- The paper introduces 4D-GRT, a novel framework combining 4D Gaussian Splatting with differentiable ray tracing to simulate diverse camera effects in dynamic scenes.
- It achieves superior performance by delivering high-fidelity results and improved rendering speeds across effects such as fisheye, rolling shutter, and depth of field.
- Experimental results demonstrate that 4D-GRT sets new benchmarks in both quality and efficiency compared to existing dynamic NeRF-based methods.
4D Gaussian Ray Tracing for Physics-based Camera Effect Data Generation
Introduction and Motivation
The paper introduces 4D Gaussian Ray Tracing (4D-GRT), a framework for generating physically accurate, controllable camera effects in dynamic scenes. The motivation stems from the limitations of conventional computer vision systems, which typically assume ideal pinhole cameras and lack robustness to real-world camera effects such as fisheye distortion, rolling shutter, and depth of field. Existing synthetic data generation approaches, including physics-based renderers and generative models, either incur high costs, suffer from sim-to-real gaps, or fail to accurately model camera effects, especially in dynamic scenes. 4D-GRT addresses these deficiencies by combining 4D Gaussian Splatting (4D-GS) with differentiable ray tracing, enabling efficient and high-fidelity simulation of diverse camera effects.
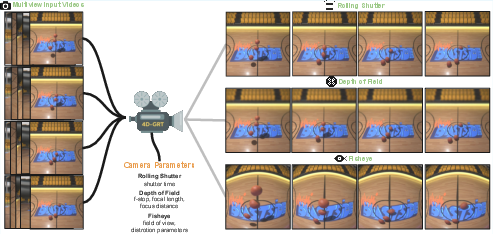
Figure 1: 4D-GRT pipeline overview: multi-view video input is reconstructed into a dynamic scene via 4D-GS and differentiable ray tracing, then rendered with controllable camera effects.
The work builds on advances in neural rendering, particularly NeRF and Gaussian Splatting. While NeRF-based methods can model light transport and simulate camera effects, they are computationally expensive and less efficient for dynamic scenes. 3D Gaussian Splatting offers real-time rendering but is limited to pinhole camera models and requires complex extensions for camera effects. Recent works such as 3DGRT and 3DGUT enable ray tracing over Gaussian primitives for static scenes, but lack support for dynamic scenarios. 4D-GRT is the first to integrate dynamic Gaussian scene representations with physically-based ray tracing, supporting a wide range of camera effects in dynamic environments.
Methodology
Dynamic Scene Reconstruction
The first stage reconstructs dynamic scenes from synchronized multi-view videos using a 4D-GS model. The scene is represented as a set of 3D Gaussians and a Gaussian deformation field network, which models per-frame deformations via spatio-temporal encoding and multi-head MLPs. Differentiable ray tracing is employed for rendering, leveraging a $k$-buffer hit-based marching scheme and hardware-accelerated OptiX interface for efficiency and accuracy.
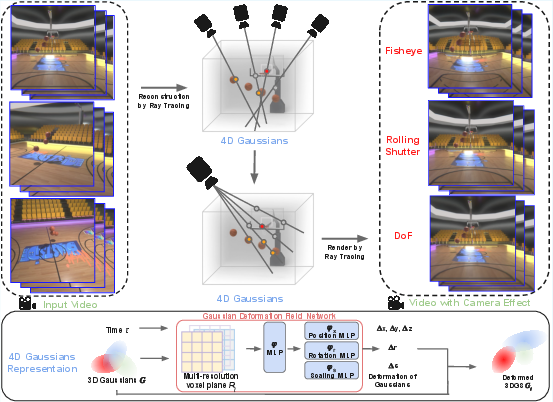
Figure 2: Model pipeline: multi-view videos are used to optimize the 4D-GS representation, which is then rendered with physically-correct camera effects via ray tracing.
Training is performed end-to-end with a color loss and total variation regularization. The loss function is:
$\mathcal{L} = \mathcal{L}_1(C_{v, t}, \hat{C}_{v, t}) + \mathcal{L}_{\mathrm{TV}}$
where $\mathcal{L}_1$ is the L1 loss between rendered and ground-truth images, and $\mathcal{L}_{\mathrm{TV}}$ is a grid-based total variation loss.
Camera Effect Rendering
After reconstruction, camera effects are synthesized by integrating physical camera models into the ray-tracing renderer:
Experimental Evaluation
Dataset Construction
A synthetic benchmark dataset was constructed in Blender 4.5, comprising 8 dynamic indoor scenes across 4 environments, each rendered from 50 viewpoints under four camera effects (pinhole, fisheye, rolling shutter, depth of field). This dataset enables controlled evaluation of camera effect simulation in dynamic scenes.
Baseline Comparison
4D-GRT is compared against HexPlane and MSTH, state-of-the-art dynamic NeRF methods capable of 4D scene reconstruction and ray tracing. All methods use the same camera effect rendering module for consistency.
Quantitative Results
4D-GRT achieves the highest rendering speed across all camera effects, with competitive or superior image quality:
- Pinhole: PSNR 32.80 dB, SSIM 0.8898, LPIPS 0.1018, FPS 36.56
- Depth of Field: PSNR 31.25 dB, SSIM 0.9124, LPIPS 0.1210, FPS 3.44
- Fisheye (masked): PSNR 28.89 dB, SSIM 0.8555, LPIPS 0.1259, FPS 41.53
- Rolling Shutter (1 row): PSNR 31.61 dB, SSIM 0.8821, LPIPS 0.1056, FPS 0.76 (scales to 13.54 FPS with 16-row chunking)
The rendering speedup is attributed to hardware-accelerated Gaussian ray tracing, while quality gains stem from the continuous 4D-Gaussian representation. Storage and training time are reasonable, with 4D-GRT balancing efficiency and fidelity.
Qualitative Results
































































Figure 4: Qualitative comparison on synthetic datasets; artifacts in baseline methods are highlighted.
4D-GRT demonstrates higher-fidelity reconstructions and more accurate camera effect simulation compared to baselines. HexPlane exhibits inferior reconstruction quality, while MSTH suffers from color temperature misalignment and artifacts absent in 4D-GRT outputs.




















Figure 5: Qualitative results of 4D-GRT on the Neural 3D Video dataset, showing effect-aware rendering in real-world dynamic scenes.
Evaluation of Commercial Video Generation Models
State-of-the-art video generation models (Sora, Veo 3, HunyuanVideo, Seedance 1.0 Mini) were evaluated for camera effect awareness. Results indicate limited physical fidelity and poor compliance with camera parameters:
- Fisheye: Only Sora produces recognizable fisheye imagery; others fail to respect lens parameters.
- Rolling Shutter: Only Veo 3 exhibits characteristic skew; others lack expected geometric distortion.
- Depth of Field: All models render pronounced blur regardless of aperture, indicating weak parameter control.

Figure 6: Evaluation of video generation models; most fail to generate physically accurate camera effects, producing artifacts or incorrect effects.

Figure 7: Fisheye video evaluation; Sora most closely follows lens parameters, others fail to produce true fisheye effect.

Figure 8: Rolling-shutter video evaluation; only Veo 3 exhibits expected skew, others lack characteristic distortion.

Figure 9: Depth-of-field video evaluation; all models produce strong blur regardless of aperture, revealing poor control of DoF effects.
Implementation Details
The Gaussian deformation network follows the 4DGS formulation, with multi-resolution plane modules and multi-head MLPs for attribute residual prediction. Training employs a two-stage optimization: static scene initialization followed by joint optimization of Gaussians and deformation network. Densification is guided by 3D gradient magnitude, scaled by distance from the camera.
Limitations and Future Directions
4D-GRT requires well-reconstructed dynamic scenes and sufficient multi-view video data, limiting applicability in sparse or monocular scenarios. Future work may integrate generative or foundation models for monocular dynamic scene reconstruction, broadening accessibility of camera effect simulation.
Conclusion
4D-GRT provides a robust, efficient framework for generating physically accurate, controllable camera effects in dynamic scenes. It outperforms dynamic NeRF baselines in rendering speed and quality, and exposes the limitations of current video generation models in camera effect awareness. The released benchmark dataset and pipeline establish a foundation for advancing camera-aware vision and effect-aware training data generation. Future research should focus on reducing multi-view data requirements and integrating generative scene reconstruction for broader applicability.
