GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
Abstract: Current research on agentic visual reasoning enables deep multimodal understanding but primarily focuses on image manipulation tools, leaving a gap toward more general-purpose agentic models. In this work, we revisit the geolocalization task, which requires not only nuanced visual grounding but also web search to confirm or refine hypotheses during reasoning. Since existing geolocalization benchmarks fail to meet the need for high-resolution imagery and the localization challenge for deep agentic reasoning, we curate GeoBench, a benchmark that includes photos and panoramas from around the world, along with a subset of satellite images of different cities to rigorously evaluate the geolocalization ability of agentic models. We also propose GeoVista, an agentic model that seamlessly integrates tool invocation within the reasoning loop, including an image-zoom-in tool to magnify regions of interest and a web-search tool to retrieve related web information. We develop a complete training pipeline for it, including a cold-start supervised fine-tuning (SFT) stage to learn reasoning patterns and tool-use priors, followed by a reinforcement learning (RL) stage to further enhance reasoning ability. We adopt a hierarchical reward to leverage multi-level geographical information and improve overall geolocalization performance. Experimental results show that GeoVista surpasses other open-source agentic models on the geolocalization task greatly and achieves performance comparable to closed-source models such as Gemini-2.5-flash and GPT-5 on most metrics.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching an AI to figure out where a photo was taken, anywhere in the world. The authors build a smart system called GeoVista that can “think with images” like a detective: it looks closely at pictures (zooming into details), searches the web to confirm guesses, and then decides the most likely location. They also create a new test set, GeoBench, made of high-quality images from many places to check how well different AIs do at this task.
What questions were they trying to answer?
They wanted to know:
- Can an AI improve at geolocalization (guessing a photo’s location) by combining careful visual inspection with web search?
- How do we fairly test this ability across different image types (normal photos, panoramas, satellite images) and different levels (country, state/province, city)?
- What training steps help an AI learn to use tools (zoom, search) during multi-step reasoning?
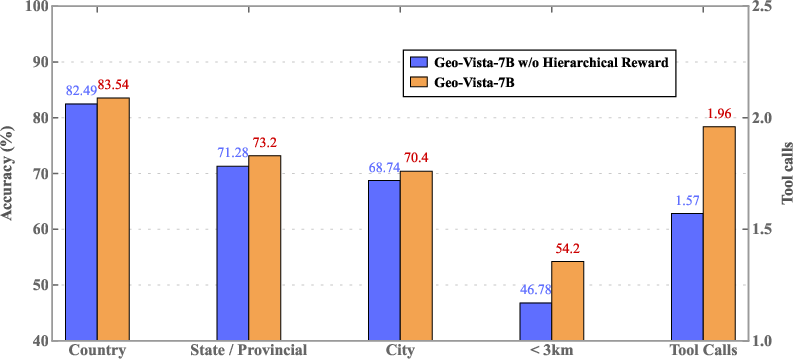
- Do smarter rewards (giving partial credit for getting the right country/state even if the city is wrong) make the AI better?
How did they do it?
The task: Geolocalization
Geolocalization means identifying where a photo was taken. Imagine you’re a travel detective: you spot clues like road signs, language, architecture, plants, license plates, and then check the web to confirm your hunch.
The benchmark: GeoBench
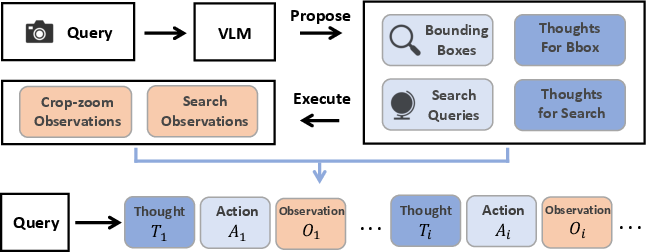
To test AIs properly, they built GeoBench:
- It contains 1,142 high-resolution images from around the world: normal photos, stitched street-view panoramas, and satellite images.
- It covers 6 continents, 66 countries, and 108 cities.
- They removed images that are too generic (like close-ups of food) and super-famous landmarks (too easy), so the task stays challenging but solvable.
- They evaluate at multiple levels: country, state/province, and city.
- For very precise guesses, they also measure how far the predicted point is from the true point on Earth (using “haversine distance,” which is like measuring the shortest path over the globe’s surface).
The AI: GeoVista
GeoVista is an “agentic” AI, meaning it decides what tools to use while thinking. It works in a loop:
- Thought: Form a guess or plan (e.g., “That street sign looks Spanish—zoom in!”).
- Action: Use a tool (crop-and-zoom on part of the image, or run a web search).
- Observation: See the zoomed image or read web results, then think again.
- Repeat until it’s confident enough to answer.
Two main tools:
- Crop-and-Zoom: Like using a magnifying glass to see small details (street signs, storefronts, flags).
- Web Search: Like quickly checking the internet to verify clues (e.g., “Does this bus logo belong to Madrid’s transit system?”).
Training the AI to think and use tools
They used two steps:
- Supervised Fine-Tuning (SFT): They first “show” the model how good reasoning looks. They collect examples where another strong model proposes:
- Which regions to zoom,
- What web queries to run,
- Why these steps help,
- And how to reach a final answer. This teaches GeoVista the pattern of multi-step, tool-using reasoning.
- Reinforcement Learning (RL): Then they let GeoVista practice and learn from feedback. If it gets the location right, it gets a reward. They use “hierarchical rewards,” which means:
- Right country → some points,
- Right state/province → more points,
- Right city → the most points. This encourages the model to improve even if it’s not perfect yet, and to use clues that help narrow down progressively.
Think of SFT as watching a coach demonstrate smart moves, and RL as playing many matches and getting points for close misses and bigger points for perfect hits.
Evaluating performance
They test:
- Accuracy at country, state/province, and city levels.
- City-level accuracy on each image type (photo, panorama, satellite).
- Fine-grained precision by checking if the predicted point is within 3 km of the true spot and by measuring the median distance error.
What did they find, and why is it important?
GeoVista did very well:
- It beat other open-source models by a large margin at all levels.
- It came close to strong closed-source systems (like Gemini-2.5) on many metrics, even though those systems are likely much larger.
- It was especially strong on panoramas and normal photos; satellite images were harder, but GeoVista still improved there.
- Its precise distance errors were small compared to other open-source models, showing it can make very accurate guesses.
They also learned what helps the most:
- Teaching the model how to think with tools (SFT) is essential. Without it, the model rarely calls tools and does poorly.
- Letting the model practice with feedback (RL) further boosts performance.
- Hierarchical rewards teach the model to use layered clues (country → state → city), improving multi-step reasoning.
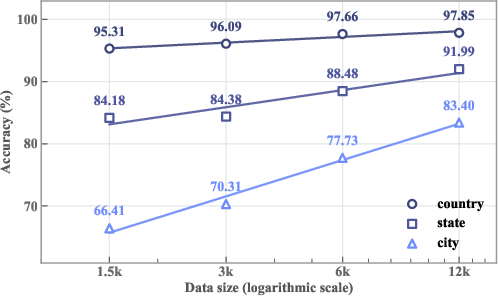
- As they increased RL training data, performance steadily improved (a healthy scaling trend).
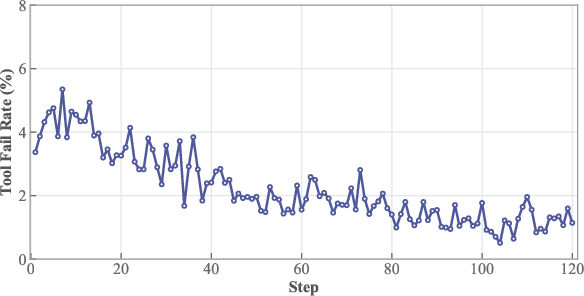
- Over time, the model made fewer bad tool calls (like malformed zoom boxes), meaning it learned to use tools more carefully.
Implications and impact
This work shows that “thinking with images” becomes much stronger when an AI can:
- Look closely (zoom) to extract fine details,
- Check the web to confirm or refine ideas,
- And learn with step-by-step guidance plus smart rewards.
Why it matters:
- Better geolocalization can help organize and search large photo collections, aid journalism and disaster response, and support mapping and navigation.
- The agentic approach (planning, acting, checking) can be applied beyond geolocalization—any task where visual clues plus online information lead to better answers (e.g., product identification, plant or animal spotting, cultural site recognition).
- The GeoBench dataset and evaluation methods provide a fair, detailed way to measure progress, pushing the field toward more practical, real-world reasoning.
Key terms explained
- Geolocalization: Guessing where a photo was taken using visual clues and knowledge.
- Agentic model: An AI that decides which tools to use while reasoning (like a detective choosing whether to zoom or to search).
- Crop-and-Zoom: Selecting a part of an image and enlarging it to see details.
- Web Search: Using the internet to check facts (logos, languages, transit systems, store names).
- Supervised Fine-Tuning (SFT): Teaching by example—showing the AI good multi-step solutions.
- Reinforcement Learning (RL): Learning by trial and reward—practicing many times and getting feedback.
- Hierarchical Reward: Giving partial credit for getting broader regions right (country, state) and more credit for getting precise locations (city).
- Haversine Distance: A way to measure how far two points are on Earth’s surface (like the shortest route around the globe).
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and questions the paper leaves unresolved, intended to guide future research:
- Web-search tool specification and robustness: the paper does not detail the search provider(s), ranking/summarization pipeline, query expansion, anti-spam measures, caching strategies, or rate-limit handling; systematically evaluate how different search engines, temporal drift, and SEO noise affect accuracy and reproducibility.
- Reliance on closed-source VLMs for SFT data curation: quantify bias/noise from Seed-1.6-vision-generated trajectories, measure effects of incorrect tool proposals on downstream performance, and compare to human-validated or filtered trajectories; release trajectory quality metrics and inter-annotator agreement.
- Small cold-start dataset size: investigate scaling laws for SFT trajectory data (beyond 2k samples) and the trade-offs between trajectory length, tool diversity, and performance; provide experiments on data mixture composition and quality-controlled SFT.
- Missing ablations on tool contributions: isolate the marginal utility of web-search vs crop-and-zoom by disabling each tool and measuring performance deltas across data types and regions; quantify when web search helps/hurts.
- Limited toolset: add OCR (street signs, storefronts), language detection/translation, logo/brand recognition, landmark disambiguation, map/geocoding APIs as tools, and panorama navigation (yaw/pitch/zoom) to test whether richer visual/knowledge tools improve localization and reduce web dependence.
- Reward design limitations: the RL uses discrete hierarchical rewards (country/state/city); explore continuous, distance-based rewards (e.g., negative haversine distance), mixed discrete+continuous rewards, and curriculum learning to better shape fine-grained predictions.
- Unexplored RL hyperparameters: assess the impact of KL/entropy regularization, clip ranges, group size, turn limits, and alternative policy optimization methods (e.g., PPO variants, process rewards) on stability, tool use, and accuracy.
- Fixed hierarchical reward coefficient: only β=2 was tested; perform sensitivity analysis across β values and adaptive weighting strategies that respond to model confidence and difficulty.
- Turn-depth and pixel-budget sensitivity: study accuracy–latency–cost trade-offs by varying maximum turns, dynamic stopping criteria, and initial pixel budgets; determine optimal policies under resource constraints.
- Evaluation reliance on a closed-source model-based verifier: quantify verifier error rates, language coverage, bias across regions, and robustness to response formats; offer an open-source alternative or multi-verifier consensus to ensure reproducibility.
- Geocoding-based nuanced evaluation risks: analyze geocoder ambiguity, failure modes (partial addresses, synonyms), and vendor dependence; report geocoding error rates and add evaluation that accepts direct coordinate outputs and compares to ground truth with spatial tolerance.
- City boundary definitions and correctness criteria: standardize spatial polygons/buffers for “city-level” correctness; report sensitivity to boundary choices and urban agglomerations; consider hierarchical geography differences across countries.
- Dataset curation transparency: detail the model-based filters (thresholds, classifiers) used to remove non-localizable images and landmarks; quantify false removals/retentions and the induced selection bias relative to real-world image distributions.
- Coverage and representation: the dataset spans 6 continents, 66 countries, and 108 cities but with small sample counts; measure per-region performance, language/script effects, and urban vs rural/remote generalization; expand underrepresented geographies.
- Satellite image underperformance: GeoVista’s city-level accuracy lags substantially on satellite images; investigate aerial-specific pretraining, cross-view matching tools, multi-scale feature extraction, and alignment with cartographic layers.
- Cross-view generalization: explicitly test ground-to-aerial and aerial-to-ground tasks and incorporate specialized tools (tile retrieval, map matching) to bridge modality gaps; benchmark against cross-view SOTA methods.
- Baseline coverage: include strong non-agentic geolocalization baselines (retrieval/classification models from Im2GPS/YFCC/OpenStreetView-5M) for fair comparisons; analyze when agentic reasoning truly outperforms specialized pipelines.
- Robustness to adversarial or noisy web content: evaluate prompt-injection, misinformation, and malicious web pages during browsing; propose defenses (content sanitization, trust scoring, provenance tracking).
- Reproducibility of web-augmented evaluation: release search logs/snapshots or a static corpus to avoid drift; measure variance across runs/times/providers and propose standardized evaluation settings.
- Inference efficiency and cost: report latency and cost per query (tool calls, search API usage), and study cost-aware planning (e.g., tool call budgeting, early stopping) without sacrificing accuracy.
- Error taxonomy and targeted fixes: provide a detailed breakdown of failure modes (visual misreads, language misinterpretation, wrong query formulation, geocoding mismatch) and link each to candidate interventions (e.g., better OCR, query rewriting).
- Uncertainty estimation and abstention: add confidence calibration, selective answering, and fallback strategies; evaluate whether calibrated uncertainty improves user trust and downstream decision-making.
- Generality beyond geolocalization: the paper motivates “general-purpose agentic models” but evaluates only geolocalization; test transfer to other web-augmented visual reasoning tasks (e.g., product recognition with sourcing, historical site identification).
- Panorama handling limitations: planar panoramas may lose navigable context; experiment with interactive 360° navigation tools, viewpoint changes, and multi-view aggregation to recover spatial cues.
- Licensing, privacy, and ethics: clarify data licenses, usage restrictions (Mapillary, Sentinel-2, web images), privacy concerns in geolocation tasks, and safeguards to prevent misuse (e.g., doxxing-sensitive content).
- Data and code release details: specify availability of GeoBench, tool wrappers, evaluation scripts, and training checkpoints; provide full documentation to enable exact reproduction of results.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, leveraging the paper’s tools (crop–zoom image manipulation and web search within an agentic reasoning loop), training recipe (SFT + RL), and evaluation assets (GeoBench with level-wise and nuanced metrics).
- OSINT and digital forensics (Policy, Media, Public Safety)
- Use case: Rapidly verify the claimed location of images/videos circulating online (e.g., conflict zones, disaster scenes), identify miscaptioned content, and support incident geo-confirmation.
- Potential tools/workflows: “GeoVista Geolocation API” microservice; pipeline that runs city/country validation, geocoding, and haversine thresholds (<3 km) with confidence scoring; audit-ready reasoning logs.
- Assumptions/dependencies: Access to real-time web search APIs; high-resolution imagery or screenshots; compliance with data privacy and platform ToS; human-in-the-loop review for high-stakes content.
- Social media geotagging and moderation (Software, Policy)
- Use case: Auto-geotag posts lacking EXIF, flag suspicious location claims, and down-rank misinformation.
- Potential tools/products: Moderation plug-in that interleaves crop–zoom and web search; escalations when distance error exceeds threshold; dashboard for policy teams.
- Assumptions/dependencies: Platform integration, cost control for API calls, guardrails for sensitive or private locations.
- Marketplace and real-estate listing verification (Finance, PropTech)
- Use case: Validate that photos for rentals/sales were taken where claimed; detect relisted or stock photos used in fraud.
- Potential tools/workflows: Batch photo verification queue with GeoVista; rules using city/state-level correctness and haversine distance; audit trail in CRM.
- Assumptions/dependencies: Sufficient visual cues (e.g., exteriors, signage); legal approvals for automated checks; user consent.
- Insurance claims assessment and fraud detection (Finance/InsurTech)
- Use case: Verify the location of accident/property damage photos against reported claims; prioritize investigations.
- Potential tools/workflows: Claims intake pipeline with automated geolocation, confidence scores, and case triage; human adjuster review with reasoning trajectory.
- Assumptions/dependencies: Clear geographic cues in images; adherence to privacy and regulatory requirements.
- Disaster response and crisis mapping (Public Safety, Humanitarian)
- Use case: Geolocate citizen-sourced imagery during floods, earthquakes, or storms to build near-real-time damage maps.
- Potential tools/workflows: Emergency ops dashboard with geocoded pins, confidence bands, hierarchical location matches; integration with GIS.
- Assumptions/dependencies: Reliable connectivity, data deduplication and verification; human oversight for critical deployments.
- Drone and robotics operator assist when GPS degrades (Robotics)
- Use case: Fallback geolocalization of aerial snapshots (or ground images) to city/neighborhood when GPS is unreliable.
- Potential tools/workflows: On-operator console assistant invoking crop–zoom; cached local web data; confidence thresholds to guide pilots.
- Assumptions/dependencies: Adequate resolution and distinct landmarks; intermittent or offline retrieval alternatives; safety protocols.
- Consumer photo organization and travel journaling (Software, Daily Life)
- Use case: Auto-sort old photos by location, reconstruct itineraries, and augment albums with local facts.
- Potential tools/products: Mobile app feature powered by GeoVista; privacy-preserving local processing of photos; “Where was this?” assistant.
- Assumptions/dependencies: Sufficient detail in photos; cost/latency suitable for consumer devices; opt-in privacy controls.
- Cultural/tourism companion (Education, Software, Daily Life)
- Use case: Identify the city from street scenes and fetch local history, points of interest, and language tips via web search.
- Potential tools/products: Web-augmented travel bot that interleaves geolocation and curated web retrieval; in-app cultural cards.
- Assumptions/dependencies: Reliable web sources; disambiguation across similar-looking regions.
- Academic benchmarking and reproducible evaluation (Academia)
- Use case: Standardize geolocalization evaluation with level-wise accuracy and nuanced metrics (haversine), compare agentic VLMs.
- Potential tools/workflows: GeoBench + evaluation scripts; GRPO training baselines; hierarchical reward ablations for research.
- Assumptions/dependencies: Dataset licensing; geocoding API availability; reproducible tool access (search, zoom).
- Web-augmented agent toolkit for non-geo visual tasks (Software)
- Use case: Reuse think–act–observe with crop–zoom + web search for tasks like sign interpretation, product identification, or storefront verification.
- Potential tools/workflows: Controller template, tool schemas, and reasoning trajectory SFT generator to bootstrap domain-specific agents.
- Assumptions/dependencies: Domain-specific prompt engineering; suitable web corpora; data quality and source credibility.
- Remote sensing quick-look city identification (Energy, Urban Planning)
- Use case: Assign likely city/region to satellite tiles during inventory, QA, or rapid response.
- Potential tools/workflows: Batch pipeline to tag tiles; confidence stratification; handoff to analysts for hard cases.
- Assumptions/dependencies: Satellite resolution and cloud cover constraints; domain finetuning for aerial imagery.
Long-Term Applications
The following use cases require further research, model scaling, edge optimization, robust guardrails, or cross-institution collaboration before reliable deployment.
- On-device geolocation fallback for autonomous vehicles and AR navigation (Robotics, Software)
- Use case: Ultra-low-latency, privacy-preserving geolocalization on edge hardware when GPS is unreliable.
- Potential tools/products: Quantized GeoVista variants; local map caches; multimodal fusion with inertial/vision odometry.
- Assumptions/dependencies: Efficient 7B (or smaller) models meeting real-time constraints; safety certification; offline retrieval strategies.
- Privacy-preserving geolocation frameworks (Policy, Software)
- Use case: Federated/on-device geolocation with differential privacy; configurable limits on precision to mitigate risks (e.g., do not output exact home addresses).
- Potential tools/workflows: Policy-controlled confidence caps; consent-aware interfaces; encrypted audit logs of reasoning.
- Assumptions/dependencies: New privacy standards; regulator-approved practices; robust anonymization.
- Cross-platform misinformation provenance networks (Policy, Media)
- Use case: Share geolocation confidence and reasoning artifacts across platforms as part of content provenance standards (e.g., C2PA extensions).
- Potential tools/workflows: Provenance registry, verifiable logs of tool calls and sources; interoperability with newsroom OSINT tools.
- Assumptions/dependencies: Industry standards adoption; legal agreements; robust source credibility scoring.
- Enterprise OSINT/research workstations (Industry, Software)
- Use case: Integrated agentic research suite combining geolocation, deep web retrieval, summarization, and audit trails for analysts.
- Potential tools/products: Desktop apps with multi-turn reasoning visualization; case management integrations; team collaboration features.
- Assumptions/dependencies: Reliability at scale; adversarial robustness; training on sector-specific data.
- Real-time emergency early-warning systems (Public Safety)
- Use case: Stream ingest from social platforms, auto-geolocate, cluster events, and alert responders with confidence ranking and uncertainty bounds.
- Potential tools/workflows: Active learning loop (human feedback improves the agent); incident triage playbooks.
- Assumptions/dependencies: Large-scale ingestion; misinformation defenses; bias mitigation; public–private data-sharing agreements.
- Smart-city asset management and GIS automation (Energy/Utilities, Urban Planning)
- Use case: Geolocate field photos of assets (poles, meters, valves), update GIS records, and trigger maintenance workflows.
- Potential tools/workflows: CMMS integration; asset-ID matching via crop–zoom and OCR; route optimization.
- Assumptions/dependencies: Annotated asset datasets; integration with existing GIS/CMMS; worker safety and privacy safeguards.
- Wildlife conservation and environmental monitoring (Environment)
- Use case: Geolocate citizen or camera-trap imagery to map species distributions or illegal logging hotspots.
- Potential tools/workflows: Conservation dashboards; combined satellite + ground-image reasoning; alerts to rangers.
- Assumptions/dependencies: Domain finetuning; limited web data in remote areas; ethical considerations in sensitive habitats.
- Generalized hierarchical reward frameworks for structured tasks (Academia, Software)
- Use case: Apply hierarchical rewards to taxonomy-aware classification (e.g., medical coding, product categorization), multi-level QA, or robotic task hierarchies.
- Potential tools/workflows: RL training libraries embedding multi-level label structures; evaluation metrics that reflect partial correctness.
- Assumptions/dependencies: High-quality hierarchical datasets; careful reward tuning to avoid gaming or collapse.
- Education platforms for geography and critical media literacy (Education)
- Use case: Interactive “Where is this?” curricula using agentic reasoning traces to teach students evidence-based geolocation and source evaluation.
- Potential tools/workflows: Classroom dashboards with step-by-step reasoning; teacher controls; student privacy.
- Assumptions/dependencies: Age-appropriate guardrails; curated web sources; alignment with standards.
- Legal admissibility and evidentiary audit (Policy, LegalTech)
- Use case: Transparent, reproducible geolocation reasoning for court exhibits, with chain-of-custody and source verification.
- Potential tools/workflows: Signed reasoning logs, source credibility scores, tamper-evident storage.
- Assumptions/dependencies: Legal standards acceptance; expert testimony for method validation; reproducibility guarantees.
- Commercial satellite tasking and supply-chain risk analysis (Energy, Finance)
- Use case: Use ground imagery geolocation to inform satellite retasking (e.g., identify emergent hotspots) and assess logistics disruptions.
- Potential tools/workflows: Agent suggestions paired with human planner review; integration with satellite providers.
- Assumptions/dependencies: Partnerships with imagery vendors; robust prioritization policies; cost management.
- Edge acceleration and compression for widespread deployment (Software, Robotics)
- Use case: Distill/quantize the 7B agent for mobile, drone, and embedded devices while preserving tool-use behaviors.
- Potential tools/workflows: Model compression toolchain; simulated benchmarks using GeoBench; latency/cost telemetry.
- Assumptions/dependencies: Maintaining performance under compression; efficient local web retrieval or cached knowledge; continual updates.
Common Assumptions and Dependencies Across Applications
- High-resolution inputs with localizable visual cues; downsample budgets may be needed initially.
- Stable access to web search and geocoding services; rate limits and cost controls must be managed.
- Guardrails for privacy, safety, and sensitive locations; configurable precision caps for outputs.
- Human-in-the-loop review for critical decisions; audit trails using serialized reasoning trajectories.
- Domain-specific finetuning for specialized imagery (e.g., satellite, indoor scenes, industrial assets).
- Robustness to distribution shifts, occlusions, and adversarial manipulation; confidence calibration and fallback strategies.
Glossary
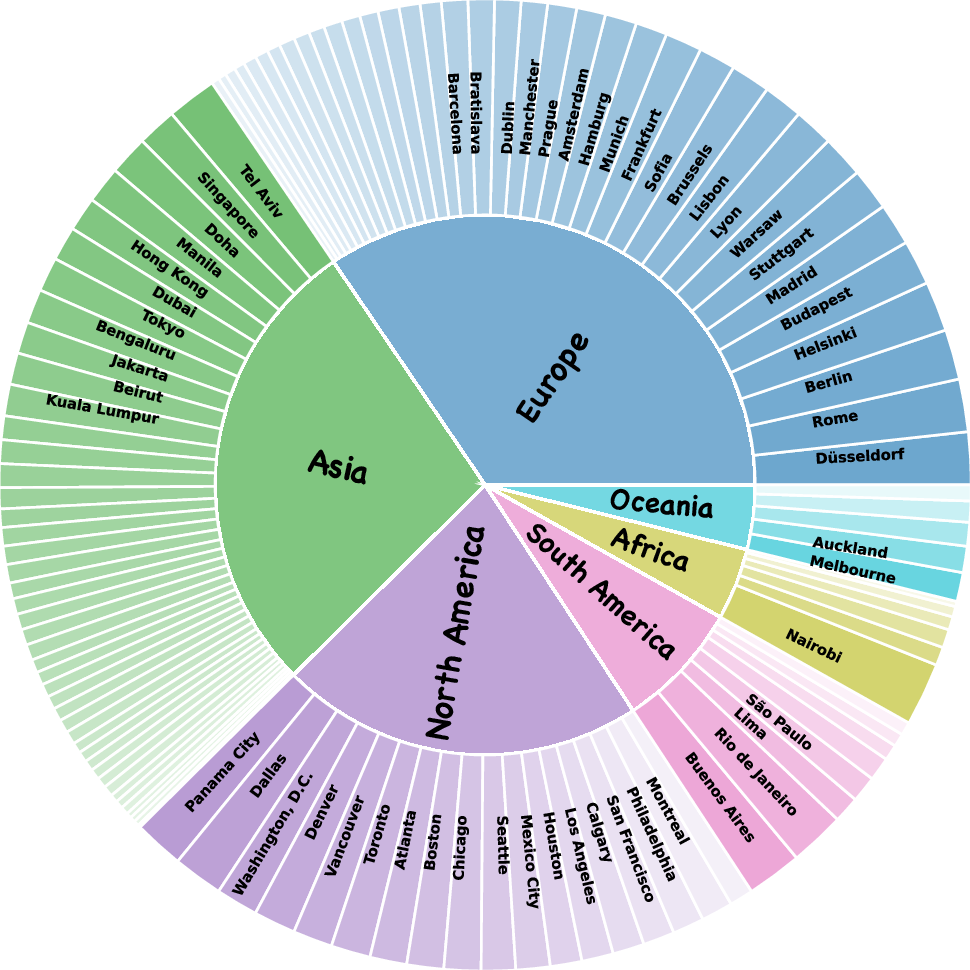
- Administrative levels: Governmental geographic tiers (e.g., country, province/state, city) used to structure evaluation. "validate the correctness of model responses at different administrative levels."
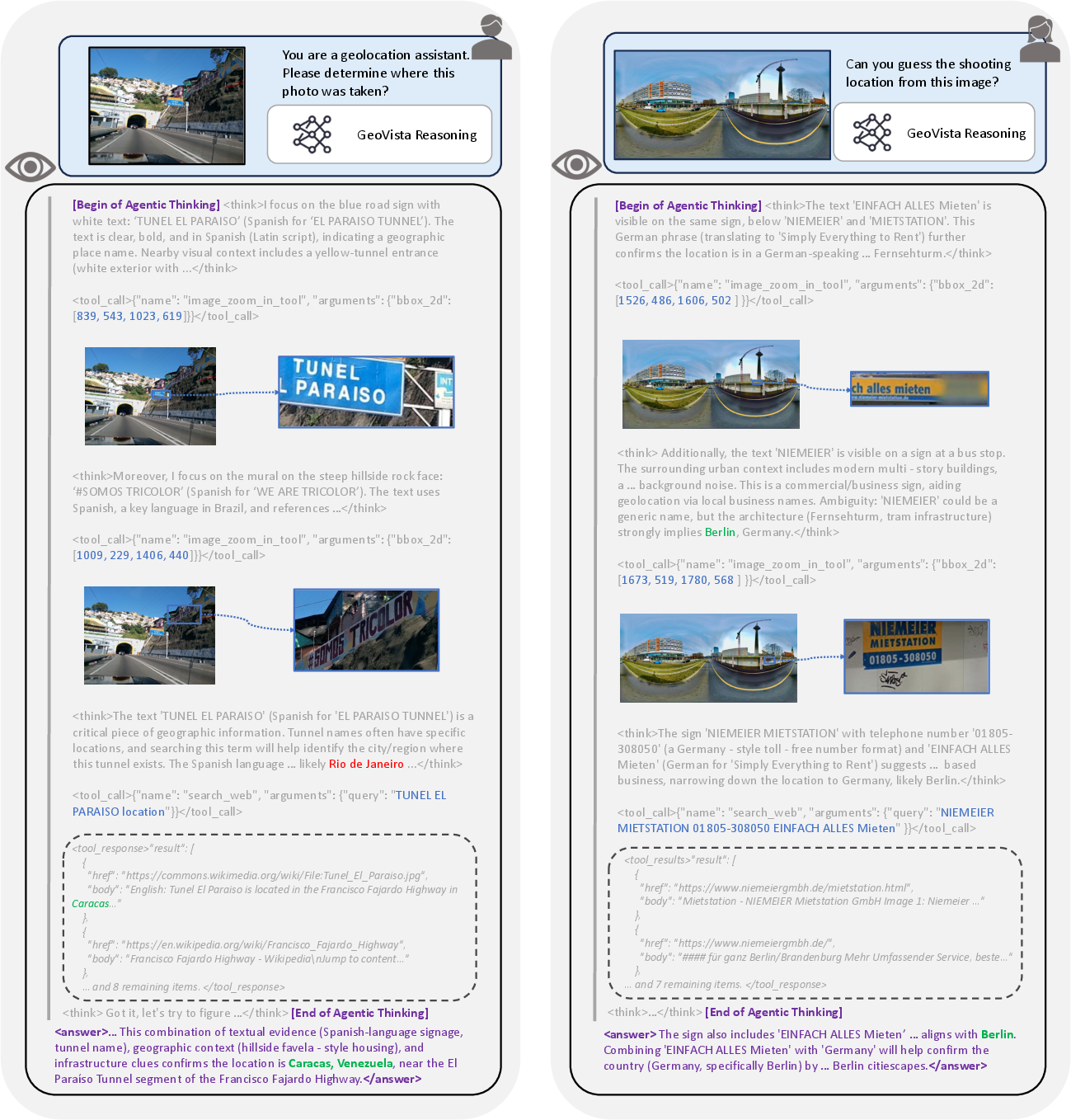
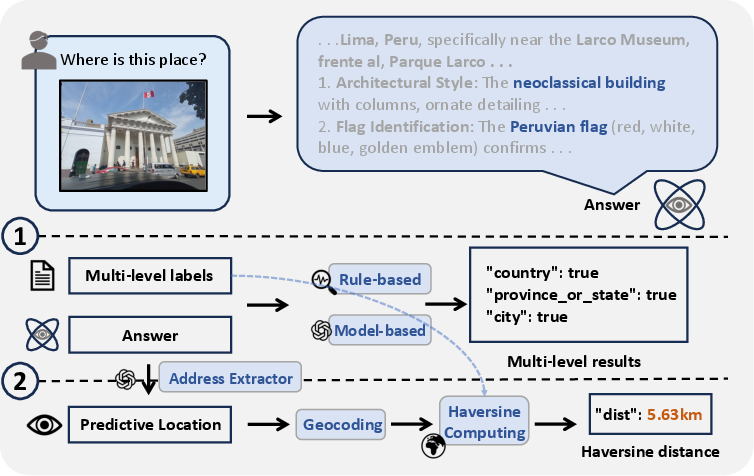
- Agentic pipeline: A structured loop where an agent generates thoughts and actions, executes tools, and updates observations until concluding. "Image examples from GeoBench and the training data, and the agentic pipeline of GeoVista."
- Agentic visual reasoning: An AI paradigm where models actively plan and use tools to reason over visual inputs. "Current research on agentic visual reasoning enables deep multimodal understanding"
- Bounding box (bbox_2d): A rectangle defined by pixel coordinates that specifies a region of interest for cropping/zooming. "The policy model outputs a bounding box parameterized with bbox_2d, which contains pixel coordinates used to crop and magnify regions of interest."
- Chain-of-Thought (CoT): An explicit sequence of intermediate reasoning steps that guides problem solving. "achieving a coordinated fashion of interleaving textual CoT~\citep{cot} with image manipulation and other tool invocations."
- Cold-start supervised fine-tuning (SFT): An initial supervised training stage that teaches reasoning patterns and tool-use behaviors before RL. "including a cold-start supervised fine-tuning (SFT) stage to learn reasoning patterns and tool-use priors"
- Crop-and-Zoom: A tool action that crops an image region and magnifies it to inspect fine details. "Crop-and-Zoom. The policy model outputs a bounding box parameterized with bbox_2d, which contains pixel coordinates used to crop and magnify regions of interest."
- Cross-view settings: Geolocalization tasks matching ground images to aerial/satellite views. "Prior work on real-world geolocalization spans single-image, landmark, and cross-view settings."
- Distributional diversity: Variability in data sources and locations to prevent bias and improve generalization. "To ensure distributional diversity, we curate GeoBench and training data of GeoVista from the cities worldwide."
- Entropy regularization: A reinforcement learning technique that encourages exploration by penalizing low-entropy policies. "In our implementation, we do not include KL or entropy regularization."
- External information retrieval: Using web search or documents from the internet to augment model knowledge during reasoning. "It not only utilizes visual operation and information retrieval tools to validate its hypotheses but also uses external information retrieval~\citep{open-web-research-agents, web_arena, BrowseMaster} to justify its previous wrong hypotheses and reach the correct solution."
- Geocoding: Converting textual locations or addresses into latitude/longitude coordinates via a service. "convert it into geodetic coordinates (latitude and longitude) via geocoding services (e.g., Google Geocoding API)"
- Geocoding API: A web service that transforms addresses into geospatial coordinates. "Google Geocoding API"
- Geodetic coordinates: Latitude and longitude values that specify locations on Earth’s surface. "convert it into geodetic coordinates (latitude and longitude) via geocoding services"
- Geolocalization: Inferring the geographic location of an image based on visual and contextual clues. "we revisit the geolocalization task, which requires not only nuanced visual grounding but also web search"
- Geolocalization coordinates: The precise latitude/longitude denoting an image’s true location. "the ground truth point (the geolocalization coordinates of the metadata)"
- Geolocalization metadata: Ancillary data attached to samples that includes true location coordinates. "each sample is accompanied by geolocalization metadata, including precise latitude and longitude."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that normalizes rewards across a group of outputs to stabilize training. "We apply group relative policy optimization (GRPO)~\citep{grpo} with geological labels to train the models."
- Haversine distance: The great-circle distance between two latitude/longitude points on a sphere. "compute the estimated haversine distance (km) between the prediction point and the ground truth point"
- Hierarchical reward: An RL reward scheme that assigns larger credit for correctly predicting more fine-grained administrative levels. "we design a hierarchical reward based on multi-level labels."
- KL regularization: A reinforcement learning constraint that limits divergence from a reference policy using Kullback–Leibler penalty. "In our implementation, we do not include KL or entropy regularization."
- Level-wise evaluation: Assessing predictions at multiple geographic administrative levels (country/province/city). "Level-wise evaluation, which employs both rule-based and model-based verifiers to determine correctness at different administrative levels"
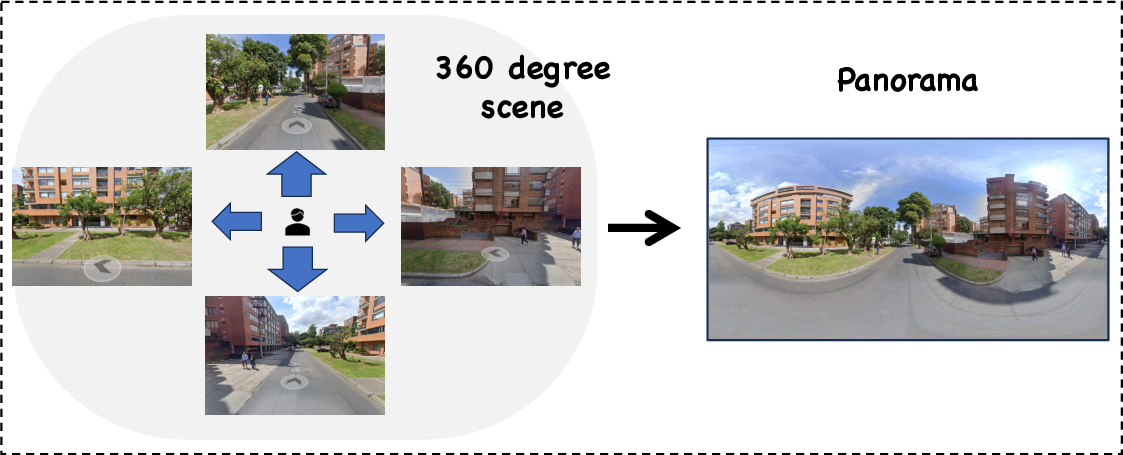
- Mapillary API: An interface for accessing street-view imagery tiles used to construct panoramas. "stitching tiles retrieved via the Mapillary API"
- Microsoft Planetary Computer: A platform providing planetary-scale environmental datasets and tools. "from the Microsoft Planetary Computer"
- Model-based verifier: An automated checker that uses an ML model to judge the correctness of location predictions. "a model\textendash based verifier (using OpenAI gpt-4o-mini) to validate the correctness of model responses"
- Mosaic (satellite imagery): Combining multiple satellite scenes to create a cloud-free, continuous image of a region. "mosaic several low-cloud scenes within each cityâs bounding box"
- Multi-level labels: Annotations that include country, province/state, and city for each image. "we develop multi\textendash level labels that include each imageâs country, province or state, and city."
- Multi-turn interaction: A dialogue or reasoning process spanning multiple steps with tool calls and observations. "integrate seamless tool invocation into multi-turn interaction through reinforcement learning."
- Nuanced evaluation: More fine-grained assessment beyond city-level, often via distance metrics from geocoded predictions. "nuanced evaluation to fully assess models' geolocalization capability."
- Panoramas: Wide-angle composite images (often 360° street-view) converted into planar format for model input. "convert them into planar panoramas by stitching tiles retrieved via the Mapillary API"
- Pixel budget: A cap on the total number of pixels fed to the visual encoder to control computation. "we are setting the initial pixel budget to "
- Policy model: The agent component that generates thoughts/actions based on the current history and observations. "the policy model iteratively produces a thought and an action "
- ReAct-style: A prompting/control pattern that interleaves reasoning (“Thought”) and acting (“Action”) with observations. "We adopt a thoughtâactionâobservation, ReAct-style~\citep{react} pattern of tool calls in multi-turn interactions."
- Reinforcement learning (RL): Training via rewards for correct behavior to improve reasoning and tool use. "followed by a reinforcement learning (RL) stage to further enhance reasoning ability."
- Rule-based verifier: A deterministic checker that matches specific geographic terms to validate responses. "a rule\textendash based verifier for matching specific terms"
- Sentinel-2 Level-2A imagery: Processed satellite data from the Sentinel-2 mission providing corrected surface reflectance. "retrieve recent Sentinel\textendash2 Level\textendash2A imagery for cities worldwide from the Microsoft Planetary Computer"
- Thought–action–observation loop: The iterative cycle where the agent thinks, acts via tools, and processes new observations. "The thoughtâactionâobservation loop terminates when the model decides to present its final answer"
- Tool fail rate: The proportion of erroneous tool calls (e.g., invalid parameters or malformed formats) during training. "The tool fail rate during RL training."
- Tool invocation: The act of calling external tools (e.g., crop/zoom, web search) during the reasoning process. "seamlessly integrates tool invocation within the reasoning loop"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for multimodal tasks. "Recent advances in Vision-LLMs (VLMs) \citep{qwen2, deepseek_vl_v2, internvl2.5} enable deep reasoning"
- Visual grounding: Aligning visual evidence in an image to specific semantic or geographic concepts for reasoning. "requires not only nuanced visual grounding"
- Web-augmented visual reasoning: Reasoning over images enhanced by retrieving and incorporating online information. "This web-augmented visual reasoning process enables GeoVista validate or refine its geolocalization judgments."
- Web search tool: An external service the agent uses to query the internet for relevant information. "a web-search tool to retrieve related web information."
- Web-Search: A tool type that issues queries and returns up to 10 web documents/URLs for reasoning. "Web-Search. The policy model initializes a web search query to retrieve up to 10 relevant information sources from the internet."
Collections
Sign up for free to add this paper to one or more collections.

