Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents
Abstract: LLM agents face fundamental limitations in long-horizon reasoning due to finite context windows, making effective memory management critical. Existing methods typically handle long-term memory (LTM) and short-term memory (STM) as separate components, relying on heuristics or auxiliary controllers, which limits adaptability and end-to-end optimization. In this paper, we propose Agentic Memory (AgeMem), a unified framework that integrates LTM and STM management directly into the agent's policy. AgeMem exposes memory operations as tool-based actions, enabling the LLM agent to autonomously decide what and when to store, retrieve, update, summarize, or discard information. To train such unified behaviors, we propose a three-stage progressive reinforcement learning strategy and design a step-wise GRPO to address sparse and discontinuous rewards induced by memory operations. Experiments on five long-horizon benchmarks demonstrate that AgeMem consistently outperforms strong memory-augmented baselines across multiple LLM backbones, achieving improved task performance, higher-quality long-term memory, and more efficient context usage.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping AI assistants built from LLMs handle long, complex tasks better. These assistants can only “see” a limited amount of text at a time (their context window), so they need good memory. The authors introduce Agentic Memory (AgeMem), a system that teaches an AI to manage both long-term memory (what it keeps for later) and short-term memory (what it’s using right now) in a unified, smart way. Instead of following fixed rules, the AI learns to decide when to store, retrieve, summarize, update, or forget information to solve tasks more effectively.
Key Objectives
The paper aims to:
- Combine long-term memory (LTM) and short-term memory (STM) management into one learned system, so the AI can coordinate both.
- Let the AI decide for itself what’s worth remembering, when to bring it back, and when to clean up the current context.
- Train this behavior end-to-end (all at once), rather than using separate modules or hand-crafted rules.
- Make training work even when rewards are rare or delayed, which is common in memory-related tasks.
Methods and Approach
Simple idea with two kinds of memory
- Think of long-term memory (LTM) like a personal notebook the AI keeps across different sessions. It stores important facts it might need later.
- Think of short-term memory (STM) like the papers spread out on the desk right now. This is the current context the AI uses while solving the task. It needs to stay tidy and focused.
Memory as tools the AI can use
The AI is given “tools” (actions) it can call, just like clicking buttons in an app. It decides when to use each tool to manage memory while thinking and acting.
Here are the tools:
- LTM tools: Add (write a new note), Update (edit a note), Delete (remove a note).
- STM tools: Retrieve (pull a note from the notebook onto the desk), Summary (compress a long chunk of context into a shorter summary), Filter (remove irrelevant bits from the desk).
Training with a three-stage plan (analogy: practice rounds)
To teach the AI how and when to use these tools, the authors use progressive reinforcement learning (RL), like leveling up skills in a game:
- Stage 1: Learn to store good long-term memories.
- The AI has casual interactions and must spot useful facts to save in its notebook.
- Stage 2: Learn to control short-term memory under distractions.
- The desk is reset, but the notebook stays. The AI faces distracting info and must summarize or filter the desk to keep it tidy.
- Stage 3: Solve a final task using both memories.
- The AI must retrieve the right notes from the notebook, keep the desk clean, and produce a good answer.
This staged setup forces the AI to rely on what it stored earlier and to manage the current context carefully.
Handling rare rewards with step-wise GRPO
Rewards (scores) often come late—only after the AI finishes the whole task. The paper uses a method called step-wise GRPO (Group Relative Policy Optimization), which works like a fair competition:
- The AI tries multiple attempts on the same task.
- Each attempt gets a score at the end.
- The system compares the attempts and uses the relative scores to assign credit to all the earlier steps in that attempt—including memory actions taken long before the final answer.
- This way, good outcomes reinforce the chain of decisions that led to them.
What counts as a “good” outcome?
The reward considers:
- Task success: Did the AI answer correctly?
- Good context management: Did it avoid clutter, summarize early, and keep useful info on the desk?
- Good long-term memory: Did it store high-quality, reusable facts and maintain them (update/delete) responsibly?
- Penalties: Avoid using too many tools, storing junk, or letting the desk overflow.
Main Findings
The authors tested AgeMem on five different benchmarks that require long-horizon reasoning (including ALFWorld, SciWorld, PDDL planning, BabyAI, and HotpotQA). The key results:
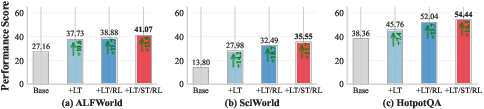
- Better overall performance: AgeMem consistently beat strong memory baselines across two different LLMs. It achieved the highest average scores and notable gains over a “no memory” agent.
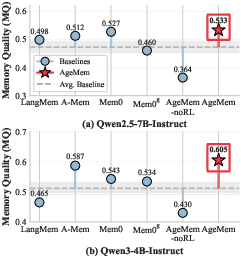
- Higher-quality long-term memory: On HotpotQA, AgeMem stored notes that matched ground-truth facts more closely than other systems (higher Memory Quality scores).
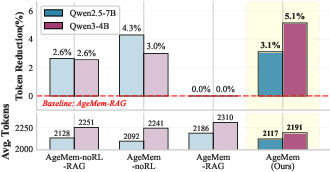
- More efficient short-term memory usage: AgeMem used fewer tokens in prompts than a version that replaced STM tools with a standard retrieval method (RAG), reducing prompt length by about 3–5% while keeping or improving accuracy.
- RL makes a real difference: Training with the three-stage RL and step-wise GRPO led to more frequent and smarter use of tools (especially Add and Update for LTM, and Filter for STM), and higher task scores than a non-RL version.
Why This Matters
This research shows a practical way to make AI assistants more “agentic” and long-term capable:
- Smarter memory = better problem-solving: By learning when to remember, what to bring into focus, and what to ignore, the AI can handle longer, more complex tasks without getting overwhelmed by its limited context window.
- Less hand-tuning, more adaptability: Instead of relying on fixed schedules or separate managers, the AI learns the memory strategy that fits the task.
- Efficient and scalable: Unified memory management can reduce clutter, improve relevance, and simplify system design (no need for extra expert controllers).
In simple terms: this helps build AI assistants that remember important stuff, don’t clutter their workspace, and use their “notebook” and “desk” in sync—leading to faster, cleaner, and more accurate thinking over long tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could directly address.
- Tool set coverage: The fixed six-tool interface (Add, Update, Delete, Retrieve, Summary, Filter) omits operations critical for large-scale memory (e.g., deduplication, conflict resolution, ranking/prioritization, hierarchical/graph linking, merge/split, cross-entry co-reference, temporal decay, TTL-based forgetting, provenance tracking). What extensions materially improve performance without excessive complexity?
- LTM store specification: The paper does not detail the long-term memory data model and indexing (flat text vs. embeddings, vector DB backend, graph structure, sharding/partitioning). How do different storage/indexing designs affect retrieval accuracy, latency, and scalability as memory grows?
- Retrieval mechanics: The method abstracts “Retrieve” but leaves similarity metrics, re-ranking, and retrieval pipelines unspecified. Which retrieval strategies (dense, hybrid lexical+dense, query expansion, learning-to-rank) best synergize with AgeMem’s policy?
- Memory scaling behavior: No experiments characterize performance/latency as LTM size increases. What are the scaling laws for task success, MQ, token usage, and tool-call overhead when memory grows by 10×–100×?
- Forgetting and staleness management: While Update/Delete are available, there is no evaluation of policies for aging, decay, or staleness detection. Which forgetting strategies avoid staleness and catastrophic forgetting while preserving rare-but-critical facts?
- Conflicts and contradictions: The framework does not address detection and resolution of contradictory or mutually inconsistent memory entries. How should agents identify and reconcile conflicts to prevent reasoning errors?
- Memory poisoning and reliability: The system lacks defenses against adversarial or low-quality inputs stored into LTM. What safeguards (trust scoring, source attribution, anomaly detection) are needed to ensure memory integrity?
- Privacy, compliance, and right-to-be-forgotten: Persistent memory raises data governance questions not explored here. How should consent, deletion requests, and privacy policies be enforced in AgeMem?
- Context summarization fidelity: STM evaluation emphasizes token reduction, but does not quantify information loss or faithfulness of summaries. How can we measure and guarantee that summarization preserves task-critical details?
- Context-window sensitivity: The method is tested on two Qwen variants but not across diverse context-window sizes. How do tool usage and performance vary under tight vs. expansive context budgets?
- Progressive RL realism: Stage resets (resetting STM between Stage 1 and 2) may not reflect real-world continuous interactions. How sensitive are results to more realistic, non-reset trajectories?
- Distractor generation: Stage 2 relies on “semantically related but irrelevant” distractors without a formal generation protocol. How do distractor type, density, and placement affect learning and robustness?
- Credit assignment robustness: Broadcasting the terminal advantage to all steps may misattribute credit across heterogeneous memory actions. How do alternative credit assignment methods (per-step shaping, TD methods, backward induction) compare?
- GRPO variant analysis: The step-wise GRPO design is introduced without theoretical guarantees or head-to-head comparisons against PPO/A2C/TD3. What are its stability, sample-efficiency, and variance characteristics for memory-intensive trajectories?
- Reward dependence on LLM judges: Task and memory rewards rely on LLM-as-a-judge, which can be biased or inconsistent. How robust is training to judge choice, drift, and noise? Can judge-free or reference-free metrics substitute?
- Reward weight tuning: All reward weights are set to 1.0 without sensitivity analysis. Which weighting schemes or automated tuning (bandits, meta-RL) yield better trade-offs between task success, memory quality, and context efficiency?
- Penalty calibration: Penalties (e.g., for context overflow, excessive tool use) are not systematically tuned or analyzed. How do penalty schedules influence exploration vs. conservative behavior and overall performance?
- Tool-call budget optimization: RL increases total tool calls. What is the optimal budgeting or dynamic pricing for tool invocations to balance latency/cost and accuracy?
- Inference efficiency: The paper lacks latency/throughput and monetary cost measurements for tool-based memory operations. What are end-to-end deployment costs and how can they be reduced?
- Evaluation breadth: Training is done only on HotpotQA, then evaluated on five benchmarks. How does AgeMem generalize under domain shift, multi-lingual settings, code-generation tasks, and interactive/embodied environments?
- Memory quality assessment beyond HotpotQA: MQ is only reported for HotpotQA with ground-truth supporting facts. How can MQ be measured in domains without explicit gold memories?
- Statistical rigor: No significance testing, variance across seeds, or compute budget parity analyses are provided. Are improvements consistent across runs and fair relative to baseline training budgets?
- Baseline completeness: Comparisons omit unified LTM+STM baselines trained with RL or more advanced RAG (e.g., adaptive retrieval, memory-aware RAG). How does AgeMem fare against stronger integrated baselines?
- Multi-agent and concurrent memory: The framework evaluates single-agent settings. How does unified memory behave under multi-agent collaboration, concurrent writes, and shared vs. private memories?
- Non-text and multimodal memory: The approach focuses on text. How should tools and policies extend to multimodal inputs (images, actions, code traces) and cross-modal retrieval?
- Long-horizon persistence: Memory persistence across sessions and long timescales is not empirically tested. How stable are policies and memory usefulness over weeks/months of interaction?
- Personalization and identity: There is no study on user-specific memories (profiles, preferences). How should AgeMem manage per-user segmentation, drift, and transfer learning across identities?
- Safety under tool exposure: Exposing tools may introduce prompt-injection surfaces or unintended behaviors (e.g., excessive deletes). What guardrails, policy constraints, or verification layers are needed?
- Failure mode analysis: The paper lacks detailed failure case studies (e.g., over-filtering, under-retrieval, summary hallucination). What systematic diagnostics best reveal and correct memory-management errors?
- Theoretical grounding: The unified RL formulation does not provide convergence or regret analyses under discontinuous, tool-induced trajectories. Can formal guarantees be derived for this setting?
- Lifecycle and provenance: The system does not track memory provenance, versioning, or audit trails. What metadata and lifecycle policies improve trust, debuggability, and maintainability of LTM?
- Integration with external KBs: AgeMem treats memory as agent-internal. How should it interoperate with knowledge bases, APIs, and enterprise data while preserving consistency and minimizing duplication?
- Generalization to variable tool schemas: It is unclear how policies adapt if tool semantics or arguments change. Can the agent meta-learn tool usage across evolving interfaces?
- Robustness to contradictory task signals: When rewards favor compression but tasks need exhaustive context, how does AgeMem resolve trade-offs? Can adaptive policies learn task-conditional memory strategies?
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now by adapting the paper’s unified memory tools (Add/Update/Delete for LTM; Retrieve/Summary/Filter for STM) and, where helpful, its step‑wise GRPO training recipe. When RL compute or data is limited, deploy the tool interface with heuristic or light supervision first (akin to AgeMem‑noRL), and progressively add RL.
- Software/Enterprise: Unified-memory enterprise copilots (docs/coding/BI)
- What: Copilots that selectively store reusable facts (LTM) about products, teams, and decisions, while summarizing/filtering working context (STM) to keep prompts lean. Example flows: code review assistant that adds/retrieves “project conventions,” BI copilot that preserves KPI definitions and recurring SQL patterns.
- Tools/products/workflows: “Memory SDK” for LangChain/Agentscope; drop‑in wrapper that exposes memory tools as function calls; dashboards to inspect and edit LTM entries and STM summaries.
- Dependencies/assumptions: Function‑calling LLM; vector/kv store for LTM; governance UI for audit/delete; optional RL data from historical logs; privacy controls for sensitive org data.
- Customer Support and CRM: Context‑aware contact center agent
- What: Agents that add/update customer preferences, past resolutions, and entitlements (LTM), and filter/summarize long tickets or multi‑turn chats (STM) to reduce token bloat while preserving salient details.
- Tools/products/workflows: “Memory‑aware” triage and resolution playbooks; automatic case summaries; auto‑forget rules for stale entitlements.
- Dependencies/assumptions: CRM integration (e.g., Zendesk, Salesforce), clear PII retention policies (GDPR/CCPA), redaction pipeline, LLM‑as‑a‑judge or rule metrics for QA.
- Productivity: Meeting/project copilots with durable team memory
- What: Assistants that convert meeting notes and action items into structured LTM, and retrieve/summarize only what’s relevant per sprint/epic (STM).
- Tools/products/workflows: Auto‑generated “living PRDs,” sprint retros, decision logs with Update/Delete to prevent staleness.
- Dependencies/assumptions: Calendar/docs integrations; review checkpoints to avoid compounding incorrect memories; role‑scoped access controls.
- Education: Personalized tutoring with learning profiles
- What: Tutors that steadily build LTM of student misconceptions and mastery while summarizing lesson context per session to avoid context overflow.
- Tools/products/workflows: “Student model” memory cards; adaptive retrieval of prerequisite knowledge; proactive Summary to keep context within token budget.
- Dependencies/assumptions: Parental/school consent for data; guardrails against bias; simple rubrics to score task performance without costly judges.
- Legal/Knowledge Work: Long‑document QA with lean prompts
- What: Agents that learn when to summarize and filter statute/contract segments (STM) and store reusable precedent and definitions (LTM).
- Tools/products/workflows: Retrieval with pre‑summarized “case kernels;” Update/Delete to handle superseded clauses.
- Dependencies/assumptions: Strict auditability of memory operations; human approval gates; jurisdiction‑aware retention rules; reliable doc chunking.
- Finance/Analytics: BI and research assistants that retain institutional knowledge
- What: Maintain LTM of canonical metric definitions, data lineage, and recurring analyses; filter verbose query histories (STM) to keep costs low.
- Tools/products/workflows: “Metric memory” registry; explainable retrieval of lineage before answering; preventive Summary when prompts grow.
- Dependencies/assumptions: Stable data catalogs; SOC2/ISO controls; versioned memory entries; careful evaluation to avoid hallucinated KPIs.
- Software Engineering: Code agents with scoped memory
- What: Agents store project conventions, API quirks, and fix patterns (LTM) and summarize diff/context windows during long refactors (STM).
- Tools/products/workflows: Memory‑backed code review bots; auto‑Update/Delete when conventions change; per‑repo memory sandboxing.
- Dependencies/assumptions: Repo permissions; CI hooks; embedding/code search infra; change‑management signals to avoid stale LTM.
- Robotics (simulation/digital twins): Long‑horizon task agents
- What: In simulated environments (ALFWorld‑like), agents learn to add reusable affordances and object relations (LTM) and filter distractors (STM) for multi‑step tasks.
- Tools/products/workflows: Sim training kits with staged trajectories; policy checkpoints transferable to digital twins.
- Dependencies/assumptions: Reliable simulators; tool‑calling interface to environment APIs; carefully shaped rewards; limited sim‑to‑real gap for now.
- Research/Academia: Memory‑centric evaluation harness
- What: Apply the staged trajectory design and MQ (memory quality) scoring to evaluate agent memory policies across tasks.
- Tools/products/workflows: Open prompts/judges; dataset construction scripts for Stage‑1/2/3 rollouts; baseline comparisons with/without STM tools.
- Dependencies/assumptions: Access to LLM judge or weak supervision; consistent MQ rubric; compute for multi‑rollout GRPO.
- Cost/Latency Optimization: Token‑efficient prompting in existing apps
- What: Introduce Summary/Filter tools to trim prompts while preserving key info, often reducing 3–5% tokens or more without accuracy loss.
- Tools/products/workflows: Prompt budget monitors; automatic early summarization when token growth is detected.
- Dependencies/assumptions: Token accounting; minimal integration to call STM tools; regression tests to guard against information loss.
Long-Term Applications
These require more R&D, scaling, safety/validation, or policy alignment, but are natural extensions of the paper’s unified memory and progressive RL approach.
- Healthcare: Longitudinal AI scribe and care‑plan copilot
- What: Persistent LTM of patient histories, meds, and prior plans; STM summarization of multi‑visit notes; Update/Delete for medication changes.
- Tools/products/workflows: EHR‑integrated memory controller; auditable retrieval before recommendations; proactive filtering of irrelevant chart noise.
- Dependencies/assumptions: HIPAA/GDPR compliance; clinical validation; bias and error mitigation; human‑in‑the‑loop; on‑prem/private‑cloud deployment.
- Industrial & Home Robotics: Memory OS for real‑world autonomy
- What: Robots that learn reusable routines and environment maps (LTM), suppress distractors (STM), and coordinate memory with perception/planning.
- Tools/products/workflows: Cross‑session skill libraries with Update/Delete; failure‑aware memory rollbacks; on‑device memory controllers.
- Dependencies/assumptions: Robust sim‑to‑real transfer; safety certification; real‑time constraints; multi‑modal memory (vision, haptics) support.
- Organizational Knowledge OS: Self‑curating corporate memory
- What: Agents that autonomously consolidate, refactor, and retire knowledge across wikis, tickets, repos, and chats.
- Tools/products/workflows: Company‑wide AgeMem policy with role‑based access; forgetting/retention SLAs; explainable memory edits.
- Dependencies/assumptions: Data governance; provenance tracking; cross‑system connectors; organizational change management.
- Public Sector/Policy: Case management and benefits administration
- What: Persistent case histories (LTM) with transparent retrieval for determinations; STM filtering of multi‑agency records to reduce processing time.
- Tools/products/workflows: Audit logs of Add/Update/Delete; policy‑aware prompts; compliance checks before final actions.
- Dependencies/assumptions: Statutory constraints; public records workflows; robust auditability and appeal processes; accessibility standards.
- Compliance and Regulation: Continuous rule‑tracking copilots
- What: Agents that store evolving rules/regulatory interpretations (LTM) and automatically update/retire entries; STM summarization of filings.
- Tools/products/workflows: “Reg change diff” pipelines; evidentiary retrieval before attestation; memory freshness monitors.
- Dependencies/assumptions: Verified sources; legal oversight; tamper‑evident logs; benchmark suites for correctness.
- Privacy‑Preserving and Federated Memory Training
- What: Train AgeMem policies across organizations or devices without moving raw data, with local Add/Update/Delete and global policy sharing.
- Tools/products/workflows: Federated GRPO variants; differential privacy on rewards; client‑side memory stores.
- Dependencies/assumptions: Secure aggregation; robust privacy budgets; heterogeneity handling across clients.
- Standards and Governance: Auditable memory operations
- What: Interoperable schemas and APIs for memory tools, including reason fields for each Add/Update/Delete and retrieval provenance.
- Tools/products/workflows: “Memory Change Ledger” standard; third‑party auditing tools; red‑team tests for memory abuse.
- Dependencies/assumptions: Industry consortia participation; regulatory buy‑in; reference implementations.
- Multi‑Agent and Cross‑Agent Memory Sharing
- What: Teams of agents sharing vetted LTM entries and STM summaries for handoffs (e.g., from discovery to delivery).
- Tools/products/workflows: Memory‑scoped sharing policies; conflict resolution protocols; team‑level reward shaping.
- Dependencies/assumptions: Trust and access controls; attribution of memory provenance; coordination overhead.
- Multi‑Modal Memory (text+vision+sensor)
- What: Unified LTM/STM over documents, images, audio, and sensor streams for domains like manufacturing QA, radiology, or retail shelf audits.
- Tools/products/workflows: Modality‑aware Summaries; embeddings/indices per modality; cross‑modal retrieval to STM.
- Dependencies/assumptions: Reliable multi‑modal encoders; alignment losses across modalities; domain‑specific accuracy testing.
- Safer RL for Memory Policies (beyond LLM judges)
- What: Replace or augment LLM‑as‑judge with verifiable metrics, weak supervision, or programmatic rewards to reduce brittleness.
- Tools/products/workflows: Reward model distillation; hybrid rule+learned rewards; safe exploration for sparse/discontinuous memory operations.
- Dependencies/assumptions: Labeling pipelines; domain gold standards; governance for reward hacking prevention.
- On‑Device/Edge Agents with Learned Memory
- What: Smartphones, wearables, and vehicles with local LTM (privacy) and STM compression to reduce cloud calls.
- Tools/products/workflows: Lightweight tool‑calling; memory pruning and compaction; intermittent sync to trusted backends.
- Dependencies/assumptions: Efficient local models; hardware acceleration; secure enclaves; energy constraints.
Notes on Cross‑Cutting Assumptions and Dependencies
- Tool support: The LLM must support function/tool calling, and the application must expose memory stores (vector DB/kv store) with CRUD and provenance.
- RL data and compute: Progressive RL with step‑wise GRPO benefits from multi‑rollout logs and reward signals; in data‑sparse or compute‑limited settings, start with supervised heuristics and upgrade to RL gradually.
- Evaluation: LLM‑as‑a‑judge is convenient but imperfect; for high‑stakes domains, adopt programmatic/ground‑truth metrics and human review.
- Privacy, security, compliance: Memory persistence increases risk surface; require redaction, encryption at rest, role‑based access, and auditable memory operations.
- Safety and staleness: Proactive Update/Delete is essential; include freshness monitors, drift detection, and human override for critical updates.
- Cost control: STM tools can reduce tokens; incorporate prompt budget monitors and early summarization triggers to limit spend without harming accuracy.
Glossary
- A-Mem: An agentic long-term memory system for LLM agents that links structured knowledge units to consolidate and organize information. "A-Mem~\citep{xu2025mem} adopts a Zettelkasten-inspired design that links structured knowledge units to facilitate consolidation."
- AgeMem: A unified framework that integrates long-term and short-term memory management into the agent’s policy via tool-based operations. "we propose Agentic Memory (AgeMem), a unified framework that integrates LTM and STM management directly into the agentâs policy."
- Agentscope framework: A software framework used to build LLM-based agents in the experiments. "We build agents using the Agentscope framework~\citep{gao2025agentscope}"
- Advantage (group-normalized advantage): A relative performance signal in policy optimization that normalizes rewards within a group to guide learning. "We compute the group-normalized advantage for the terminal step as:"
- Context window: The finite span of tokens an LLM can condition on, limiting how much context it can attend to at once. "LLM agents face fundamental limitations in long-horizon reasoning due to finite context windows, making effective memory management critical."
- GRPO (Group Relative Policy Optimization): A reinforcement learning method that optimizes policies using the relative quality of trajectory groups, often without a value function. "we design a step-wise Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath}"
- Importance ratio: The ratio of action probabilities under the new and old policies used to scale updates in off-policy optimization. "where the importance ratio
$\rho_t^{(k,q)} = \frac{\pi_\theta(a_t| s_t)}{\pi_{\theta_{\text{old}(a_t |s_t)}$
controls the update magnitude under the new policy"
- KL divergence: A regularization penalty measuring how different the current policy is from a reference policy, used to stabilize training. "and $D_{\text{KL}^{(k,q)}$ denotes the KL divergence penalty between the current policy and a fixed reference $\pi_{\text{ref}$"
- Long-horizon reasoning: Reasoning over extended multi-step interactions where memory and context management are critical. "LLM agents face fundamental limitations in long-horizon reasoning due to finite context windows"
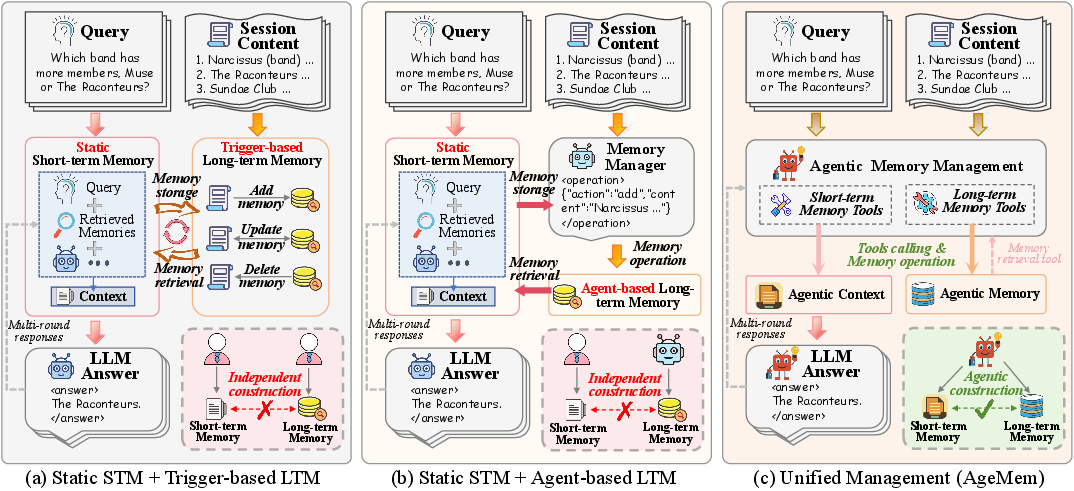
- Long-term memory (LTM): Persistent memory that stores user- or task-specific knowledge beyond the current context. "long-term memory (LTM), which persistently stores user- or task-specific knowledge"
- LLM-as-a-Judge (J): An evaluation approach that uses an LLM to score task completion quality. "For the primary task completion metrics, we adopt Success Rate (SR) for ALFWorld, SciWorld, and BabyAI, Progress Rate (PR) for PDDL, and LLM-as-a-Judge (J) for HotpotQA."
- Memory Manager: A specialized agent component that controls long-term memory operations in some architectures. "(Middle) Independent framework with an additional Memory Manager controlling LTM in an agent-based manner, while STM remains static."
- Memory Quality (MQ): A metric quantifying the relevance and usefulness of stored long-term memories. "measured by Memory Quality (MQ)."
- Retrieval-Augmented Generation (RAG): A technique that augments prompts by retrieving external or stored content to expand usable context. "STM is commonly enhanced through retrieval-augmented generation (RAG)~\citep{pan2025memory}"
- Rollout: A sampled trajectory of interactions used in reinforcement learning to estimate returns and update policies. "where denotes the number of independent rollouts"
- Short-term memory (STM): The currently active input context the agent can directly attend to during reasoning. "short-term memory (STM), which comprises the information contained in the current input context"
- Step-wise GRPO: A variant of GRPO that broadcasts terminal advantages to all steps, linking final task rewards to intermediate decisions. "We adopt a step-wise variant of GRPO to connect long-range task rewards with memory decisions across all stages."
- Temporal knowledge graph: A knowledge graph that encodes time-aware relations to support cross-session and time-sensitive reasoning. "Zep~\citep{rasmussen2025zep} represents memory as a temporal knowledge graph to enable cross-session and time-aware reasoning."
- Trajectory: The sequence of states and actions across an episode; the unit over which returns are computed. "For a trajectory , the cumulative reward is defined as:"
- Trinity framework: A fine-tuning framework used to train the proposed system. "and fine-tune AgeMem using the Trinity framework~\citep{pan2025trinity}."
- Zettelkasten: A note-linking organizational method that structures knowledge via interconnected units. "A-Mem~\citep{xu2025mem} adopts a Zettelkasten-inspired design that links structured knowledge units to facilitate consolidation."
Collections
Sign up for free to add this paper to one or more collections.