- The paper introduces a joint optimization framework that refines agent policies and a structured tool graph memory to support compositional reasoning.
- A hybrid advantage estimation mechanism combines episode-level and tool-anchored step-level rewards to improve credit assignment in sparse-reward environments.
- Empirical evaluations on multi-hop QA and mathematical benchmarks demonstrate SEARL's modularity, efficient transfer, and superior performance.
Motivation and Problem Statement
Contemporary RL-based agent frameworks for LLMs are limited by sparse reward signals, static predefined tool sets, and unstructured external memory systems. Monolithic tool synthesis frequently results in combinatorial overwhelm and lack of compositional generalization, especially when leveraging small-to-midsize LLMs in resource-limited deployments. Additionally, current memory augmentation practices do not support explicit inter-tool dependencies, which constrains long-term knowledge accumulation and multi-step planning.
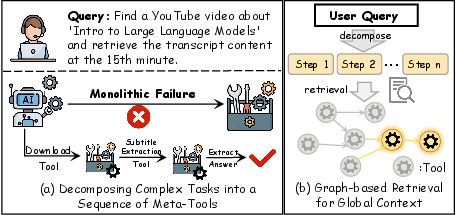
Figure 1: Existing monolithic paradigms overwhelm LLMs and lack the structural memory connectivity required for compositional reasoning.
SEARL Framework Overview
The SEARL framework addresses these deficiencies by jointly optimizing both the agent policy and a structured external Tool Graph Memory. The architecture leverages: (1) task decomposition and trajectory encoding based on agent-environment interaction, (2) tool-anchored step grouping for fine-grained advantage estimation, and (3) a dynamic, self-evolving graph-structured memory that encodes tool semantics and operational dependencies.
Figure 2: SEARL architecture integrates structured agent-environment interaction, anchor-action step grouping, and a dynamic tool graph memory for continual agent self-evolution.
Methodology
SEARL formalizes external memory as a directed Tool Graph TG=(V,E), where nodes denote MCP tools and edges represent inter-tool dependency relations derived from execution order within generated plans. For each new task, the agent generates a DAG-like subplan structure, which is mapped to a corresponding subgraph in the tool memory. Modular tools are encouraged, improving reusability and facilitating decomposition strategies that mitigate the burdens of monolithic reasoning.
Hybrid Advantage Estimation
Credit assignment in sparse-reward RL environments is improved using a two-level advantage structure:
- Episode-Level Relative Advantage: Aggregates cumulative group returns across trajectory rollouts under the same task, offering a stabilized global reward signal.
- Tool-Anchored Step-Level Advantage: For each trajectory, steps are grouped by the tool-invocation anchor, allowing for process-level, tool-specific reward assignment that abstracts away environment state sparsity.
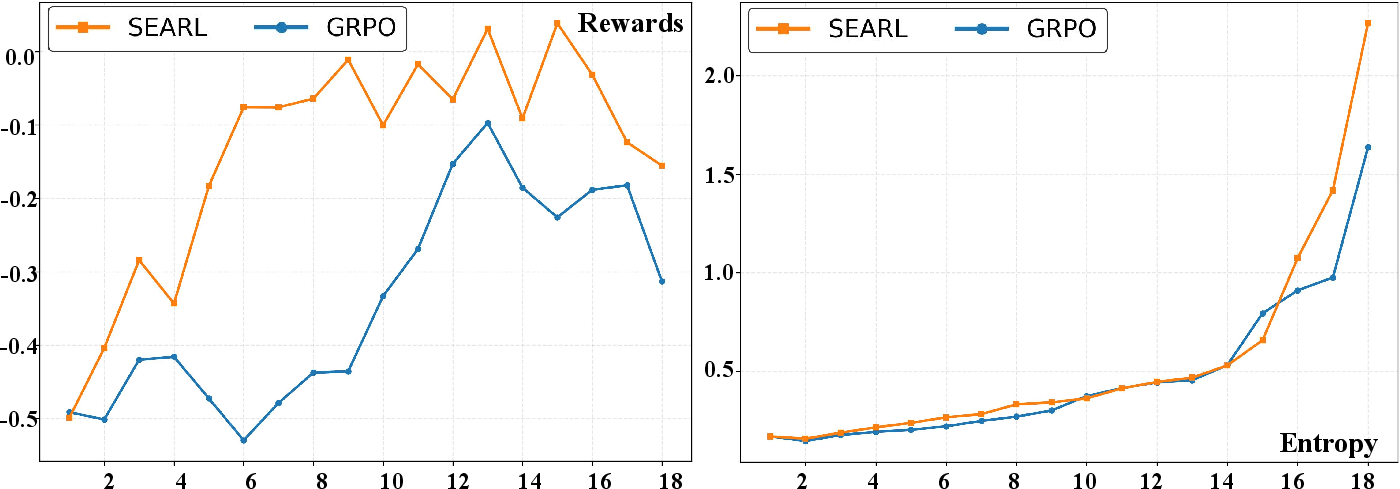
This dual estimation provides both coarse and fine-grained optimization, where tool-anchored groupings are essential for isolating reusable reasoning primitives—an observation confirmed by ablation studies.
Memory Consolidation and Evolution
Tool creation is decoupled from immediate registration to avoid redundancy. After each rollout, only tools w.r.t. highest-rewarded trajectories are preserved and merged into the global memory. Tool equivalence is determined via semantic embedding and cosine similarity, enabling robust merging and effective accumulation of domain experience. Edge integration maintains the causal precedence of tool invocation, resulting in ever-expanding, richly structured agent memory.
Empirical Evaluation
Extensive experiments on long-horizon reasoning tasks—including AIME24, MATH500, GSM8K for mathematics, and HotpotQA, 2WikiMultihopQA, Musique, Bamboogle, and WebWalker for knowledge reasoning—demonstrate the efficiency and generalization capabilities of SEARL-trained agents.
Ablation analysis further demonstrates that step-level grouping is critical: removing this mechanism causes marked degradation, particularly in structurally complex datasets.
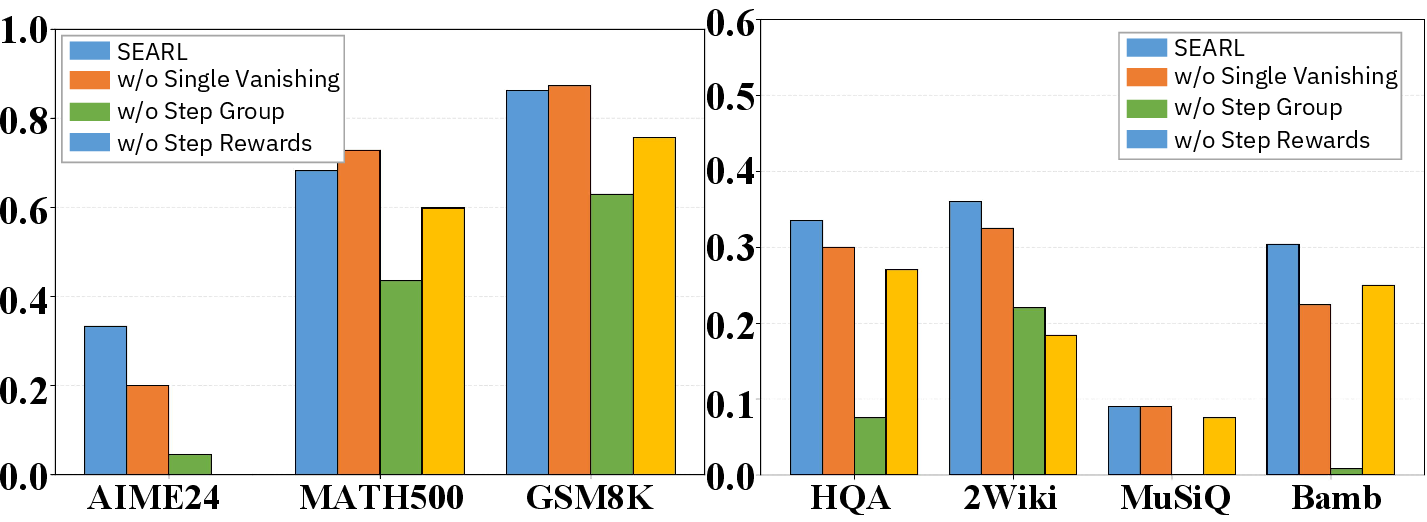
Figure 4: The ablation removing step-level grouping causes the sharpest accuracy decline, highlighting its importance for advantage estimation.
In compositional reasoning scenarios (e.g., sequence optimization), SEARL prevents brute-force search explosion by constructing modular tool chains, hierarchically enforcing constraints, and maximizing reusability.
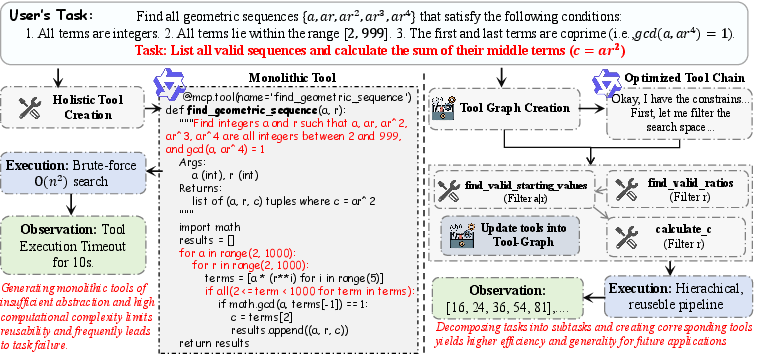
Figure 5: Modular tool chains induced by SEARL prune search spaces and outperform monolithic, brute-force strategies in constrained optimization.
The learned tool graph evolves from fragmented, disjoint structures to densely connected, multi-branch topologies, reflecting transfer and cross-domain synthesis across training.
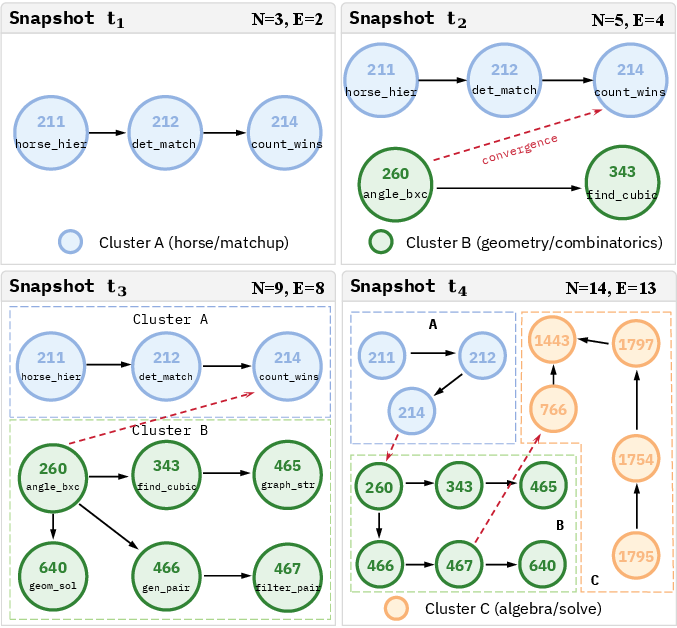
Figure 6: Tool memory evolves from single-path reuse to complex, multi-branch convergence, indicating accumulation of diverse problem-solving experience.
Theoretical and Practical Implications
SEARL formalizes a new paradigm for agent optimization where external knowledge is not a static resource but a continually adapted, topologically structured memory that is intimately linked with policy optimization. Tight coupling between policy learning and structured memory fosters adaptive behavior, efficient transfer, and domain generalization. Process-level reward shaping embedded in the group-based estimation framework provides robust gradients even in environments with sparse outcome rewards.
Practically, this joint optimization unlocks efficient long-horizon reasoning capabilities in small LLMs with minimal deployment overhead, making high-quality agentic capabilities accessible for real-world, resource-constrained environments. The compositional Tool Graph can serve as a persistent skill repository for transfer and meta-learning scenarios.
Theoretically, the structured abstraction and the compositional credit assignment mitigate well-known RL pathologies such as reward sparsity, credit diffusion, and catastrophic forgetting.
Future Prospects
Further work may extend the framework with richer syntactic and semantic tool signatures, cross-agent tool sharing, and hierarchical meta-controller policies governing tool synthesis. This may open avenues toward foundation models capable of structure-aware, persistent, and open-ended learning and reasoning.
Conclusion
SEARL establishes a robust self-evolution paradigm for tool-using agents, wherein policy and graph-structured tool memory co-evolve. The system achieves efficient long-range credit assignment and robust generalization. Empirical results confirm significant improvements in complex multi-hop and mathematical reasoning, especially where compositional reuse and persistent skill accumulation are essential. The approach provides a modular, pluggable framework for continual agent improvement and represents a significant advancement toward structure-aware reinforcement learning in agentic AI (2604.07791).