- The paper presents a non-intrusive pipeline using graphics API interception to extract synchronized RGB images and multiple G-buffer channels from AAA game footage.
- The approach achieves significant quantitative improvements in inverse rendering benchmarks (e.g., MPI-Sintel, Black Myth: Wukong) with reduced error metrics across depth, normal, and material predictions.
- The dataset enables advanced applications like video relighting and game editing, ensuring robust generalization and high-fidelity rendering in complex, dynamic, real-world scenes.
Generative World Renderer: A Large-Scale Bidirectional Dataset and Pipeline for Real-World Generative Rendering
Introduction and Motivation
The paper "Generative World Renderer" (2604.02329) introduces a large-scale, high-fidelity dataset and an efficient data collection pipeline tailored for bidirectional generative rendering tasks—specifically, forward rendering (RGB synthesis from scene attributes) and inverse rendering (decomposing observed RGB images into geometry, materials, and lighting). This work is motivated by the insufficient realism, diversity, and temporal coherence present in prior synthetic datasets, which fundamentally limit generalization to complex, “in-the-wild” video scenarios.
The dataset consists of 4 million continuous frames (720p/30 FPS) collected from modern AAA games (Cyberpunk 2077, Black Myth: Wukong), paired with synchronized RGB and five G-buffer channels, under varied environments and challenging conditions such as adverse weather and motion blur. The scale, continuous nature, and domain diversity of the dataset is designed to address longstanding sim-to-real gaps in generative video rendering tasks.

Figure 1: The dataset comprises high-resolution RGB videos with aligned G-buffers, capturing continuous, dynamic, and diverse visual sequences.

Figure 2: Existing methods struggle with real-world effects; the proposed dataset provides scene-level supervision that generalizes to complex, long-range, dynamic, and photorealistic sequences.
Dataset Construction and Pipeline Design
The core technical contribution is a scalable, non-intrusive curation pipeline that leverages graphics API interception (via ReShade) and a dual-screen compositing and capture strategy. Intermediate G-buffers (albedo, normal, depth, metallic, roughness) are extracted at runtime without engine modifications or asset extraction, ensuring both legal compliance and broad generalizability.
A multi-stage semi-automated filtering process pairs ReShade with offline RenderDoc inspection to reliably identify and export relevant G-buffers. Materials channels are spatially separated to minimize inter-channel contamination, and motion blur is synthetically generated via frame interpolation (RIFE) to match real-world imaging artifacts.
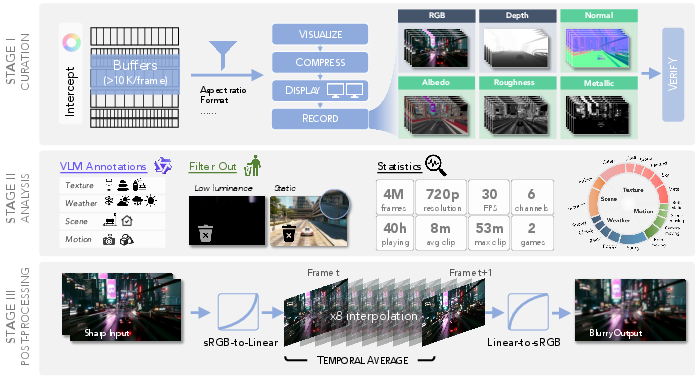
Figure 3: Data pipeline for capturing and verifying high-resolution, multi-channel video sequences from games using runtime graphics API interception and multi-stage filtering.
Clip meta-information—including weather, scene type, motion status, and material appearance—is automatically annotated using a vision-LLM (Qwen3-VL-235B-A22B-Instruct), enabling detailed analysis of data diversity and material distributions.
Quantitative and Qualitative Evaluation
Comprehensive experiments demonstrate the efficacy of the dataset for inverse rendering. Fine-tuning state-of-the-art video inverse rendering models (DiffusionRenderer) on this data yields robust generalization to new domains, outperforming prior models on held-out AAA game data and synthetic benchmarks such as MPI-Sintel, particularly with respect to depth, normal, albedo, metallic, and roughness predictions.
Strong quantitative improvements are observed:
- On the Black Myth: Wukong test set, the proposed approach achieves lower Abs Rel, RMSE, and RMSE-log for depth; improved normal and albedo scores (including scale-invariant metrics); and substantially reduced RMSE/MAE for both metallic and roughness channels compared to DiffusionRenderer and other recent baselines.
- On MPI-Sintel, the model fine-tuned on this data outperforms all others on depth and albedo, establishing a new performance standard for inverse rendering with scale-invariant assessment.
Qualitative results further highlight improved material separation, accurate geometry recovery, and resilience to confounding factors such as smoke, illumination change, and volumetric effects.

Figure 4: Inverse rendering performance comparison on real-world data; the proposed model yields cleaner, artifact-resistant decomposition across modalities.
Real-World and Human-Centric Evaluation
Recognizing the lack of ground-truth labels in real-world videos, the authors introduce a VLM-based protocol using Gemini 3 Pro for human-aligned semantic, spatial, and temporal assessment of material property predictions. User studies with domain experts demonstrate high agreement with VLM rankings, validating this scalable evaluation methodology.
Motion augmentation is found to further improve consistency and reduce artifacts (blurring, temporal flicker) in high-motion scenes.

Figure 5: Additional qualitative comparison, verifying robust inverse rendering in diverse, in-the-wild scenes.
Applications: Relighting and Editing
The dataset enables noteworthy advances in practical applications:
- Video Relighting: Forward renderers driven by improved (dataset-trained) G-buffers yield high-fidelity novel relit sequences even under challenging outdoor, highly dynamic, and volumetric effects scenarios.

Figure 6: Video relighting driven by G-buffer outputs, demonstrating robust adaptation to new environmental illumination.
- Game Editing: The pipeline supports text-driven scene editing in AAA game footage. By conditioning on accurate G-buffers, the model can efficiently manipulate style attributes such as lighting, weather, and visual effects while maintaining geometry and material fidelity, outperforming ControlNet, SDEdit, and physics-based baselines in both fidelity and editability.

Figure 7: Game editing with controllable lighting, weather, and style manipulation enabled by G-buffer conditioning.
Implications and Future Directions
This work provides a substantial empirical foundation for bidirectional video rendering under realistic conditions. The methodology and dataset:
- Bypass the need for scene- or asset-level engine access, enabling scalable expansion to other graphical domains.
- Directly address domain transfer and generalizability challenges for neural rendering architectures by providing high-fidelity, pixel-aligned, temporally continuous supervision.
- Establish a practical evaluation paradigm with human-aligned VLM judgments, essential for robust, real-world deployment.
In future development, the dataset and open-sourced pipeline should facilitate both advances in foundation models for video rendering and new lines of research in controllable, physically-grounded generative editing. The non-intrusive extraction strategy and continuous, multi-modal nature of the data render it suitable for training generalist video foundation models, studying long-range temporal consistency, and developing more effective model-based disentanglement methods.
Conclusion
The introduction of the Generative World Renderer dataset and pipeline marks a key advance in the scaling and generalization of bidirectional rendering for real-world video. Extensive evaluation shows that this resource closes significant gaps in scene coverage, modality diversity, and temporal coherence, enabling robust, physically grounded inverse and forward rendering that generalizes across domains. The synthetic-to-real domain gap is substantially narrowed, with both quantitative and qualitative improvements in controllable generation and editing tasks. This work provides a critical resource and methodological blueprint for next-generation generative world modeling.