- The paper presents a unified framework that merges autoregressive planning and diffusion-based simulation to enhance spatial grounding and logical reasoning.
- It employs a closed-loop Simulate-Critic-Refine cycle where critic feedback iteratively corrects errors to improve visual and textual inference.
- Empirical results demonstrate that the collaborative approach mitigates spatial hallucinations and reduces computational token usage in geometric reasoning tasks.
Reasoning with Autoregressive-Diffusion Collaborative Thoughts
Introduction and Problem Motivation
This work introduces Collaborative Thoughts, a unified framework designed to integrate autoregressive (AR) and diffusion-based generative models within a closed-loop system for improved multimodal reasoning and generation. While AR models such as LLMs demonstrate strong sequential planning and constraint satisfaction, they exhibit clear limitations in tasks demanding explicit spatial grounding or physical semantics. Conversely, diffusion models enable rich spatial structure generation but lack stepwise logical control, and their outputs are prone to compounding errors without iterative correction. Collaborative Thoughts addresses the gap by enabling interaction across these two paradigms, with a critic module acting as an alignment mechanism that evaluates and refines multimodal intermediate states, resulting in higher fidelity reasoning and generation, especially on tasks with deeply intertwined linguistic and spatial requirements.
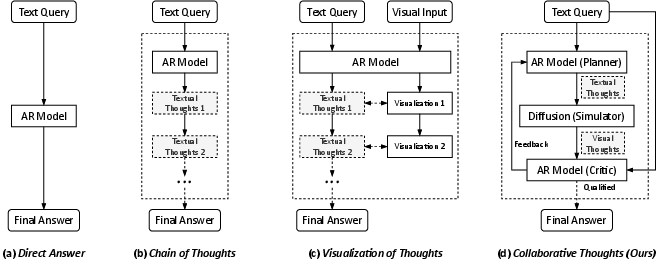
Figure 1: Traditional chain-of-thought (CoT) relies exclusively on text, limiting physical and spatial reasoning; collaborative thought interleaves multimodal traces for iterative correction and alignment.
Methodology: Closed-Loop Multimodal Reasoning Architecture
The Collaborative Thoughts framework operationalizes multimodal reasoning as a sequential decision process comprised of three system modules: Planner (AR LLM), Simulator (diffusion model), and Critic (autoregressive VLM). The reasoning process is formulated as an iterative Simulate-Critic-Refine cycle. At each step, the Planner decomposes the query into visualizable constraints, which are then instantiated as intermediate "visual thoughts" by the Simulator. The Critic evaluates physical and logical coherence, providing actionable feedback for the next cycle.
The AR model is responsible for hierarchical task decomposition, prompt engineering, and reactive planning based on critic feedback. The diffusion model instantiates prompts into high-dimensional visual traces under optional structural guidance (e.g., ControlNet constraints) to reduce geometric instability. Feedback from the Critic combines verification scoring and natural language localization of errors, ensuring only visually-validated traces propagate through the reasoning trajectory.
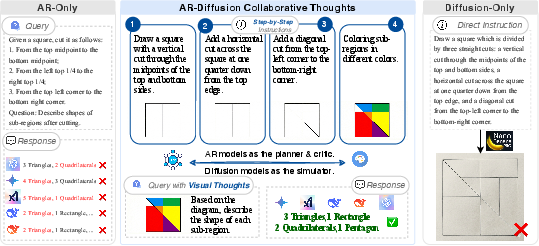
Figure 2: Autoregressive models plan, diffusion models instantiate, and critic feedback ensures constraint adherence—the collaborative loop systematically corrects both text and visual errors at each step.
Empirical Demonstrations: Spatial Reasoning and Geometric Inference
The paper systematically compares the Collaborative Thoughts framework with AR-only and diffusion-only reasoning on geometric manipulation and inference tasks. Results indicate that text-based AR reasoning alone leads to spatial hallucinations (such as incorrect partitioning in composite shape tasks), whereas single-step diffusion generation fails to enforce strict topological constraints, resulting in geometric distortions. The collaborative framework sequentially constructs intermediate blueprints, leveraging visual feedback to prevent error propagation and ensuring the final configuration accurately reflects both the problem constraints and visual semantics.
A notable demonstration is the efficiency gain in Euclidean geometry problem solving: whereas traditional CoT approaches require thousands of tokens to resolve geometric relationships, the collaborative reasoning loop generates visual intermediate snapshots that ground inference, reducing computational cost essentially to O(1) in token usage while maintaining perfect accuracy on the tested queries.
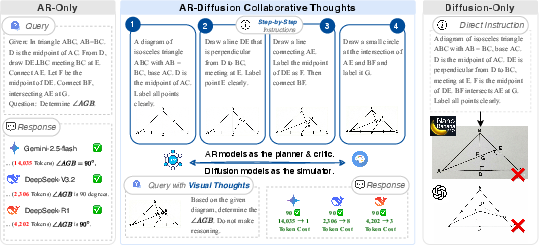
Figure 3: The AR-diffusion collaborative approach reliably bridges the gap between text and vision, eliminating hallucinations and reducing inference cost compared to standalone paradigms.
Discussion: Theoretical and Practical Implications
Collaborative Thoughts substantiates the computational merit of a dual coding model, operationalizing the complementary strengths of symbolic reasoning and statistical spatial simulation. By integrating a diffusion-based world model as a semantic "soft simulator"—rather than a rigidly parameterized physics engine—the framework enables generalizable, open-domain spatial reasoning where explicit simulation is computationally infeasible. The iterative critic-driven refinement supports robustness against error propagation in both modalities.
Major bottlenecks persist. The iterative closed-loop nature incurs significant compute overhead due to repeated diffusion sampling. Furthermore, the system's upper bound on reasoning performance is constrained by the quality of the diffusion (Simulator) and vision-language (Critic) components. Misalignment or poor critic performance can bottleneck the whole framework—this motivates further research on stronger vision-language feedback mechanisms and sample-efficient diffusion control.
Conclusion
Collaborative Thoughts advances a unified architecture for multimodal reasoning by iteratively coupling AR-driven planning and diffusion-based simulation with critic supervision. The approach mitigates the classical failure cases of text-based semantic deduction in spatial domains and addresses the lack of controllability in pure diffusion generation. The results support the hypothesis that high-level cognition in AI emerges from interaction between distinct generative modules, each specialized for different representational domains, continuously critiquing and refining hypotheses.
Future research directions include reducing computation via more efficient visual generation, extending simulation capacity to 3D and temporal (video) domains, and deploying the architecture in embodied agent settings for real-time spatial and physical reasoning. This offers a potential pathway toward AI systems that reason and act via continual multimodal hypothesis testing prior to physical instantiation.

