- The paper demonstrates that GeoBrowse integrates fragmented visual cues and multi-hop text verification to evaluate agentic geolocation strategies.
- The paper details the GATE workflow, which coordinates image and text-based tools to achieve significant accuracy gains in both Level 1 and Level 2 tasks.
- The paper’s error taxonomy and trajectory analysis reveal that strategic sequencing of multimodal tools is crucial to overcoming perception and evidence synthesis challenges.
Introduction and Motivation
GeoBrowse establishes a new agentic multimodal benchmark to rigorously evaluate tool-use strategies, evidence-driven reasoning, and multimodal information seeking in challenging geolocation tasks. Existing testbeds such as BrowseComp focus primarily on text and multi-hop verification. Prior multimodal benchmarks either isolate visual cues or treat perceptual input as a single step within a text-dominant chain, failing to reflect the integration and open-ended verification often required in authentic web-driven geolocation tasks. GeoBrowse is designed to require both the composition of weak, ambiguous visual cues and BrowseComp-style multi-hop knowledge traces, with explicitly annotated expert trajectories.
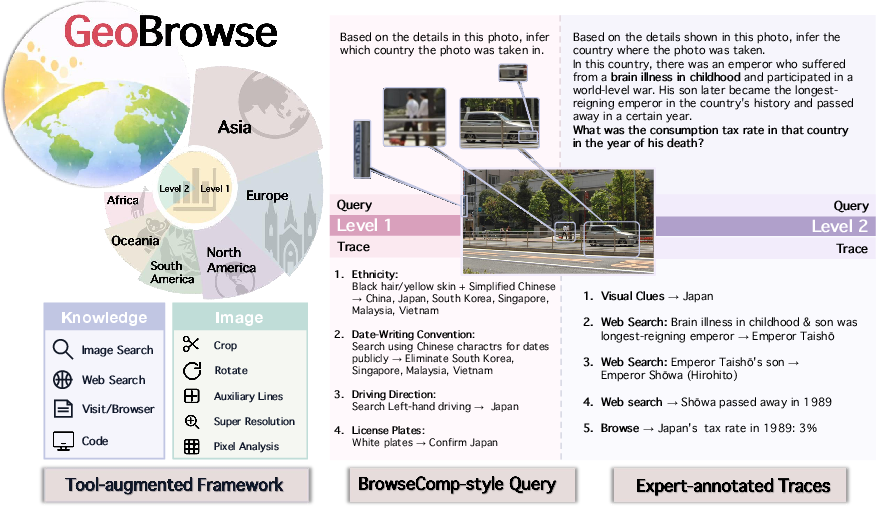
Figure 1: GeoBrowse couples a tool-use framework with a geolocation benchmark: Level 1 emphasizes visual cue composition, while Level 2 contains BrowseComp-style queries, all paired with expert-annotated stepwise traces.
GeoBrowse consists of 300 globally distributed instances, stratified into two levels. Level 1 necessitates extracting and composing fragmented visual cues, typically avoiding salient landmarks to increase complexity yet guarantee solvability. Level 2 superadds a multi-hop chain construction methodology, systematically obfuscating key path entities following the BrowseComp paradigm, thus enforcing multi-stage retrieval and web-based verification. Each instance is certified by curated expert stepwise traces, maximizing both solvability and interpretability for model analysis.
GeoBrowse Benchmark Design
GeoBrowse instances are sourced from expert-generated geolocation videos, further annotated by domain specialists to establish actionable visual fragments, required tool-use, and evidentiary reasoning chains. Instances are globally distributed, with 47% from Asia and substantial representation from Europe, the Americas, Africa, and Oceania.
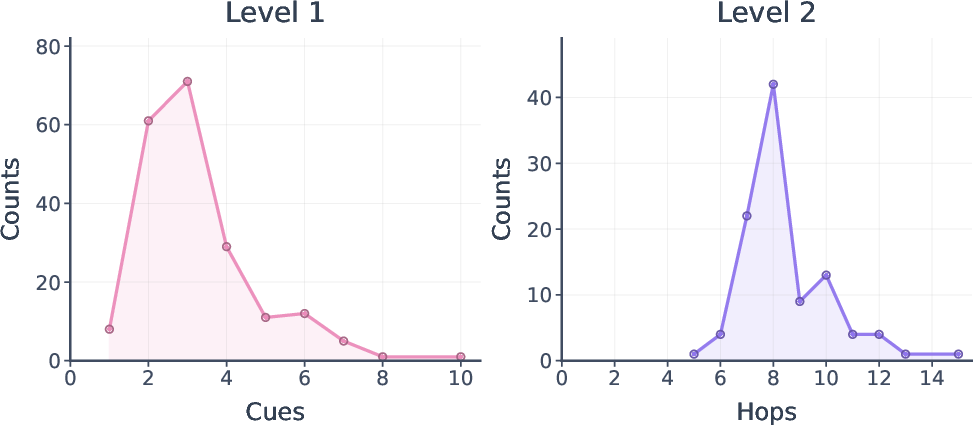
Figure 2: Distribution of target administrative levels. The # and \% signify count and percentage, respectively.
Level 1 tasks are image-centric, with 2–4 visual cues per instance (mean 3.21). Level 2 extends these by introducing manipulated, multi-hop chains constructed from the Wikipedia entity graph. Intermediate entities are purposely obfuscated, increasing reliance on sequential inference and external evidence validation. Each instance includes an authoritative trajectory, specifying milestones and error-resilient solution paths, enabling granular trajectory-level evaluation.
The GATE Agentic Workflow
GeoBrowse’s agentic evaluation is structured around the GATE (Geolocation Agentic-workflow with Tool Enhancement) system. GATE orchestrates a suite of image-side and knowledge-side tools, supporting both in-depth visual manipulation and multi-channel web-based evidence acquisition.
- Think-with-image tools: Include region cropping, orientation correction, auxiliary overlays, local super-resolution, and pixel-level statistics (e.g., color histograms, edge density).
- Knowledge tools: Support web-based text and image search (Google SerpApi), goal-conditioned page navigation (Jina), and in-sandbox code interpretation for symbolic/numerical processing.
The agent employs a ReAct-style iterative protocol: in each cycle, a <Think> block summarizes the evidence state and tool deployment plan, <Action> executes a tool, and <Obs> incorporates the result. An embedded image registry enables robust tracking of image derivatives across steps, circumventing context and pointer errors characteristic of long tool call chains.
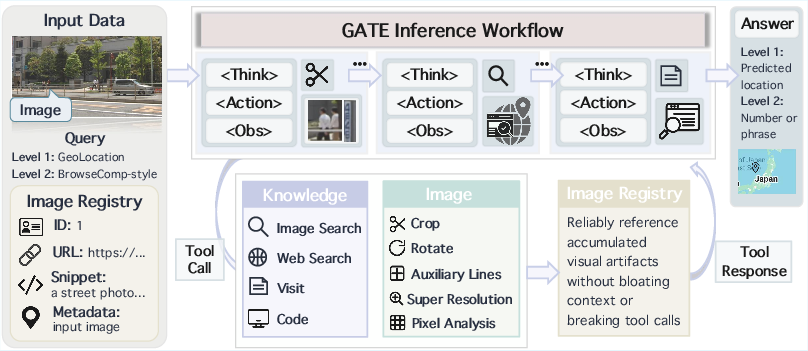
Figure 3: The pipeline of GATE, the Geolocation Agentic-workflow with Tool Enhancement. The agent interacts iteratively via <Think>, <Action>, and <Obs> in a structured loop, employing image and knowledge tools.
Empirical Results
Comprehensive experiments across 12 MLLMs and 3 open-source agents illuminate three core findings:
- GATE’s agentic workflow yields substantial accuracy gains over direct inference and isolated tool-use baselines. On Level 1, Gemini-3-Pro with GATE attains 48.2% versus 35.7% for direct inference; on Level 2, 34.7% versus 22.8%, demonstrating that neither search-only nor image-only paradigms are sufficient.
- Performance gains derive from coordinated, level-specific tool use—coherent plans instead of increased tool frequency. Coarse tool call statistics reveal that Level 1 is dominated by image processing and image search (e.g., Crop, Local Super-Resolution), while Level 2 shifts heavily to web text search and goal-conditioned visits for evidence integration.
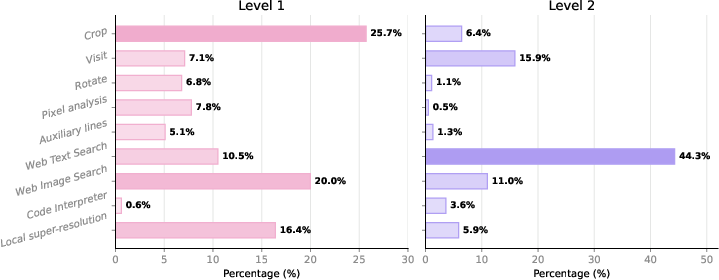
Figure 4: Tool-use distribution on GeoBrowse, illustrating the functional differentiation of tool classes between Level 1 (visual-centric) and Level 2 (knowledge-centric) tasks.
- Trajectory analysis shows robust models leverage agentic planning to improve solution path fidelity, milestone coverage, and reduce final integration errors. Strong models (e.g., Gemini-3-Pro, GPT-5) achieve milestone hit rates above 78% in successful Level 2 trajectories, with error analysis pinpointing failures to evidence synthesis and final decision stages, rather than initial cue extraction or query formulation.
Analysis and Error Taxonomy
Ablation studies confirm that agentic gains do not originate from mere tool proliferation but from the strategic selection and sequencing of tools. Single-tool settings—for instance, disabling web search in Level 2—result in significant accuracy drop (best synergy gap 3.7% on Level 2).
Fine-grained analysis of failed Level 2 cases reveals a distinct error taxonomy:
- Perception/grounding failures: Weak models disproportionately fail at early entity extraction and grounding.
- Retrieval/synthesis failures: Strong models mostly err during evidence synthesis and final inference, often after accumulating sufficient milestones.
This stratification supports the claim that web-augmented multimodal reasoning requires both robust perceptual grounding and high-fidelity evidence integration.
Practical and Theoretical Implications
GeoBrowse provides a controlled yet challenging substrate for investigating the limits of agentic multimodal reasoning. Its design exposes weaknesses in current open-source agents, particularly in tool coordination and evidence synthesis, and motivates future work in adaptive planning, belief-state tracking, and budgeted verification. Methodologically, its expert-annotated, milestone-driven structure enables refined trajectory-level model analysis, supporting both fine-grained error attribution and the development of trajectory-aligned learning objectives.
On the practical front, GeoBrowse offers a benchmark for evaluating web-augmented agents in scenarios where visual ambiguity is unavoidable, and verification from open evidence is required—setting a realistic bar for deployment in scientific, investigative, and real-world decision-support tasks.
Future research may focus on scalable, semi-automated expert trace annotation, improved open-ended tool libraries, and context-adaptive planning frameworks with tighter evidence closure constraints.
Conclusion
GeoBrowse formalizes the integration of ambiguous visual perception, evidence-driven reasoning, and agentic tool use, providing a rigorous multimodal benchmark with stepwise expert traces. Empirical results show that agentic, plan-coherent tool workflows are required for reliable performance—simple tool orchestration or direct inference is insufficient, especially as compositional and verification complexity increases. The dataset enables detailed error analysis, facilitating progress in trajectory-level planning and robust evidence integration. GeoBrowse is thus positioned as a foundation for the next generation of web-augmented, multimodal agents.