Making Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
Abstract: Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making digital people (avatars) in videos that don’t just talk, but also follow instructions to use real objects in their scene. For example: given a single photo of a person in a kitchen, a short spoken line, and a text instruction like “pick up the red cup,” the system makes a short, realistic video where the same person talks and actually reaches for that exact red cup in the photo, instead of inventing a new scene.
Key Questions
The authors focus on two big challenges:
- How can an avatar understand its environment from one reference image and interact with the right objects in the right places? (They call this “grounding” actions in the scene.)
- How can we keep strong control over what the avatar does (so it follows instructions) without ruining video quality or lip-sync? They call this the “control–quality dilemma.”
How They Did It
Think of the system as a two-person team making a movie from a single photo, a text instruction, and speech audio:
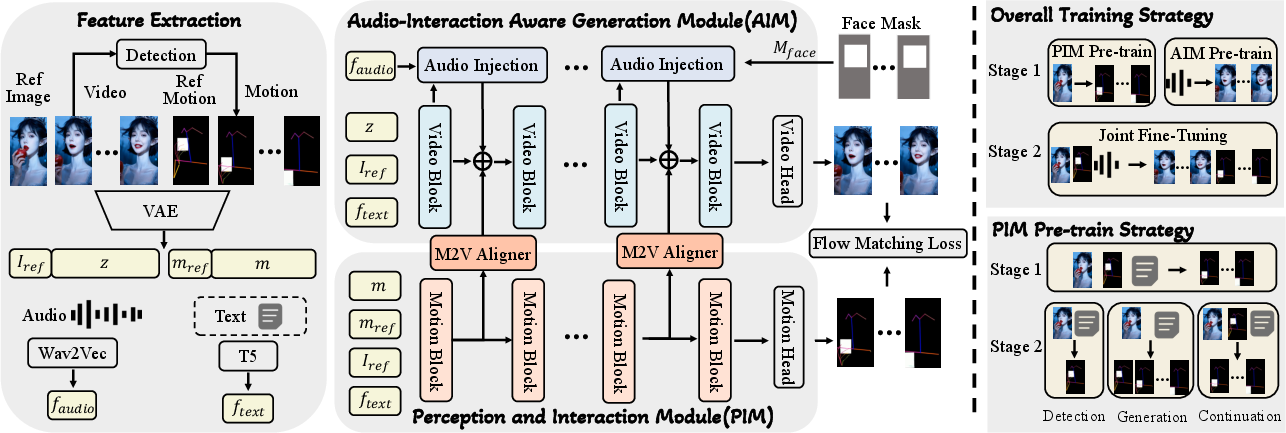
- The Planner (PIM: Perception and Interaction Module)
- Job: Look at the reference image, find and understand objects, read the text instruction, and then plan the movement.
- Output: A simple “sketch” of the action over time, like a stick-figure body pose plus boxes showing where objects are. This sketch is called “motion.”
- The Artist (AIM: Audio-Interaction-aware Module)
- Job: Take the plan from the Planner and the speech audio, and paint a high-quality video with accurate lip movements and realistic body motion in the original scene.
To keep the Artist closely following the Planner’s sketch, they use a helper:
- Motion-to-Video Aligner
- Think of it as the Planner whispering guidance into the Artist’s ear at every step, so the final video matches the planned motion without the stick-figure showing through.
How they trained the system, in simple terms:
- First, train the Planner to “see” and plan:
- Sometimes it must detect objects and the starting pose directly from the photo.
- Sometimes it gets the first motion frame and must continue the movement.
- This teaches the Planner to both understand the scene and design motion that fits the text.
- Then, train the Artist to talk well:
- They feed in audio features (numbers that represent speech, extracted by a tool called Wav2Vec) and focus on perfect lip-sync and natural movement first.
- Finally, fine-tune them together:
- The Planner’s motion guides the Artist as they produce the final video, so actions stay aligned with the text and the scene.
They also built a test set called GroundedInter:
- 600 cases with photos, text instructions about interactions, and matching speech audio.
- Used it to fairly compare different methods and measure things like how well the avatar touches objects, lip-sync accuracy, and whether the scene stays consistent.
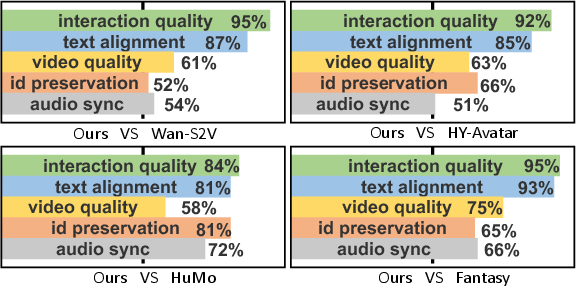
Main Findings
In comparisons with strong existing systems:
- Better interactions: Their avatars are much more likely to actually use hands correctly, touch and move the right objects, and perform richer actions—not just lip movements or small motions.
- Still looks good: Even with more complex interactions, the videos remain high quality and keep the original person and background from the photo.
- Strong lip-sync: Mouth movements match the input speech well.
- Flexible control: The same model can work in different modes, like text + audio, text + audio + motion, or purely text-driven planning.
Why this works:
- Splitting the work into a Planner (scene understanding + motion plan) and an Artist (final video) reduces the control–quality trade-off.
- The aligner keeps the Artist on track with the planned motion without causing visual glitches.
Why It Matters and What’s Next
Implications:
- More realistic digital humans for education, games, virtual assistants, and storytelling, where characters need to handle objects naturally in their actual surroundings.
- Easier control: Creators can use simple text and speech to direct complex actions, instead of building detailed motion scripts.
Limitations and future directions:
- Right now, the system handles one person at a time. Future work could add multi-person interactions and more complex scenes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the key aspects that remain missing, uncertain, or unexplored in the paper. Each item is framed to be concrete and actionable for future research.
- Multi-person interactions are unsupported; how to perceive, plan, and coordinate multi-agent HOI (roles, collision avoidance, social dynamics) remains open.
- Camera and viewpoint are assumed static; handling camera motion, re-framing, and viewpoint changes while preserving grounding to the reference environment is not addressed.
- Grounding is largely 2D; explicit 3D scene understanding (depth, occlusion reasoning, out-of-plane interactions) is absent, limiting physically correct hand–object contact in 3D.
- No physics or contact constraints are enforced; there is no modeling of collisions, friction, grasps, or ergonomic limits. Integrating differentiable physics or contact-consistency losses is an open direction.
- Object state changes are not explicitly modeled (e.g., opening a door, deforming soft objects, liquid transfer). The framework lacks object-centric state tracking beyond bounding boxes.
- Motion is represented as RGB “rendered skeletal poses and object boxes”; the trade-off vs. vectorized keypoints or parametric hand/body models (accuracy under occlusion, small objects, finger articulation) is unquantified.
- Hand–object contact quality is coarsely measured (box–keypoint proximity); there is no evaluation of finger-level articulation, contact area, or grasp stability. Developing fine-grained contact metrics and annotations is needed.
- The GroundedInter benchmark is primarily synthetic (images generated by jimeng4.0) and uses pseudo-labels (SegAny, DINO, DW-Pose) as “ground truth”. Real-world generalization and reliability of evaluation are uncertain.
- Real-scene evaluation is limited (50 cases); broader, diverse, and challenging real-world test sets (occlusions, clutter, lighting changes, motion blur) are required to assess robustness.
- Training data composition, sources, and annotation quality for PIM/AIM are under-specified; reproducibility is limited without release of training datasets and code.
- VLM-QA and CLIP scores can be biased and correlate imperfectly with HOI quality; standardized, task-specific metrics (affordance compliance, trajectory accuracy, contact IoU over time, grasp success) and larger human studies are needed.
- Long-horizon generation is untested (training clips are 3–10s); stability, drift, and cumulative errors over longer sequences (minutes) and complex multi-step tasks remain unclear.
- Scaling to more than 1–3 objects, concurrent interactions, and compound action planning (multi-stage, conditional subgoals) is not explored.
- Robustness to occlusions and challenging object types (small, transparent, reflective, deformable) is unassessed; architecture extensions (open-vocabulary detectors, learned segmentation) may be needed.
- Speech is used only for lip synchronization; leveraging speech content and prosody for action planning (e.g., grounding commands from audio instead of text) is an open question.
- Cross-lingual and noisy audio robustness (accents, speaking rates, background noise, reverberation) is not evaluated; reliance on TTS (CosyVoice) may mask real-world challenges.
- Identity preservation under large motions, self-occlusion, and aggressive manipulation is only lightly evaluated; failure modes and mitigation (e.g., identity-aware priors) warrant study.
- External driving signals require perfect alignment; motion retargeting to varied body shapes, camera setups, and scene scales (automatic spatial calibration) is not handled.
- Efficiency and deployment constraints (runtime, memory, energy, real-time feasibility, batching) are not reported; model compression, distillation, and streaming generation are open avenues.
- Uncertainty and failure detection are absent; the system does not re-perceive or correct plans mid-generation when perception or grounding is unreliable. Closed-loop, feedback-driven control is an open design.
- Generalization to unseen object categories and open-vocabulary grounding (linking text to detection without predefined labels) is unclear; evaluation across broader object taxonomies is needed.
- Dataset bias from synthetic imagery (jimeng4.0) is likely; assessing performance across photorealism levels and domain-adaptive training strategies is missing.
- The M2V aligner is limited to residual feature injection; exploring alternative fusion (cross-attention, gating, adapters, spatial-temporal aligners) and formal analysis of alignment effectiveness remains to be done.
- The RoPE remapping heuristic (virtual timestep −1) lacks sensitivity analysis; learned temporal anchoring or alternative positional schemes may improve stability and generalization.
- Complex hand manipulation (fine finger control, tool use, in-hand object reorientation) is not supported; richer hand models and manipulation priors/constraints are needed.
- Ethical and user-control aspects (preventing unsafe or unintended interactions, interactive correction, constraint specification) are not considered; user-in-the-loop interfaces could enhance reliability.
- Benchmark annotation provenance and licensing (auto vs. manual labels, usage rights) are unclear; releasing high-quality, human-annotated HOI benchmarks would improve community progress.
Practical Applications
Overview
This paper introduces InteractAvatar, a dual-stream Diffusion Transformer system that enables text-driven, environment-grounded human-object interactions for talking avatars by decoupling perception/planning (PIM) from video synthesis (AIM), aligned via a motion-to-video (M2V) residual mechanism. It also provides the GroundedInter benchmark with tailored HOI metrics. Below are practical applications derived from these findings and methods.
Immediate Applications
These applications can be piloted or deployed now using the described framework, with modest integration and productization.
- Shoppable product demos with interactive presenters
- Sector: e-commerce, advertising, media
- Use case: Generate short videos where a brand ambassador avatar in a reference product shot “picks up the sneaker,” “opens the lid,” or “points to features” while lip-syncing a script.
- Tools/products/workflows: API/SDK for “Avatar Studio” integrated into CMS; author prompt + script; upload reference image; optional audio via TTS; export for PDPs and ads.
- Assumptions/dependencies: Single-person scenes; static backgrounds (grounded to the initial image); object detection quality matters; rights to subject identity and background images.
- Instructional micro-lessons and how-to guides
- Sector: education, industrial training, consumer electronics
- Use case: Avatar demonstrates steps like “insert the battery,” “tighten the clamp,” grounded in an equipment photo, with accurate lip-sync to narrated instructions.
- Tools/products/workflows: Authoring tool that ingests text and audio; PIM plans motions; AIM renders video; publish to LMS or help center.
- Assumptions/dependencies: Static scene; constrained to short sequences; interaction represented by poses and bounding boxes (no physical simulation).
- Patient education and device use demonstrations
- Sector: healthcare communication
- Use case: Explain inhaler priming, insulin pen assembly, or brace fitting using clinic or product reference images and clinician narration.
- Tools/products/workflows: Clinical content pipeline; compliance review; export for portals.
- Assumptions/dependencies: HIPAA/IP compliance for images; single-person; no real-time adaptation; validated scripts to reduce misuse.
- Retail digital signage and kiosk presenters
- Sector: retail, OOH media
- Use case: In-store avatars verbally highlight items and gesture to shelves in a photo-based context for promotions.
- Tools/products/workflows: Batch video generation from shelf images and promo scripts; scheduling in signage CMS.
- Assumptions/dependencies: Good scene detection; static layouts; short clips.
- Social media and influencer content augmentation
- Sector: media, creator tools
- Use case: Creators produce talking avatar segments that interact with props (e.g., cooking tools) in a still kitchen photo to complement B-roll.
- Tools/products/workflows: Plugin for editing apps (Premiere/CapCut/Canva); guided prompt templates (“stir the pot,” “hold the knife safely”).
- Assumptions/dependencies: Single-person; limited HOI complexity; brand safety controls.
- Corporate communications with branded object interactions
- Sector: enterprise communications, marketing
- Use case: Executive avatar in office reference photo points to charts, picks up branded merchandise as part of announcements.
- Tools/products/workflows: Internal content pipeline; script-to-video generator; branding assets library.
- Assumptions/dependencies: Identity rights; static office scene; short duration.
- UX walkthroughs and product onboarding clips
- Sector: software, consumer devices
- Use case: Avatar demonstrates hardware setup or points to physical controls in product imagery, supplementing software tutorials.
- Tools/products/workflows: Documentation teams integrate PIM/AIM via SDK; scripts authored from onboarding flows.
- Assumptions/dependencies: Requires clear, high-resolution reference images; single-person.
- Rapid previsualization for scene blocking
- Sector: film/TV, virtual production
- Use case: Quick previs of actor motions interacting with set props using a set photograph, before detailed shoots or 3D previz.
- Tools/products/workflows: Pipeline integration as a blocking storyboard tool; prompt-controlled motion variations.
- Assumptions/dependencies: Not physics-accurate; useful for ideation rather than final shots.
- Benchmarking and evaluation of GHOI systems
- Sector: academia, applied research, model evaluation
- Use case: Use GroundedInter to benchmark text-driven HOI generation, measure hand/object quality, pixel-level interaction, and semantic alignment.
- Tools/products/workflows: Evaluation harness with VLM-QA, CLIP-based metrics, DINO consistency; reproducible test suite.
- Assumptions/dependencies: Synthetic images; metric bias considerations; benchmark maintenance.
- Synthetic training data generation for HOI perception models
- Sector: academia, software (CV), robotics simulation
- Use case: Generate controlled interaction videos with known keypoints/boxes to augment HOI detectors/trackers.
- Tools/products/workflows: Data synthesis pipeline with PIM-generated motion and AIM-rendered video; labels retained via motion representation.
- Assumptions/dependencies: Domain gap from synthetic to real; quality of motion generalization.
Long-Term Applications
These require further research, scaling, or extension (e.g., multi-person, real-time, 3D reasoning, stronger grounding, safety tooling).
- Conversational AR assistants that demonstrate in-situ tasks
- Sector: AR/VR, consumer support, smart home
- Use case: Live assistant overlays a talking avatar that interacts with real household items (e.g., “turn this valve,” “connect this cable”) using the device camera.
- Tools/products/workflows: Real-time perception module; continuous PIM planning; on-device AIM; AR overlay pipelines.
- Assumptions/dependencies: Real-time detection/segmentation; occlusion handling; lighting/domain adaptation; privacy controls.
- Visual coaching for field technicians and customer troubleshooting
- Sector: telecom/utility/consumer electronics support
- Use case: Avatar demonstrates repair steps grounded in the customer’s photo/video of equipment, guiding hand placement and tool use.
- Tools/products/workflows: Support platform integration; dialog systems; safety checklists; escalation workflows.
- Assumptions/dependencies: Diverse scene generalization; multi-view robustness; safety/compliance; multilingual.
- Robot learning from human-object interaction demos
- Sector: robotics, manufacturing, logistics
- Use case: Use PIM’s scene-aware motion planning as a scaffold to generate imitation learning curricula for robot manipulation tasks.
- Tools/products/workflows: Mapping 2D motion to 3D kinematics; physics simulation; vision-language-action alignment.
- Assumptions/dependencies: 3D pose/object state estimation; dynamics/force modeling; sim-to-real transfer.
- Metaverse/VR training with embodied tutors
- Sector: education, enterprise training, healthcare
- Use case: Multi-step procedures taught by avatars that interact with virtual replicas of physical objects, synchronized with voice guidance.
- Tools/products/workflows: 3D assets; physics engines; multi-person coordination; session recording and assessment.
- Assumptions/dependencies: Multi-person HOI support; temporal coherence over long sequences; interoperable content standards.
- Multi-character interactive scenes and dialogue
- Sector: entertainment, simulation, social platforms
- Use case: Avatars converse and hand off objects, following text scripts and grounded in shared environments.
- Tools/products/workflows: Extended PIM for multi-agent planning; collision/occlusion handling; AIM scalability.
- Assumptions/dependencies: Multi-person modeling; object state transitions; robust identity and gaze control.
- Advanced compliance and provenance tooling for synthetic media
- Sector: policy, trust & safety, platform governance
- Use case: Standardized watermarking, disclosure, and provenance for talking avatars that interact with objects in real environments.
- Tools/products/workflows: Cryptographic watermarking; provenance logs; platform-level labeling and detection; audit frameworks using GroundedInter-like metrics.
- Assumptions/dependencies: Cross-platform standards; legal frameworks; user consent and IP verification.
- Studio-grade interactive video editing with controllable HOI tracks
- Sector: software (creative tools), virtual production
- Use case: Integrate M2V-aligner-driven tracks into NLEs to keyframe or prompt-control interactions while preserving video fidelity.
- Tools/products/workflows: NLE plugins; layer-wise residual editing UI; motion track export/import; round-trip workflows.
- Assumptions/dependencies: Exposed control APIs; compute-efficient inference; user training.
- Data-centric evaluation and standardization for GHOI
- Sector: academia, standards bodies
- Use case: Expand GroundedInter with real-scene subsets, multi-person cases, and cross-cultural objects, defining HOI benchmarks and best practices.
- Tools/products/workflows: Community datasets, evaluation servers, leaderboards; shared metric definitions (VLM-QA, PI, HQ/OQ).
- Assumptions/dependencies: Broad participation; metric robustness; dataset licensing.
- Personalized, multilingual avatars for global communications
- Sector: enterprise, media localization, education
- Use case: Maintain subject identity and environment while switching languages and culturally relevant object interactions.
- Tools/products/workflows: TTS/ASR integration; prompt libraries; culturally aware interaction templates.
- Assumptions/dependencies: Cross-lingual audio injection quality; cultural safety; bias mitigation.
- Safety-critical demonstrations (medical devices, hazardous equipment)
- Sector: healthcare, energy, manufacturing
- Use case: Verified avatars demonstrate complex procedures with strict compliance and physics-aware interactions.
- Tools/products/workflows: Validation pipelines; domain-specific motion constraints; expert-in-the-loop reviews.
- Assumptions/dependencies: Physics/ergonomics modeling; regulatory approvals; liability frameworks.
Notes on Feasibility and Dependencies
- Technical constraints: Current system is single-person, short-form (3–10s), grounded to static reference images, and uses 2D motion representations (skeletal poses + object boxes). Complex 3D dynamics, physics, occlusion, and multi-person interactions require research.
- Data and compute: Relies on pre-trained VAE/DiT backbones (wan2.2-5B), T5 text embeddings, Wav2Vec audio features; GPU resources needed for inference at high resolution.
- Legal/ethical: Requires consent and IP rights for subject and background images; strong need for watermarking/provenance to prevent deceptive uses.
- Integration: Best suited as an SDK/API embedded into content pipelines, with authoring tools for prompts/scripts and guardrails for safety and brand control.
Glossary
- Audio-Interaction Aware Generation Module (AIM): The video synthesis module that renders talking avatars conditioned on audio and interaction motion. "Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions."
- Bilinear interpolation: A simple resampling method used to upsample spatial feature maps. "using simple bilinear interpolation."
- CLIP-score: A metric that measures semantic alignment between text and visual content using CLIP. "the CLIP-score~\cite{radford2021learning} between the original text prompt and a VLM-generated caption of the generated video;"
- co-articulation: The influence of surrounding sounds on the articulation of a given phoneme over time. "To capture the co-articulation and temporal dynamics of speech, rather than relying on isolated phonemes, we extract features from a contextual window around each timestep."
- co-generation: Parallel generation of motion and video to improve control and quality. "enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma."
- Control-Quality Dilemma: The trade-off between controllability of actions and visual fidelity in GHOI generation. "Control-Quality Dilemma:"
- cross-attention: An attention mechanism that conditions features from one modality on another. "To achieve frame-level audio-visual alignment, the extracted audio feature sequence {f}_{\text{audio}, i}} is injected into the AIM via cross-attention."
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models used in video generation. "We introduce a dual-stream Diffusion Transformer (DiT) for generating text-controlled grounded human-object interactions."
- DINO consistency: An object-level consistency metric based on DINO features. "Object Quality (OQ), assessed by the product of object dynamics score~\cite{zhang2025speakervid} and object DINO consistency~\cite{zhang2022dino};"
- DW-Pose: A pose estimation method that provides human skeletal keypoints. "and DW-Pose keypoints~\cite{yang2023effective}."
- Flow Matching paradigm: A training framework that learns a vector field guiding latent transitions for generation. "Both modules are trained under a unified Flow Matching paradigm."
- Grounded Human-Object Interaction (GHOI): Human-object interactions that occur within and respect a specific visual environment. "extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects."
- GroundedInter: A benchmark dataset designed to evaluate grounded human-object interaction video generation. "we constructed the GroundedInter benchmark."
- Hand Laplacian sharpness score: A metric assessing the sharpness of rendered hands via Laplacian-based measurement. "Hand Quality (HQ), assessed by the product of hand dynamics score and hand Laplacian sharpness score~\cite{lin2024cyberhost};"
- Layer-wise residual injection: A mechanism that injects residual features from the motion stream into corresponding video layers to enforce control. "the M2V aligner, which employs a layer-wise residual injection mechanism to ensure that the generated video consistently adheres to the evolving structural motion from PIM in lockstep."
- Motion-to-Video (M2V) aligner: A module that aligns motion features to video generation through residual feature injection. "With a specially designed motion-to-video (M2V) aligner, our symmetrical yet decoupled framework effectively alleviates the control-quality dilemma in complex GHOI video generation,"
- Object dynamics score: A metric quantifying how objects move over time in generated videos. "Object Quality (OQ), assessed by the product of object dynamics score~\cite{zhang2025speakervid} and object DINO consistency~\cite{zhang2022dino};"
- Perception and Interaction Module (PIM): The planning module that perceives the environment and generates text-aligned motion sequences. "Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions."
- Pixel-Level Interaction (PI): A metric verifying contact between detected object regions and pose keypoints at the pixel level. "Pixel-Level Interaction (PI), which verifies contact between DINO object boxes and DW-Pose keypoints."
- Rotary Position Embeddings (RoPE): A positional encoding technique for transformers enabling relative rotation in attention. "we employ a custom mapping for its Rotary Position Embeddings (RoPE)."
- Subject-consistent video generation: Video synthesis that maintains subject identity while generating new scenes. "Recently, subject-consistent video generation also exhibited the capacity to synthesize HOI video."
- Temporal consistency (Temp-C): A metric assessing smoothness and coherence across consecutive frames. "temporal consistency (Temp-C) and dynamic degree (DD) from VBench~\cite{zhang2024evaluationagent}."
- Variational Autoencoder (VAE): A generative model that encodes inputs into a latent space and reconstructs them, used here for visual latents. "A pre-trained Variational Autoencoder (VAE)~\cite{wan2025} encodes all visual inputs (videos, motions, ref images) into latent space,"
- vector field: A function mapping latents to their flow directions used in Flow Matching training. "The model is optimized to predict a vector field with the following objective function:"
- VLM-QA: A question-answering evaluation protocol using a vision-LLM to score interaction correctness. "VLM-QA, we design 30 questions structured around three categories (object, human, interaction), and the VLM~\cite{wang2025internvl3_5} assigns a score of 1 or 0 to each based on the provided reference image and video."
- Wav2Vec: A pretrained model for extracting contextualized audio features. "We employ a pre-trained Wav2Vec model~\cite{baevski2020wav2vec} as our audio feature extractor."
- Zero-initialized linear layer: A stability technique where an injected linear projection starts with zero weights. "This is followed by a projection through a zero-initialized linear layer."
Collections
Sign up for free to add this paper to one or more collections.