- The paper introduces FR3E, which identifies high-uncertainty decision points in LLM reasoning trajectories to segment them into semantically grounded states.
- It employs targeted rollouts from these uncertain states alongside adaptive policy updates using methods like asymmetric clipping and advantage modulation.
- Experimental results on GSM8K, Math500, and AIME24 demonstrate that FR3E produces longer, more coherent reasoning chains and higher task accuracy compared to GRPO++.
FR3E: Enhancing Exploration in RL for LLMs through Uncertainty-Driven Techniques
This paper introduces First Return, Entropy-Eliciting Explore (FR3E), a novel framework designed to improve the exploration phase in Reinforcement Learning from Verifiable Rewards (RLVR) for LLMs (2507.07017). The core idea behind FR3E is to identify high-uncertainty decision points within reasoning trajectories and then conduct targeted rollouts to create semantically grounded intermediate feedback. This approach aims to provide more directed guidance to the LLM without depending on dense supervision.
Methodology: First Return, Entropy-Eliciting Explore
The FR3E framework operates in two distinct stages, inspired by the "First Return, Then Explore" principle [Ecoffet_2021]:
- First Return: This stage focuses on generating a base trajectory from a given query and identifying positions of high uncertainty. Token-wise entropy is computed to pinpoint these critical decision points, which are then used to segment the trajectory into intermediate semantic states (Sj).
- Entropy-Eliciting Explore: In this stage, multiple rollouts are launched from each identified state (Sj). The rewards for these rollouts are evaluated, and empirical values V(Sj) are computed to guide adaptive policy updates.

Figure 1: A depiction of the FR3E framework, including base trajectory generation, entropy computation, intermediate semantic state construction, and adaptive policy updates.
The entropy Hk at position k is calculated as:
Hk=−v∈V∑πθ(v∣q,t<k)logπθ(v∣q,t<k)
where πθ(v∣q,t<k) represents the softmax-normalized probability distribution over the vocabulary V at step k, conditioned on the query q and previously generated tokens t<k.
Frequent tokens with high average entropy are used as segmentation points (Figure 2). This figure is adapted from prior work (Wang et al., 2 Jun 2025), which analyzes token-level uncertainty across model trajectories. These entropy-sensitive positions serve as natural breakpoints for segmenting the trajectory into semantically meaningful reasoning blocks.
Implementation Details
Several key implementation details contribute to the effectiveness and stability of FR3E:
- Rejection Sampling: To avoid degenerate cases where a prompt consistently yields trajectories with identical rewards, rejection sampling is employed (Yu et al., 18 Mar 2025, Zhang et al., 19 Apr 2025). Prompts that result in all correct or all incorrect rollouts are rejected from the current batch.
- Clip-Higher: Standard PPO-based reinforcement learning uses symmetric clipping bounds. To encourage exploration, the Clip-Higher mechanism is adopted (Yue et al., 7 Apr 2025), which replaces symmetric clipping with asymmetric bounds that permit more substantial increases in the probability of underexplored reasoning paths.
- Adaptive Advantage Modulation: An advantage modulation factor, αj, is introduced to scale the learning signal based on the marginal improvement in value from the previous state Sj−1 to the current state Sj:
αj=exp(V(Sj)−V(Sj−1))1
This factor dynamically modulates the advantage function, preventing premature convergence and preserving exploration diversity.
Experimental Results
The paper evaluates FR3E on mathematical reasoning benchmarks, including GSM8K, Math500, and AIME24. The training data is constructed from DeepScaler and SimpleRL datasets. The results demonstrate that FR3E promotes more stable training, generates longer and more coherent responses, and increases the proportion of fully correct trajectories.
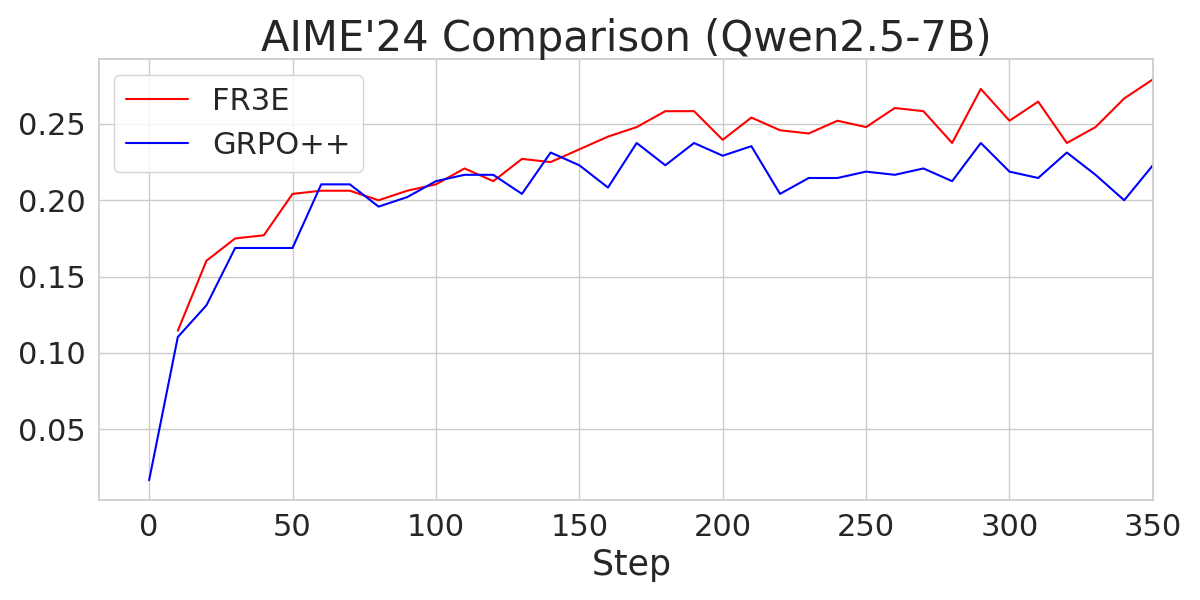
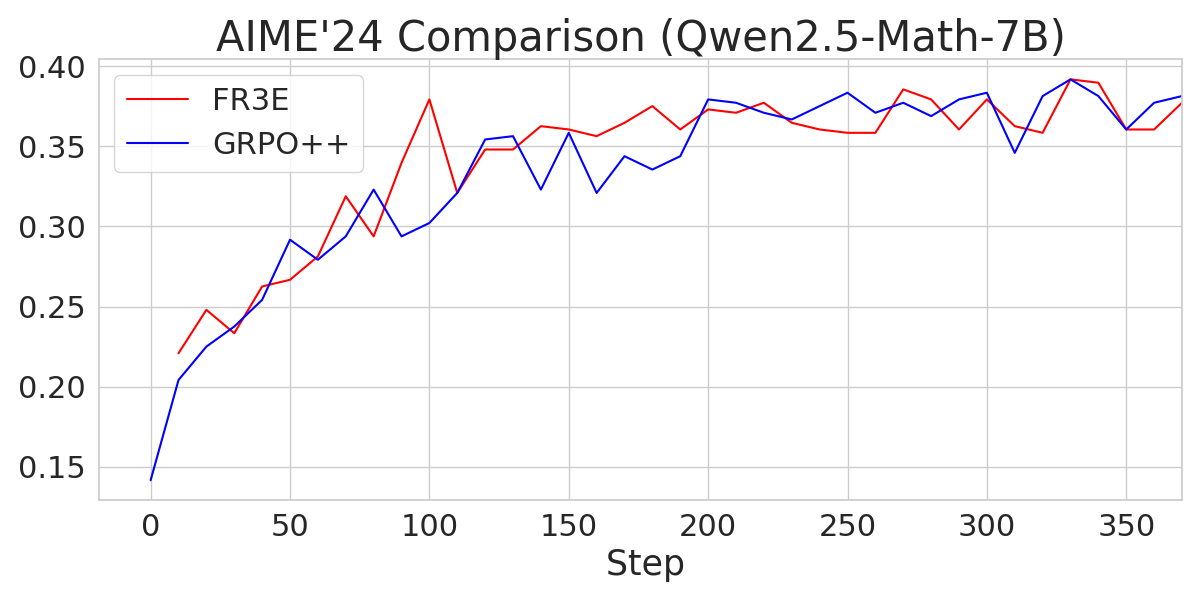
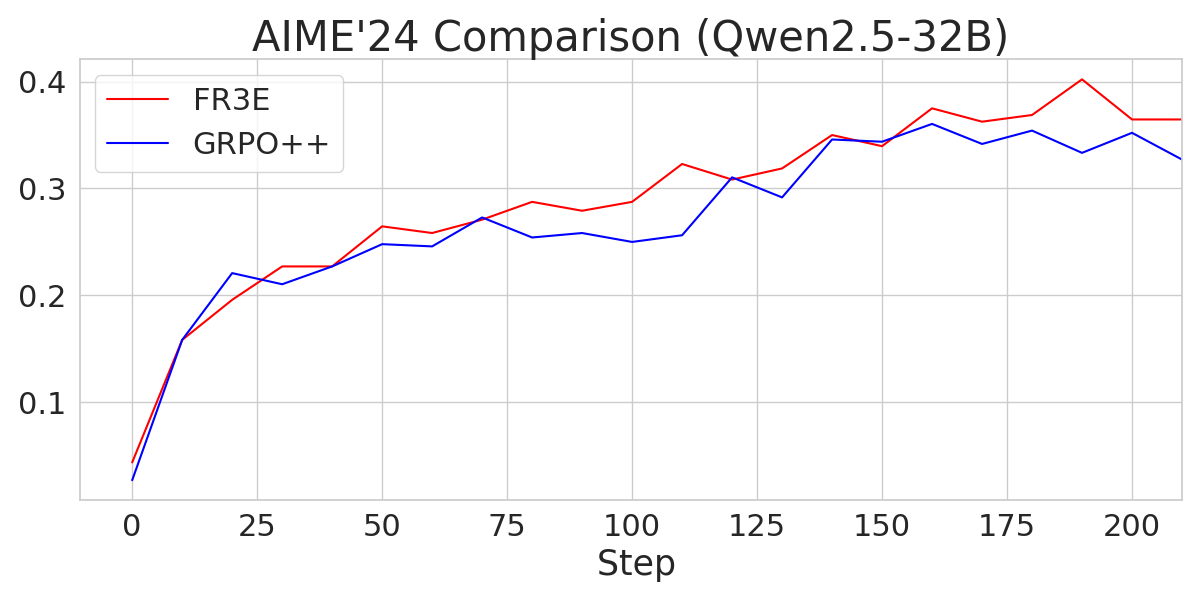
Figure 3: A comparison of entropy loss across different Qwen2.5 models trained with FR3E and GRPO++, demonstrating FR3E's ability to maintain higher entropy levels.
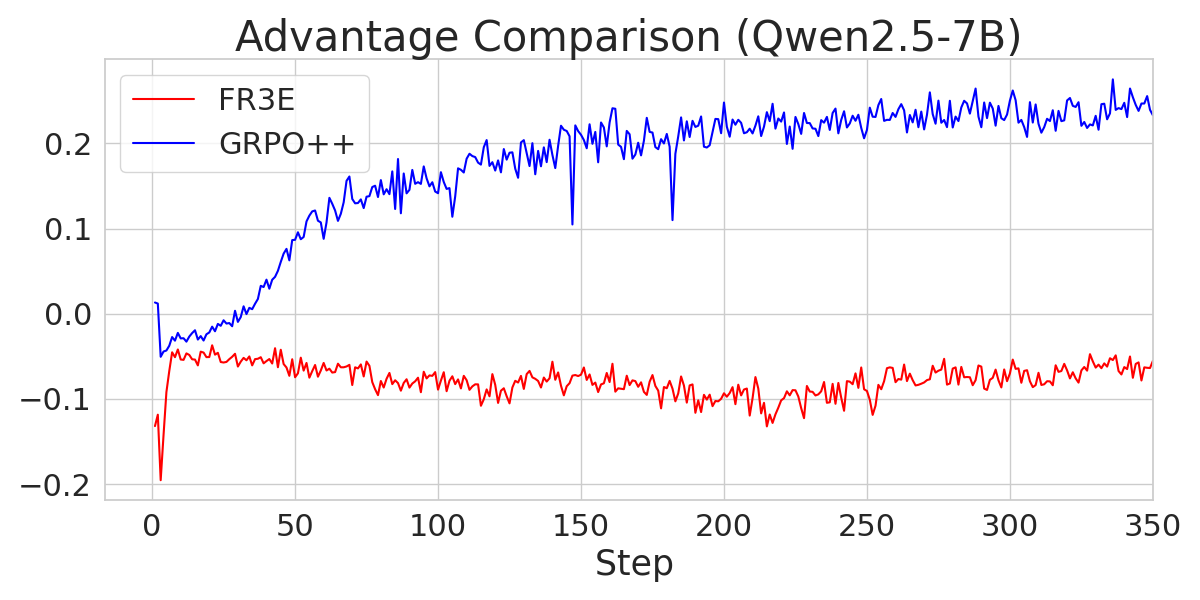
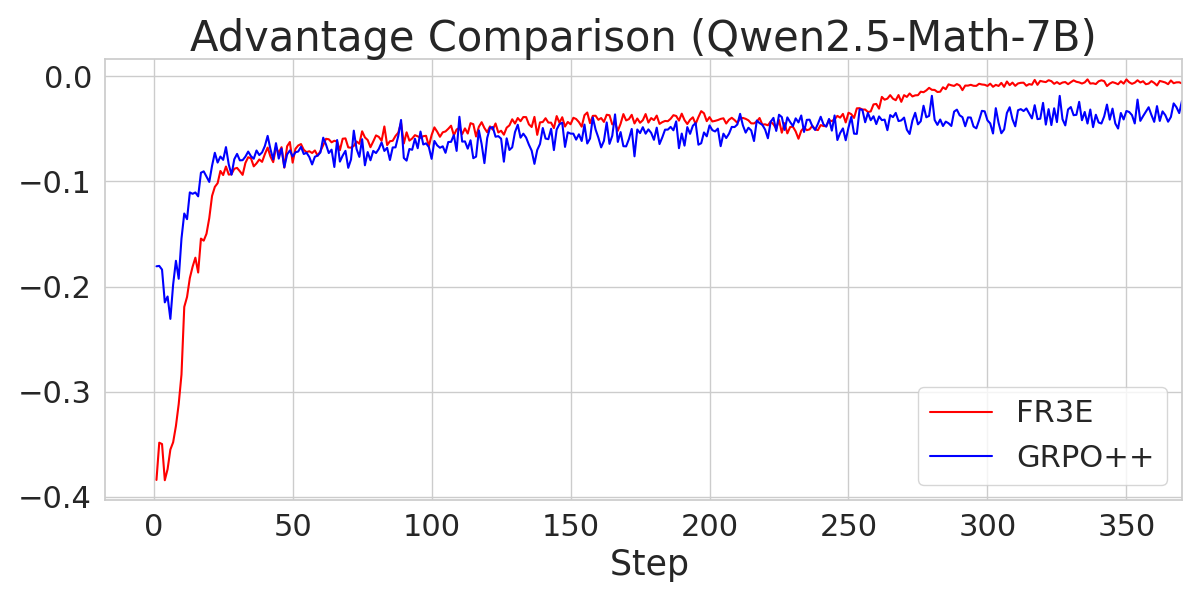

Figure 4: A comparison of AIME24 performance across different Qwen2.5 models trained with FR3E and GRPO++, showcasing FR3E's superior performance.
The experiments compare FR3E against GRPO++, a variant of Group Relative Policy Optimization integrated with rejection sampling and clip-higher mechanisms. The results indicate that FR3E achieves higher performance than GRPO++ under the same training steps. Notably, the GRPO++ baseline on Qwen2.5-32B performs at a level consistent with the M1-reproduced DAPO results (MiniMax et al., 16 Jun 2025), suggesting normal baseline behavior.
Analysis of Training Dynamics
The paper provides an analysis of the training dynamics of Qwen2.5-Math-7B, noting that it exhibits distinct patterns compared to other models. Qwen2.5-Math-7B reaches the maximum sequence length limit early and shows greater variability in entropy loss. However, FR3E appears to support the development of extended reasoning sequences for this model better than GRPO++.
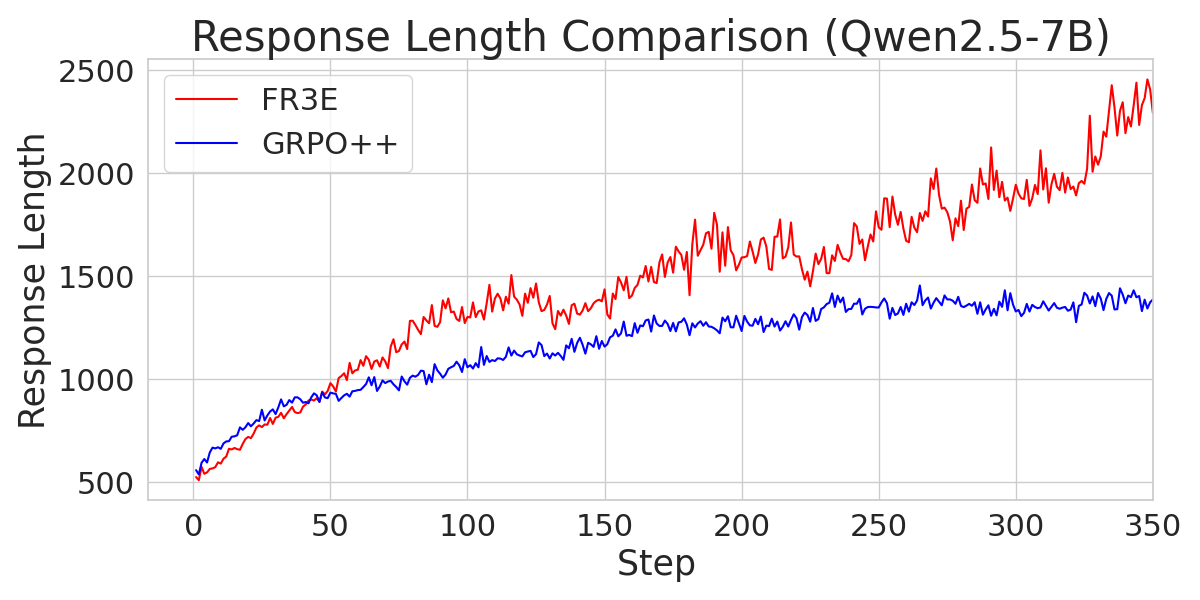
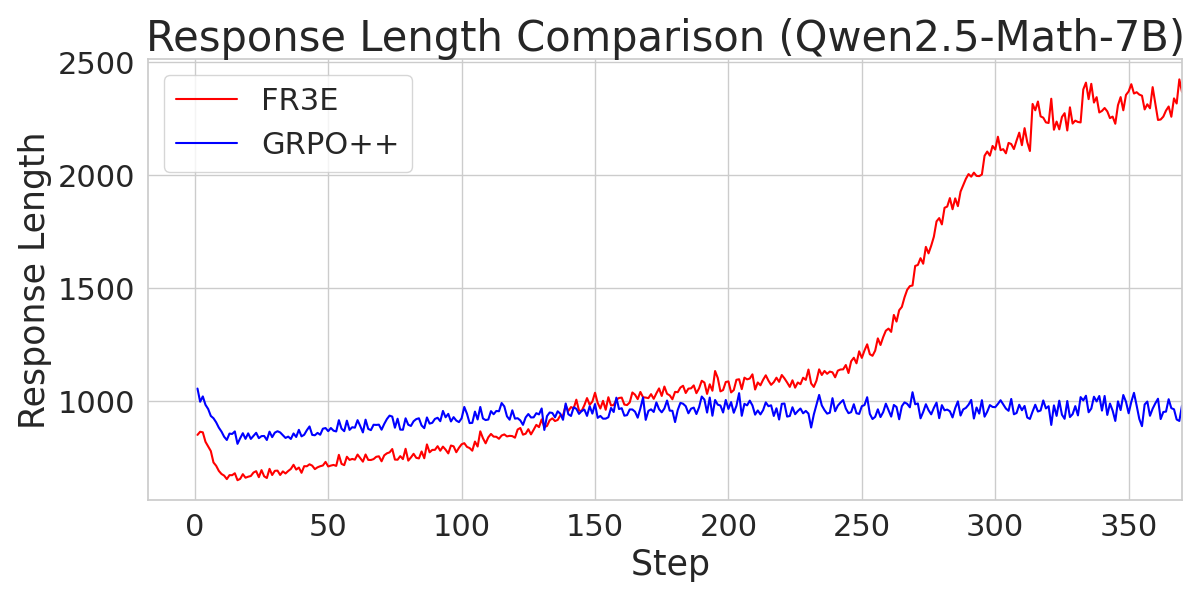
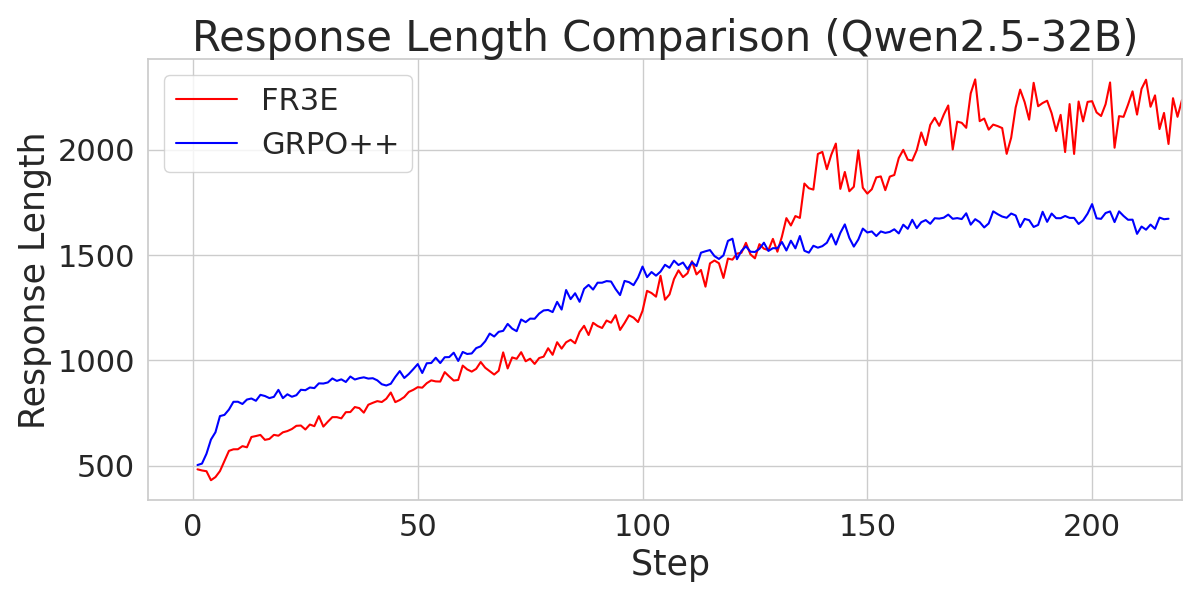
Figure 5: A comparison of response length across different Qwen2.5 models trained with FR3E and GRPO++, indicating FR3E's ability to promote longer reasoning chains.
The analysis also explores the sources of gains in FR3E, highlighting that higher entropy enables healthier exploration. FR3E significantly increases the number of "All-Right" trajectories (where all rollouts are correct) while suppressing "All-Wrong" trajectories.
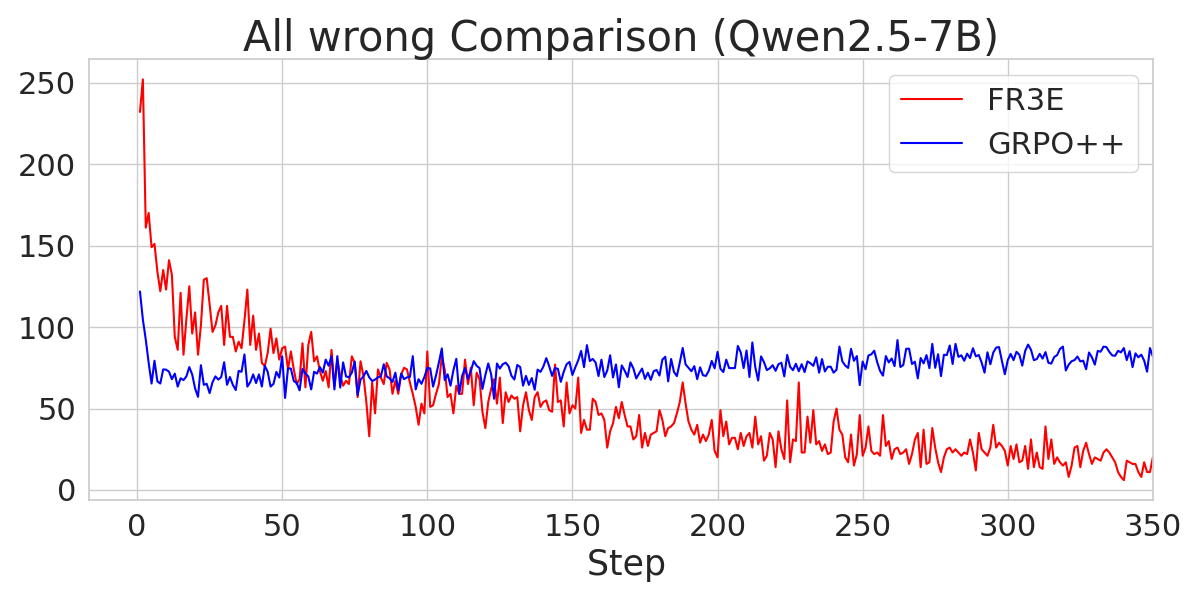
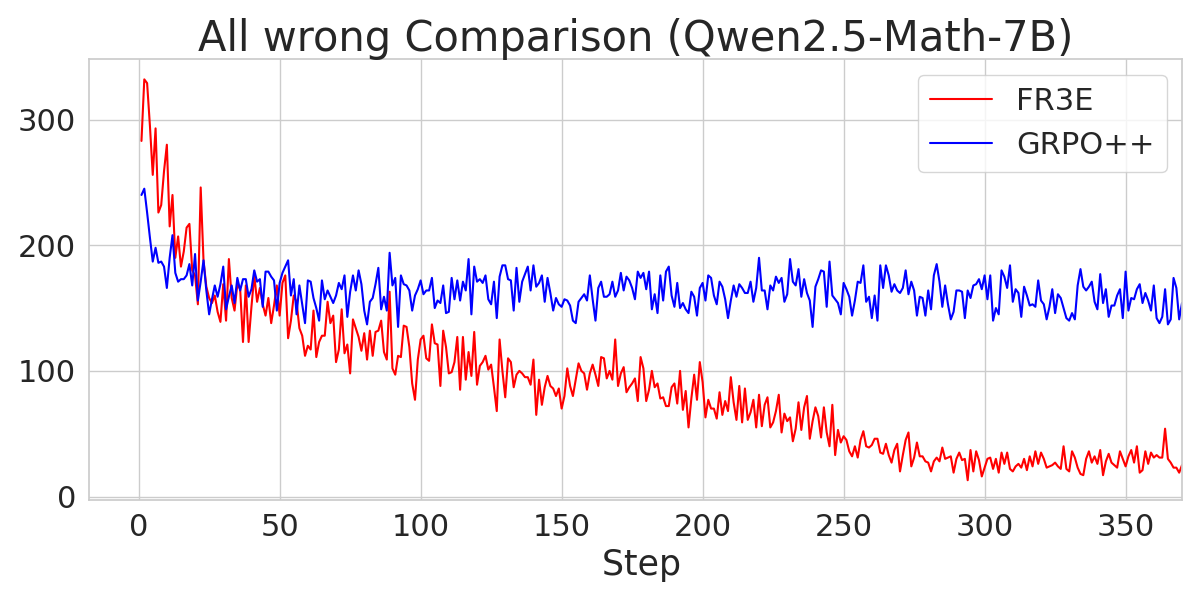
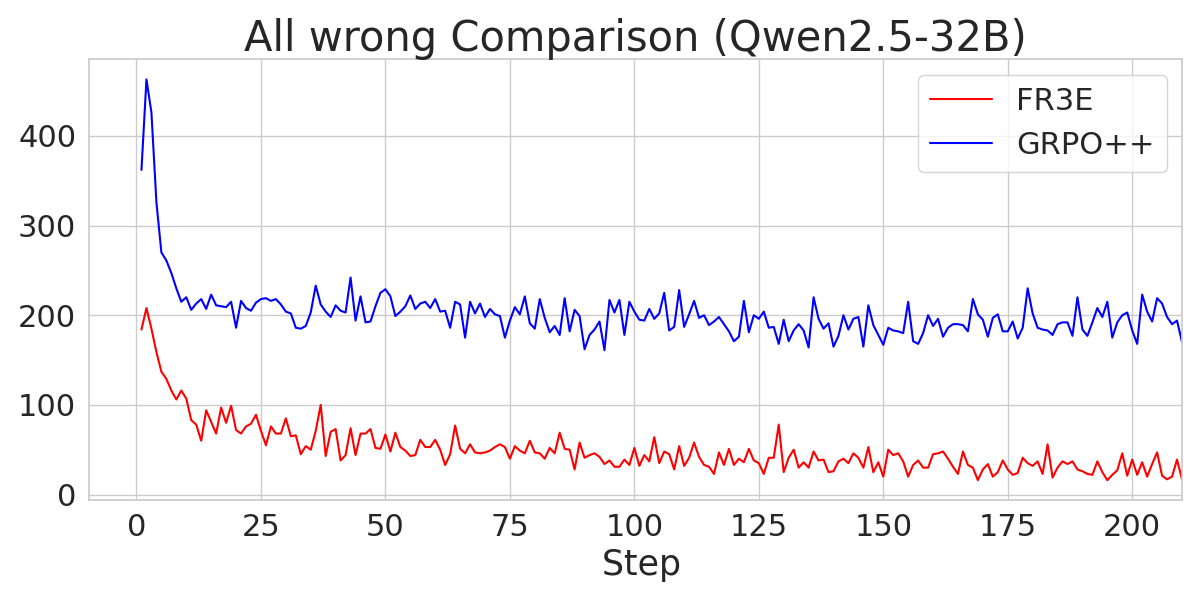
Figure 6: A comparison of the number of "All-Wrong" trajectories during the Entropy-Eliciting Explore phase for different Qwen2.5 models trained with FR3E and GRPO++.
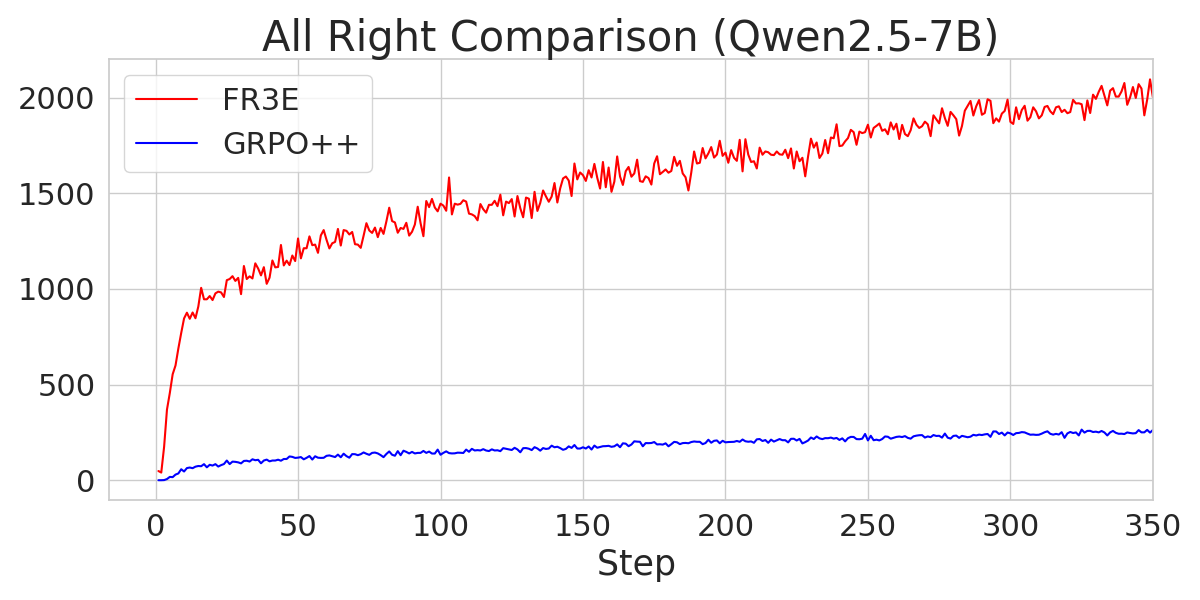
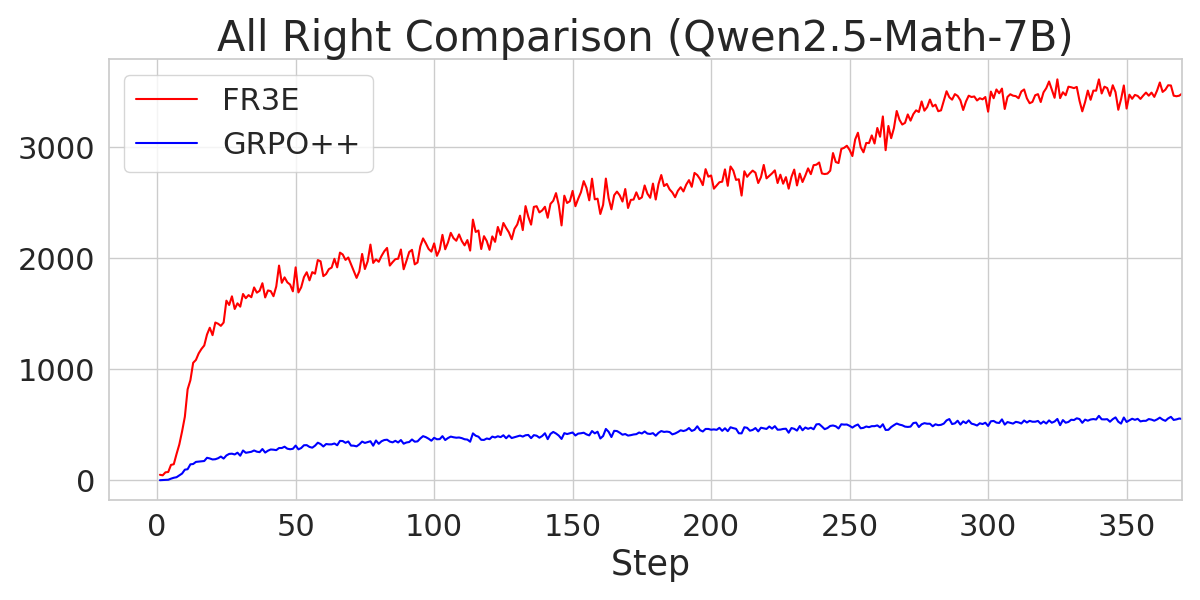
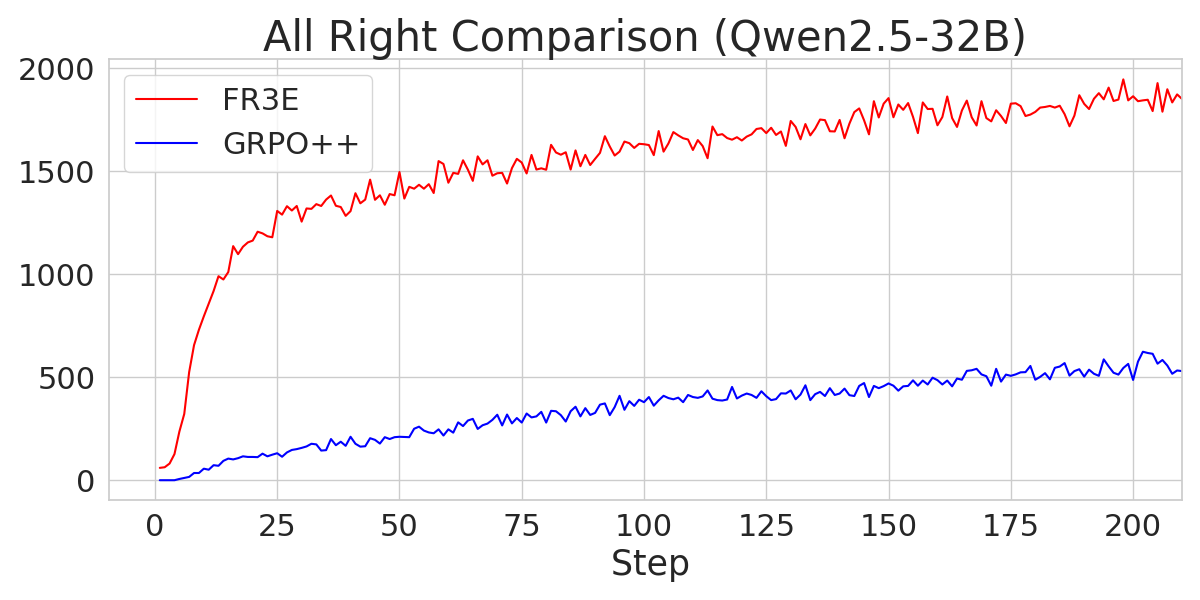
Figure 7: A comparison of the number of "All-Right" trajectories during the Entropy-Eliciting Explore phase for different Qwen2.5 models trained with FR3E and GRPO++.
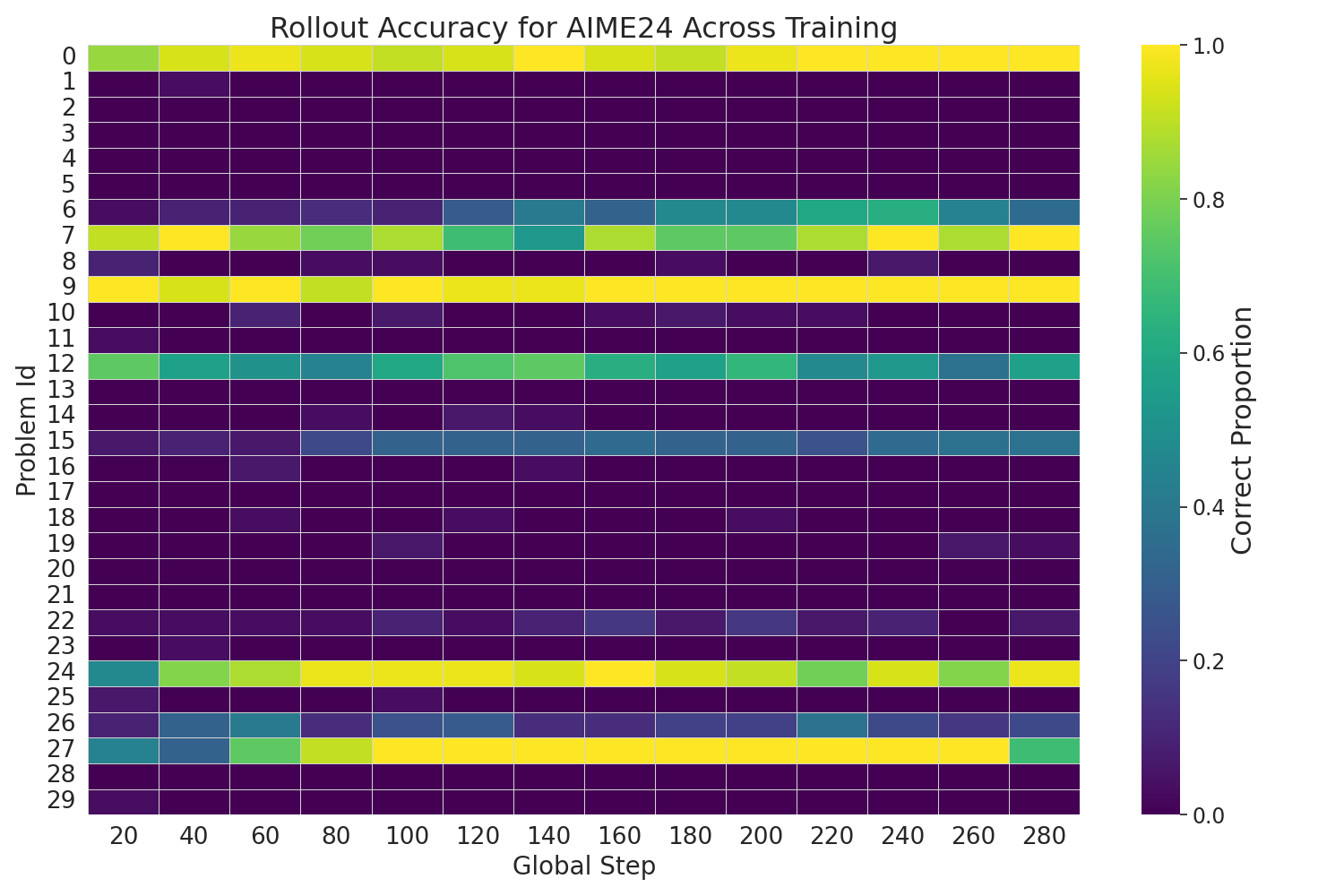
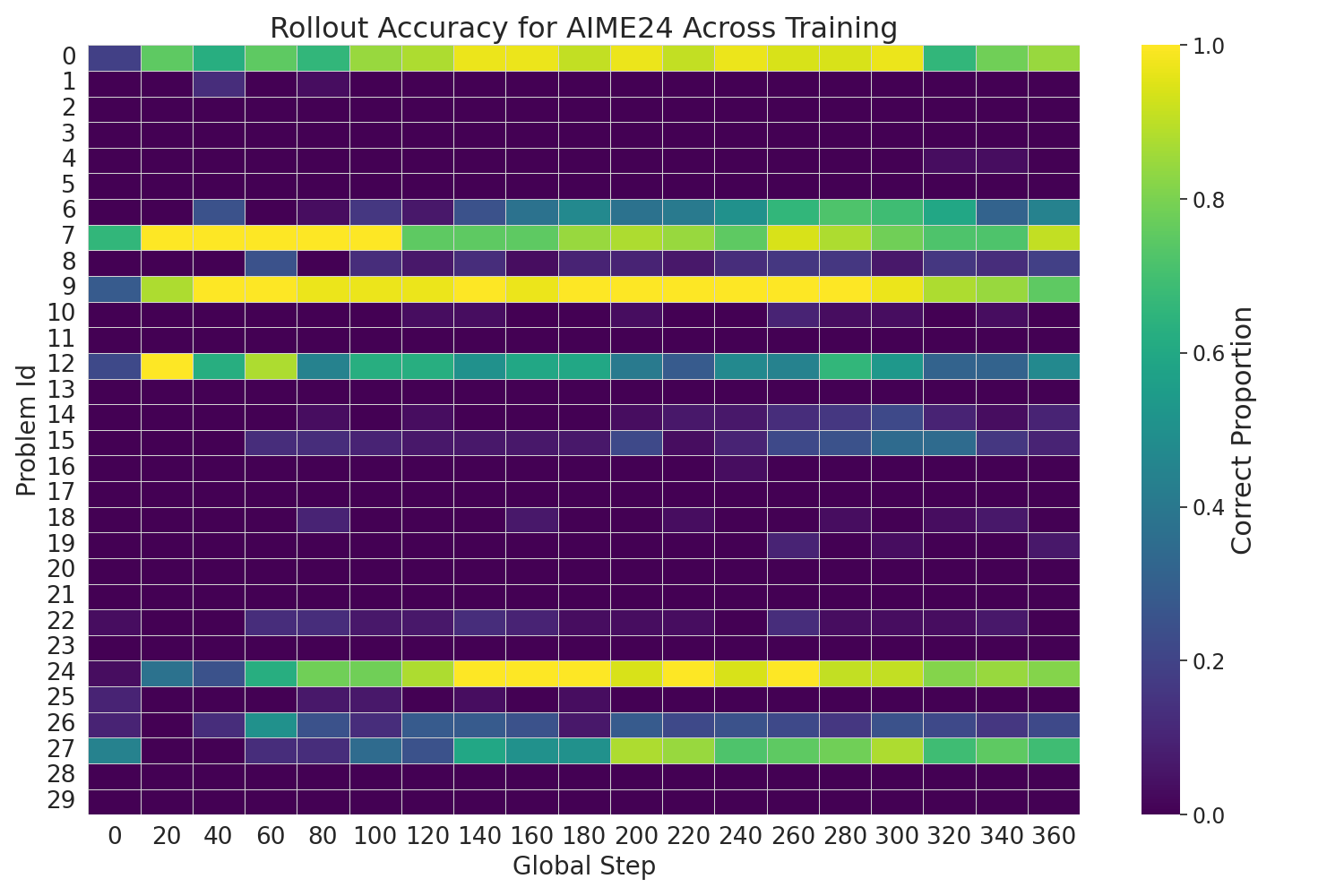
Figure 8: Rollout accuracy heatmap for FR3E(Qwen2.5-7B) showcasing a consistent transition from low-accuracy regions to high-accuracy regions as training progresses, indicating stable and progressive improvement.
Conclusion
FR3E offers an effective and structured approach to improving reasoning in LLMs through more reliable exploration. By identifying high-uncertainty points and initiating targeted rollouts, FR3E constructs intermediate feedback to guide the model and ensures stable policy updates. The results demonstrate that FR3E leads to more stable training dynamics, produces longer and more coherent reasoning chains, and increases the yield of correct solutions.

