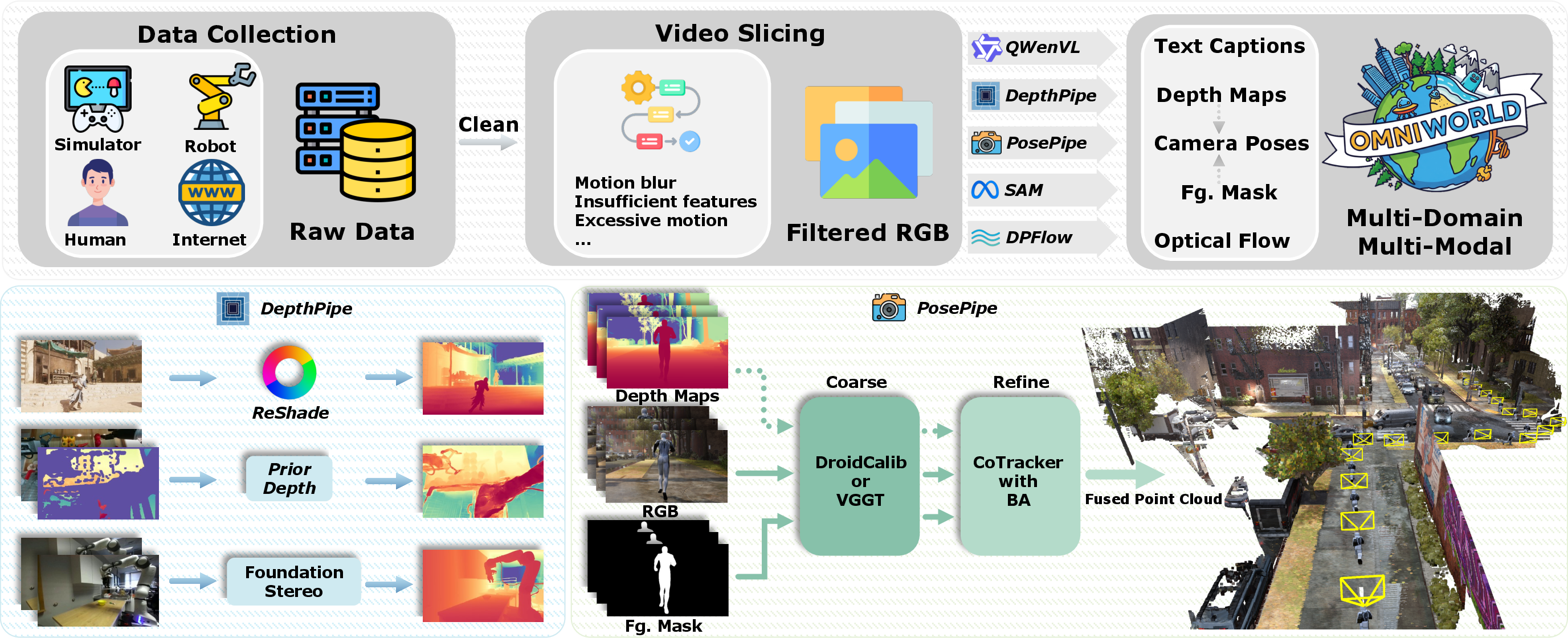
- The paper introduces OmniWorld, a comprehensive dataset integrating synthetic and real-world multi-modal data for robust 4D world modeling.
- The methodology leverages advanced acquisition techniques and a modular annotation pipeline to generate high-fidelity depth, optical flow, and camera pose data.
- Benchmarking shows that fine-tuning SOTA models on OmniWorld improves performance in monocular and video depth estimation while revealing limitations in dynamic scene handling.
OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling
Introduction and Motivation
The OmniWorld dataset addresses a critical bottleneck in the development of general-purpose 4D world models: the lack of large-scale, multi-domain, and multi-modal data with rich spatio-temporal annotations. Existing datasets for 3D geometric modeling and camera control video generation are limited by short sequence lengths, low dynamic complexity, and insufficient modality coverage, which restricts the evaluation and training of models capable of holistic world understanding. OmniWorld is designed to overcome these limitations by providing a comprehensive resource that integrates high-quality synthetic data with curated public datasets across simulator, robot, human, and internet domains.

Figure 1: OmniWorld provides a large-scale, multi-domain, multi-modal resource for 4D world modeling, including depth, camera pose, text, optical flow, and foreground mask annotations.
Data Acquisition and Annotation Pipeline
OmniWorld's acquisition pipeline combines self-collected synthetic data from game environments with public datasets representing diverse real-world scenarios. The synthetic subset leverages tools such as ReShade for precise depth extraction and OBS for synchronized RGB capture, enabling high-fidelity, temporally consistent multimodal data. Public datasets are integrated to cover robot manipulation, human activities, and in-the-wild internet scenes, with additional annotation for modalities missing in the originals.
The annotation pipeline is modular and domain-adaptive, providing:
Dataset Composition and Diversity
OmniWorld comprises 12 heterogeneous datasets, totaling over 600,000 video sequences and 300 million frames, with more than half at 720P or higher resolution. The dataset is annotated with five key modalities, enabling comprehensive spatio-temporal modeling. The human domain constitutes the largest share, reflecting real-world activity diversity. Scene types span outdoor-urban, outdoor-natural, indoor, and mixed environments, with a predominance of first-person perspectives and coverage of ancient, modern, and sci-fi eras. Object diversity is high, with natural terrain, architecture, vehicles, and mixed elements.
Text annotations are notably dense, with most captions containing 150–250 tokens, surpassing existing video-text datasets in descriptive richness.
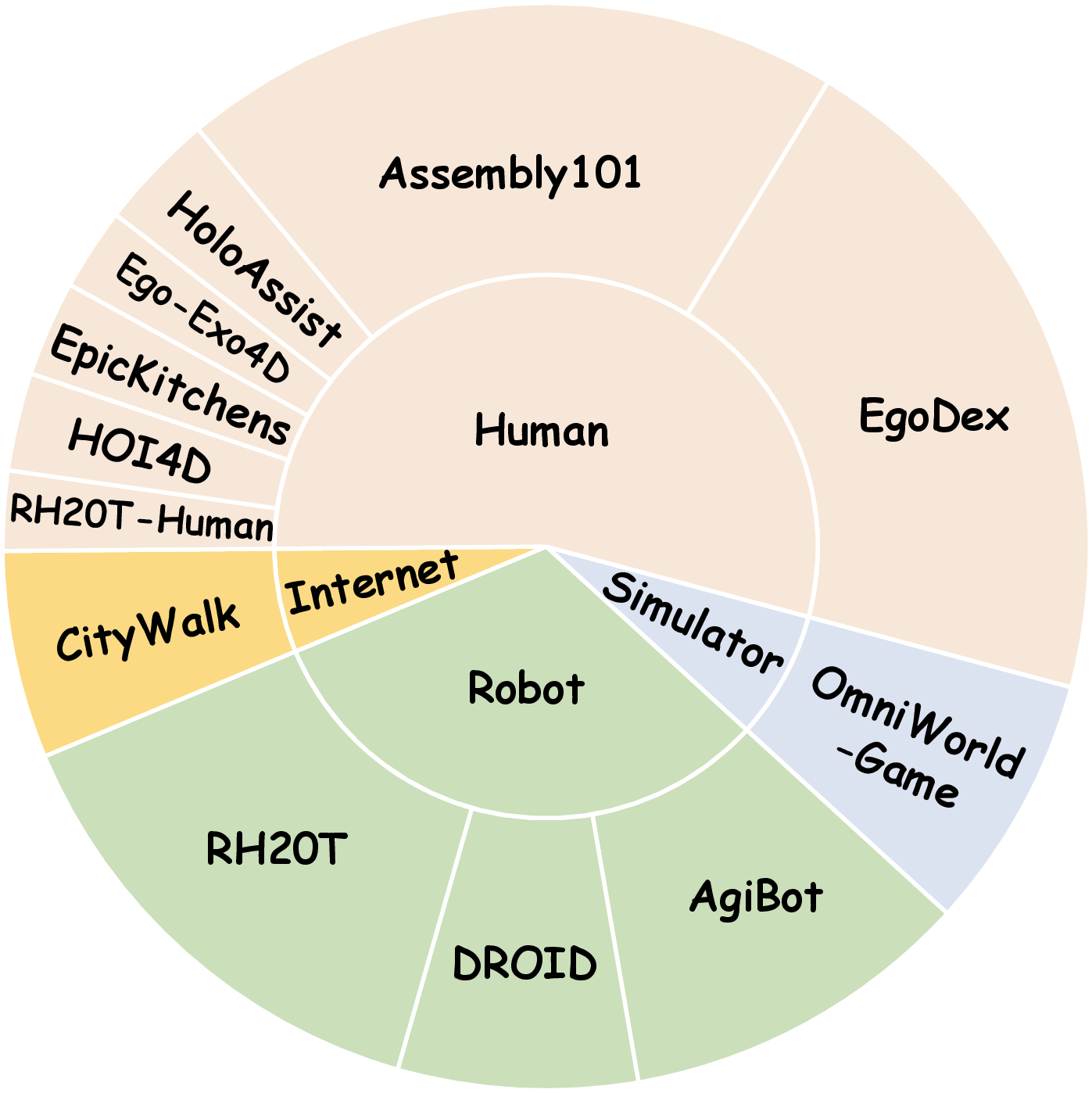
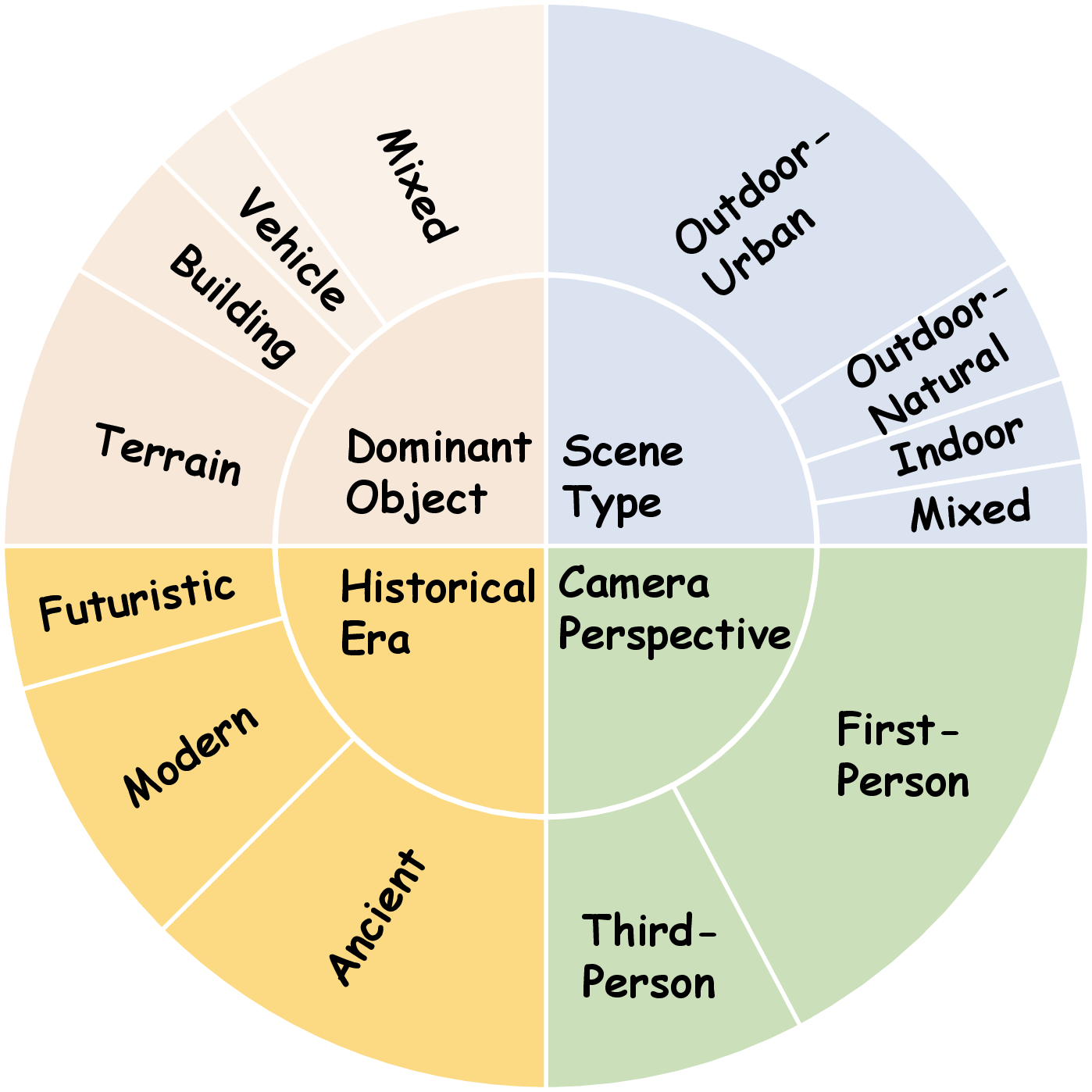
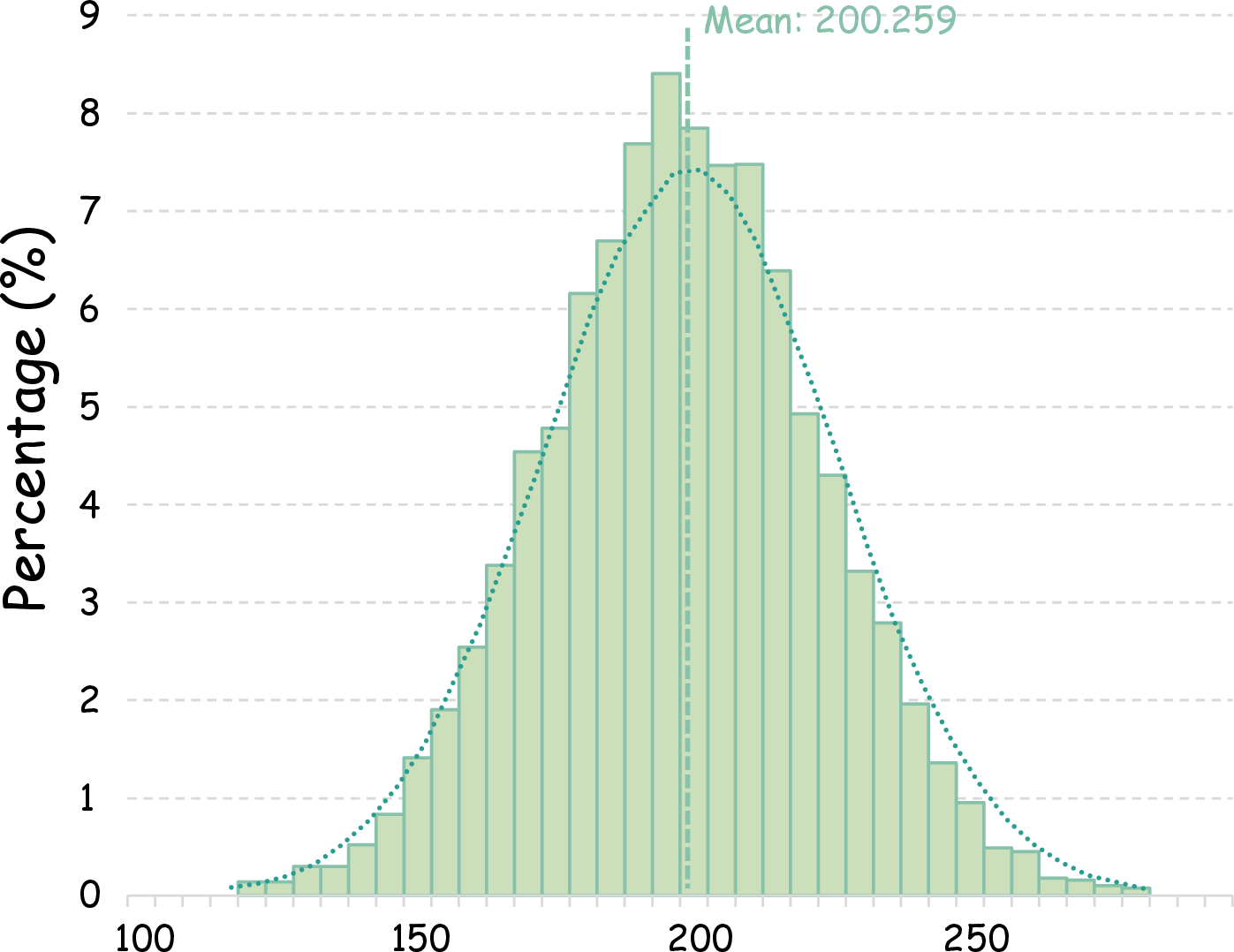
Figure 3: OmniWorld's compositional distribution highlights domain diversity and internal scene complexity.
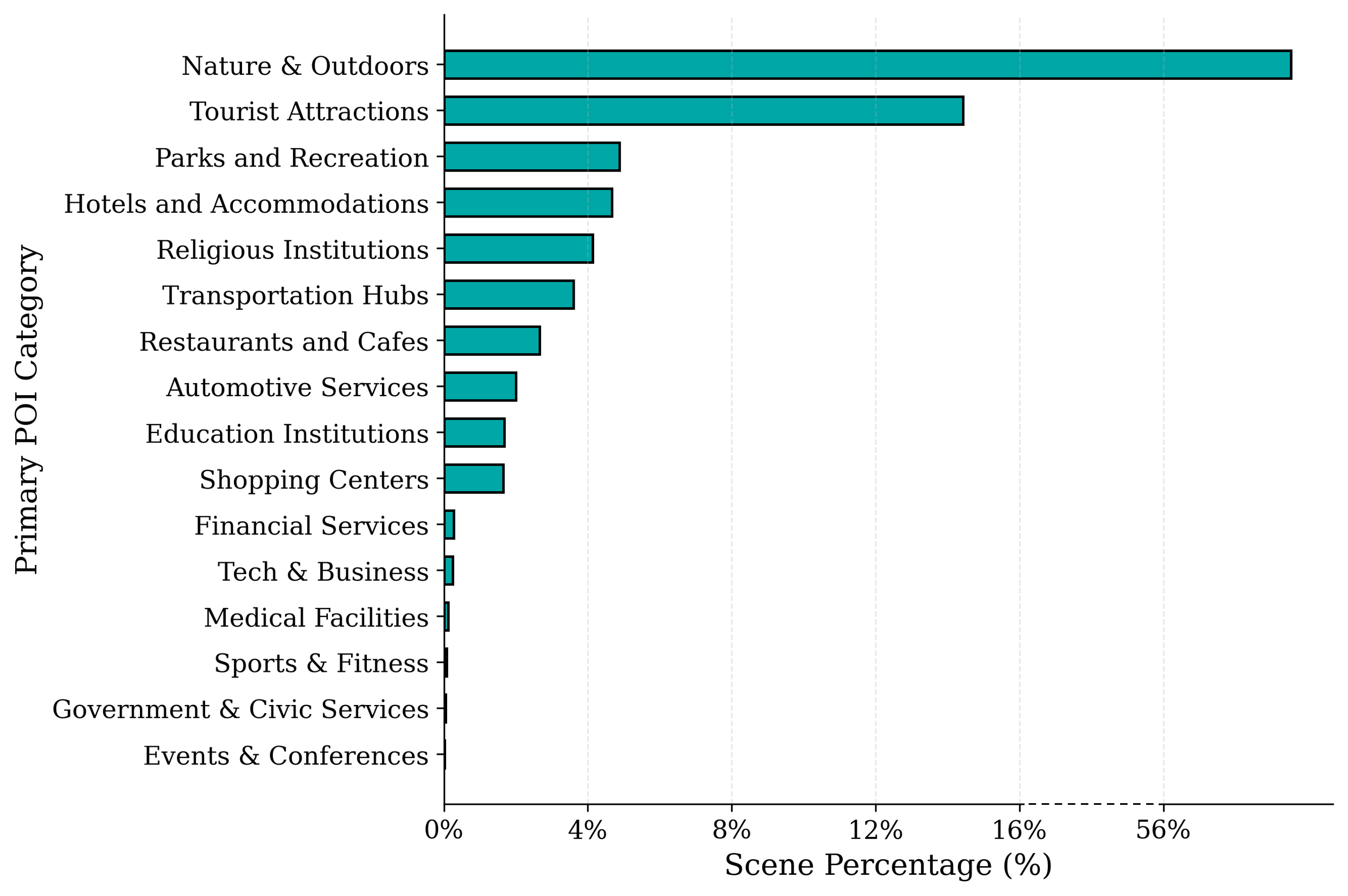
Figure 4: Distribution of scene categories (primary POI locations) in OmniWorld, demonstrating coverage of real-world environments.
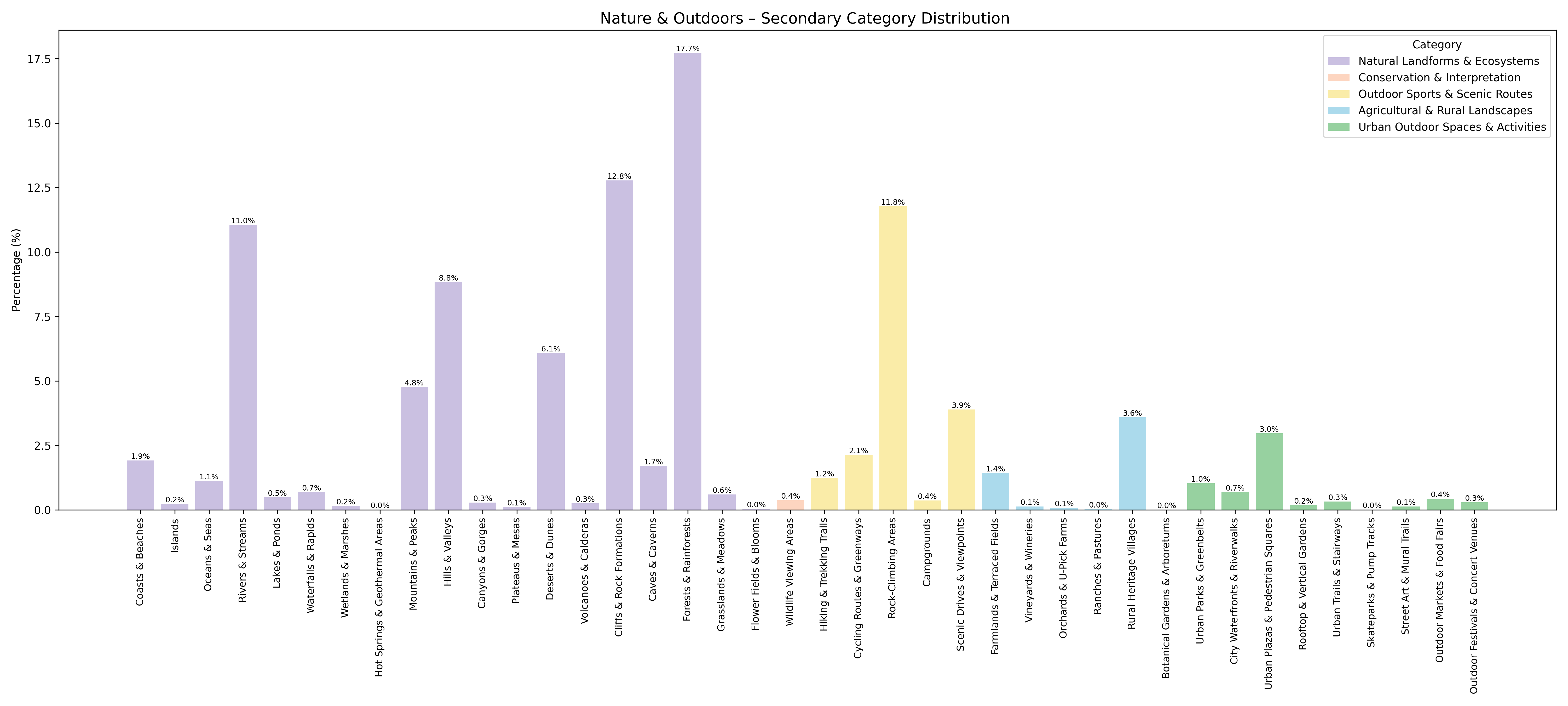
Figure 5: Internal diversity within the "Nature Outdoors" category, with quantitative breakdowns of second- and third-level scene types.
Benchmarking 3D Geometric Foundation Models
OmniWorld establishes a challenging benchmark for 3D geometric prediction, featuring long sequences (up to 384 frames), high dynamic complexity, and high-resolution data. Evaluated models include DUSt3R, MASt3R, MonST3R, Fast3R, CUT3R, FLARE, VGGT, and MoGe variants. Tasks include monocular and video depth estimation, with images resized to a long side of 512 pixels.
Key findings:
- Monocular depth estimation: MoGe-2 achieves the best accuracy, but all models show substantial room for improvement, indicating the benchmark's difficulty.
- Video depth estimation: VGGT outperforms others in both scale-only and scale-and-shift alignments, with high FPS, but no model excels across all metrics, revealing limitations in handling long, dynamic sequences.

Figure 6: Visual results of monocular depth estimation on OmniWorld, with MoGe-2 producing sharp, accurate depth maps.

Figure 7: Qualitative comparison of multi-view 3D reconstruction, showing VGGT's superior temporal consistency but persistent artifacts in dynamic scenes.
Benchmarking Camera Control Video Generation
The camera control video generation benchmark in OmniWorld features dynamic content, diverse scenes, complex camera trajectories, and multi-modal inputs. Evaluated models include AC3D (T2V), CamCtrl, MotionCtrl, and CAMI2V (I2V). Metrics include camera parameter errors and Fréchet Video Distance (FVD).
Key findings:
Model Fine-Tuning and Efficacy Validation
Fine-tuning SOTA models on OmniWorld yields consistent and significant performance improvements across monocular depth estimation, video depth estimation, and camera control video generation. For example, fine-tuned DUSt3R and CUT3R outperform their original baselines and even surpass models fine-tuned on multiple dynamic datasets. AC3D, when fine-tuned on OmniWorld, shows marked gains in camera trajectory adherence and temporal consistency.

Figure 9: Qualitative comparison of DUSt3R and CUT3R before and after fine-tuning on OmniWorld, with improved geometric detail and depth accuracy.

Figure 10: Visual comparison of AC3D before and after fine-tuning, demonstrating enhanced camera trajectory following and object consistency.
Implications and Future Directions
OmniWorld sets a new standard for multi-domain, multi-modal datasets in 4D world modeling. Its scale, diversity, and annotation richness enable rigorous evaluation and training of models for spatio-temporal understanding, geometric prediction, and controllable video generation. The strong empirical results from fine-tuning SOTA models underscore the dataset's value as a training resource.
Practically, OmniWorld facilitates the development of models capable of robust generalization to complex, dynamic environments, with direct applications in robotics, autonomous systems, and interactive AI. Theoretically, the dataset exposes current limitations in spatio-temporal consistency, modality integration, and long-term prediction, guiding future research toward more holistic and scalable world models.
Conclusion
OmniWorld provides a comprehensive, multi-domain, multi-modal dataset for 4D world modeling, addressing critical gaps in existing resources. Its challenging benchmarks reveal the limitations of current SOTA models, while fine-tuning experiments demonstrate substantial gains in performance and robustness. OmniWorld is poised to accelerate progress in general-purpose world modeling, supporting both practical deployment and theoretical advancement in AI systems capable of understanding and interacting with the real physical world.