- The paper presents a novel framework that leverages lightweight multimodal LLMs and industry-grade rendering to generate interactive 3D virtual environments.
- It introduces a unique 32×32 symbolic layout approach that fuses text and visual inputs for precise spatial reasoning and scene configuration.
- The system achieves high visual fidelity and efficiency, reducing production time by over 90× and enabling dynamic multi-agent interactions.
LatticeWorld: A Multimodal LLM-Driven Framework for Interactive Complex World Generation
Introduction
LatticeWorld presents a comprehensive framework for the generation of large-scale, interactive 3D virtual environments, leveraging lightweight multimodal LLMs and industry-grade rendering engines. The system is designed to accept both textual and visual instructions, producing dynamic, high-fidelity worlds with multi-agent interactions and realistic physics. The framework is motivated by the need to bridge the sim-to-real gap in embodied AI, autonomous driving, and entertainment, where high-quality, controllable, and efficient world generation is essential.
System Architecture and Pipeline
LatticeWorld is architected as a modular pipeline comprising three primary components: a multimodal scene layout generator, an environmental configuration generator, and a procedural rendering pipeline. The system is built atop LLaMA-2-7B, augmented with a visual encoder (CLIP ViT-B/32) and a lightweight CNN-based projection module for vision-language alignment. The rendering backend utilizes Unreal Engine 5 (UE5), chosen for its advanced physics, real-time rendering, and multi-agent support.
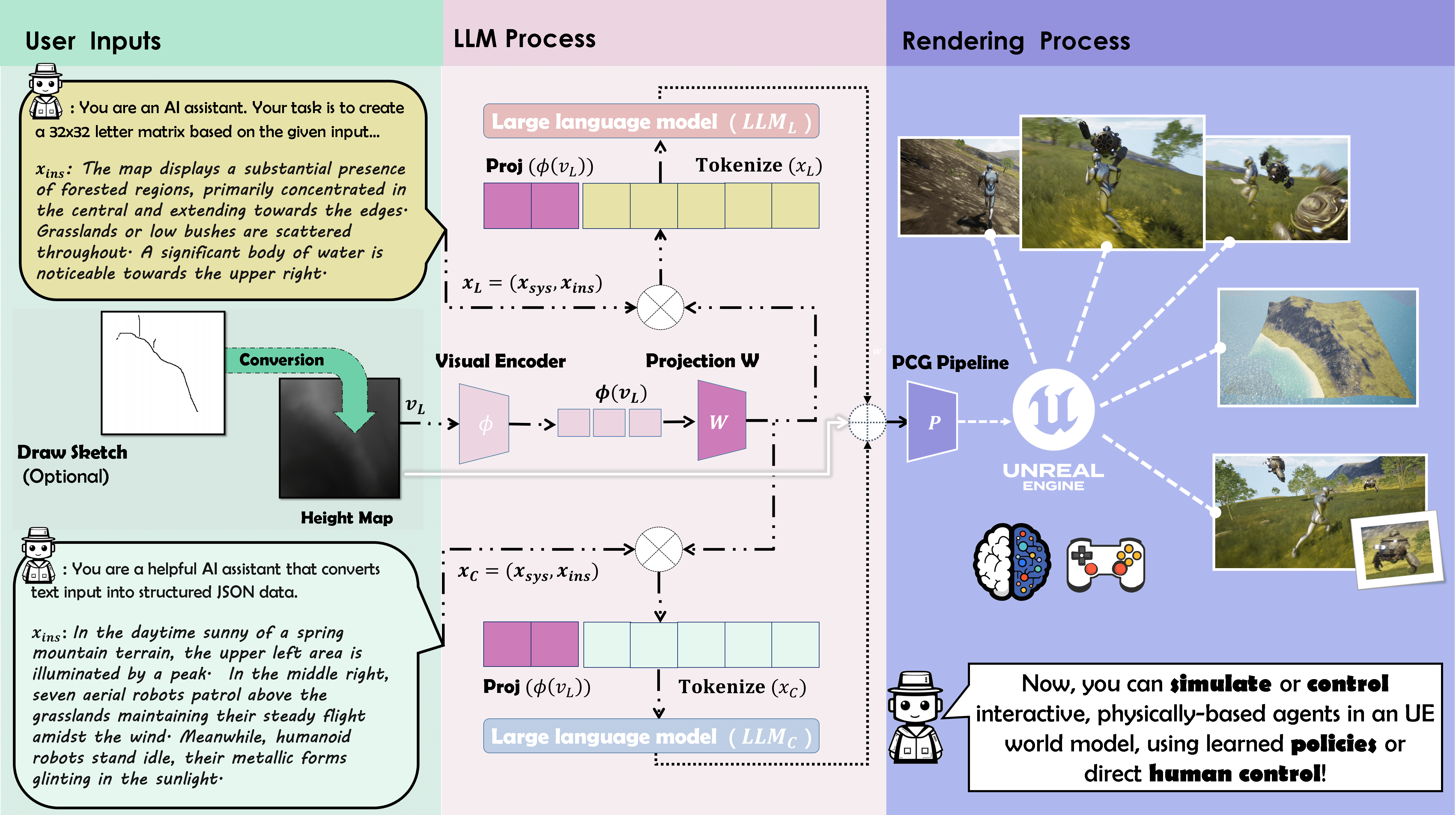
Figure 1: The technical framework of LatticeWorld, illustrating the flow from multimodal input to 3D world generation.
The pipeline operates as follows:
- Input: Users provide a textual description of the desired environment and, optionally, a visual instruction (e.g., a height map or sketch).
- Scene Layout Generation: The multimodal LLM generates a symbolic matrix encoding the spatial layout of assets, informed by both text and visual cues.
- Environmental Configuration Generation: A second LLM, conditioned on the layout, visual input, and additional configuration text, produces a structured set of scene and agent parameters.
- Rendering: The symbolic layout and configuration are decoded into engine-native formats, and the scene is procedurally instantiated in UE5.
Symbolic Layout Representation and Multimodal Generation
A key innovation in LatticeWorld is the use of a 32×32 symbolic matrix to represent scene layouts. Each symbol corresponds to an asset class (e.g., water, forest, building), enabling the LLM to reason over spatial relationships and asset distributions in a format amenable to sequence modeling. This approach is generalizable to LLMs with only text generation capabilities, facilitating broad applicability.
The system supports both fixed-height (text-only) and variable-height (text + visual) scene generation. For variable-height scenes, visual instructions are encoded via CLIP, projected into the LLM embedding space, and fused with text tokens. The visual module is trained in three stages: CLIP fine-tuning for terrain understanding, projection module alignment, and end-to-end fine-tuning with frozen CLIP weights.

Figure 2: Demonstration of generated results via LatticeWorld, showcasing diverse, high-fidelity 3D environments from multimodal instructions.
Environmental Configuration and Agent Modeling
Environmental configuration in LatticeWorld is hierarchically structured, separating coarse scene attributes (e.g., season, weather, style) from fine-grained parameters (e.g., asset density, material, agent state). The configuration LLM is trained to map natural language descriptions and layout context to a JSON schema compatible with UE5's procedural content generation (PCG) pipeline.
Agent modeling is integrated into the configuration process, supporting specification of agent types, quantities, states, and spatial positions. The system enforces semantic constraints (e.g., aquatic agents only in water regions) and supports dynamic, adversarial multi-agent behaviors, with extensibility for more complex policies.
Dataset Construction and Annotation
A significant contribution of LatticeWorld is the construction of two large-scale multimodal datasets: one based on the LoveDA remote sensing dataset (fixed-height, urban/suburban) and a proprietary Wild dataset (variable-height, wilderness). Each sample includes semantic segmentation, symbolic layout, textual captions, and, for Wild, sketches and height maps.
Annotation is performed using GPT-4o with prompt engineering to ensure spatially grounded, semantically rich descriptions. Data augmentation (e.g., rotations, multiple captions per image) is employed to enhance robustness.
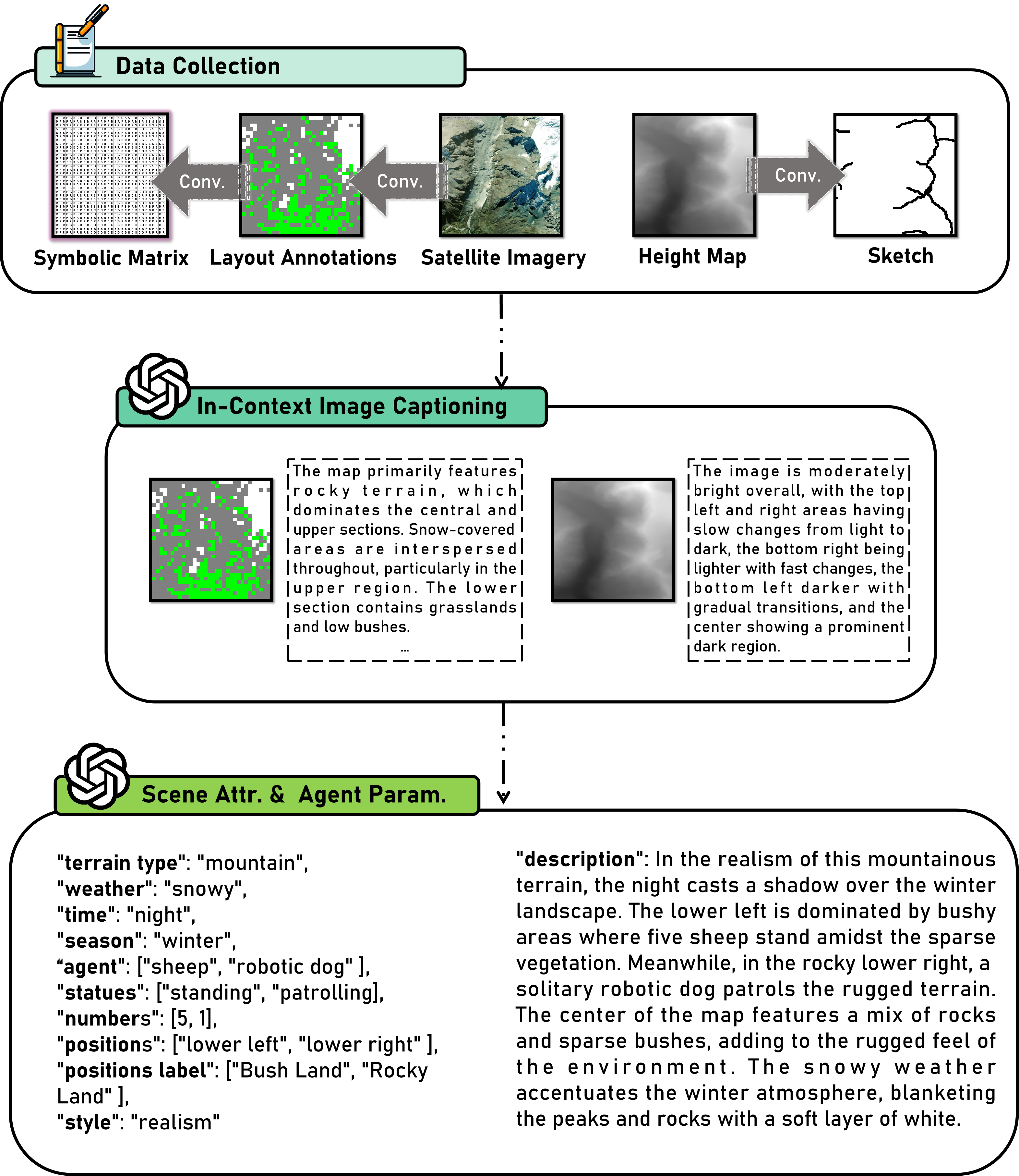
Figure 3: Illustration of the dataset construction process, including conversion to symbolic matrices and multimodal annotation.
Procedural Rendering and Engine Integration
The rendering pipeline translates symbolic layouts into binary masks, applies edge blending for natural transitions, and maps configurations to engine-native properties. The system leverages UE5's advanced features (e.g., Niagara Fluids, Volumetric Cloud, agent plugins) for high-fidelity, real-time simulation. The architecture is engine-agnostic, with decoders and translators (ΨL, ΨC) abstracted for portability to other platforms (e.g., Unity, Blender).
Experimental Evaluation
LatticeWorld is evaluated on both fixed- and variable-height layout generation, environmental configuration, and full 3D scene synthesis. Comparative experiments against GPT-4o, Claude 3.7 Sonnet, DeepSeek-R1, Qwen2-VL-Max, and prior platform-based methods (e.g., BlenderGPT, SceneCraft, Infinigen) demonstrate:
- Superior layout accuracy and visual fidelity across both urban and wilderness domains.
- Robust multimodal reasoning, with the ability to enforce spatial and semantic constraints from both text and visual input.
- High-quality 3D scene generation with dynamic agents and realistic physics, outperforming prior works in qualitative comparisons.
- Industrial-scale efficiency: LatticeWorld achieves over a 90× reduction in production time compared to manual workflows, with comparable creative quality.
Limitations and Future Directions
While LatticeWorld demonstrates strong performance, several limitations are acknowledged:
- Agent behaviors are currently limited to simple adversarial policies; richer multi-agent dynamics and learning-based policies are a natural extension.
- Main agent control is restricted to a single entity and input devices; support for multiple controllable agents and AI-driven policies is planned.
- Asset diversity is bounded by the current library; ongoing expansion is required for broader domain coverage.
Implications and Outlook
LatticeWorld establishes a scalable, interpretable, and efficient paradigm for multimodal, LLM-driven 3D world generation. The symbolic layout approach enables controllable, semantically grounded scene synthesis, while the modular architecture supports rapid adaptation to new engines and domains. The demonstrated efficiency gains have direct implications for industrial content creation, simulation, and embodied AI research.
Theoretically, the work highlights the spatial reasoning capabilities of lightweight LLMs when equipped with appropriate intermediate representations and vision-language alignment. Practically, LatticeWorld provides a foundation for future research in interactive world models, agent-based simulation, and sim-to-real transfer.
Conclusion
LatticeWorld delivers a practical, extensible framework for multimodal, LLM-empowered 3D world generation, integrating symbolic spatial reasoning, hierarchical configuration, and procedural rendering. The system achieves strong empirical results in both fidelity and efficiency, with clear pathways for further enhancement in agent modeling, asset diversity, and multimodal instruction following.