LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning
Abstract: LLMs demonstrate their reasoning ability through chain-of-thought (CoT) generation. However, LLM's autoregressive decoding may limit the ability to revisit and refine earlier tokens in a holistic manner, which can also lead to inefficient exploration for diverse solutions. In this paper, we propose LaDiR (Latent Diffusion Reasoner), a novel reasoning framework that unifies the expressiveness of continuous latent representation with the iterative refinement capabilities of latent diffusion models for an existing LLM. We first construct a structured latent reasoning space using a Variational Autoencoder (VAE) that encodes text reasoning steps into blocks of thought tokens, preserving semantic information and interpretability while offering compact but expressive representations. Subsequently, we utilize a latent diffusion model that learns to denoise a block of latent thought tokens with a blockwise bidirectional attention mask, enabling longer horizon and iterative refinement with adaptive test-time compute. This design allows efficient parallel generation of diverse reasoning trajectories, allowing the model to plan and revise the reasoning process holistically. We conduct evaluations on a suite of mathematical reasoning and planning benchmarks. Empirical results show that LaDiR consistently improves accuracy, diversity, and interpretability over existing autoregressive, diffusion-based, and latent reasoning methods, revealing a new paradigm for text reasoning with latent diffusion.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LaDiR (Latent Diffusion Reasoner), a new way to help LLMs “think” better. Instead of writing out a chain of thought one token at a time and never looking back (like writing with a permanent marker), LaDiR first creates short “thought bubbles” in a compact form, then repeatedly polishes them (like unblurring a photo step by step) before producing the final answer. This helps the model plan, revise, and explore different solution paths more efficiently and accurately.
What questions did the researchers ask?
They focused on three simple questions:
- Can we give LLMs a better way to revise and improve their reasoning, not just their final answer?
- Can we help them explore multiple different solution paths in parallel, instead of being stuck with one?
- Can we make the model’s reasoning both more accurate and more understandable?
How does their method work?
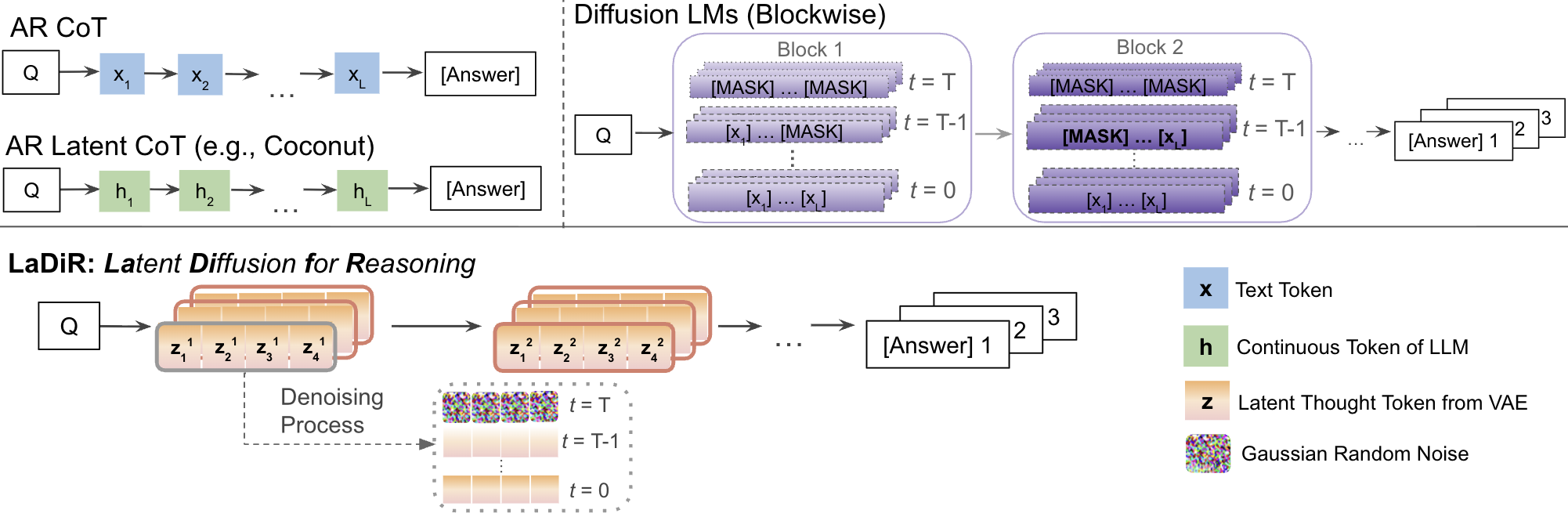
LaDiR separates thinking from answering. It builds a special “latent” space for thoughts and uses an image-like “diffusion” process to clean and refine those thoughts before producing the final answer.
The problem with current LLMs
Standard LLMs generate text one token at a time, left to right (called “autoregressive” decoding). That’s like writing a paragraph with no eraser: if you think of a better earlier sentence later on, you can’t go back. This makes self-correction hard and limits exploring different ideas.
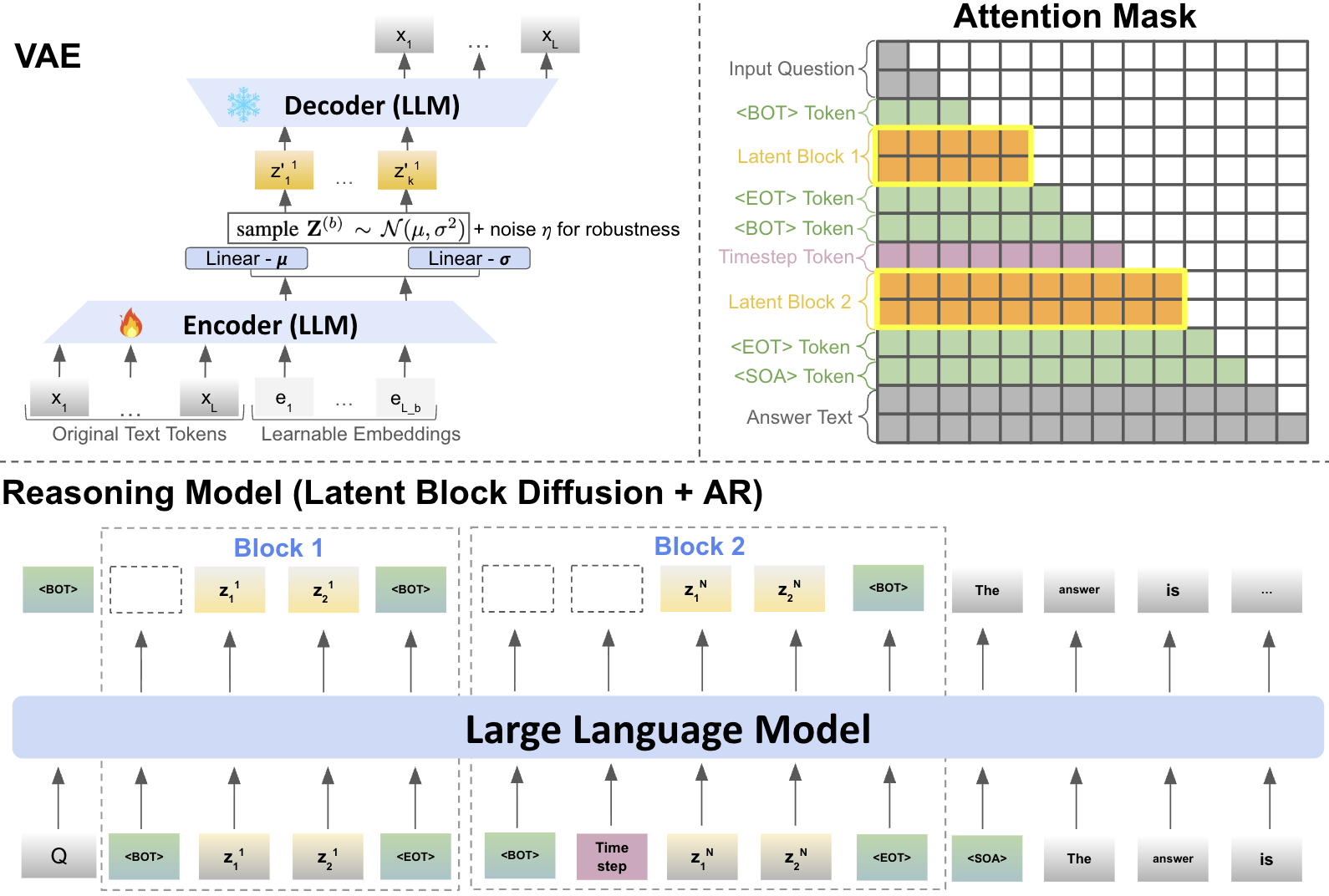
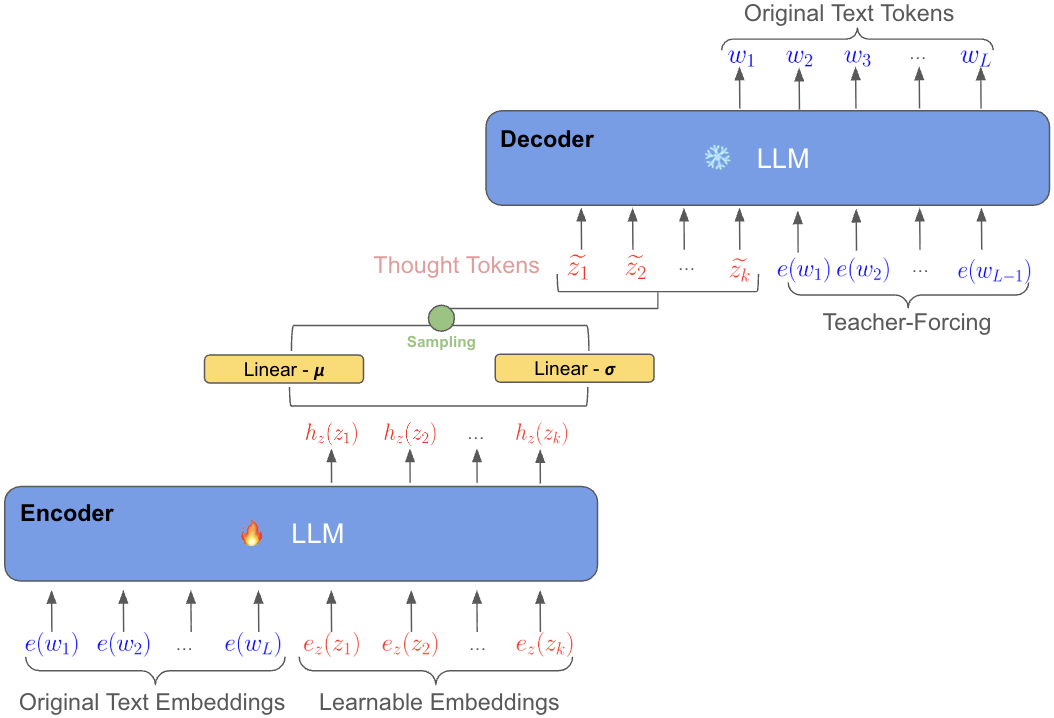
Latent “thought tokens” with a VAE
- Think of each reasoning step as a short sentence—a “thought block.”
- A Variational Autoencoder (VAE) acts like a smart zipper: it compresses each thought block into a small bundle of numbers (a “latent thought token”) and can also reconstruct the text back from that bundle.
- This creates a space where each thought is a compact, meaningful point. Because the VAE is trained to keep meaning intact, these points are interpretable and structured.
Analogy: It’s like turning each sentence into a “thought bubble code” that captures what it means, not just the exact words.
Polishing thoughts with diffusion
- Diffusion is like taking a very blurry picture and unblurring it step by step until it’s clear.
- LaDiR uses diffusion in the thought-bubble space: it starts from noise and iteratively denoises to produce a clean, sensible thought block. This allows the model to revise earlier parts of the thought block, not just append new text.
- Inside each thought block, the model can “look both ways” (bidirectional attention) to keep the thought consistent. Across blocks, it still moves forward step by step so the overall plan makes sense.
Putting it together: training and inference
- Stage 1 (teacher-forcing): The model learns using the “right” latent thoughts from the data, so it knows what good thought bubbles look like and how to polish them.
- Stage 2 (rollout): The model practices with its own generated (imperfect) thought bubbles and learns to correct itself, reducing mistakes that would otherwise accumulate at test time.
- At the end of reasoning, the model switches to normal text generation to write the final answer, guided by the polished thought bubbles.
Making answers diverse (finding many different good solutions)
To get varied ideas, LaDiR:
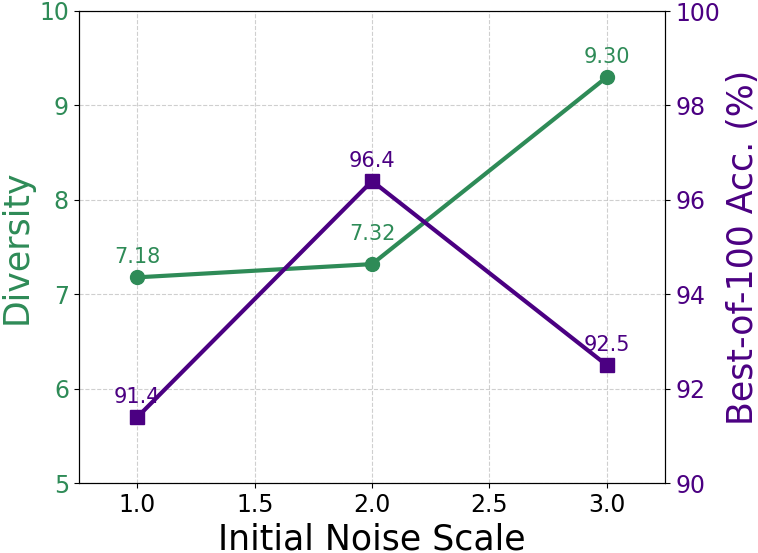
- Starts from slightly different random noise so each run explores a different path.
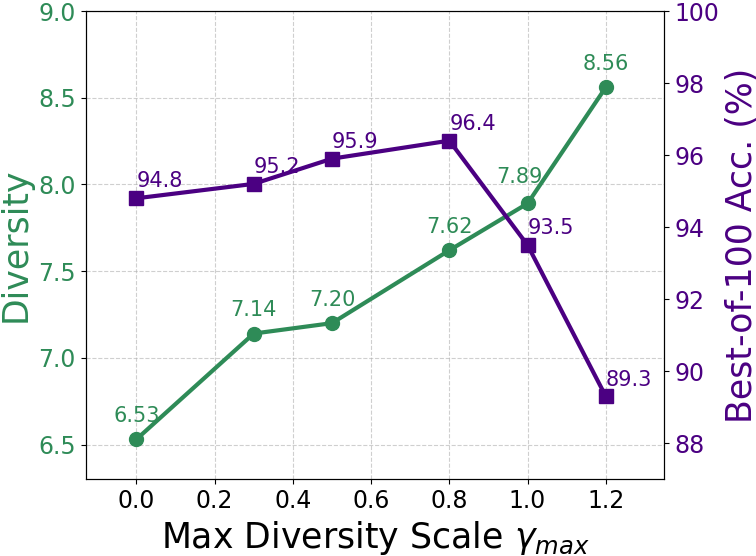
- Adds a gentle “repulsion” between solutions in the same batch so they don’t all collapse to the same idea (imagine teammates encouraged to try different strategies).
Adaptive “thinking time”
You can give LaDiR more or fewer refinement steps at test time:
- More steps = more polishing = better accuracy (useful for harder questions).
- Fewer steps = faster answers when the question is easy.
This means you can trade speed for quality when you need to.
What did they find?
Across math and planning tasks, LaDiR consistently improved both accuracy and the ability to explore diverse solutions.
Highlights:
- Math benchmarks (like GSM8K and MATH) and several out-of-domain math tests: LaDiR beat strong baselines, including normal chain-of-thought and other latent/diffusion models, on average across 7 datasets.
- Countdown planning game (a number puzzle): LaDiR had large gains (over 30% absolute improvement in some “pass@k” scores), found more unique valid solutions, and scaled well as you sampled more attempts.
- Iterative refinement in action: as the model denoised the latent thoughts step by step, its partial calculations got corrected over time—like fixing off-by-one mistakes and stabilizing the right equations.
- More denoising steps led to better accuracy, showing you can dial up test-time compute for tougher problems.
Why this matters: It suggests that “reasoning in meaning-space” (latent space) and refining iteratively can produce more faithful, consistent steps than writing raw text tokens one by one.
Why does this matter and what could it change?
- Better self-correction: By polishing thought blocks, LaDiR can rethink parts of its reasoning instead of just plowing forward. This is closer to how people revise drafts.
- More diverse thinking: Being able to explore several solution paths in parallel means it can uncover multiple correct approaches and avoid getting stuck on one idea.
- Flexible compute: You can give the model more “thinking time” only when needed, making it practical in real applications.
- More transparency: Because thoughts are organized into interpretable blocks, you can inspect the reasoning more easily than with opaque hidden states.
- Broader impact: This could improve math tutoring, scientific problem solving, planning tasks (like scheduling or strategy), and any setting where careful multi-step reasoning and revision are important.
In short, LaDiR shows a promising new direction: let LLMs reason in a compact, meaning-focused space and use diffusion to iteratively refine those thoughts before answering. This leads to more accurate, diverse, and understandable reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future work:
- Blockization strategy validity
- The one-sentence-per-block heuristic is untested against learned or task-adaptive segmentation; no ablations on block size
L_b, variable-length blocks, or learned boundary prediction. - Unclear whether splitting by sentences aligns with logical step boundaries in math/planning; need automatic segmentation tuned for reasoning granularity.
- The one-sentence-per-block heuristic is untested against learned or task-adaptive segmentation; no ablations on block size
- Latent space design and robustness
- No systematic study of VAE hyperparameters (e.g., , latent dimensionality, number of latent tokens per block) and their impact on faithfulness, interpretability, and downstream accuracy.
- Risk of posterior collapse or under-utilization of latent capacity is not analyzed; diagnostics (e.g., mutual information, KL usage, disentanglement metrics) are missing.
- The effect of the relatively large latent noise augmentation (
k=3) and token substitution (p=0.3) lacks sensitivity analyses and justification across tasks. - Interpretability is asserted but not quantitatively evaluated; no faithfulness audit linking decoded thought text to answer correctness (e.g., step-level verifiers, human evaluation, or causal interventions in latent space).
- Diffusion/flow-matching modeling choices
- The choice of flow matching over DDPM/score matching, and ODE over SDE sampling, lacks comparative evaluation (quality, stability, compute).
- Denoising schedule, solver choice, and step allocation policies are not optimized or learned; adaptive/two-stage samplers and progressive distillation remain unexplored.
- Convergence and stability under rollout training with gradients through denoising (memory/computation costs, training instabilities) are not characterized.
- Attention mask and long-range reasoning
- The hybrid attention mask (bidirectional within block, causal across blocks) is not ablated; it is unclear whether full causal/bidirectional or alternative structured masks yield better global consistency.
- Cross-block dependencies are limited by causal attention; how to capture long-horizon global constraints that span multiple blocks remains open.
- Stopping criterion and block count control
- Reliability of the
<SOA>stopping signal is not assessed (early/late termination, over- or under-generation of blocks, calibration); no fallback or verification mechanism if<SOA>is mispredicted. - Stage-2 rollout fixes the number of blocks to the ground truth, while inference predicts it; the impact of this mismatch on exposure bias and error accumulation is not measured.
- Reliability of the
- Diversity guidance and sampling
- The repulsion-based diversity guidance is heuristic; no comparison to alternative diversification methods (e.g., determinantal point processes, contrastive decoding, tempered/ensembled sampling, restarting seeds).
- Computational and scaling costs are quadratic in batch size; efficiency, stability, and potential to push latents off-manifold are not analyzed.
- The interaction between initial noise scale and guidance strength is only partially explored; principled scheduling or learning of these hyperparameters is missing.
- Faithfulness and verification
- Since answers are generated without decoding latent thoughts at inference, the consistency between latent reasoning and final answers is unverified; automated verifiers (e.g., equation checking, proof checkers) and counterfactual tests are missing.
- No mechanisms to enforce or check faithfulness (e.g., self-verification, tool use, or constrained decoding) are integrated.
- Compute, efficiency, and scalability
- Wall-clock latency, throughput, memory footprint, and hardware efficiency vs. strong AR baselines are unreported (both training and inference).
- The adaptive compute story (more denoising steps → higher accuracy) lacks policies to allocate steps per-instance and trade-offs vs. AR multi-sampling or test-time ensembling; early-exit confidence measures are not developed.
- Scalability to larger backbones (e.g., 70B), to MoE architectures, or to low-resource regimes (parameter-efficient finetuning) is untested.
- Evaluation coverage and fairness
- Generalization beyond math/planning (commonsense, multi-hop QA, scientific QA, code generation, theorem proving with formal verification) remains unevaluated.
- Baseline comparability is imperfect (different backbones/training for diffusion LMs, MGDM being task-specific); stronger and better-matched baselines (e.g., AR with best-of-N and verifier feedback) are needed.
- Statistical significance, variance across random seeds, and robustness to prompt perturbations are not reported.
- Potential train–test contamination risks from synthetic math corpora (e.g., DART-MATH overlap) are not audited.
- Countdown setup limitations
- The integrated pipeline is not evaluated end-to-end: answer generation is disabled, and a single fixed-size latent block is used; it is unclear how multi-block reasoning interacts with planning and with the
<SOA>mechanism. - Exact string match is used; equivalence under algebraic transformations or alternative correct derivations is not accounted for, possibly undercounting valid solutions.
- The integrated pipeline is not evaluated end-to-end: answer generation is disabled, and a single fixed-size latent block is used; it is unclear how multi-block reasoning interacts with planning and with the
- Learning signals and training procedure
- The effect of the special-token loss (for
<BOT>/<SOA>) is not ablated; its contribution to stable block count prediction is unclear. - The reliance on teacher forcing in Stage 1 may induce exposure bias; alternatives (scheduled sampling, DAgger-like aggregation) are not explored.
- How answer supervision shapes latent trajectories via backprop through denoising is not analyzed (e.g., whether it improves faithfulness vs. just answer accuracy).
- The effect of the special-token loss (for
- Safety, robustness, and adversarial aspects
- Robustness to adversarial or out-of-distribution prompts, noisy or ambiguous problems, and instruction changes is not tested.
- No analysis of calibration, uncertainty estimation, or confidence-aware decision-making for stopping criteria and step allocation.
- Theoretical understanding and diagnostics
- There is no formal characterization of how semantic denoising trajectories correspond to reasoning operations (e.g., algebraic transformations, subgoal refinement) or how fixed points relate to “correct” solutions.
- Lack of diagnostic probes: clustering latent steps, latent traversals, counterfactual edits, or causal interventions to test what concepts the latent tokens encode.
- Integration with external tools and RL
- Tool use, external verifiers, program execution, or symbolic solvers are not integrated; how latent diffusion interacts with verifier-in-the-loop or self-consistency remains untested.
- The method appears compatible with RL/post-training, but no experiments assess whether reinforcement learning on latent trajectories improves reasoning reliability or faithfulness.
- Multi-modal and interactive extensions
- Applicability to multi-modal reasoning (e.g., math diagrams, charts) and to multi-turn interactive settings (dialogue, planning under feedback) is entirely unexplored.
- Reproducibility and transparency
- Full training details (hyperparameters, compute budgets, seeds), code, and checkpoints are not provided; exact replication and fair comparison may be difficult without more comprehensive disclosure.
- Ceiling effects and remaining gaps to specialized models
- Despite strong gains, LaDiR underperforms a specialized discrete diffusion model (MGDM) on Pass@1 in CD-4; understanding gaps to specialized planners and how to close them remains an open problem.
Practical Applications
Overview
Based on the paper “LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning,” the applications below translate the framework’s findings and methods (VAE-based latent thought tokens, block-wise latent diffusion with flow matching, hybrid attention, diverse parallel trajectory exploration, and adaptive test-time compute) into practical, real-world use cases. Each item notes sector alignment, potential tools/workflows, and feasibility assumptions or dependencies.
Immediate Applications
These items are deployable now with modest engineering effort, using available LLMs, VAE tooling, and inference infrastructure.
- AI reasoning accelerator for existing LLM products (Software/AI)
- What: Integrate LaDiR as a post-training reasoning module that separates “reasoning” (latent blocks, diffusion refinement) from “answering” (AR decoding), providing higher accuracy and parallel diverse solutions.
- Tools/Products/Workflows:
- A microservice that exposes “reasoning modes”: number of denoising steps, diversity guidance scale, block size, and stop criteria (<SOA>).
- Batch-parallel trajectory generation with repulsion guidance; return top-k distinct candidates and a single final answer conditioned on the chosen trajectory.
- Assumptions/Dependencies: Requires an LLM backbone (e.g., Llama 3.1 8B), a trained VAE for thought blocks, and operational controls for adaptive compute. Needs evaluation harness and guardrails for safety/hallucination.
- Math tutoring and homework assistance with multiple solution paths (Education)
- What: Provide students with several valid solution trajectories for math problems, curated by diversity-guided latent diffusion; offer interpretable intermediate steps by decoding the latent blocks when needed.
- Tools/Products/Workflows:
- “Parallel Thought Explorer” UI: students select among diverse reasoning paths; the final answer is generated AR with links to the latent steps.
- Adaptive policy to spend more denoising steps on harder items (e.g., contest or college-level problems).
- Assumptions/Dependencies: Requires a CoT-rich math dataset (e.g., DART-MATH, GSM8K) and domain fine-tuning. Needs content moderation and error-checking (e.g., auto-verification for arithmetic).
- Planning assistants for combinatorial tasks (Software/Operations)
- What: Use single-block latent diffusion for short-horizon planning tasks (e.g., recipe sequencing, small logistics, or simplified arithmetic puzzles), leveraging LaDiR’s Countdown-style gains and diversity.
- Tools/Products/Workflows:
- “Latent Plan Explorer” that enumerates diverse plans in parallel; a validator checks operational constraints (e.g., time, resources) and selects the best plan.
- Assumptions/Dependencies: Works best where plans can be scored/verified; needs domain validators and constraint-checkers. Diversity hyperparameters must be tuned to balance accuracy vs exploration.
- Scenario generation for analytics and decision support (Enterprise/Policy/Finance)
- What: Rapidly produce multiple plausible narratives or strategies (e.g., marketing campaign options, policy scenario sketches, budget allocation outlines) and refine them iteratively at the latent level.
- Tools/Products/Workflows:
- “Diverse Scenario Generator” API that returns clustered solution paths; stakeholders compare and select a trajectory for AR expansion to full prose or action steps.
- Adaptive compute: assign more denoising steps to high-impact queries; fewer steps to routine ones.
- Assumptions/Dependencies: Requires domain priors (RAG or fine-tuned models). Human-in-the-loop selection is critical to mitigate hallucinations.
- Reasoning QA/test harnesses for academic research (Academia/ML)
- What: Evaluate reasoning diversity vs accuracy by sweeping denoising steps and repulsion scales; study interpretability by decoding latent blocks and aligning them to ground truth steps.
- Tools/Products/Workflows:
- Benchmark suite that logs trajectory refinement across time (e.g., t=1→0) and measures Pass@k, diversity, and correction dynamics.
- Teaching tools for algorithmic thinking: inspect how errors are corrected as diffusion progresses.
- Assumptions/Dependencies: Open datasets with intermediate solutions; training infrastructure for VAE + flow matching; reproducible inference settings.
- Cost-aware adaptive compute policies for LLM inference (Software/Platforms)
- What: Introduce a runtime policy that increases denoising steps for difficult queries to boost accuracy, while capping compute for easy ones.
- Tools/Products/Workflows:
- A scheduler that estimates query difficulty (e.g., problem features, early signals) and sets step budgets; instrumentation for latency and cost tracking.
- Assumptions/Dependencies: Requires telemetry and difficulty estimation; user SLAs must tolerate variable latency.
- Coverage testing for safety and correctness (Software Quality/Safety)
- What: Use diversity-guided trajectories to expose corner cases and inconsistent reasoning; auto-checkers detect contradictions or policy violations.
- Tools/Products/Workflows:
- “Reasoning Fuzzer” that varies noise and repulsion to maximize trajectory spread; rule-based or learned validators flag problematic paths.
- Assumptions/Dependencies: Validation rules and domain-specific checkers; careful tuning to avoid degrading accuracy excessively.
- Enhanced RAG + latent reasoning (Software/Knowledge Management)
- What: Combine retrieval conditioning with latent diffusion over thought blocks to maintain global coherence while grounding to retrieved facts.
- Tools/Products/Workflows:
- Pipeline: retrieve → encode context → latent reasoning (blocks, bidirectional attention inside block) → AR answering.
- Return multiple grounded lines of reasoning for analyst review.
- Assumptions/Dependencies: High-quality retrieval, domain fine-tuning, and reliability checks to prevent fluent but unsupported conclusions.
Long-Term Applications
These items require further research, scaling, domain data, validation, or regulatory compliance to be feasible.
- Clinical decision support with diverse differential diagnoses (Healthcare)
- What: Generate and refine multiple diagnostic hypotheses in latent space and present interpretable trajectories; allocate more denoising steps for complex cases.
- Tools/Products/Workflows:
- “Differential Explorer” that shows alternative thought paths; integrate guidelines and EHR context via RAG; clinician selects and edits a trajectory before AR summarization.
- Assumptions/Dependencies: Requires clinical-grade datasets, rigorous validation, bias auditing, regulatory approvals (e.g., FDA), and robust safety layers.
- Scientific experiment planning and hypothesis generation (Academia/Science)
- What: Explore diverse experimental designs or proofs in mathematics and science by parallel latent trajectories; iteratively refine to convergent, verifiable plans.
- Tools/Products/Workflows:
- “Latent Lab Planner” that proposes multiple experiment sequences with constraints; auto-checkers (symbolic tools, simulators) score feasibility.
- Assumptions/Dependencies: Domain-specific corpora, simulators, and formal verification tools; collaboration with experts to curate acceptable plans.
- Program synthesis and algorithm design with semantic planning (Software/DevTools)
- What: Employ block-wise latent reasoning to outline algorithmic strategies before code generation, increasing global planning consistency and diversity of solutions.
- Tools/Products/Workflows:
- “Algorithm Plan→Code” workflow: latent plan blocks (design, complexity trade-offs, edge cases) → AR code and tests; compare multiple algorithmic trajectories.
- Assumptions/Dependencies: Strong code datasets, unit test generation and execution, static analysis, and correctness verification; additional training beyond math/planning tasks.
- Robotics task and motion planning (Robotics)
- What: Use latent diffusion to propose diverse high-level plans that satisfy constraints; refine plans iteratively before committing to low-level control.
- Tools/Products/Workflows:
- “Plan Ensemble” that enumerates task decompositions; simulation-based validators prune unsafe or inefficient plans; selected plan passed to planners (e.g., TAMP).
- Assumptions/Dependencies: Accurate environment models/simulators, integration with existing planning stacks, safety checks, and real-time constraints.
- Portfolio allocation and risk scenario analysis (Finance)
- What: Generate parallel strategy narratives (e.g., rebalancing under various macro scenarios), refine them via latent diffusion, and present interpretable rationale.
- Tools/Products/Workflows:
- “Portfolio Scenario Engine” that produces multiple strategy paths and stress-test results; analysts select a trajectory and AR-expand into a formal memo.
- Assumptions/Dependencies: Domain data (market, risk models), compliance requirements, human oversight; heavy validation to prevent spurious reasoning.
- Policy design and multi-stakeholder scenario planning (Policy/Government)
- What: Create diverse policy options with clear trade-offs and procedural steps; iteratively refine in latent space to explore consequences and constraints.
- Tools/Products/Workflows:
- “Policy Playbook Generator”: multiple trajectories per objective; link to evidence via RAG; deliberation UI for expert review and synthesis.
- Assumptions/Dependencies: Trusted knowledge sources, transparency/audit features for interpretability, governance processes, and public accountability.
- Formal methods integration for high-assurance reasoning (Software Assurance)
- What: Combine latent reasoning with symbolic/verifiable proofs (e.g., in math or critical software) to ensure correctness while allowing diverse approach exploration.
- Tools/Products/Workflows:
- Hybrid pipeline: latent trajectory proposals → formal proof assistants or SMT solvers → AR explanations aligned to verified steps.
- Assumptions/Dependencies: Interfacing with formal tools, dataset curation of proof steps, performance optimizations to make the loop practical.
- Energy-aware compute scheduling for large-scale reasoning services (Energy/Cloud)
- What: Use adaptive test-time compute policies to balance accuracy, latency, and energy cost across fleets of reasoning requests.
- Tools/Products/Workflows:
- Orchestrator that assigns denoising steps based on SLA and predicted difficulty; batch-parallel diversity exploration with dynamic scaling.
- Assumptions/Dependencies: Cloud orchestration, telemetry, cost models; A/B testing for accuracy vs energy trade-offs.
Cross-cutting assumptions and dependencies
- Requires an LLM backbone and a trained VAE to construct interpretable latent thought tokens; block sizes and attention masks must be tuned for task length and domain.
- Performance depends on high-quality CoT training data and, for domain deployment, careful fine-tuning and validation.
- Adaptive compute improves accuracy but increases latency/cost; a runtime policy is needed to balance SLAs and quality.
- Diversity guidance (noise scale, repulsion strength) must be calibrated to avoid degrading accuracy; validators or scoring functions are useful to select among trajectories.
- Interpretability relies on decoding latent blocks; reconstruction fidelity is bounded by the VAE and may need domain-specific optimization.
- Safety, robustness, and compliance are essential in regulated sectors (healthcare, finance, government), requiring human-in-the-loop workflows and auditing.
Glossary
- Adaptive test-time compute: The ability to adjust the amount of computation during inference (e.g., number of denoising steps) to improve accuracy. "enabling longer horizon and iterative refinement with adaptive test-time compute."
- Answer Token Loss: A training objective that maximizes the likelihood of the correct answer tokens conditioned on the question and latent reasoning blocks. "Answer Token Loss."
- Autoregressive (AR) paradigm: A generation approach that produces tokens sequentially, conditioning each token on previously generated tokens. "the autoregressive (AR) paradigm"
- Autoregressive decoding: The token-by-token generation process used by many LLMs, which can limit revisiting earlier tokens. "LLM's autoregressive decoding may limit the ability to revisit and refine earlier tokens"
- Bandwidth parameter: A scale computed from pairwise distances among latents to control the strength of diversity repulsion during inference. "First, we compute a bandwidth parameter as the median pairwise distance between the latent tokens in a batch at the current step"
- Begin-of-thought (BOT): A special token that marks the beginning of a latent reasoning block. "predicts whether the next block begins with a <SOA> (start-of-answer) or <BOT> (begin-of-thought) token"
- β-VAE: A variant of the Variational Autoencoder that balances reconstruction and regularization via a scaling factor β, promoting disentangled latent spaces. "We adopt the -VAE"
- Block diffusion: A scheme that applies diffusion at the level of contiguous token blocks, interpolating between autoregressive and diffusion modeling for sequences. "Block Diffusion"
- Blockization: The process of splitting chain-of-thought text into sentence-level blocks to localize reasoning steps in latent space. "Blockization."
- Blockwise bidirectional attention mask: An attention design allowing bidirectional attention within each block and causal attention across blocks. "with a blockwise bidirectional attention mask"
- Causal attention: An attention constraint where tokens can only attend to previous positions, ensuring autoregressive dependence across blocks. "with bidirectional attention inside a block and causal attention across blocks."
- Chain-of-thought (CoT): Explicit intermediate reasoning steps generated by LLMs to improve reasoning performance. "LLMs demonstrate their reasoning ability through chain-of-thought (CoT) generation."
- Classifier-free guidance: A technique that blends base model predictions with a guidance signal to steer generation, here used analogously for diversity. "in a form analogous to classifier-free guidance"
- Countdown: A combinatorial arithmetic planning task used to evaluate reasoning and planning capabilities. "Puzzle Planning – Countdown"
- Cross-entropy loss: A standard supervised loss used to train the model to predict correct answer tokens. "The training objective for those answer tokens is the cross-entropy loss:"
- Curriculum learning: A training strategy that gradually increases task difficulty to stabilize learning of latent reasoning. "as in Coconut w/o curriculum learning"
- Denoising steps: Iterative steps in diffusion models that progressively transform noise into structured latent representations. "additional denoising steps can be flexibly allocated to improve performance."
- Diffusion LLMs: LLMs that generate text via iterative denoising rather than purely autoregressive decoding. "Diffusion LLMs - LLaDA 8B"
- Diversity gradient guidance: An inference-time method that adds a repulsion term to latents to encourage diverse reasoning trajectories. "Diversity gradient guidance."
- End-of-thought (EOT): A special token that marks the end of a latent reasoning block. "we introduce a special binary classification head ... whenever an <EOT> (end-of-thought) token is generated."
- Error accumulation: The compounding of mistakes when a model conditions on its own generated latents rather than oracle latents. "suffering from error accumulation issue."
- Flow matching: A training framework that learns a velocity field to match an interpolating flow between data and noise, enabling diffusion without score estimation. "Diffusion can also be viewed as a continuous-time generative flow trained via flow matching"
- FlowGRPO: A training approach for flow/diffusion models that reduces denoising steps during rollout to mitigate error accumulation. "following FlowGRPO"
- Gaussian noise: Random noise sampled from a Gaussian distribution used as the starting point for diffusion generation. "the process begins from Gaussian noise ."
- Hybrid attention mask: An attention pattern that mixes bidirectional attention within blocks and causal attention across blocks. "we adopt a hybrid attention mask "
- Implicit CoT (iCoT): A latent reasoning baseline that gradually removes explicit CoT tokens via curriculum learning. "Implicit CoT (iCoT)"
- Iterative refinement: The capability of diffusion-based reasoning to progressively improve latent reasoning across steps. "enable iterative refinement"
- Latent collapse: A failure mode where latent representations degenerate, losing informative structure. "To avoid latent collapse as in Coconut w/o curriculum learning"
- Latent diffusion model: A diffusion model operating in the latent space (typically of a VAE), enabling semantic-level generation and refinement. "latent diffusion models"
- Latent Gaussian noise: An augmentation that injects isotropic Gaussian perturbations into latent tokens during VAE training for robustness. "Latent Gaussian noise."
- Latent reasoning space: A continuous representation space for reasoning steps, constructed via a VAE. "constructs a latent reasoning space"
- Latent thought tokens: Continuous latent tokens encoding high-level reasoning steps, denoised by the diffusion model. "latent thought tokens"
- Latent tokens: Continuous variables sampled by the VAE that compactly encode text or reasoning content. "a latent token is sampled as "
- Ordinary differential equation (ODE): The continuous-time formulation used to define the generative flow in diffusion/flow matching. "This path is controlled by an ordinary differential equation (ODE)"
- ODE solver: A numerical integrator used to follow the learned velocity field backward in time during diffusion inference. "using an ODE solver as follows:"
- Pass@k: An evaluation metric measuring whether at least one valid solution is found among k samples. "Results for pass@k performance on Countdown-4"
- Repulsion force field: A diversity-promoting vector field applied to latents during inference to push samples apart. "The repulsion force field for a latent token is then defined as"
- Rollout training: A training stage where the model generates its own latents (with fewer steps) and learns to correct them, reducing train–test mismatch. "Stage~2 adopts an rollout training."
- Special binary classification head: An auxiliary head that predicts whether to start a new thought block or transition to the answer. "we introduce a special binary classification head"
- Start-of-answer (SOA): A special token indicating the model should stop reasoning in latent space and generate the final answer. "we introduce a special binary classification head ... <SOA> (start-of-answer)"
- Supervised finetuning (SFT): Post-training on labeled data to adapt a base model to specific tasks or reasoning styles. "AR CoT supervised finetuning (SFT)"
- Teacher-forcing: A training regime that conditions the model on oracle latents or tokens rather than its own predictions to stabilize learning. "the model is trained under a teacher-forcing regime"
- Variational Autoencoder (VAE): A generative model that learns latent representations by balancing reconstruction quality and prior regularization. "A Variational Autoencoder (VAE) learns a latent representation of data"
- Velocity field: The target vector field defining the time derivative of the interpolating path between data and noise in flow matching. "where is the target velocity field."
- VQ-VAE: A vector-quantized autoencoder that maps inputs to discrete latent codes, used in discrete latent baselines. "via VQ-VAE for reasoning."
Collections
Sign up for free to add this paper to one or more collections.