- The paper presents VerlTool, a unified framework that decouples RL workflows from tool execution to enable scalable, asynchronous multi-turn learning.
- The paper demonstrates that using asynchronous rollouts, VerlTool achieves up to a 2× speedup and competitive performance across six ARLT tasks including math, SQL, and visual reasoning.
- The paper highlights a plugin-based design that simplifies integration of diverse tools, fostering extensibility and reproducibility in agentic reinforcement learning.
Motivation and Context
The paper introduces VerlTool, a modular and extensible framework for Agentic Reinforcement Learning with Tool Use (ARLT), addressing the fragmentation and inefficiency of prior RL-based tool-using agent systems. Existing ARLT implementations are typically task-specific, tightly coupling tool logic with RL workflows and relying on synchronous execution, which impedes scalability, reproducibility, and extensibility. VerlTool formalizes ARLT as multi-turn RL with multi-modal observation tokens, supporting diverse tool types and asynchronous rollouts, and is upstream-aligned with VeRL for compatibility and maintainability.
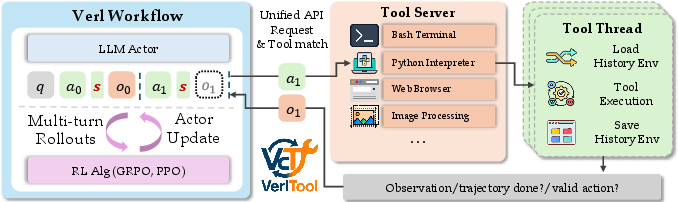
Figure 1: Overview of VerlTool, illustrating the modular separation of RL workflow and tool execution for extensibility and efficiency.
Framework Architecture and Design Principles
VerlTool is architected around two decoupled components: the RL workflow (Verl Workflow) and the Tool Server, connected via a unified API. The RL workflow manages multi-turn rollouts and policy optimization, while the Tool Server handles tool execution, supporting modalities such as code interpreters, search engines, SQL databases, and image processors. This separation enables independent scaling and maintenance of RL and tool services.
A key innovation is the asynchronous rollout pipeline, where each trajectory interacts with the Tool Server independently, eliminating idle waiting and maximizing resource utilization. This design achieves up to 2× speedup in rollout throughput compared to synchronous batch-based frameworks.
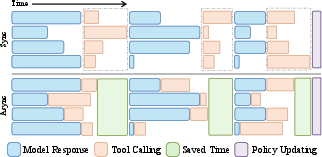
Figure 2: Visualization of the asynchronous rollout pipeline, demonstrating concurrent evolution of actor and environment.
Tool integration is realized via a plugin system: each tool is implemented as a subclass of a unified BaseTool, with standardized interfaces for action parsing, environment state management, and execution. Adding a new tool requires only a lightweight Python definition, facilitating rapid extensibility and minimizing development overhead.

Figure 3: Example code for adding a new tool in VerlTool using the plugin interface.
Tokenization of LLM-generated actions and tool observations is handled carefully to ensure stable alignment across multi-turn trajectories, avoiding inconsistencies that can destabilize training.
VerlTool extends the RLVR paradigm to multi-turn, tool-augmented trajectories. The agent's trajectory is τ={a0,o0,…,an−1,on−1,an}, where ai are LLM actions and oi are tool observations. Tool invocation is detected via predefined stop tokens, and observation tokens are masked during policy optimization to maintain on-policy stability.
The framework supports GRPO (Generalized Reward Policy Optimization) for RL, with the loss function adapted to multi-turn, tool-augmented settings. This enables credit assignment across sequential tool calls and explicit handling of observation tokens, which are off-policy with respect to the current LLM.
Experimental Evaluation Across Six Domains
VerlTool is evaluated on six ARLT tasks: mathematical reasoning (Python executor), knowledge QA (search retriever), SQL generation (SQL executor), visual reasoning (image operations), web search (browser API), and software engineering (bash/code execution). The framework demonstrates competitive or superior performance compared to specialized baselines, while providing unified infrastructure and extensibility.
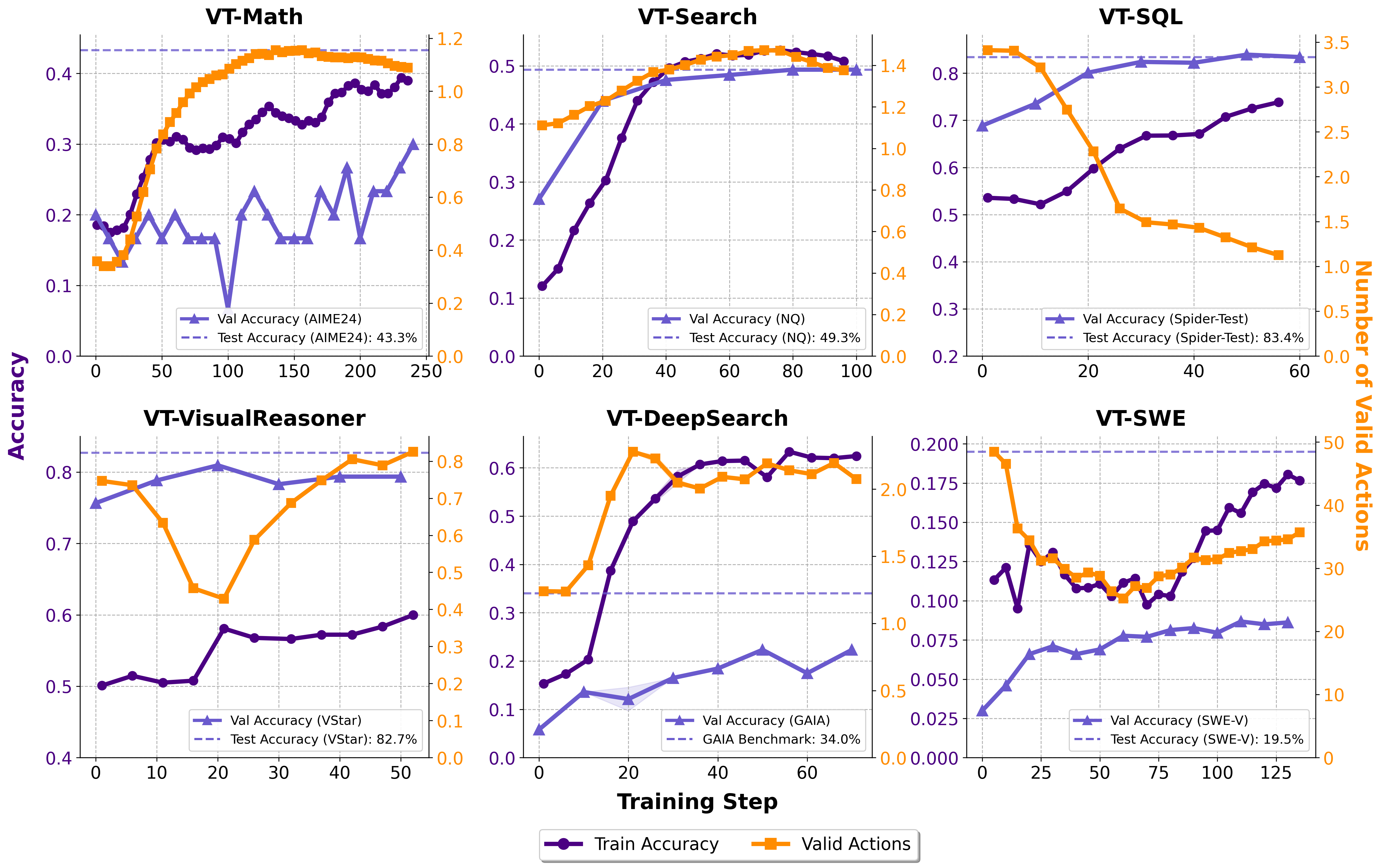
Figure 4: Training dynamics of VerlTool across six tasks, showing competitive evaluation performance and action statistics.
Notable results include:
- VT-Math achieves up to 62.2% average on mathematical benchmarks, matching or exceeding ToRL and SimpleRL baselines.
- VT-Search reaches 45.9% on knowledge QA, outperforming Search-R1.
- VT-SQL matches SkyRL-SQL on Spider benchmarks.
- VT-VisualReasoner achieves 82.7% on V* Bench, competitive with Pixel-Reasoner.
- VT-DeepSearch attains 34.0% on GAIA, surpassing vanilla RAG and WebThinker.
- VT-SWE achieves 19.5 on SWE-Verified, outperforming OpenHands and SkyRL-v0.
The framework supports multi-modal tool integration, with agents dynamically invoking tools across text, code, SQL, and visual domains. Tool usage patterns are task-dependent: mathematical and SQL tasks see rapid reduction in tool calls as models learn to memorize results, while search and web tasks require persistent tool invocation due to the non-memorability of retrieved content.
Implementation and Scaling Considerations
VerlTool's modular design enables scalable deployment in distributed environments. The Tool Server supports both multi-threaded and Ray-based asynchronous execution, allowing efficient resource management for lightweight and resource-intensive tools. The separation of RL and tool services facilitates elastic scaling, fault tolerance, and efficient orchestration via Kubernetes and Docker.
Training configurations are tailored per task, with batch sizes, turn limits, and temperature settings adjusted for task complexity. The framework is robust to environment failures, with timeouts and exception handling ensuring stable RL optimization.
Implications and Future Directions
VerlTool provides a principled foundation for ARLT research, enabling reproducible, extensible, and efficient training of tool-using LLM agents. The unified API and plugin system lower the barrier for community adoption and algorithmic innovation, supporting rapid experimentation with new tools and modalities.
The framework's support for asynchronous rollouts and multi-modal tool integration positions it as a scalable solution for long-horizon, agentic RL tasks. The demonstrated competitive performance across diverse domains validates the effectiveness of unified, modular ARLT training.
Future research directions include:
- Extending support for more complex tool orchestration, including hierarchical and multi-agent tool use.
- Investigating advanced reward designs for emergent agentic behaviors, such as strategic planning and self-correction.
- Scaling to larger models and more challenging environments, including real-world web and software engineering tasks.
- Integrating process-level and implicit rewards for more robust agentic learning.
Conclusion
VerlTool addresses critical limitations in ARLT system design, providing a unified, modular, and efficient framework for training tool-using LLM agents. Its extensible architecture, asynchronous execution, and multi-modal support enable competitive performance across six domains, while facilitating scalable research and deployment. VerlTool establishes a robust foundation for future advances in agentic RL and tool-augmented LLM research.

