LocalSearchBench: Benchmarking Agentic Search in Real-World Local Life Services
Abstract: Recent advances in large reasoning models (LRMs) have enabled agentic search systems to perform complex multi-step reasoning across multiple sources. However, most studies focus on general information retrieval and rarely explores vertical domains with unique challenges. In this work, we focus on local life services and introduce LocalSearchBench, which encompass diverse and complex business scenarios. Real-world queries in this domain are often ambiguous and require multi-hop reasoning across merchants and products, remaining challenging and not fully addressed. As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types. We construct 300 multi-hop QA tasks based on real user queries, challenging agents to understand questions and retrieve information in multiple steps. We also developed LocalPlayground, a unified environment integrating multiple tools for agent interaction. Experiments show that even state-of-the-art LRMs struggle on LocalSearchBench: the best model (DeepSeek-V3.1) achieves only 34.34% correctness, and most models have issues with completeness (average 77.33%) and faithfulness (average 61.99%). This highlights the need for specialized benchmarks and domain-specific agent training in local life services. Code, Benchmark, and Leaderboard are available at localsearchbench.github.io.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LocalSearchBench, a big test (a “benchmark”) to see how well AI assistants can handle real-world, multi-step questions about local life services, like finding restaurants, booking hotels, planning trips, or arranging doctor visits in a city. It also presents a testing playground called LocalPlayground and a search tool called LocalRAG that help simulate what a smart assistant would do in the real world.
Think of it like this: if you ask an AI, “Find a kid-friendly restaurant near a movie theater in Beijing, open after 8 pm, with vegetarian options, and plan how to get there from my hotel,” the AI has to do several steps across different places and rules. This paper builds the data and tools to test whether today’s AIs can handle tasks like that—then measures how well they do.
What questions did the researchers ask?
The researchers focused on three simple questions:
- Can we build a realistic, safe, and rich dataset of local businesses and tasks that reflect real city life?
- How well do current AI models solve complex, multi-step, real-world local tasks?
- Does letting the AI use web search help, and how does the number of steps (conversation rounds) affect its performance?
How did they do their research?
To make the tests realistic, the team built a detailed database and a set of multi-step questions, then created a “playground” where AI models could use tools (like a local search engine and the web) to find answers.
Building a realistic local services database
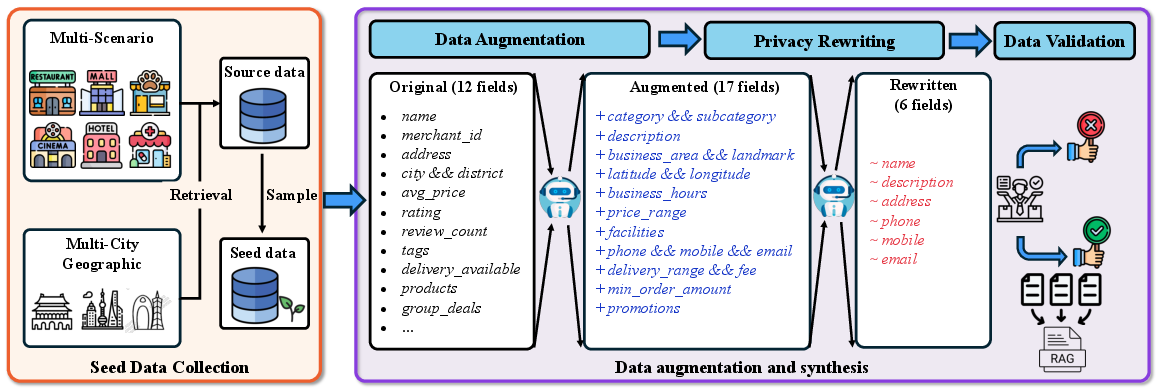
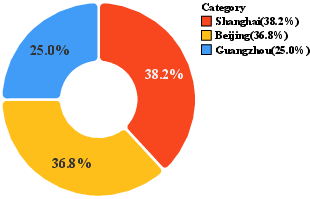
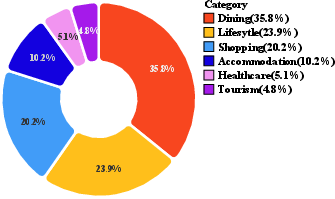
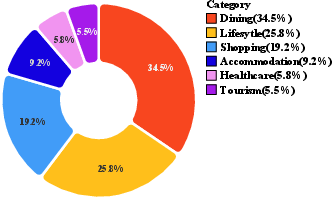
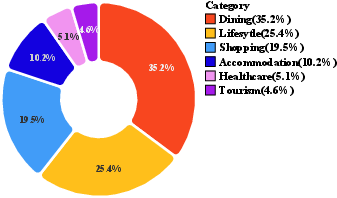
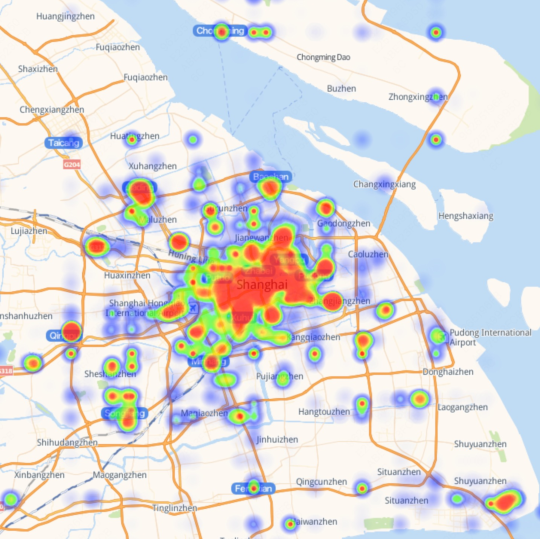
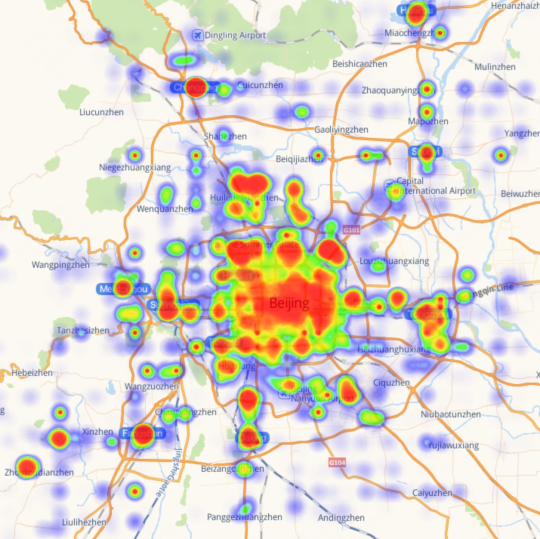
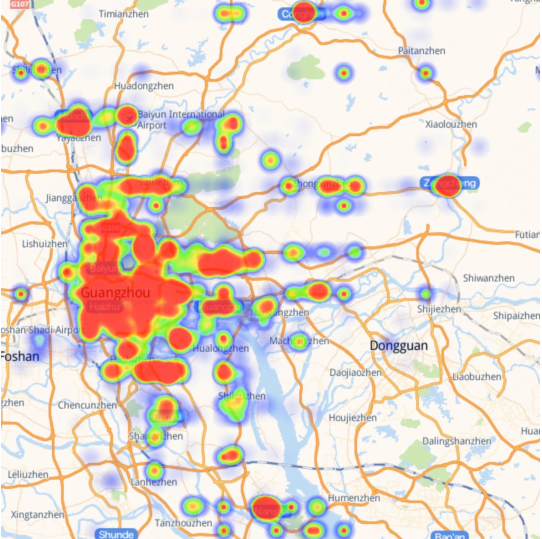
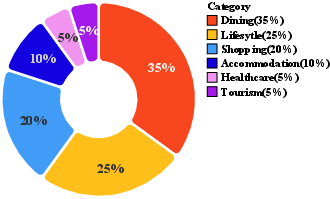
They collected and cleaned real-world business data from three major Chinese cities (Shanghai, Beijing, Guangzhou) across six service categories (dining, lifestyle, shopping, accommodation, healthcare, tourism). After privacy-safe rewriting, they kept 150,031 high-quality, anonymized entries. Each business entry includes useful details like category, location, hours, price range, services, and promotions.
Analogy: Imagine a city guidebook with tens of thousands of shops, each with a neat, standardized profile—but with private details like exact names/contacts safely changed.
Creating multi-step questions
They wrote 300 challenging, multi-step questions based on real user needs, such as:
- Multi-constraint merchant recommendation (e.g., “Find a late-night noodle place within 1 km of this train station, under a certain price, with good ratings”).
- Spatiotemporal planning (e.g., “Have lunch, visit a museum, then get to the airport by 5 pm—plan the chain of stops and times”).
- Event-based bundling (e.g., “It’s raining—find indoor activities and nearby dining deals that fit a tight schedule”).
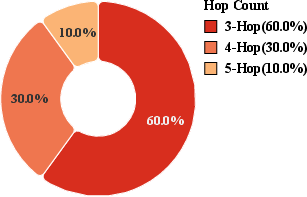
Each question requires 3–5 “hops” (steps), like comparing options, checking distances, and fitting time constraints.
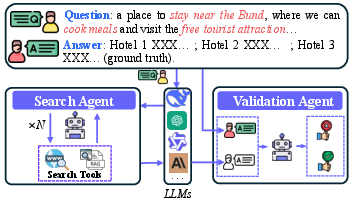
The tools: LocalRAG and LocalPlayground
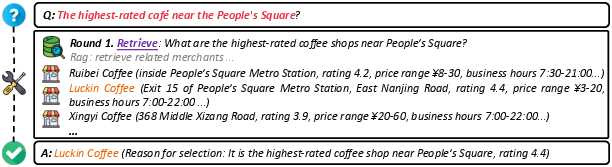
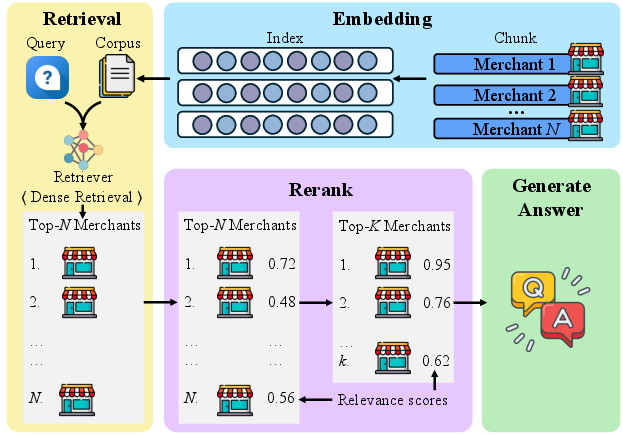
- LocalRAG: A retrieval tool that turns each merchant’s info into a kind of “math map” (vectors) so the AI can find the most relevant businesses by meaning, not just keywords. It first retrieves likely matches, then re-ranks them to pick the best ones.
- LocalPlayground: A test environment where an AI agent can:
- Use LocalRAG and web search (e.g., for live info like weather or news).
- Think and act in several rounds (like asking itself follow-up questions, refining searches, and combining results).
- Get scored by a separate “judge” AI that checks answers for correctness, completeness, clarity, honesty (no made-up facts), and safety.
How they tested AI models
They evaluated 10 well-known AI models. Each model could:
- Do up to 5 reasoning-action rounds per question.
- Call LocalRAG and web search (with limits).
- Be scored on:
- Correctness (did it get the facts right?),
- Completeness (did it cover everything asked?),
- Fluency (is it easy to read?),
- Faithfulness (did it avoid inventing facts?),
- Safety (no harmful content),
- Plus efficiency stats (how many tool calls and rounds).
What did they find?
- Even the best models struggled. The top model got only 34.34% of answers fully correct. That’s low for real-life planning tasks.
- On average, answers were reasonably complete (77.33%), but faithfulness (not making things up) lagged (61.99%). This shows models often “fill gaps” with guesses.
- Adding web search helped and hurt:
- It improved correctness and completeness a bit (more info helps),
- But it reduced faithfulness (extra web noise can tempt models to include unreliable details).
- Closed-source models were slightly better at completeness and efficiency, but overall performance across all models was still far from reliable for complex, real-world local tasks.
Why this matters: Real users often ask complicated, multi-part questions with time, distance, price, and preference constraints. Current AIs aren’t yet reliably solving these.
What does this mean for the future?
- We need specialized training for local-life tasks. General “internet Q&A” training isn’t enough to plan a night out, bundle services, or satisfy strict time and location limits.
- Better tools and guardrails are needed to reduce made-up facts, especially when mixing local databases and open web results.
- Benchmarks like LocalSearchBench are essential to push progress. They give a shared, realistic testbed where researchers can compare methods and improve step by step.
- If the community builds on this, future AI assistants could:
- Plan full city outings with accurate timing and routes,
- Handle personal preferences and budgets,
- Safely combine multiple services (like booking food, transport, and tickets),
- Respect privacy and avoid fabrications.
In short: This paper provides a realistic test and toolkit for building smarter local service assistants. It shows today’s AIs still struggle, but also points the way to making them truly helpful in everyday city life.
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions that can guide future research.
- Geographic generalizability is untested: the benchmark covers only three major Chinese cities; its applicability to other regions (rural areas, different countries, diverse urban forms) and languages remains unknown.
- Domain coverage is incomplete: while six service categories are included, critical cross-domain dependencies (e.g., ride-hailing/public transit APIs, payment/booking, maps/route optimization) are not integrated or evaluated.
- Static offline setting limits realism: the benchmark does not capture dynamic, real-time variables (e.g., inventory/seat availability, wait times, event schedules, weather, surge pricing), constraining evaluation of time-sensitive planning and execution.
- Exclusion of L5 tasks: cross-platform coordination, task execution, and adaptive reflection are intentionally omitted; building a safe “live” evaluation environment for these tasks is an open challenge.
- Synthetic augmentation risks: merchant profiles are expanded by LLMs from 12 to 29 fields without independent ground truth; the impact of hallucinations, fabrication, or stylistic biases on downstream retrieval and reasoning is not quantified.
- Privacy rewriting fidelity: anonymization may distort location/contact semantics; there is no formal privacy guarantee (e.g., k-anonymity, differential privacy) or re-identification risk audit, nor an analysis of how anonymization affects retrieval accuracy.
- Heavy reliance on LLM-as-judge: both data validation and system evaluation depend on a single proprietary judge (Claude-Sonnet-4); judge bias, consistency across judges, and robustness to model families are not assessed.
- Limited human evaluation: a small number of experts and sampled instances are used; inter-annotator agreement, error typologies, and scaling of human verification are not reported.
- Ground-truth answer generation uses proprietary models (GPT-5, Claude-4.1): reproducibility, licensing constraints, and openness of the gold-answer pipeline are not addressed; open-source alternatives and audit trails are needed.
- Size of multi-hop QA is modest (300 items): statistical power, category balance, and representativeness of real-world multi-hop queries (especially longer chains) are not demonstrated.
- Retrieval pipeline is under-explored: no ablation on embedding/reranker choices, chunking strategies, field-aware vs. text-only encoding, top-N/top-K parameters, or their interactions with different LRMs.
- Structural retrieval gap: LocalRAG concatenates structured fields into free text; there is no evaluation of schema-aware retrieval, knowledge graphs, or spatial-temporal indexing tailored to local services.
- Web search scope is narrow: only Baidu is used; cross-engine variability (e.g., Google, Bing), multilingual search, and aggregation strategies are not studied.
- Tool-orchestration constraints: at most one LocalRAG and one web-search call per round, with N=5 rounds; the effects of longer horizons, richer toolboxes (maps, calendars, booking), and adaptive policies (RL/learning-to-search) are unexplored.
- Evidence-grounded evaluation is missing: correctness is binary and faithfulness is judge-scored; there is no required citation alignment, per-hop evidence verification, or provenance tracking to ensure claims are grounded.
- Domain-specific safety is underdefined: safety scoring is generic, without taxonomies for local-life risks (e.g., health advice missteps, discriminatory recommendations, unsafe neighborhood suggestions).
- Personalization gap: no user profiles, histories, budgets, or preference models; evaluation of personalized planning and long-term user constraints is absent.
- Multi-modal omission: images (menus, storefronts), maps, and POI photos—central to local decision-making—are excluded; multimodal retrieval and reasoning are not evaluated.
- Spatiotemporal reasoning fidelity: travel times, routing, schedule feasibility, and constraint satisfaction are not benchmarked against ground-truth maps or timetables.
- Dataset freshness and drift: merchant data is tied to 2025; update cadence, versioning, and longitudinal evaluation under domain drift are not addressed.
- Web-search faithfulness trade-off: while web search improves correctness/completeness, it reduces faithfulness; mitigation strategies (citation enforcement, reliability filters, calibration, source weighting) are not investigated.
- Failure-mode analysis is limited: there is no granular breakdown of error sources (retrieval recall, reranking precision, planning mistakes, tool-use errors, grounding failures) to guide targeted improvements.
- Training strategies are untested: domain-specific finetuning, RL for tool use, curriculum learning for multi-hop tasks, and reflection-based self-correction are proposed but not evaluated.
- Efficiency metrics are sparse: latency, compute cost, and throughput under different tool/round budgets are not analyzed, hindering practical deployment insights.
- Robustness not assessed: performance under ambiguous, noisy, adversarial, or code-switched queries is unknown; stress tests for misspellings, colloquialisms, and dialects are absent.
- Cultural and fairness considerations: bias across neighborhoods, merchant sizes (small vs. large chains), and price bands is not measured; fairness-aware retrieval/recommendation remains open.
- Negative/decoy design: the benchmark lacks “hard negatives” and distractor merchants to test discrimination and calibration under confounders.
- Licensing and data provenance: the release of anonymized data derived from platform M raises questions about legal constraints, reproducibility, and whether entirely synthetic-yet-realistic datasets are needed for fully open benchmarks.
- Real multi-hop session capture: most multi-hop queries are instantiated by annotators; collecting and anonymizing real user multi-hop sessions, clarifications, and tool-invocation traces would improve ecological validity.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with today’s models, data engineering practices, and tool ecosystems, derived directly from the benchmark, the LocalPlayground evaluation framework, the LocalRAG retrieval system, and the data augmentation/privacy pipelines presented in the paper.
- Benchmark-driven search quality assurance for local-life platforms
- Sector: software, e-commerce/local services (food delivery, restaurant discovery, travel, retail, healthcare)
- Tools/products/workflows: adopt LocalSearchBench as a regression and acceptance test suite; integrate LocalPlayground as a CI/CD harness to detect drops in correctness, completeness, and faithfulness across model updates and prompts; build a search-quality dashboard using the paper’s LLM-as-judge metrics
- Assumptions/dependencies: representative coverage for your target cities/verticals; evaluation judge model independence; periodic recalibration with human audits
- Production-grade domain RAG for merchant and POI retrieval (LocalRAG pattern)
- Sector: search/recommendation, marketplaces, mobility, hospitality
- Tools/products/workflows: implement a LocalRAG-like pipeline (structured-to-text formatting → embeddings → vector DB → reranker → tool endpoint for agents); plug into agentic workflows to ground answers with merchant profiles
- Assumptions/dependencies: up-to-date merchant data; appropriate embedding/reranker choices; governance for stale or incomplete entries
- Multi-hop in-app concierge for bundled local services
- Sector: travel and leisure, food and beverage, events, retail
- Tools/products/workflows: deploy an agent that plans “dinner + movie + transport” or “hotel + attractions + dining” by invoking LocalRAG and web search per hop; expose transparent step traces to improve user trust
- Assumptions/dependencies: adequate tool orchestration and timeout policies; fallbacks to rule-based filters; UI affordances for clarifying ambiguous constraints
- Customer support and care triage with tool-use reasoning
- Sector: platform operations, customer service
- Tools/products/workflows: use agentic search to resolve queries like “refund for closed merchant” or “reschedule due to weather”; bind to policy and knowledge bases; log multi-hop tool calls for auditability
- Assumptions/dependencies: API access to policy KBs; safety red-teaming to avoid unsupported commitments; guardrails against hallucinated policies
- Privacy-safe data sharing and internal analytics via the paper’s Privacy Rewriting Agent
- Sector: compliance, data engineering, partnerships
- Tools/products/workflows: operationalize a privacy rewriting SOP to de-identify merchant identity, location granularity, and contact fields while retaining business attributes for model training, sandbox testing, and partner sandboxes
- Assumptions/dependencies: legal review; re-identification risk analysis; periodic privacy audits; versioned transformation logs
- Merchant onboarding and enrichment via Data Augmentation Agent
- Sector: marketplace operations, SMB services
- Tools/products/workflows: fill missing fields (business hours, facilities, tags, promos) and standardize formats to raise retrieval recall/precision; auto-summarize descriptions for embedding
- Assumptions/dependencies: human-in-the-loop validation for sensitive fields (e.g., healthcare); clear error handling for low-confidence augmentation
- Search guardrails and reliability monitoring using LLM-as-judge
- Sector: platform risk, trust & safety
- Tools/products/workflows: run continuous canary tests for faithfulness/completeness; trigger rollback or prompt updates when faithfulness dips; store provenance snippets for post-hoc review
- Assumptions/dependencies: separation of judge and task models; calibration with human raters; cost controls for judge inference
- A/B testing and data generation in a realistic agent sandbox (LocalPlayground)
- Sector: MLOps, product experimentation
- Tools/products/workflows: simulate multi-hop tool-use with capped rounds; collect traces for fine-tuning; compare prompting, reasoning depth, and tool-call budgets
- Assumptions/dependencies: synthetic-to-production gap awareness; throttling to prevent overfitting to benchmark artifacts
- Academic coursework and reproducible research on agentic search
- Sector: academia (IR, NLP, AI planning)
- Tools/products/workflows: course assignments on multi-hop reasoning; ablation studies on embeddings/rerankers; reproducible leaderboards; cross-model evaluations using the paper’s metrics
- Assumptions/dependencies: access to the dataset and tool code; compute quotas; ethical use of anonymized data
- City and campus-life assistants for routine planning
- Sector: daily life, education
- Tools/products/workflows: assistants that plan “lunch near lecture hall plus pharmacy pickup,” or “budget-friendly date near a landmark” using LocalRAG-like retrieval
- Assumptions/dependencies: locale adaptation; preference handling; disclaimers for availability and pricing drift
Long-Term Applications
These require additional research, ecosystem standards, cross-platform integrations, or stronger model reliability than current SOTA results indicate (e.g., the paper reports best correctness at ~34%).
- Cross-platform autonomous booking and execution (L5-style)
- Sector: travel, hospitality, mobility, healthcare
- Tools/products/workflows: end-to-end agents that not only plan but execute bookings, reschedule on failures, and reconcile payments and vouchers across providers
- Assumptions/dependencies: stable third-party APIs; verifiable tool-use; contracts for liability and consumer protection; robust exception handling
- Open standards for local-service APIs and provenance-backed agent reasoning
- Sector: software standards, policy, platform interoperability
- Tools/products/workflows: schema/ontology for merchants, slots, time windows, and constraints; signed citations to enforce faithfulness; interoperable tool-call logs for audits
- Assumptions/dependencies: multi-stakeholder governance; privacy/security norms; adoption by major platforms
- Continual learning and RL for tool-use policies trained in LocalPlayground-like environments
- Sector: AI/ML infrastructure
- Tools/products/workflows: reinforcement learning from search traces and human feedback to reduce unnecessary tool calls and improve correctness under budget
- Assumptions/dependencies: safe exploration; off-policy evaluation; synthetic-to-real generalization; reward hacking mitigation
- Fairness, accessibility, and geographic equity auditing
- Sector: policy/governance, civic tech
- Tools/products/workflows: evaluate whether recommendations skew toward certain districts or price bands; enforce constraints for wheelchair access, dietary needs, and language accessibility
- Assumptions/dependencies: annotated accessibility fields; representative coverage across neighborhoods; fairness metrics aligned with local regulations
- Voice/in-car copilots and AR city guides powered by agentic search
- Sector: automotive, consumer devices, tourism
- Tools/products/workflows: hands-free planning across routes, stops, and bookings; heads-up AR overlays for live itineraries and capacity estimates
- Assumptions/dependencies: robust on-device NLU; multimodal perception; offline fallbacks; low-latency tool calls
- Privacy-preserving training and evaluation via federated or synthetic pipelines
- Sector: compliance, AI research
- Tools/products/workflows: federated embeddings/reranking; privacy-rewriting-by-construction; synthetic city replicas for stress testing without real PII
- Assumptions/dependencies: DP/federated infra; statistical utility targets; privacy budget accounting; regulator alignment
- Agentic negotiation and dynamic bundling with merchants
- Sector: retail, dining, events
- Tools/products/workflows: agents that request group deals, off-peak bundles, or “event-driven service chaining” discounts; merchant-side bots to accept/decline
- Assumptions/dependencies: pricing and offer APIs; anti-collusion safeguards; transparent consumer disclosures
- City-scale planning insights and simulation for tourism and events
- Sector: urban planning, destination management
- Tools/products/workflows: simulate demand flows across landmarks and service chains; test congestion alleviation strategies or event-driven resource allocation
- Assumptions/dependencies: aggregate, privacy-safe mobility data; calibration against real traffic and sales; cross-agency coordination
- Multilingual, cross-cultural expansion of LocalSearchBench-style datasets
- Sector: academia, global platforms
- Tools/products/workflows: localization of categories, norms, and constraints; cross-city/domain transfer learning benchmarks
- Assumptions/dependencies: culturally accurate annotations; regional regulatory approvals; language coverage and evaluation parity
- Household “errand orchestrator” and healthcare journey companion
- Sector: daily life, healthcare
- Tools/products/workflows: orchestrate multi-stop errands (groceries, pharmacy, repair shop) with time windows; coordinate referrals, clinic visits, and medication pickups respecting insurance and eligibility constraints
- Assumptions/dependencies: secure access to calendars/health data; strict privacy and consent; integration with provider/insurer APIs
Notes on feasibility and risk across applications:
- Data freshness and coverage: merchant data must be updated and validated to avoid stale recommendations.
- Model reliability: current faithfulness and correctness limitations require human-in-the-loop, citations, and fallback rules.
- Legal/privacy: de-identification and data minimization are prerequisites for sharing and model training; jurisdiction-specific rules apply.
- Tool/API fragility: cross-platform orchestration depends on stable, well-documented APIs and clear error semantics.
- User trust: expose provenance, provide cost/time estimates, and clarify uncertainties or assumptions in multi-hop plans.
Glossary
- Adaptive reflection: An agent’s ability to revise plans based on outcomes and errors during execution. "L5 (AGI) for cross-platform coordination with adaptive reflection."
- AGI: Artificial General Intelligence; a level of intelligence exhibiting broad, cross-domain capability and autonomy. "L5 (AGI) for cross-platform coordination with adaptive reflection."
- Agentic search: AI systems that autonomously plan, query tools, and synthesize information to solve complex search tasks. "As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types."
- Anonymization Degree: A measure of how thoroughly sensitive information is anonymized in data. "Anonymization Degree (50% weight) ensuring complete merchant identity anonymization including name deidentification, location sanitization, and contact information anonymization;"
- Approximate nearest neighbor retrieval: Fast search technique that finds vectors close to a query in high-dimensional space without exact computation. "with cosine similarity-based search capabilities for fast approximate nearest neighbor retrieval, implementing dense retrieval methodology."
- Closed-ended QA: Question answering tasks with well-defined, objective answers. "Existing benchmarks for agentic search systems in general domain can be broadly categorized into closed-ended and open-ended QA tasks."
- Cosine similarity: A metric that measures the cosine of the angle between two vectors to determine similarity. "with cosine similarity-based search capabilities for fast approximate nearest neighbor retrieval, implementing dense retrieval methodology."
- Cross-platform coordination: Orchestrating actions and data across multiple systems or services to complete a task. "L5 (AGI) for cross-platform coordination with adaptive reflection."
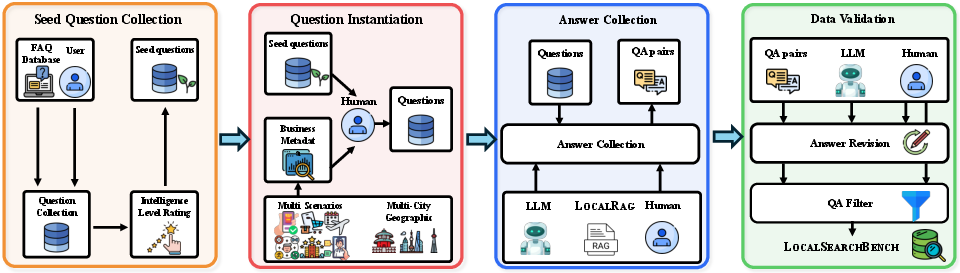
- Data Augmentation Agent: An LLM-powered component that enriches sparse records with additional structured fields. "We employ a Data Augmentation Agent to expand these 12-field records into 29-field profiles using LLMs across six dimensions (see Figure~\ref{fig:seed} and Figure~\ref{fig:prompt1})."
- Decoding temperature: A parameter controlling randomness in model output generation. "LRMs decoding temperature set to 0 to ensure reproducibility."
- Dense retrieval: Retrieval method using learned embeddings to match queries and documents in vector space. "with cosine similarity-based search capabilities for fast approximate nearest neighbor retrieval, implementing dense retrieval methodology."
- Embedding model: A model that converts text or structured data into high-dimensional vector representations for similarity search. "LocalRAG employs a state-of-the-art embedding model to convert merchant information into high-dimensional vector representations."
- Event-driven service bundling: Combining multiple services based on events or triggers to fulfill complex user needs. "real-world user queries often involve multi-constraint merchant recommendation, spatiotemporal service chain planning, and event-driven service bundling"
- Faithfulness: The degree to which a model’s response avoids fabricated or hallucinated content and adheres to evidence. "most models have issues with completeness (average 77.33\%) and faithfulness (average 61.99\%)."
- Geographical proximity analysis: Evaluating spatial closeness between entities (e.g., merchants and landmarks) to improve relevance. "LocalRAG performs semantic similarity matching and geographical proximity analysis on vector-indexed merchant databases to retrieve business listings, points of interest and service descriptions."
- Geospatial inference: Deriving spatial patterns or distributions from location data. "The geographical distribution of merchant data for each city was derived through geospatial inference to generate latitude-longitude heatmaps"
- Golden answer: The reference ground-truth answer used for evaluation. "Given the generated outputs and the golden answer, an LLM (specifically Claude-Sonnet-4~\cite{anthropic2025claude4} in our experiments) evaluates answer quality across seven dimensions"
- Grounded question instances: Questions instantiated with specific real-world context (e.g., city, merchants) to ensure realism. "This process generates 300 grounded question instances."
- Hop count: The number of reasoning and retrieval steps required to answer a question. "For each question, annotators document the hop count, the retrieval target of each hop, and the required search tool (Web Search or LocalRAG) for each hop"
- LLM-as-a-Judge: Using a LLM to evaluate outputs across defined criteria. "A Validation Agent, implemented as an LLM-as-a-Judge framework, conducts a comprehensive, two-stage quality assessment"
- Local life services: Location-based commerce and services such as dining, shopping, accommodation, travel, and healthcare. "Local life services cover a wide range of sub-domains, including dining, lifestyle, shopping, accommodation, travel, and healthcare"
- LocalRAG: A specialized RAG system and tool interface built on the merchant dataset for local search tasks. "we further construct a comprehensive Retrieval-Augmented Generation (RAG) system, which we term LocalRAG"
- LocalSearchBench: A benchmark for evaluating agentic search in local life service scenarios. "As the first comprehensive benchmark for agentic search in local life services, LocalSearchBench includes over 150,000 high-quality entries from various cities and business types."
- Long-horizon questions: Queries requiring extended reasoning steps or long-term dependencies to resolve. "challenging QA benchmarks designed for long-horizon questions with long-tail knowledge"
- Long-tail knowledge: Rare or infrequent facts that are hard to encounter in typical training data. "challenging QA benchmarks designed for long-horizon questions with long-tail knowledge"
- Multi-agent data generation process: A pipeline where multiple agents collaborate to produce complex datasets or tasks. "These multi-hop QA tasks are constructed through a multi-agent data generation process, requiring agents to perform complex reasoning across multiple information sources and reasoning steps."
- Multi-constraint merchant recommendation: Suggesting merchants that satisfy several simultaneous user constraints. "real-world user queries often involve multi-constraint merchant recommendation, spatiotemporal service chain planning, and event-driven service bundling"
- Multi-hop QA: Question answering that requires multiple sequential retrieval and reasoning steps. "We construct 300 multi-hop QA tasks based on real user queries, challenging agents to understand questions and retrieve information in multiple steps."
- o1-style reasoning process: A reasoning paradigm inspired by OpenAI’s o1 approach, emphasizing stepwise problem solving. "~\citet{li2025search} first proposed integrating the agentic search workflow into the o1-style reasoning process of LRMs to achieve autonomous knowledge supplementation."
- Open-ended QA: Question answering tasks with broad, exploratory answers rather than single facts. "Existing benchmarks for agentic search systems in general domain can be broadly categorized into closed-ended and open-ended QA tasks."
- Privacy Rewriting Agent: An agent that anonymizes sensitive fields while preserving utility of data. "we employ a Privacy Rewriting Agent on the augmented data (see Figure~\ref{fig:prompt2})."
- Reinforcement learning: Training approach where models learn via reward signals to improve decision sequences. "~\citet{li2025webthinker}, ~\citet{jin2025search}, and ~\citet{song2025r1} further enhanced the autonomous search capabilities of LLMs by applying reinforcement learning, enabling the models to generate queries and invoke external retrieval systems during reasoning."
- Reranking model: A model that refines initial retrieval results by scoring candidate relevance more precisely. "then applies a specialized reranking model to perform fine-grained relevance scoring between the query and these candidates."
- Retrieval-Augmented Generation (RAG): A framework that augments generation with retrieved evidence. "we further construct a comprehensive Retrieval-Augmented Generation (RAG) system, which we term LocalRAG"
- Semantic similarity matching: Comparing representations to find semantically related items beyond exact keyword overlap. "LocalRAG performs semantic similarity matching and geographical proximity analysis on vector-indexed merchant databases"
- Similarity retrieval: Retrieving items based on their similarity to a query in embedding space. "LocalRAG consists of three core components: vector embedding generation, similarity retrieval, and result reranking"
- Vector database: A storage and index system for embeddings enabling fast similarity search. "The generated embeddings are organized in an indexed vector database with cosine similarity-based search capabilities"
- Vector embedding generation: The process of creating vector representations of data for retrieval tasks. "LocalRAG consists of three core components: vector embedding generation, similarity retrieval, and result reranking"
- Web search APIs: Interfaces to search engines that provide programmatic access to web results. "integrating multiple auxiliary tools to autonomously perform interactive generation through search tools (, web search APIs or external databases) for handling complex search tasks."
Collections
Sign up for free to add this paper to one or more collections.

