe → Think → Act → Reflect
- Observe: Watch the latest generated clip to understand what changed.
- Think: Plan the next sub-goal and predict what the video should look like if things go right.
- Act: Turn that plan into a very detailed instruction for the video model.
- Reflect: Compare the actual new video to the prediction. If it doesn’t match, try again or adjust the plan.
- Two “systems” that split brainwork:
- System 2 (Planner): Does slow, careful reasoning—keeps track of progress, chooses next goals, and predicts outcomes.
- System 1 (Executor): Turns the plan into precise, model-specific prompts so the video comes out as intended (like speaking the exact “dialect” the video model understands).
In everyday language: System 2 is the strategist; System 1 is the precise doer. The OTAR loop makes sure the avatar doesn’t just assume things went fine—it checks and corrects.
Simple explanations of key terms
- Internal World Model (IWM): A mental map the avatar keeps about what the world is like right now, what changed, and what will likely happen next.
- Partial observability: The avatar doesn’t see everything, only what shows up in its generated clips.
- POMDP (a mouthful that means “Partially Observable Markov Decision Process”): A fancy way to say “make good decisions when you don’t know everything, and only get noisy clues.”
- Image-to-Video (I2V) model: A tool that turns a starting image and a text instruction into a short video clip.
What they found and why it matters
The authors tested ORCA on the L-IVA benchmark against three types of baselines:
- Reactive agent: Acts step-by-step but doesn’t plan or remember well.
- Open-loop planner: Plans everything at the start and never checks results.
- A prior “world-model” style method without reflection on the video’s actual outcome.
Main results:
- ORCA had the best average task success (about 71%) across different scenarios (kitchen, garden, workshop, office, livestream).
- ORCA’s videos were rated more physically plausible (objects behave sensibly and consistently) and more consistent (the avatar keeps the same identity/look across clips).
- Humans preferred ORCA’s outputs overall.
Interesting trade-off:
- In simpler tasks, the open-loop planner sometimes looked okay because it rushed through all steps without stopping. But in harder tasks where early mistakes ruin later steps (like “move plant, add soil, water, place pot”), ORCA’s Reflect stage was crucial—catching errors early and keeping the plan on track.
Ablation (what parts matter most):
- Without the belief state (the avatar’s mental map), it repeated steps or did things out of order.
- Without Reflect, small generation errors piled up and broke the plan.
- Without System 1’s precise prompting, the video model misinterpreted actions.
Why this research is important
- It pushes video avatars from “following orders” to “working toward goals,” which is needed for things like livestream hosting, product demos, or interactive tutoring.
- The OTAR loop shows a practical way to cope with the randomness of video generation: check what actually happened, then adapt.
- The split between planning (System 2) and precise execution (System 1) could help many future AI systems that must turn fuzzy ideas into reliable results.
In short, this paper takes a big step toward avatars that can think ahead, adapt when things go wrong, and finish multi-step tasks—more like a helpful assistant than a puppet.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, highlighting concrete directions future work could pursue:
- Formal belief-state modeling is underspecified: functions for observe/think/reflect (e.g.,
f_observe,f_think,f_reflect) are defined symbolically but lack explicit algorithms, probabilistic formulations (e.g., Bayesian filters), or learned models; no quantitative evaluation of belief-state accuracy is provided. - Reflection reliability is unmeasured: the accuracy, failure modes, and bias of VLM-based outcome verification (accept/reject) are not quantified, nor is the impact of incorrect reflections on long-horizon planning.
- Evaluation and agent may share the same VLM: using a single proprietary VLM (Gemini-2.5-Flash) for both reasoning and VLM-based metrics risks circularity; the paper does not control for evaluator–agent coupling or test with diverse/independent evaluators.
- Action grounding is hand-engineered and model-specific: System 1 relies on prompt engineering tailored to one I2V model (Wanx2.2); portability, generalization across I2V models, and learned grounding policies are not explored.
- No training or learning of the world model/policy: despite POMDP framing, ORCA is training-free; the benefits of learned internal world models, policy optimization (e.g., RL), or differentiable planning are left unexplored.
- Trade-offs between retries, step budget, and success are ad hoc: the strategy to allocate retries vs. progress is not optimized or learned; adaptive policies for retry thresholds, confidence-based acceptance, or budget-aware planning are not studied.
- Real-time performance is unreported: latency, throughput, and computational cost of OTAR (especially with retries) for livestream scenarios are not measured; integration constraints for real-time hosting remain open.
- Limited environment complexity: L-IVA restricts to fixed-viewpoint, single-room scenes to avoid I2V inconsistencies; robustness to camera motion, occlusions, multi-room navigation, dynamic lighting, and viewpoint changes is untested.
- Long-horizon scaling is modest: tasks are 3–8 steps; performance, memory stability, identity consistency, and error compounding over tens/hundreds of steps (e.g., true long livestreams) remain uncharacterized.
- Physical plausibility lacks objective metrics: PPS is human-rated; scalable, objective measures of continuity (e.g., object tracking across chunks, 3D scene consistency, action pre/post conditions) are missing.
- Multi-agent coordination is unclear: the benchmark includes two-person tasks, but ORCA’s mechanisms for concurrent multi-avatar planning, coordination, and communication (e.g., joint belief states, conflict resolution) are not specified or evaluated.
- Scene understanding is brittle: reliance on VLM scene parsing without explicit detection/tracking modules (e.g., object permanence, state changes under occlusion) is untested; integrating structured perception remains an open path.
- Generalization across VLMs/I2V models is not validated: ablations across different VLMs and generators (and their parameterizations) are absent; the sensitivity of ORCA to model choice and drift is unknown.
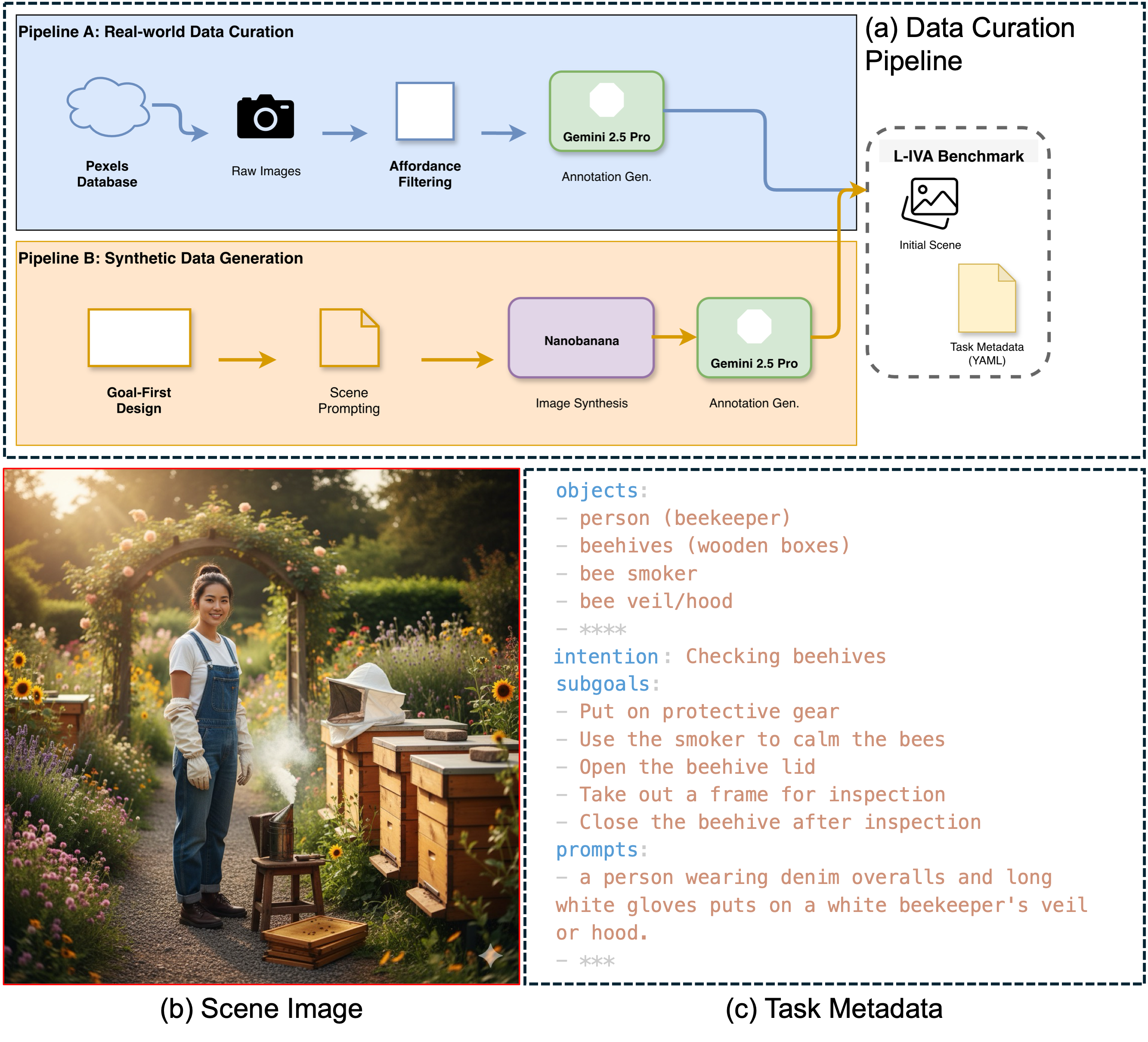
- Benchmark diversity is limited: 92 synthetic vs. 8 real images; domain shift to real imagery, cross-cultural object sets, cluttered scenes, and out-of-distribution tasks is insufficiently covered.
- Alternative valid plans are only loosely supported: while the benchmark “accepts” alternative action orderings, the scoring protocol for equivalence, partial credit, and plan diversity is not rigorously defined or automated.
- Failure recovery is heuristic: “adaptive recovery” after repeated rejects is not detailed; principled uncertainty-aware replanning (e.g., risk-sensitive planning, belief entropy thresholds) is an open design question.
- Identity safety and ethics are not addressed: risks of agency in avatars (misrepresentation, consent, fairness across identities, abuse in livestreaming) and mitigation strategies are absent.
- Multimodal control remains limited: integration of audio, gaze, and layout cues into planning/execution (beyond text captions) is not explored; cross-modal grounding and conflicts are unaddressed.
- Memory management over long histories is unspecified: how the belief state scales with history length, how memory is pruned/abstracted, and robustness to memory corruption are not analyzed.
- Reproducibility details are lacking: seeds, prompt variants, dataset release specifics (especially object inventories for real images), and evaluator instructions for BWS/PPS are not fully disclosed; human-evaluation variance is noted but not systematically controlled.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the paper’s ORCA framework (closed-loop OTAR reasoning + dual-system architecture) and the L-IVA benchmark to improve reliability and goal-directed behavior in generative video workflows.
- Autonomous product demo/livestream avatar — sector: retail/e-commerce
- What it does: An avatar that plans and executes multi-step product showcases (unboxing, feature comparison, usage sequence), verifying each clip’s outcome before proceeding.
- Tools/workflow: ORCA controller; “System 2” task decomposition (checklists, sub-goal planning); “System 1” action-caption compiler tailored to target I2V; Reflect-stage quality gate; integration with TTS/ASR and on-screen overlays.
- Assumptions/dependencies: Access to a high-quality I2V model; model-specific prompt templates; rights/consent for identity preservation; compute sufficient for retries; current constraint to single-room, fixed-viewpoint scenes.
- Instructional “how-to” video generator — sectors: education, consumer software
- What it does: Generates step-by-step tutorials (cooking, DIY, software walkthroughs) that track sub-goals and correct errors via the Reflect stage.
- Tools/workflow: ORCA as a tutorial director; domain-specific goal templates; Action Fidelity/Physical Plausibility checks to ensure semantic alignment and continuity.
- Assumptions/dependencies: Domain coverage of the VLM’s world knowledge; stable identity across long horizons; content disclaimers and source-of-truth curation for technical steps.
- Marketing and ad production with brand consistency — sector: media/advertising
- What it does: Produces multi-scene promotional clips while maintaining visual identity and narrative coherence across steps.
- Tools/workflow: ORCA-integrated “ad storyboard to execution” pipeline; Reflect-stage guardrails for brand safety (logos, slogans, disclosures); Identity-preservation modules; human-in-the-loop approval.
- Assumptions/dependencies: Brand asset libraries; legal approvals; compliance rules encoded into Reflect-stage checks; latency budget for retries.
- Enterprise support videos from knowledge bases — sector: software/enterprise
- What it does: Converts troubleshooting flows into coherent multi-step instructional videos that verify each action’s success before advancing.
- Tools/workflow: ORCA wrapped around KB retrieval; System 2 uses retrieved steps to plan; System 1 compiles model-specific captions; Reflect-stage failure analysis triggers re-generation.
- Assumptions/dependencies: Accurate KB grounding; content provenance; privacy/PII handling; predictable task environments.
- Studio previsualization and iterative direction — sectors: film, gaming
- What it does: Rapidly previsualizes multi-step scenes, maintaining subject consistency over long horizons and reducing artifact accumulation through Reflect gating.
- Tools/workflow: ORCA as a “previz director”; shot-by-shot goal decomposition; model-specific prompt libraries; versioned belief-state logs for review.
- Assumptions/dependencies: Human oversight; integration with existing DCC tools; limited physics fidelity in current I2V models.
- Content QA and moderation inside generation pipelines — sectors: platform policy/compliance
- What it does: Uses the Reflect stage to automatically accept/reject clips based on semantic alignment, safety rules, or disclosure requirements (e.g., “synthetic avatar” notices).
- Tools/workflow: Reflect-stage rule packs; Action Fidelity and Physical Plausibility scoring; audit trails of belief updates; watermark/provenance checks (C2PA-compatible).
- Assumptions/dependencies: Well-specified policy checklists; reliable VLM judgments; organizational adoption of disclosure/watermark standards.
- Benchmarking and evaluation for research groups — sector: academia
- What it does: L-IVA evaluates long-horizon agency under generative uncertainty with metrics like Task Success Rate (TSR), Physical Plausibility Score (PPS), Action Fidelity Score (AFS), and human preference (BWS).
- Tools/workflow: L-IVA task suite; ORCA baseline; reproducible protocols and structured prompts; standardized reporting across scenarios (Kitchen, Livestream, Workshop, Garden, Office).
- Assumptions/dependencies: Public availability of scenes/specs; consistent human/VLM evaluators; shared access to comparable I2V systems.
- Prototype digital fitness or wellness coach — sectors: consumer health, daily life
- What it does: Generates multi-step routines (warm-up, exercise progression, cool-down) with outcome verification and sub-goal tracking.
- Tools/workflow: ORCA routine planner; System 1 tailoring of movement prompts; Reflect-stage correction of implausible motion or identity drift.
- Assumptions/dependencies: Non-medical disclaimers; motion plausibility in I2V; personalization requires user consent and data governance.
- Orchestration middleware for generative video stacks — sector: software
- What it does: A controller library that wraps I2V models with OTAR loops, dual-system prompting, action-caption compilers, and retry logic.
- Tools/workflow: ORCA-like API; per-model “prompt compilers”; observability dashboards (belief state, retries, accept/reject logs).
- Assumptions/dependencies: Model APIs; cost controls; DevOps integration; modularity to swap VLM/I2V engines.
Long-Term Applications
Below are strategic applications that likely require further research, scaling, or ecosystem development (e.g., faster I2V, richer world models, policy frameworks).
- Real-time interactive avatars in live sessions — sectors: e-commerce, education, entertainment
- What it could do: Bi-directional, low-latency OTAR control in response to audience input, with speech and gesture synthesis and on-the-fly replanning.
- Needed advances: Streaming I2V with sub-second latency; robust state tracking under continuous input; multi-modal fusion (ASR/TTS/gesture); scalable retry strategies.
- Multi-agent collaborative avatars and multi-person tasks — sectors: media, events, training
- What it could do: Coordinated group behaviors (panel discussions, team demos, role-play) with shared belief states and task allocation.
- Needed advances: Multi-avatar identity preservation; joint planning across agents; conflict resolution; scene continuity across camera changes.
- Physics-aware 3D world modeling and AR/VR integration — sectors: gaming, training, robotics
- What it could do: Avatars that reason over 3D geometry, object permanence, and causal dynamics, generating footage that aligns with physical constraints or simulations.
- Needed advances: 3D-aware I2V; sensor-style observation functions; explicit state estimators; hybrid pipelines combining generative video with physics engines.
- End-to-end autonomous storefront host — sectors: retail/e-commerce
- What it could do: Integrate inventory, POS, analytics, and content generation to run an entire product showcase autonomously, optimizing for conversion and engagement.
- Needed advances: Business system integrations; reliable analytics feedback loops; compliance modules; robust handling of unexpected events.
- Personalized digital twins for creators and brands — sectors: media, social platforms
- What it could do: Long-horizon content generated by identity-preserving avatars with consistent style and behavioral traits, including endorsements and interactive formats.
- Needed advances: Consent management and licensing; watermarking/provenance; bias/fairness auditing; scalable content governance.
- High-stakes procedural training (healthcare, industrial safety) — sectors: healthcare, manufacturing, energy
- What it could do: Validated training videos with scenario branching, accountability logs, and post-hoc auditing of each step’s correctness.
- Needed advances: Domain verification tools; expert-in-the-loop validation; liability frameworks; higher physical plausibility and lower hallucination rates.
- Standardization and regulation for synthetic avatars — sectors: policy, platform governance
- What it could do: Mandate disclosures, provenance (C2PA), watermarking, and audit logs; establish performance and safety benchmarks for long-horizon generative agents.
- Needed advances: Regulatory consensus; interoperable provenance standards; automated compliance checks embedded in the Reflect stage.
- Research into POMDPs under generative uncertainty — sector: academia
- What it could do: New algorithms for belief-state estimation when observations are stochastic generations; cross-model generalization; stronger evaluation suites beyond single-room setups.
- Needed advances: Larger, more diverse benchmarks (multi-camera, outdoor, multi-room); standardized metrics; public baselines across models.
- Tooling standardization: Action Caption DSL and prompt compilers — sector: software
- What it could do: A domain-specific language for executable action captions plus compilers targeting diverse I2V models, enabling portability and reproducibility.
- Needed advances: Community adoption; model vendors publishing prompt specs; formal verification hooks; open-source libraries.
Cross-cutting assumptions and dependencies
- Model capabilities and access: The framework assumes strong VLM reasoning and competent I2V generation; performance depends on model quality, cost, and latency.
- Prompt engineering: System 1 requires per-model prompt formats and careful engineering; portability benefits from standardization (e.g., an Action Caption DSL).
- Scene constraints today: ORCA and L-IVA operate best in single-room, fixed-viewpoint scenarios; multi-camera/3D interactions remain challenging.
- Rights, safety, and compliance: Identity preservation implies consent and licensing; platform policies likely require watermarking, disclosures, and moderation guardrails.
- Compute and retries: The Reflect stage uses accept/reject loops; production deployments need quota management, deterministic fallbacks, and SLA-aware orchestration.
- Human-in-the-loop: For brand-critical or high-stakes content, editorial review and expert validation should complement automated reflection and QA.
Glossary
- Action Fidelity Score: A metric quantifying the semantic alignment between commands and generated clips. "a VLM-based {Action Fidelity Score} to quantify the semantic alignment between commands and video clips ()."
- Autoregressive: A generation process where each chunk depends on the final frames of the previous chunk. "operate in a chunk-level autoregressive manner"
- Best-Worst Scaling (BWS): A comparative human preference method producing robust rankings. "Best-Worst Scaling (BWS)~\cite{louviere2015best} to derive robust human preference rankings."
- Belief state: An internal estimate of the hidden world state maintained from observations and history. "internal belief state , a state with history information and updated via observation."
- Closed-loop OTAR cycle: A feedback-driven control cycle that verifies outcomes before belief updates to prevent error accumulation. "a closed-loop OTAR cycle (Observe-Think-Act-Reflect)"
- Compositional reasoning: Planning by composing knowledge over open-domain scenarios. "compositional reasoning over open-domain scenarios"
- Dual-process theory: A cognitive theory distinguishing fast, intuitive processes from slow, deliberative reasoning. "inspired by dual-process theory~\cite{evans2013dual}."
- Embodied AI: AI agents that interact within physical environments. "than in robotics or embodied AI, where agents interact with deterministic physical environments."
- Forward dynamics: Modeling how actions change states to support planning. "world models support planning through learned forward dynamics"
- Generative uncertainty: Randomness in generative models that leads to variable, unpredictable outcomes. "robust state tracking under generative uncertainty"
- Hierarchical dual-system architecture: A design separating strategic planning (System 2) from precise execution (System 1). "a hierarchical dual-system architecture"
- I2V model (Image-to-Video): A generative model that produces video conditioned on images and textual/action inputs. "Image-to-Video (I2V) model"
- Internal World Model (IWM): An internal model enabling state estimation, prediction, and outcome simulation for planning. "Internal World Models (IWMs)"
- L-IVA (Long-horizon Interactive Visual Avatar): A task and benchmark for evaluating goal-directed planning in generative environments. "L-IVA (Long-horizon Interactive Visual Avatar)"
- Open-domain action space: An unconstrained set of natural-language actions without predefined primitives. "open-domain action space composed of natural language captions."
- Open-Loop Planner: A planner that executes a fixed action sequence without intermediate feedback. "Open-Loop Planner plans the complete action sequence upfront"
- Outcome verification: Checking that generated outcomes match predicted states before updating beliefs. "Without outcome verification, incorrect generations corrupt subsequent steps."
- OTAR (Observe-Think-Act-Reflect): A four-stage reasoning loop for robust, reflective agent control. "OTAR (Observe-Think-Act-Reflect)"
- Partially Observable Markov Decision Process (POMDP): A decision framework under partial observability requiring belief-based policies. "characterized as a Partially Observable Markov Decision Process (POMDP)"
- Physical Plausibility Score (PPS): A human-rated metric of object permanence and spatial consistency. "{Physical Plausibility Score} to assess object permanence and spatial consistency"
- Prompt engineering: Crafting model-specific prompts to achieve precise generative control. "This process leverages extensive prompt engineering"
- Sparse and terminal reward: A reward scheme that yields credit only upon final task completion. "the reward is sparse and terminal"
- Stochastic generative environments: Generative settings where identical actions can yield diverse outcomes. "goal-directed planning in stochastic generative environments"
- Subject Consistency: A measure of identity consistency across generated video segments. "suffers from the lowest Subject Consistency."
- System 1: The execution module that grounds abstract plans into detailed, model-specific action captions. "System 1 translates abstract plans into precise, model-specific action captions."
- System 2: The strategic reasoning module that maintains belief and predicts next states. "System 2 performs strategic reasoning with state prediction"
- Task Success Rate (TSR): The fraction of completed sub-goals per task used as the primary success metric. "Our primary metric is the {Task Success Rate (TSR)}"
- Vision-LLM (VLM): A model that jointly understands and reasons over visual and textual inputs. "vision-LLM"
- World modeling: Explicit modeling of environment states and dynamics to enable robust planning. "explicit world modeling is essential"
Collections
Sign up for free to add this paper to one or more collections.