- The paper introduces PSP and VRG to mitigate premature answer generation and improve sequential reasoning in diffusion multimodal language models.
- It demonstrates that these techniques enhance multimodal performance with up to 7.5% accuracy improvement and a 3× speedup over baseline methods.
- The analysis reveals delayed visual grounding in dMLLMs compared to AR models, necessitating paradigm-specific inference strategies.
Thinking Diffusion: Penalize and Guide Visual-Grounded Reasoning in Diffusion Multimodal LLMs
Introduction
The paper "Thinking Diffusion: Penalize and Guide Visual-Grounded Reasoning in Diffusion Multimodal LLMs" (2604.05497) addresses the reasoning process in diffusion-based multimodal LLMs (dMLLMs). While diffusion LLMs (dLLMs) have demonstrated efficient parallel token generation over standard autoregressive (AR) LLMs, a direct extension to multimodal settings reveals systemically different reasoning behaviors, especially under Chain-of-Thought (CoT) prompting. The study identifies and analyzes two key deficiencies: early answer generation and insufficient early visual grounding during inference, attributing them to the intrinsic parallel restoration mechanism of dMLLMs.
To mitigate these issues and improve visual reasoning accuracy and sample efficiency, the authors introduce two inference-time techniques: Position Step Penalty (PSP) and Visual Reasoning Guidance (VRG). These methods bias token generation toward greater reasoning completeness and visual dependency, without retraining the underlying model.
Analysis of Reasoning Dynamics in dMLLMs
A central observation is that dMLLMs differ fundamentally from their AR counterparts in how answers are generated during CoT inference. Under practical settings (modest L and T), the model often generates the answer token very early, with subsequent reasoning steps acting as post hoc justifications. This phenomenon is captured as "Early Answer Generation". Quantitative experiments with LaViDa demonstrate that over 30% of instances generate an answer within the first 7 diffusion steps for L=64, T=32, regardless of the longer CoT (Figure 1).
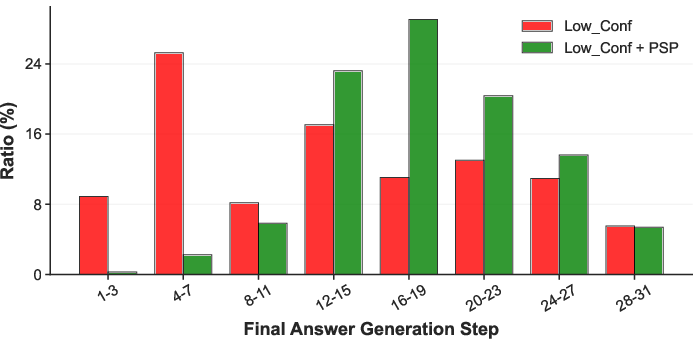
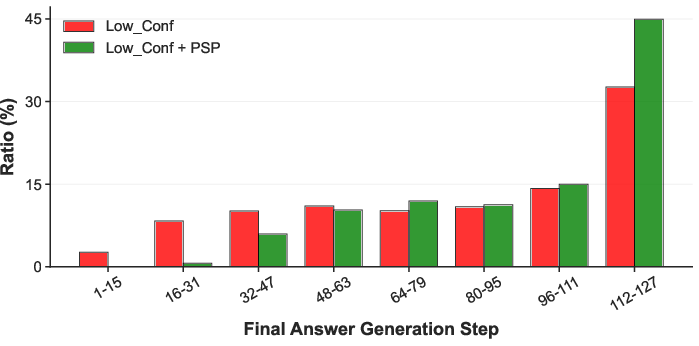
Figure 1: The empirical distribution of the answer generation timestep in LaViDa evidences frequent premature final answer production with L=64, T=32.
Furthermore, a comparative analysis using the visual prompt dependency measure (PDM) reveals that, in contrast to AR-based VLMs (e.g., LLaVA-1.5), dMLLMs exhibit markedly lower visual dependency in early timesteps (Figure 2). AR models leverage visual information intensely at the beginning, gradually shifting toward textual reasoning, whereas dMLLMs only incorporate visual cues at advanced stages, often after the answer is already fixed.
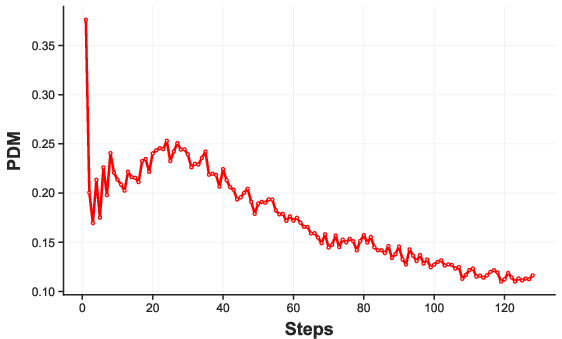
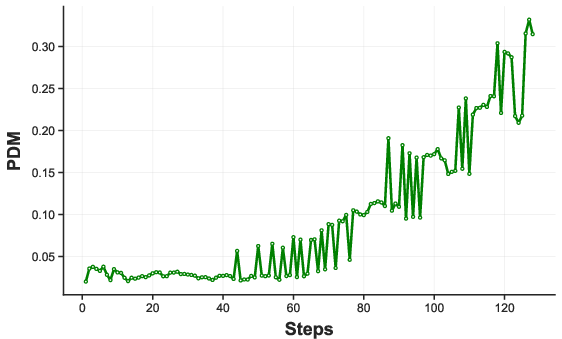
Figure 2: PDM comparison highlights strong early-stage visual grounding in LLaVA-1.5 versus weak, delayed visual reliance in LaViDa (diffusion-based).
This dissonance partially explains why direct transfer of AR-CoT methods to dMLLMs is empirically ineffective—a paradigm-specific approach is necessary.
Methodology: Position Step Penalty (PSP) and Visual Reasoning Guidance (VRG)
Position Step Penalty (PSP)
PSP aims to remedy premature answer generation by imposing a position-weighted penalty on the confidence scores for generating late-sequence (i.e., near-answer) tokens during early timesteps. The penalty strength γ is modulated by the relative diffusion progress, attenuating as the process advances.
This bias compels the model to populate intermediate reasoning tokens before committing to the answer, fostering more stepwise, progressive CoT reasoning. Empirically, PSP notably delays the earliest occurrence of answer tokens, as depicted in Figure 1 for both LaViDa and MMaDa.
Visual Reasoning Guidance (VRG)
VRG generalizes the classifier-free guidance concept from generative diffusion to the visual CoT context. It combines the logits produced with (conditional) and without (unconditional) visual input via a scale parameter svrg, amplifying the contribution from visual evidence at each timestep. The guided logits are then used to compute confidence in token sampling, effectively reweighting the model’s reliance toward multimodal input.
Applying VRG shifts PDM curves upward at every timestep, indicating stronger and earlier visual grounding during the coevolution of reasoning (Figure 3).
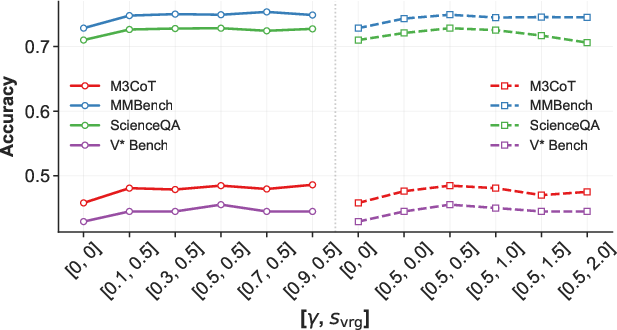
Figure 3: VRG ablation demonstrates enhanced PDM (visual grounding) across all reasoning steps for LaViDa with svrg=0.5.
Empirical Results
Extensive experiments are conducted on multiple multimodal reasoning and perception benchmarks, including M3CoT, ScienceQA, MMBench, and V* Bench, using both the LaViDa and MMaDa architectures.
Key empirical findings:
- PSP and VRG achieve up to 7.5% absolute accuracy improvement over strong baselines (including DDCoT and CCoT) and provide over 3× speedup relative to quadrupling diffusion steps to reach similar accuracy.
- These improvements persist across variations in generation length, diffusion steps, model scale, and remasking strategies.
Figure 4 visualizes the method’s application to dMLLMs inference, relating baseline and enhanced reasoning trajectories.


Figure 4: Overview of baseline versus PSP+VRG dMLLM inference, highlighting delayed answer tokenization and strengthened visual grounding.
Ablation studies confirm that both modules individually boost performance, and their combination yields the highest gains. Performance remains robust to moderate hyperparameter variation (Figure 3), and efficiency analysis demonstrates that inference cost increases minimally compared to substantial accuracy incentives.
Implications and Future Directions
The results substantiate that naive application of AR-style reasoning augmentation is inadequate for dMLLMs. The introduction of inference-time, training-free strategies such as PSP and VRG demonstrates a viable path to enhance visual reasoning completeness, sample efficiency, and modal alignment in parallel-generating models, circumventing the need for slow, sequential AR decoding.
Practically, these insights should inform future dMLLM development—remasking strategies and visual guidance must be tailored with respect to diffusion’s parallelism. Theoretically, the findings suggest that progressive CoT restoration and conditional guidance are orthogonal, composable mechanisms that could extend to other structured prediction and multimodal generative frameworks.
As diffusion-based LLMs attain greater deployment in complex, high-throughput reasoning systems, embedding such runtime guidance will be crucial for maintaining reasoning fidelity and interpretability, particularly in settings with limited resource budgets.
Conclusion
This work provides the first empirical and methodological analysis of visual-grounded reasoning processes in dMLLMs under CoT prompting. By rigorously characterizing early answer generation and delayed visual grounding, and remedying these with PSP and VRG, the study establishes both the necessity and effectiveness of paradigm-specific inference strategies. Consequently, dMLLMs equipped with these approaches not only achieve parity with AR models in reasoning tasks, but also preserve the inherent speed advantages of parallel diffusion decoding, charting a promising direction for further research in multimodal generative AI.