SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Abstract: LLM agents have demonstrated remarkable capabilities in software development, but their performance is hampered by long interaction contexts, which incur high API costs and latency. While various context compression approaches such as LongLLMLingua have emerged to tackle this challenge, they typically rely on fixed metrics such as PPL, ignoring the task-specific nature of code understanding. As a result, they frequently disrupt syntactic and logical structure and fail to retain critical implementation details. In this paper, we propose SWE-Pruner, a self-adaptive context pruning framework tailored for coding agents. Drawing inspiration from how human programmers "selectively skim" source code during development and debugging, SWE-Pruner performs task-aware adaptive pruning for long contexts. Given the current task, the agent formulates an explicit goal (e.g., "focus on error handling") as a hint to guide the pruning targets. A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal. Evaluations across four benchmarks and multiple models validate SWE-Pruner's effectiveness in various scenarios, achieving 23-54% token reduction on agent tasks like SWE-Bench Verified and up to 14.84x compression on single-turn tasks like LongCodeQA with minimal performance impact.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SWE-Pruner, a tool that helps AI coding assistants (like ChatGPT-style models that read and write code) deal with very large amounts of code without getting overwhelmed. When these assistants work on real software projects, they often read huge files and lots of surrounding text. That makes their jobs slower and more expensive because they have to process many “tokens” (small pieces of text the AI reads). SWE-Pruner “skims” the code and keeps only the lines that matter for the assistant’s current goal, so the assistant sees less noise and more of what’s relevant.
What problem is the paper trying to solve?
The core questions the paper asks are simple:
- Can we help AI coding assistants avoid reading too much unimportant code?
- Can we remove (prune) the right parts of the code while keeping the important structure intact?
- Will this make the assistants faster and cheaper to use without hurting their ability to solve problems?
In short, the paper aims to reduce the “context wall” (too much code in the assistant’s input) while still letting the assistant do its job well.
How does SWE-Pruner work?
Think of reading a giant textbook to answer one question. You wouldn’t read every page—you’d skim for the parts that match what you’re looking for. SWE-Pruner does this for code.
Here’s the idea, step by step:
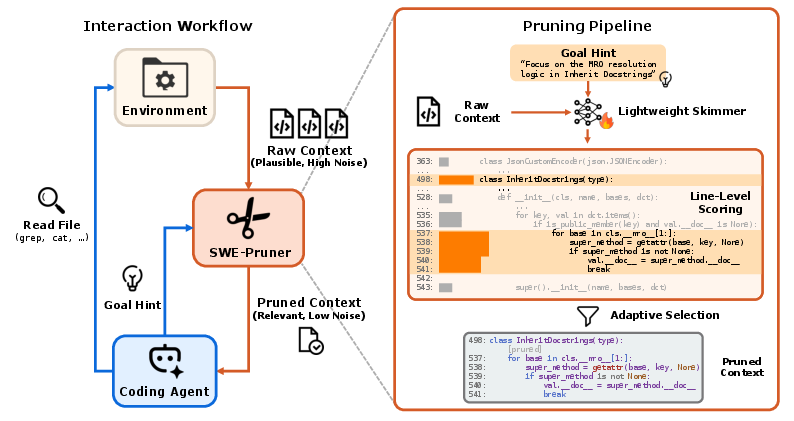
- The AI assistant tells SWE-Pruner its current goal using a short hint (like “focus on error handling” or “find how authentication works”). This is called a “Goal Hint.” It’s basically a note about what the assistant wants right now.
- When the assistant runs tools like
greporcat(which read files), SWE-Pruner sits in the middle like a smart filter (middleware). It intercepts the big chunk of code those tools return. - A small, fast neural network (about 0.6 billion parameters, much smaller than big LLMs) scores each line of the code based on the Goal Hint and decides which lines are relevant.
- SWE-Pruner returns just those important lines, keeping code structure intact. This reduces the number of tokens the assistant has to read.
To make the “skimmer” smart, the authors trained it on a large set of examples where an AI teacher prepared task-focused questions and labeled which lines of code mattered. The model also learns that code lines are connected (e.g., it should keep related lines together), so it doesn’t break the logic or syntax.
In everyday terms:
- The “Goal Hint” is like a search note: “Look for where errors are handled.”
- The “skimmer” is like a highlighter that marks only the useful lines and hides the rest.
- The “middleware” is like a filter placed between the file-reading tool and the assistant, so the assistant sees a cleaner view.
What did the experiments show?
The authors tested SWE-Pruner on both multi-step agent tasks (where the assistant interacts multiple times) and single-turn tasks (answering questions or completing code in one go). They tried different AI models and several benchmarks. Here’s what they found:
- On multi-step software tasks (like fixing real GitHub issues):
- SWE-Pruner reduced the amount of text (tokens) the assistant had to read by about 23–38% on SWE-Bench Verified.
- It often reduced the number of back-and-forth steps (rounds) by up to about 26%.
- The success rate (how often the AI solves the issue) stayed roughly the same—sometimes even slightly better.
- This means lower cost and faster runs, with little to no drop in quality.
- On single-turn long-code tasks (like answering questions about large codebases):
- SWE-Pruner achieved very high compression (up to about 14.8× fewer tokens) while keeping accuracy strong.
- Unlike methods that chop tokens blindly, SWE-Pruner’s line-level approach avoided breaking code syntax and kept important details.
- Compared to other compression methods:
- Token-level pruning methods (which delete text pieces without considering code structure) often hurt performance.
- Simple retrieval (RAG) sometimes missed fine-grained details.
- Summaries added delay and sometimes lost specifics.
- SWE-Pruner balanced compression and correctness best, because it keeps whole lines and listens to the current goal.
- Speed and overhead:
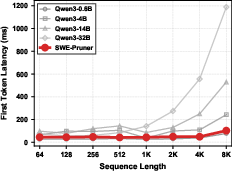
- The skimmer is small and fast, adding very little delay (first-token time often under 100 ms), while saving lots of downstream processing time and cost.
Why does this matter?
When AI coding assistants work on real software, they spend most of their time reading code, not just writing it. The more they read, the higher the cost and the slower the interaction. SWE-Pruner helps by filtering the reading step and focusing the assistant’s attention on the useful parts, like a good study technique. That means:
- Lower cost and faster results.
- Less confusion from noisy or irrelevant code.
- Fewer unnecessary steps to find the problem.
- Better scalability to huge codebases.
What’s the bigger impact?
This approach can make AI coding agents more practical in the real world: cheaper, quicker, and more reliable. It can also be combined with other tools (like methods that compress past conversation history), since SWE-Pruner focuses on pruning the environment’s observation (the code being read) rather than the assistant’s memory. While the current work focuses mostly on Python and adds a tiny bit of overhead, it shows a clear path toward smarter, goal-aware reading for many programming languages and tasks.
In short, SWE-Pruner helps AI assistants “read smarter, not harder,” which makes fixing bugs and understanding big codebases faster and more cost-effective.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to be actionable for future research.
- Multilingual generalization: Validate SWE-Pruner on diverse programming languages (e.g., Java, C/C++, JavaScript/TypeScript, Go, Rust) and multi-language repositories with different syntactic/semantic structures.
- Cross-file/context dependencies: Assess whether line-level pruning within individual files preserves dependencies across files (imports, shared state, configuration) and propose mechanisms to retain cross-file coherence.
- Syntactic and semantic validity checks: Quantify how often pruned contexts remain parsable/compilable and preserve semantic coherence (e.g., runnable tests, AST integrity, build success) across languages.
- AST-aware pruning: Compare line-level pruning against AST/block/function-level granularity; explore hybrid approaches that respect code structure boundaries (decorators, docstrings, indentation blocks).
- Goal hint reliability: Systematically evaluate how hint quality affects pruning outcomes; develop robustness mechanisms for sparse, noisy, or incorrect hints (confidence estimation, automatic fallback, hint refinement).
- Automatic hint generation: Investigate deriving goal hints from tool arguments and agent actions (e.g., grep patterns, error traces, stack frames) to reduce reliance on LLM-generated hints.
- Adaptive bypass policy: Design and evaluate policies to automatically bypass pruning when exploration is needed, including uncertainty detection and task-stage classifiers.
- Thresholding strategy: Detail and evaluate the dynamic thresholding mechanism (selection, calibration, per-task adaptation); consider learning τ end-to-end or via meta-learning to optimize the compression–performance trade-off.
- Chunking long contexts: Provide and evaluate the chunking/merging strategy for raw outputs exceeding the skimmer’s context window (e.g., >8K tokens), including cross-chunk dependencies and aggregation methods.
- Latency and resource placement: Report end-to-end agent latency (including I/O and tool calls), and study optimal deployment (CPU/GPU placement, batching, concurrency) to ensure cost-benefit holds under load.
- Failure mode taxonomy: Build a systematic analysis of when pruning harms performance (e.g., removing subtle invariants, tests, or configuration lines), and propose mitigation strategies.
- Security and safety implications: Evaluate whether pruning hides or removes security-critical code/comments (e.g., input validation, auth checks), and develop safety-preserving filters or policies.
- Robustness to adversarial/noisy retrieval: Test scenarios where grep/patterns return misleading or duplicate lines (code clones, generated files) and design defenses against overfitting to spurious signals.
- Dataset quality and bias: Replace or complement synthetic silver labels with human-annotated datasets; quantify teacher-LLM bias, hallucinations, and label errors; release auditing/QA protocols.
- Data leakage assessment: Provide rigorous contamination analyses across all benchmarks (including SWE-Bench variants and LongCodeQA) to ensure training–evaluation independence.
- CRF vs simpler heads: Ablate the CRF-based pruning head against simpler token/line classifiers and sequence models; justify CRF’s benefits with controlled experiments and statistical significance.
- Reranking head usage: Clarify how document-level relevance from the reranking head is used during inference; evaluate whether integrating doc-level signals improves pruning decisions.
- Model scale ablations: Explore performance/latency trade-offs across skimmer sizes (e.g., 100M–1B) and architectures (bi-encoders vs cross-encoders), including distillation and early-exit methods.
- Extreme long-context cases: Validate behavior on ultra-long contexts (e.g., 100k–1M tokens) with explicit strategies for sliding windows, hierarchical summarization, or multi-pass pruning.
- Closed- vs open-source backbones: Extend evaluations beyond Claude Sonnet 4.5 and GLM-4.6 to a wider set of open-source LLMs with different tokenizers and attention patterns; report variability and generalization.
- Combination with history compression: Study how observation pruning composes with trajectory/history compression (e.g., AgentFold, ACON), including scheduling and joint optimization policies.
- Compression ratio control: Provide mechanisms to target and reliably achieve specified compression budgets (4x/8x) without overshooting; quantify trade-offs and controllability under different tasks.
- Real-world deployment studies: Conduct longitudinal evaluations in live repositories/CI pipelines (developer-in-the-loop, IDE integration), measuring productivity, bug resolution time, and operational costs.
- Privacy and compliance: Analyze whether middleware pruning introduces new data handling risks (PII, licensing headers, compliance notes) and design privacy-preserving filters.
- Benchmark coverage and statistical rigor: Increase sample sizes for baseline comparisons on SWE-Bench; include confidence intervals, significance testing, and variance analyses across seeds/runs.
- Logs and non-code artifacts: Evaluate pruning effectiveness on test logs, build outputs, configs (YAML/TOML/JSON), and documentation, which often drive agent reasoning.
- Non-English comments and identifiers: Assess performance with code/comments in non-English languages and mixed scripts; develop multilingual hinting and pruning strategies.
- Agent behavior shifts: Investigate why GLM-4.6 increases rounds post-pruning and design mitigation (e.g., hint refinement, exploration policies) to harmonize behavior across models.
- Reproducibility of training: Provide corrected, executable loss formulations and training code; resolve equation typos and share full hyperparameters, data generation prompts, and annotation pipelines.
- Evaluation of hallucination/attention effects: Directly measure whether pruning reduces attention dilution and hallucinations claimed to arise from long noisy contexts.
- Patch quality analysis: Beyond success rates, analyze types of patches produced (bug categories, diff quality, test coverage impact) to understand qualitative effects of pruning.
- Cost accounting: Include the pruner’s compute cost in aggregate API/GPU cost analyses to present net savings under realistic deployment constraints.
Practical Applications
Immediate Applications
The following applications can be deployed with minimal additional research, leveraging SWE-Pruner’s middleware design, goal-hint interface, and 0.6B neural skimmer with line-level pruning.
- Software engineering (enterprise coding agents)
- Application: Reduce token/cost and latency in multi-turn coding agents (e.g., SWE-Bench-like issue resolution, repo QA), by inserting SWE-Pruner as middleware to intercept read operations (cat/grep) and return pruned context based on agent-provided goal hints.
- Tools/products/workflows: “Pruning Proxy” microservice or library; add
context_focus_questionparameter to file tools; integrate with existing frameworks such as Mini SWE Agent or OpenHands; use Qwen3-Reranker-0.6B-based skimmer. - Expected impact: 23–38% token reduction on SWE-Bench Verified; up to 26% fewer rounds; 29–54% token reduction in repo QA; proportionate cloud API cost savings.
- Assumptions/dependencies: Agents must reliably generate concise, task-aware goal hints; codebases primarily Python (current training focus); minor engineering needed to wrap file tools; small latency overhead (<100 ms TTFT up to 8k tokens).
- Software engineering (IDE assistants and developer tooling)
- Application: VS Code/JetBrains extension that prunes large file reads and search outputs before sending to LLM assistants for debugging, code comprehension, or refactoring.
- Tools/products/workflows: A local daemon or plugin that implements
grep_with_pruner, intercepts editor file-search results, and applies line-level pruning guided by developer prompts (“focus on error handling”). - Expected impact: Faster assistant responses, fewer hallucinations from noisy context, real-time cost control for cloud-based assistants.
- Assumptions/dependencies: Plugin access to editor API; developer willingness to provide goal hints or preset “focus templates”; acceptable local CPU/GPU for 0.6B model.
- DevOps/CI (LLM fixers and automated triage)
- Application: Insert SWE-Pruner in CI bots that read test logs and source files to propose patches, reducing prompt size and stabilizing syntax retention in patches.
- Tools/products/workflows: CI step that wraps read actions (cat/grep), uses task-specific goal hints derived from failing tests (e.g., “focus on MRO resolution,” “focus on auth errors”), and prunes content before LLM patch generation.
- Expected impact: Lower API bills per run, fewer flaky edits from token-level compression, faster triage cycles.
- Assumptions/dependencies: Stable mapping from test failures to goal hints; CI agents must expose read operations for interception; compute budget for skimmer.
- Security and compliance (privacy-preserving assistant usage)
- Application: Minimize exposure of sensitive code when calling external LLMs by pruner-mediated “least context necessary,” keeping more computation on-prem and reducing raw code exfiltration.
- Tools/products/workflows: A “Pruning Gateway” that runs locally to prune before sending prompts to cloud LLM; add PII redaction and file-path whitelisting.
- Expected impact: Reduced risk surface and audit footprint; balance between productivity and data governance.
- Assumptions/dependencies: Policies and DLP tools to complement pruning; acceptance that pruner sees raw code locally; adequate logging/compliance controls.
- Repository Q&A/chatops (developer productivity)
- Application: Slack/Teams bots for repo Q&A that route retrieval results through SWE-Pruner given a user’s natural-language question (“How is authentication handled?”), returning focused code snippets.
- Tools/products/workflows: Chatbot pipeline with goal hint = user query; embedding retrieval + line-level pruning; deploy as internal dev assistant.
- Expected impact: More accurate and concise answers; reduced token usage in long monorepos.
- Assumptions/dependencies: Reliable retrieval stage; correct language settings; permission model for repo access.
- Academic research (agent evaluation and efficiency studies)
- Application: Use SWE-Pruner to study trade-offs in agent trajectories, token savings, and decision quality; replicate benchmarks (SWE-Bench Verified, SWE-QA, Long Code QA/Completion) and extend ablation studies.
- Tools/products/workflows: Open-source integration; synthetic training data pipeline; agent trajectory analytics.
- Expected impact: Faster experimentation; standardized efficiency baselines for long-context tasks.
- Assumptions/dependencies: Access to benchmark environments; reproducible agent configs; careful handling of potential data leakage.
- Daily developer workflows (personal productivity)
- Application: CLI wrappers around grep/cat that accept a question (goal hint) and return pruned outputs ready to paste into ChatGPT/Claude; reduce copy-paste noise when consulting AI on large files.
- Tools/products/workflows: A simple local script (
grep_with_pruner) and a small model runtime; prebuilt “focus presets” (e.g., logging, error handling, data validation). - Expected impact: Less time spent curating contexts; fewer LLM misreads; lower usage costs.
- Assumptions/dependencies: Local runtime for the 0.6B model; basic command-line familiarity; benefit scales with file length.
- Energy and cost management (organizational policy guidance)
- Application: Adopt “prune-first” organizational guidelines for AI coding tools to reduce compute and carbon footprint before increasing context windows.
- Tools/products/workflows: Engineering standards requiring pruning middleware in agent stacks; budget dashboards reflecting token savings.
- Expected impact: Immediate reductions in GPU-hours and API spend.
- Assumptions/dependencies: Policy compliance and tooling adoption; accurate monitoring of token and cost metrics.
Long-Term Applications
The following applications require further research, scaling, or development before broad deployment.
- Multilingual and multi-ecosystem support (software industry)
- Application: Extend SWE-Pruner training to diverse languages (Java, JS/TS, C/C++, Go, Rust) and frameworks; handle language-specific syntax and comments more robustly.
- Tools/products/workflows: Polyglot training corpus and line segmentation; language-aware thresholds; model distillation for on-device use.
- Dependencies: High-quality, language-diverse labeled data; revalidation on non-Python repositories; potential AST-aware segmentation.
- AST-aware and structure-preserving pruning (software, security)
- Application: Combine line-level scoring with AST and control/data-flow awareness to preserve invariants and critical semantics; improve correctness in patch generation and code auditing.
- Tools/products/workflows: Hybrid skimmer (encoder + AST parsers); code intelligence features (symbol links, call graphs).
- Dependencies: Reliable parsing across languages; new training objectives; benchmarking on semantics-sensitive tasks.
- Learned pruning policies and planning (agent research)
- Application: Jointly learn when to prune, how much to prune, and how to generate goal hints via reinforcement learning or supervised trajectory imitation; cost-aware agent planning under token budgets.
- Tools/products/workflows: Integration with history-compression managers (e.g., AgentFold/ACON); dynamic thresholds; meta-controllers that balance exploration vs focus.
- Dependencies: Long-horizon training, safe RL, reward shaping tied to task outcomes and cost; robust evaluation suites.
- Domain transfer beyond code (logs/configs/docs) in industry verticals
- Application: Adapt query-aware, line-level pruning to operational logs (SRE), configurations (DevOps), technical documentation (support), contracts (legal) and clinical notes (healthcare) for focused AI assistance on long artifacts.
- Sectors: SRE/ops, legal, healthcare, customer support.
- Tools/products/workflows: Domain-specific training data; privacy-preserving local runtimes; compliant redaction pipelines.
- Dependencies: New datasets with line-level labels; text-specific heuristics (e.g., section boundaries vs code lines); governance for sensitive data.
- Secure “Agent Observation Firewall” (security, compliance)
- Application: Enterprise gateway that prunes and sanitizes agent observations (files, logs) before passing to any LLM, enforcing PII redaction, policy-based filtering, and minimal exposure by design.
- Tools/products/workflows: Policy engine; audit logs; integration with DLP/SAST; redaction + pruning stack.
- Dependencies: Accurate policy enforcement; performance at scale; regulatory audits; robust change management.
- Standardization and procurement policy (organizational governance)
- Application: Industry standards for “efficient-context AI agents,” including metrics and SLAs for token savings vs task success; procurement requirements to include pruning capabilities for vendor tools.
- Tools/products/workflows: Benchmark-driven RFP criteria; dashboards tracking compression ratios and success rates; sustainability reporting.
- Dependencies: Consensus on metrics; third-party certification; open benchmarking corpora.
- Education and training (academia, edtech)
- Application: Code tutoring that uses pruning to highlight relevant lines/regions for lessons, debugging exercises, and formative feedback; “focus mode” for teaching code comprehension strategies.
- Tools/products/workflows: Classroom IDEs with guided goal hints; analytic feedback on student reasoning paths.
- Dependencies: Pedagogical validation; alignment to curricula; privacy when analyzing student code.
- Hardware/edge acceleration (systems)
- Application: Optimize 0.6B skimmer for edge devices or embedded developer machines (quantization, early-exit), enabling on-device pruning for privacy-critical workflows.
- Tools/products/workflows: Quantized inference; CPU-friendly models; streaming APIs.
- Dependencies: Model compression without accuracy loss; efficient parallelization; device heterogeneity.
- Finance and cost governance (enterprise)
- Application: Token-budget planning and automated cost controls: agents auto-adjust pruning aggressiveness to stay within monthly budgets while meeting resolve-rate targets.
- Tools/products/workflows: Budget-aware agent orchestration; cost forecasting; policy-triggered pruning thresholds.
- Dependencies: Reliable cost telemetry; business rules; acceptance of slight performance trade-offs under budget constraints.
Glossary
- Abstractive summaries: Model-generated condensed text that paraphrases source content rather than copying verbatim code or tokens. "LLM Summarize that generates abstractive summaries using the backbone model."
- Abstractive techniques: Compression approaches that rewrite content at a higher level, often losing exact token or character details. "abstractive techniques discard character-level information critical for debugging"
- Adaptive selection: Dynamically choosing relevant content based on current goals or queries. "enabling adaptive selection conditioned on given goals"
- Agentic workflows: Multi-step, goal-driven interactions where an LLM agent plans, retrieves, and acts within an environment. "covering common information needs in real-world agentic workflows."
- Attention dilution: Degradation of model focus due to excessive or noisy context, spreading attention over irrelevant tokens. "introduces severe noise, leading to attention dilution and hallucinations"
- Binary line-level mask: A per-line 0/1 annotation indicating whether a line should be retained or pruned. "M is a binary line-level mask indicating which lines to retain"
- Coarse-grained file operations: Broad file-reading actions (e.g., streaming whole files) that retrieve large, noisy context. "agents must extensively explore through coarse-grained file operations that stream entire files or blocks into the context."
- Coarse-grained retrieval: Chunk-level fetching of information that may miss fine-grained details. "three categories of baselines: token-level compression (LLMLingua2), coarse-grained retrieval (RAG), and generative summarization (LLM Summarize)."
- Compression constraints: Target limits (e.g., 4x, 8x) imposed on how much the context must be reduced. "evaluating under 4x and 8x compression constraints."
- Compression ratio: A measure of how much the context is reduced relative to the original size. "The table compares the performance and compression ratio () under 4x and 8x constraints."
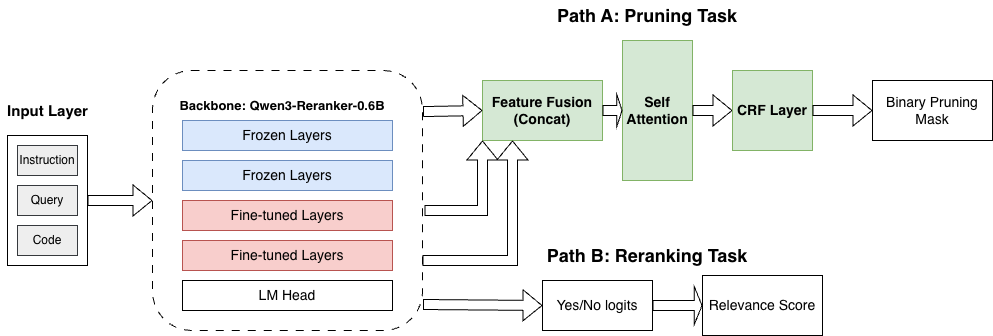
- Conditional random field negative log likelihood (CRF-NLL): A structured loss for sequence labeling that models transitions between labels. "We train the pruning model by minimizing the conditional random field negative log likelihood (CRF-NLL)"
- Context compression: Techniques to reduce the length of input context while preserving essential information. "Although context compression techniques offer a potential remedy, existing approaches face critical limitations when applied to coding agents."
- Context Wall: The practical barrier caused by extremely long, unwieldy code contexts during agent navigation. "Navigating real-world software repositories confronts agents with a massive ``Context Wall.''"
- Context window: The maximum number of tokens an LLM can attend to in a single input. "Modern coding LLMs support context windows of 128k tokens or more"
- Document-level relevance score: A scalar assessing the overall importance of a document/chunk with respect to a query. "where is a binary line-level mask indicating which lines to retain and is a document-level relevance score."
- Edit Similarity (ES): A code completion metric comparing predicted edits to ground truth edits. "Task performance is measured through Edit Similarity (ES) and Exact Match (EM) for code completion"
- Effective compression ratios: Realized compression beyond nominal targets due to model’s selective pruning efficiency. "Notably, SWE-Pruner achieves substantially higher effective compression ratios than baselines configured at identical compression targets."
- Embedding similarity: Retrieval by comparing vector representations of code or text for semantic proximity. "RAG which retrieves code chunks via embedding similarity using UniXCoder"
- Exact Match (EM): A strict metric counting instances where the predicted code exactly matches the ground truth. "Task performance is measured through Edit Similarity (ES) and Exact Match (EM) for code completion"
- First token latency: Time to generate the first token during inference, reflecting initial computation cost. "First token latency comparison across different sequence lengths."
- Generative summarization: Producing a natural-language summary via an LLM to condense context. "three categories of baselines: token-level compression (LLMLingua2), coarse-grained retrieval (RAG), and generative summarization (LLM Summarize)."
- Goal Hint: A natural-language description of the agent’s current information need that guides pruning. "the agent generates a Goal Hint describing its current information need (e.g., ``Focus on MRO resolution logic'')."
- Hallucinations: Fabricated or incorrect outputs produced by an LLM, often due to noisy or insufficient context. "introduces severe noise, leading to attention dilution and hallucinations"
- Hierarchical oversight: Multi-level control frameworks that supervise or steer agent behavior and memory. "others like COMPASS, ACON, AgentDiet, and AgentFold introduce hierarchical oversight or proactive folding policies."
- History managers: Systems that learn to compress or manage prior agent interaction histories. "can be seamlessly combined with such learned history managers."
- Line-level granularity: Operating at the code line level for scoring and pruning to preserve syntax and structure. "By operating at line-level granularity, our approach preserves syntactic and structural integrity"
- Line-level relevance score: The aggregated importance score computed per code line for retention decisions. "The line-level relevance score is computed as the average of its constituent token scores:"
- LLM-as-a-Judge: Using an LLM to assess data or outputs for quality control or evaluation. "We employ an LLM-as-a-Judge filtering mechanism"
- Middleware: Software that sits between an agent and environment, intercepting and transforming data. "SWE-Pruner operates as middleware between coding agents and their environment."
- MRO (Method Resolution Order): The order in which methods are searched on class hierarchies in object-oriented languages like Python. "Focus on MRO resolution logic"
- Multi-turn agent tasks: Problems requiring iterative interactions, retrievals, and edits across several rounds. "We evaluate SWE-Pruner across multi-turn agent tasks (SWE-Bench Verified and SWE-QA)"
- Neural skimmer: A lightweight model that scores and selects relevant lines from large contexts. "A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal."
- Perplexity (PPL): A language-model metric indicating how well a model predicts a sequence; often misused for pruning code. "they typically rely on fixed metrics such as PPL"
- Prompt compression: Reducing the input prompt size to lower cost and latency while maintaining performance. "Prompt compression has been extensively studied for both natural language and code."
- Query-conditioned thresholding: Applying an adaptive retention cutoff that depends on the current query/goal. "an adaptive, query-conditioned thresholding mechanism."
- RAG (Retrieval-Augmented Generation): Systems that combine retrieved documents with generation to improve answers. "RAG which retrieves code chunks via embedding similarity using UniXCoder"
- Reranking: Reordering items (tokens/lines/documents) by relevance to a given query. "We formulate context pruning as a reranking problem"
- Reranking head: The model component that predicts document-level relevance scores for ordering. "We keep the original reranking head in Qwen Reranker"
- Resolve Rate: The percentage of issues successfully fixed by the agent on a benchmark like SWE-Bench. "Resolve Rate on SWE-Bench Verified"
- Semantic coherence: Preservation of meaningful relationships and readability within pruned code. "maintaining the semantic coherence necessary for code comprehension."
- Sequence-length normalization: Loss scaling that accounts for sequence length to avoid biased pruning. "sequence-length normalization, which prevents bias toward aggressive pruning in long contexts."
- Silver labels: Imperfect but useful supervisory labels produced by automated or teacher models. "Given the context representation ... and silver labels "
- Structured pruning: Retention/removal decisions that respect sequence structure and transitions. "enabling the model to learn structured pruning patterns that respect code boundaries."
- Threshold τ: The cutoff score used to decide whether a line is retained during pruning. "a line is retained if its aggregated score exceeds a predefined threshold ."
- Token budget: The available token capacity that agents must manage across actions and rounds. "coding agents spend an excessive amount of their token budget on repeatedly exploring the codebase"
- Token consumption: The number of tokens used in prompts and interactions, linked to cost and latency. "SWE-Pruner reduces token consumption by 23--38\% while maintaining comparable success rates."
- Token-level pruning: Removing individual tokens based on metrics like perplexity, often harming code syntax. "token pruning methods compromise syntactic validity"
- Trajectory analysis: Examining the sequence of agent actions/rounds to understand behavior and performance. "Through trajectory analysis, we find that after pruning, GLM tends to explore more files before formulating answers"
Collections
Sign up for free to add this paper to one or more collections.