MVInverse: Feed-forward Multi-view Inverse Rendering in Seconds
Abstract: Multi-view inverse rendering aims to recover geometry, materials, and illumination consistently across multiple viewpoints. When applied to multi-view images, existing single-view approaches often ignore cross-view relationships, leading to inconsistent results. In contrast, multi-view optimization methods rely on slow differentiable rendering and per-scene refinement, making them computationally expensive and hard to scale. To address these limitations, we introduce a feed-forward multi-view inverse rendering framework that directly predicts spatially varying albedo, metallic, roughness, diffuse shading, and surface normals from sequences of RGB images. By alternating attention across views, our model captures both intra-view long-range lighting interactions and inter-view material consistency, enabling coherent scene-level reasoning within a single forward pass. Due to the scarcity of real-world training data, models trained on existing synthetic datasets often struggle to generalize to real-world scenes. To overcome this limitation, we propose a consistency-based finetuning strategy that leverages unlabeled real-world videos to enhance both multi-view coherence and robustness under in-the-wild conditions. Extensive experiments on benchmark datasets demonstrate that our method achieves state-of-the-art performance in terms of multi-view consistency, material and normal estimation quality, and generalization to real-world imagery.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
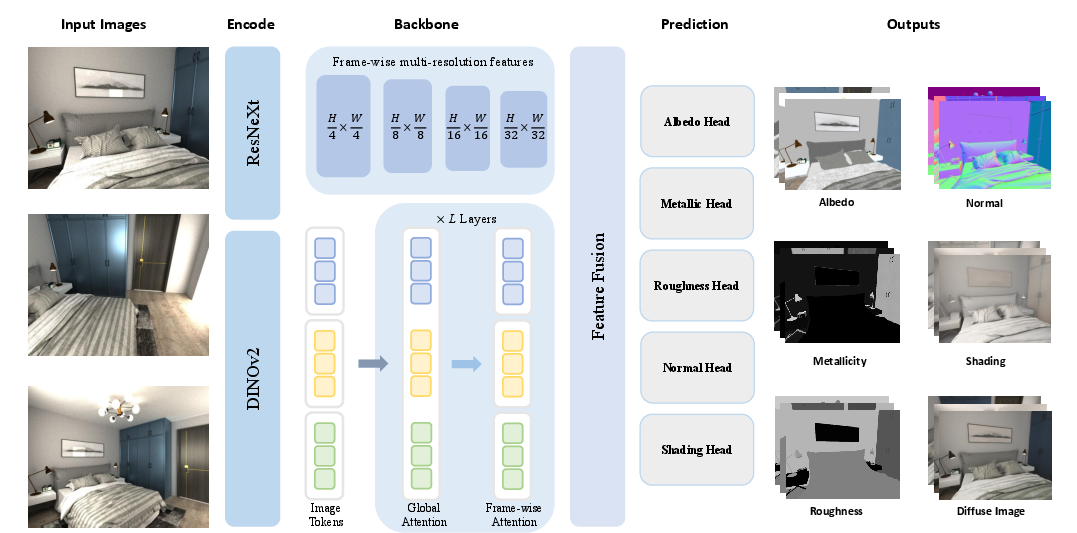
This paper introduces MVInverse, a fast computer program that can look at several photos or a short video of a scene and figure out the hidden “ingredients” of that scene. These ingredients include what colors things truly are (without shadows or bright spots), how shiny or metallic they are, how smooth or rough their surfaces are, which way each tiny patch of surface is facing, and how light is softly falling on them. Once MVInverse recovers these properties, you can re-light the scene—add new lights or change the lighting—and get realistic results in just a few seconds.
Key objectives and questions
The paper aims to solve three main problems:
- Can we recover the true material properties and shapes of a scene from multiple views quickly instead of spending minutes or hours per scene?
- Can we make sure those recovered properties are consistent across different camera angles (so the same part of a table looks the same in every photo)?
- Can the method work well not just on computer-made (synthetic) images, but also on real-world photos and videos?
How did they do it? (Methods explained simply)
Think of MVInverse like a very smart detective that examines a set of images to figure out what the scene is made of.
- Multiple views help: Looking at the same scene from different angles lets the program check its guesses. If the wall looks red in one view, it should also look red in another view—unless the lighting is different. MVInverse uses this “cross-checking” to stay consistent.
- Alternating attention: MVInverse uses a transformer (a powerful pattern-finding system) with two kinds of “attention,” switching back and forth:
- Frame-wise attention: Focuses inside one image to understand long-range effects like shadows or reflections across far-apart pixels in that image.
- Global attention: Connects matching areas across different images of the same scene (even if the camera moved), so the material of the same 3D spot stays consistent.
- What it predicts for each image:
- Albedo: The true base color of the surface (like paint color), without shadows or glare.
- Metallic: How much a surface behaves like metal.
- Roughness: How smooth vs. matte a surface is (smooth = mirror-like, rough = diffuse).
- Surface normals: The direction each tiny patch of surface is facing (important for how light hits it).
- Diffuse shading: The soft, overall lighting on the surface (not direct shiny highlights).
- Training and fine-tuning:
- First, it learns from large synthetic datasets (fake but very clean and labeled).
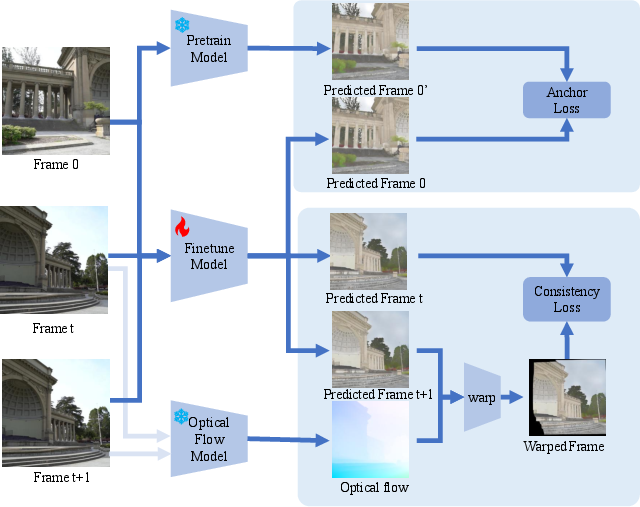
- Then, to handle real videos better, it fine-tunes itself without needing labels. It compares predictions across adjacent frames using optical flow (which tracks how pixels move between frames). If the same physical spot moves in the video, its material prediction should move with it and match. A small “anchor” keeps it from drifting away from its good initial predictions.
In everyday terms: MVInverse looks at multiple photos, links matching parts across views, and learns a consistent story about what the scene is made of and how it’s lit. It practices first on clean, fake data, then polishes its skills on real videos by making sure its predictions stay steady over time.
Main findings and why they are important
- Speed: MVInverse does all this in seconds per scene, while many older methods need minutes to hours. That’s a big deal for real-time use.
- Consistency across views: It keeps material predictions consistent when the camera angle changes. This avoids weird flickering or color changes of the same object between frames or viewpoints.
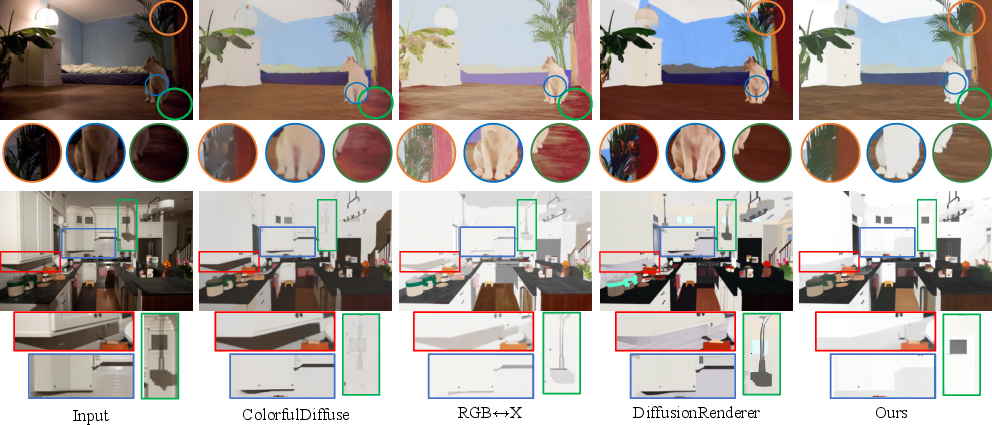
- High quality: It reaches or beats state-of-the-art results on standard tests for material recovery and surface normals (the “which way the surface faces” detail).
- Works on real videos: With the consistency fine-tuning, it reduces flicker and gets stable results on real-world footage.
Why it matters:
- Scenes look more realistic when re-lit or edited because the underlying materials are accurate and consistent.
- Fast processing lets creators and engineers use it interactively—great for film, games, AR/VR, and robotics.
Implications and potential impact
MVInverse shows that multi-view inverse rendering can be done quickly without sacrificing quality. This opens doors to:
- Real-time relighting: Change the lighting in a video and get realistic results fast.
- View-consistent editing: Change the color or texture of an object and have that change look correct from any camera angle.
- Better 3D understanding for robots and AR: Knowing what surfaces are made of and how light behaves helps with safe interaction and realistic overlays.
A current limitation is the lack of large, high-quality real-world training data with perfect labels. As better datasets appear, models like MVInverse could become even more accurate and widely used, becoming a standard part of 3D content creation and scene understanding pipelines.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and unresolved questions that future work could address.
- Lack of explicit illumination estimation: the method predicts a diffuse shading map but does not recover an environment map, SH lighting, or direct/indirect components; it remains unclear how to perform physically faithful relighting with changing global illumination or view-dependent effects.
- Specular modeling is under-specified: while metallic and roughness are predicted, there is no explicit specular shading or Fresnel/IOR parameterization, leaving open how accurately the approach handles strong specular highlights, anisotropic materials, clear coats, or multi-lobe microfacet BRDFs.
- Diffuse-only shading entanglement: predicting “diffuse shading” as a 3-channel image risks color bleeding and albedo–shading entanglement; the paper does not quantify disentanglement quality or failure modes under complex interreflections.
- No treatment of transparency/translucency/SSS: glass, liquids, subsurface scattering, and participating media are not modeled; it is unknown how the system behaves on such materials or how to extend it to them.
- World-space consistency of normals is not enforced: normals are predicted in camera space per view; there is no 3D consistency constraint or world-space fusion, which could lead to cross-view normal inconsistencies.
- Pose-free cross-view association limits: global attention is used without camera pose supervision; the robustness of correspondence under large baselines, minimal overlap, or repetitive textures is not characterized.
- Finetuning relies on 2D optical flow: flow-based consistency can fail with occlusions, large parallax, dynamic objects, and illumination changes; the method does not incorporate occlusion masks or 3D geometry-aware warping during finetuning.
- Temporal consistency is local-only: finetuning enforces coherence across adjacent frames, but long-range temporal consistency (over large viewpoint changes or long sequences) and cumulative drift are not evaluated.
- Anchor-based finetuning may preserve pretraining biases: the anchor loss tethers the model to pretrained outputs; the trade-off between removing temporal flicker and retaining erroneous priors is not studied.
- Limited supervision on real data: real-world finetuning uses unlabeled videos (and pseudo albedo for a subset); there is no mechanism to calibrate scaling/exposure/white balance differences, potentially harming albedo consistency.
- Exposure and ISP variability: the method does not explicitly model camera response, white balance, or tone mapping; the impact of auto-exposure/auto-WB across views on albedo/shading separation remains unknown.
- Assumption of static illumination: the training and evaluation do not examine scenes with changing lighting across views/time; performance under moving lights or time-varying HDR environments is not reported.
- Limited quantitative relighting validation: while relighting demos are shown, there is no quantitative evaluation (e.g., against ground-truth relit images, energy conservation checks, or user studies) to assess physical fidelity.
- Dependence on external geometry for applications: relighting and editing rely on separate feed-forward 3D reconstruction to build a point cloud; the effect of geometry/pose inaccuracies on material use and relighting quality is not analyzed.
- No joint geometry–material learning: geometry and materials are not learned jointly; whether end-to-end joint learning (e.g., with lightweight differentiable rendering) could improve multi-view coherence and physical accuracy is untested.
- Multi-view consistency protocol is narrow: the proposed evaluation uses five Hypersim scenes and assumes accurate depth/poses; sensitivity to pose/depth errors and generalization to broader datasets or outdoor scenes is unreported.
- Scalability with sequence length and resolution: alternating global attention across all views has quadratic complexity; the paper does not report memory/time scaling with number of views, resolution, or token count.
- Inference speed characterization is incomplete: “seconds” is claimed, but detailed benchmarks (image size, number of views, GPU type, peak memory) and speed–quality trade-offs are not provided.
- Loss design sensitivity: all losses are equally weighted; there is no ablation on weighting strategies, scale-invariant albedo loss choices, or the effect of adding perceptual/reflectance-regularization terms.
- Domain coverage and bias: synthetic training data and pseudo-labeled videos may not capture the diversity of real materials, outdoor lighting, or sensor characteristics; the impact of dataset bias is not quantified.
- Handling of occlusions in consistency losses: the finetuning loss does not detail occlusion masking or confidence weighting for flow; without it, the model may be penalized for unavoidable inconsistencies.
- Robustness to real-world artifacts: performance under motion blur, rolling shutter, heavy noise, lens distortion, and compression artifacts is not evaluated.
- Material editing limitations: editing examples replace albedo and reuse predicted diffuse shading; there is no support for physically correct updates to indirect illumination, specular transport, or self-shadowing after edits.
- No uncertainty estimation: predictions lack confidence/uncertainty measures; integrating uncertainty could improve finetuning, fusion across views, and downstream use.
- Generalization to dynamic scenes: moving objects and nonrigid motion are not addressed; it is unclear how to extend the method or finetuning to such cases without 3D tracking or scene flow.
- Lack of standardized multi-view benchmarks: the field lacks common datasets/metrics for multi-view inverse rendering; establishing benchmarks (with GT materials, normals, lighting) would enable more rigorous comparisons.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now based on MVInverse’s feed-forward, multi-view inverse rendering capability (seconds-level inference; consistent albedo/metallic/roughness/normals/shading; self-supervised consistency finetuning for real videos).
- Fast video relighting for post-production and advertising
- Sectors: Media & Entertainment, Advertising, Software
- Tools/Products/Workflows: Nuke/After Effects/Houdini/Blender plugin to ingest multi-view frames → run MVInverse → combine with feed-forward 3D reconstruction (e.g., Pi3/VGGT) → PBR relight shot with new light rigs
- Assumptions/Dependencies: Mostly static scenes; commodity GPU; integration with a renderer; material model aligns with studio PBR; consistent exposure/white balance across views
- View-consistent material editing across shots
- Sectors: Media & Entertainment, Game Art, Design
- Tools/Products/Workflows: “Material Edit” tool in DCCs (Blender/Maya/Unreal/Unity) that swaps albedo maps and preserves shading/geometry consistency across views; batch shot processing
- Assumptions/Dependencies: Accurate normals/shading; adequate texture resolution; static lighting during capture to avoid confounds
- Rapid PBR asset capture for photogrammetry pipelines
- Sectors: Gaming, 3D Asset Marketplaces, E-commerce
- Tools/Products/Workflows: Mobile capture (orbit phone around object) → MVInverse produces albedo/metallic/roughness/normals → fuse with mesh/point cloud from feed-forward 3D recon → publish as PBR-ready asset
- Assumptions/Dependencies: Multi-view images; object remains static; adequate coverage and lighting diversity; GPU or on-prem server for fast inference
- AR/VR compositing with scene-aware materials
- Sectors: AR/VR, Mobile Software
- Tools/Products/Workflows: ARKit/ARCore extension to estimate scene materials/normals/diffuse shading → match virtual object materials/lighting for seamless placement
- Assumptions/Dependencies: Real-time inference budget; consistent exposure; robust handling of glossy/specular surfaces; integration with AR runtime
- Robotics perception for manipulation and contact planning
- Sectors: Robotics, Industrial Automation
- Tools/Products/Workflows: ROS node that estimates roughness/metallic and normals from multi-view cameras → heuristics for friction/grip strategy and tool-path planning
- Assumptions/Dependencies: Static targets during capture; mapping between visual material estimates and physical properties (calibration dataset needed); controlled illumination improves accuracy
- Interior design and real estate staging
- Sectors: Architecture, Real Estate, Retail
- Tools/Products/Workflows: Mobile app to relight and recolor finishes (paint, flooring, cabinetry) using MVInverse maps; live previews for clients
- Assumptions/Dependencies: Adequate scene coverage; device GPU/edge inference; static scenes; realistic mapping of material edits to client-facing renderers
- Manufacturing quality inspection for finishes
- Sectors: Manufacturing, Quality Assurance
- Tools/Products/Workflows: Multi-camera inspection cell → MVInverse separates albedo from illumination → detect finish inconsistencies, scratches, or coating defects
- Assumptions/Dependencies: Controlled lighting; calibrated cameras; known tolerances for material parameters; domain adaptation to specific product lines
- Cultural heritage digitization with physically-based assets
- Sectors: Museums, Cultural Heritage, Education
- Tools/Products/Workflows: Minimal-capture workflows producing PBR materialized models for online exhibits and research; web viewers that support relighting
- Assumptions/Dependencies: Non-invasive capture; controlled environment; policies for conservation-grade scanning and data stewardship
- Academic benchmarking and toolkits
- Sectors: Academia, Open-Source Software
- Tools/Products/Workflows: Open baselines and protocols for multi-view material consistency evaluation (RMSE via reprojection); ablation studies on alternating global/frame attention; datasets with pseudo labels for real-world finetuning
- Assumptions/Dependencies: Access to benchmark datasets; reproduction of training protocols; licensing for DINOv2/RAFT and pretrained models
- Consumer photo apps: shadow removal and color correction
- Sectors: Consumer Software, Mobile Apps
- Tools/Products/Workflows: Smartphone app that extracts albedo to remove shadows and fix color casts; batch processing for galleries
- Assumptions/Dependencies: On-device or cloud inference; primarily static subjects; acceptable approximation of material/shading for casual use
Long-Term Applications
These use cases require additional research, scaling, generalization, or productization beyond the current state.
- Real-time, on-device inverse rendering in mobile AR video streams
- Sectors: Mobile, AR/VR, Edge AI
- Tools/Products/Workflows: Model compression/distillation + hardware acceleration (NPUs) for live material/shading estimation; direct camera pipeline integration
- Assumptions/Dependencies: Model optimization for latency/power; robust outdoor performance; privacy-preserving on-device processing
- Dynamic scene inverse rendering (moving objects, changing lights)
- Sectors: AR/VR, Media, Robotics
- Tools/Products/Workflows: Motion segmentation + dynamic illumination estimation; frame-to-frame tracking of materials in non-static scenes
- Assumptions/Dependencies: New training data and losses for motion/lighting changes; improved optical flow/scene flow; temporal stability guarantees
- Robust outdoor/general-purpose inverse rendering
- Sectors: Autonomous Systems, Urban Modeling, Digital Twins
- Tools/Products/Workflows: Outdoor datasets and domain adaptation; handling high dynamic range, specular highlights, weather effects
- Assumptions/Dependencies: Expanded training corpora; radiometric calibration; scalable finetuning with self-supervised constraints
- Extended PBR parameterization (anisotropy, clearcoat, subsurface scattering)
- Sectors: VFX, Product Design, Simulation
- Tools/Products/Workflows: Prediction heads for richer SVBRDFs beyond metallic/roughness; physically grounded evaluation pipelines
- Assumptions/Dependencies: Availability of labeled or synthetic ground truth; renderer alignment; computational budgets for additional channels
- City-scale digital twins with physically accurate materials
- Sectors: Urban Planning, Energy, Infrastructure, Policy
- Tools/Products/Workflows: Feed-forward geometry + MVInverse materials across large capture fleets; energy simulation of lighting/daylighting and heat
- Assumptions/Dependencies: Massive data ingestion; privacy and data governance; standards for material metadata; cross-agency collaboration
- Robotics with tactile-aware planning from vision-inferred materials
- Sectors: Industrial Robotics, Logistics
- Tools/Products/Workflows: Fuse visual material maps with tactile/force sensors; predictive models of friction and wear; safety-certified controllers
- Assumptions/Dependencies: Calibration datasets linking visual BRDF to physical properties; safety/regulatory approval; robust edge inference
- Automated e-commerce product scanning booths with material authenticity checks
- Sectors: E-commerce, Retail Operations
- Tools/Products/Workflows: Multi-camera capture + MVInverse → standardized PBR assets; authenticity and finish verification; auto-listing pipelines
- Assumptions/Dependencies: Controlled illumination; SKU-specific material references; policies against deceptive relighting/deepfake editing
- Compliance and audit tools for relit/edited media
- Sectors: Media Regulation, Policy, LegalTech
- Tools/Products/Workflows: Provenance tracking and material/lighting edit logs; watermarking of relighted content; fairness audits in advertising
- Assumptions/Dependencies: Industry standards for audit trails; adoption by platforms; alignment with legal frameworks
- Edge inverse rendering for drones/field robotics
- Sectors: Energy, Construction, Inspection, Agriculture
- Tools/Products/Workflows: Onboard inference to produce material-aware maps for inspection (corrosion, coating wear) and planning
- Assumptions/Dependencies: Ruggedized hardware; real-time constraints; outdoor generalization; safety and airspace compliance
- Scientific and planetary remote sensing
- Sectors: Space, Earth Observation
- Tools/Products/Workflows: Cross-view material estimation under domain shifts (spectral differences, extreme illumination); mission planning and analysis
- Assumptions/Dependencies: Specialized sensors and calibration; domain adaptation to non-RGB spectra; collaboration with scientific agencies
Each long-term application depends on improved generalization to diverse environments, richer material models, stronger temporal handling for dynamic scenes, tighter integrations with downstream systems (renderers, robotics stacks, AR runtimes), and—where relevant—standards, governance, and regulatory frameworks.
Glossary
- 3D Gaussian Splatting: A real-time 3D representation and rendering technique using Gaussian primitives for efficient radiance field approximation. "More recently, 3D Gaussian Splatting~\cite{kerbl20233d} has been adapted for inverse rendering"
- Albedo: The intrinsic, view-independent base color of a surface, excluding lighting effects. " denotes the albedo map, representing the surface's base reflectance color."
- Alternating attention: A transformer mechanism that alternates between per-frame and global cross-view attention to aggregate consistent features. "By alternating attention across views, our model captures both intra-view long-range lighting interactions and inter-view material consistency"
- Anchor loss: A stabilization term that anchors finetuned outputs to a pretrained reference to prevent degenerate solutions. "To prevent this, we introduce an anchor loss at frame 0."
- Back-projection: Mapping image pixels and predicted properties back into 3D world coordinates using depth and camera pose. "back-projected into 3D world coordinates and reprojected onto other views."
- Camera-space normals: Surface normal vectors expressed in the camera’s coordinate system. "predicts albedo, roughness, and metallicity along with camera-space normals and diffuse shading maps"
- Cosine similarity loss: A loss that measures orientation agreement between predicted and ground-truth normals via cosine similarity. "Surface normals are trained using a cosine similarity loss, enforcing correct orientation rather than raw vector magnitude:"
- Dense optical flow: Pixel-wise motion field between consecutive frames used to warp predictions across time. "we estimate dense optical flow between frames and "
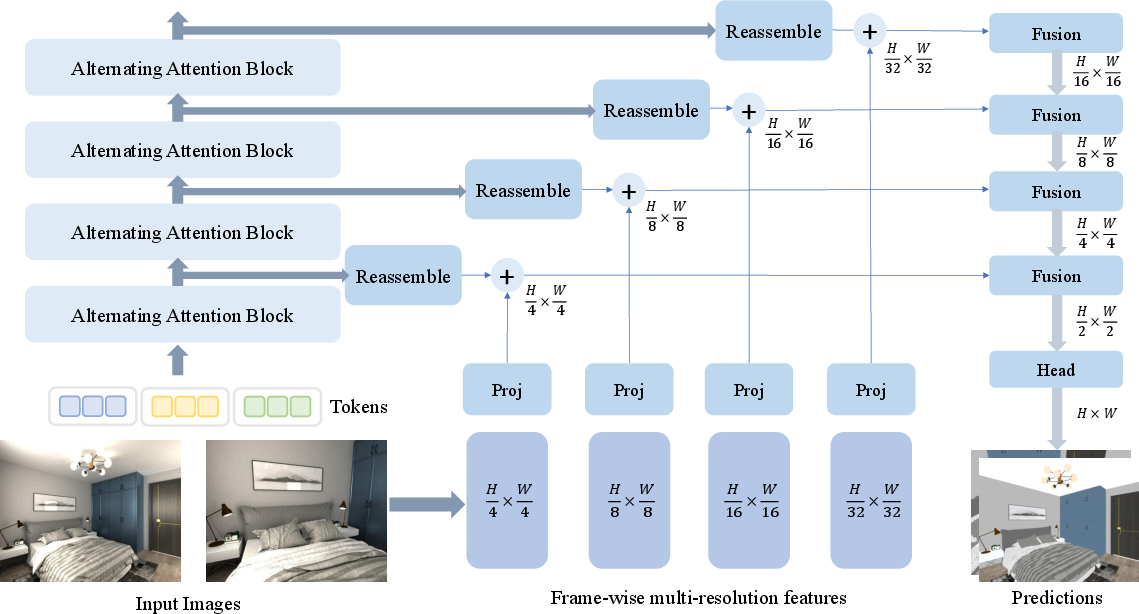
- Dense prediction: Pixel-aligned outputs produced by models for per-pixel properties like materials and normals. "Each head is implemented as a DPT-style dense prediction module~\cite{ranftl2021vision}, producing pixel-aligned predictions at the input resolution."
- Diffuse shading: The component of shading due to diffuse reflection, integrating incoming radiance over the upper hemisphere. " denotes the diffuse shading map, capturing the total incoming radiance over the upper hemisphere at each surface point"
- Differentiable rendering: Rendering that provides gradients for optimization of scene parameters via backpropagation. "multi-view optimization methods rely on slow differentiable rendering and per-scene refinement"
- DINOv2: A self-supervised vision foundation model used as a strong feature encoder for images. "We use DINOv2~\cite{oquab2023dinov2} as the visual feature encoder"
- DPT-style head: A decoder architecture for dense prediction that fuses multi-scale features to output pixel-aligned maps. "Each head is implemented as a DPT-style dense prediction module~\cite{ranftl2021vision}, producing pixel-aligned predictions at the input resolution."
- End-to-end prediction: Direct mapping from inputs to outputs without iterative per-scene optimization stages. "replacing lengthy optimization pipelines with direct, end-to-end prediction~\cite{wang2025pi, wang2025vggt, keetha2025mapanything, liu2025worldmirror}."
- Feed-forward: A single-pass inference process that predicts outputs without iterative refinement. "a feed-forward multi-view inverse rendering framework"
- Frame-wise self-attention: Attention computed within each image to capture intra-frame spatial dependencies. "Frame-wise self-attention, which performs attention within a single image and refines token representations by capturing long-range spatial dependencies and local semantic structures."
- Global self-attention: Attention computed across all input views to align and aggregate cross-view information. "Global self-attention, which performs attention across all input images and allows tokens from different views to mutually reference and reinforce each other."
- Implicit neural fields: Continuous neural representations of scene properties (e.g., radiance, reflectance) indexed by spatial coordinates. "These methods model radiance and reflectance within implicit neural fields"
- Inter-view: Across different camera viewpoints in a multi-view setup. "inter-view material consistency"
- Intra-view: Within a single camera viewpoint/image. "intra-view long-range lighting interactions"
- Inverse rendering: The process of estimating intrinsic scene properties (materials, geometry, illumination) from images. "Inverse rendering aims to decompose a scene into geometry, material properties and illumination"
- Iterative optimization: Repeated gradient-based refinement of scene parameters, typically slow and per-scene. "the majority of approaches rely on iterative optimization frameworks"
- LPIPS: A perceptual metric that measures similarity between images based on deep features. "We evaluate albedo predictions using PSNR, SSIM, and LPIPS"
- Mean angular error (MAE): The average angular difference between predicted and ground-truth normals. "Normal estimation performance is measured using mean angular error (MAE)"
- Mean squared error (MSE): A pixel-wise regression loss measuring the squared difference between predictions and ground truth. "we follow~\cite{li2018cgintrinsics, li2018megadepth, careagaColorful} to use mean-squared error (MSE) loss and multi-scale gradient (MSG) loss"
- Metallic: A material parameter indicating the fraction of metal-like reflectance behavior. " is the metallic map"
- Multi-scale gradient (MSG) loss: A loss computed on image gradients at multiple scales to preserve spatial detail. "and multi-scale gradient (MSG) loss"
- Multi-view inconsistency: Divergence in predicted material properties for the same 3D region across different views. "their extension to multi-view settings is plagued by multi-view inconsistency: material predictions for the same 3D region across different viewpoints often diverge"
- Multi-view inverse rendering: Joint recovery of materials, geometry, and illumination across multiple viewpoints. "Multi-view inverse rendering aims to recover geometry, materials, and illumination consistently across multiple viewpoints."
- NeRF: Neural Radiance Fields, an implicit representation for view synthesis using volumetric rendering. "NeRF~\cite{mildenhall2021nerf} and NeuS~\cite{wang2021neus}-based approaches~\cite{srinivasan2021nerv, boss2021nerd, knodt2021neural, zhang2021nerfactor, boss2021neural, yang2022ps, yao2022neilf, chen2022tracing, boss2022samurai, attal2024flash, zhang2022iron, liu2023nero, yang2024robir, wang2024inverse, cai2024pbir} have become a dominant paradigm."
- NeuS: Neural Implicit Surfaces, an implicit neural representation focusing on surface geometry with differentiable rendering. "NeRF~\cite{mildenhall2021nerf} and NeuS~\cite{wang2021neus}-based approaches ... have become a dominant paradigm."
- Optical flow: The apparent motion of pixels between frames used for temporal alignment. "Optical flow warps the prediction of frame to frame "
- Permutation-equivariant: A property of a model whose output is invariant under permutation of the input view order. "we adopt a permutation-equivariant alternating-attention transformer backbone from Pi3~\cite{wang2025pi}."
- Physically based rendering (PBR): Rendering that models light transport and material interaction using physical principles. "inverse rendering serves as a cornerstone for advancing physically based rendering (PBR) pipelines"
- Pi3: A feed-forward 3D reconstruction transformer architecture used as a backbone reference. "we adopt a permutation-equivariant alternating-attention transformer backbone from Pi3~\cite{wang2025pi}."
- Point cloud: A set of 3D points representing a scene or object, often with associated attributes. "we can obtain textured point clouds that enable various downstream applications"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric comparing reconstructed images to references. "We evaluate albedo predictions using PSNR, SSIM, and LPIPS"
- Radiance: The measure of light energy emitted or reflected in a given direction per unit area and solid angle. "capturing the total incoming radiance over the upper hemisphere at each surface point"
- ResNeXt: A convolutional neural network architecture with aggregated transformations for efficient feature extraction. "a frame-wise ResNeXt~\cite{xie2017aggregated} encoder provides multi-resolution convolutional features"
- RMSE: Root Mean Squared Error; a metric for measuring average prediction error magnitude. "We then compute RMSE between reprojected and directly predicted maps"
- Roughness: A material parameter controlling microfacet distribution and specular lobe width. " represents the roughness map."
- Scale-invariant MSE loss: An error measure normalized to be insensitive to global scale differences (e.g., illumination). "Note that a scale-invariant MSE loss is applied for albedo prediction"
- Self-supervised finetuning: Adapting a model using constraints derived from the data itself without ground-truth labels. "we perform self-supervised finetuning on real-world videos"
- Skip connection: A neural network connection that bypasses layers to preserve high-frequency details. "The extracted fine-grained details are skip-connected to the prediction heads"
- SSIM: Structural Similarity Index; a perceptual metric for image similarity focusing on structure and luminance. "We evaluate albedo predictions using PSNR, SSIM, and LPIPS"
- SVBRDFs: Spatially-varying Bidirectional Reflectance Distribution Functions that model per-pixel material reflectance. "These learning-based approaches can jointly estimate spatially-varying bidirectional reflectance distribution functions (SVBRDFs), complex lighting, and surface normals."
- Token: A patch-level feature vector produced by an encoder for transformer processing. "Each input image is converted into a set of visual tokens: "
- Vision Transformer (ViT): A transformer-based architecture for image understanding using patch tokens. "vision transformer (ViT)-based models have revolutionized the field by replacing lengthy optimization pipelines with direct, end-to-end prediction"
- Warping: Spatially transforming one frame’s prediction to align with another using estimated motion. "The predicted material map is warped according to to obtain ."
Collections
Sign up for free to add this paper to one or more collections.

