- The paper introduces Lita, a minimal agentic framework that reduces prompt engineering and manual intervention to reveal intrinsic LLM coding capabilities.
- The methodology leverages a simplified toolkit with explicit reasoning and memory components to transform benchmarks into a unified, multi-turn format.
- Experimental results indicate that Lita achieves higher pass rates and lower token consumption compared to complex workflow-based agents, supporting the Agent Complexity Law.
Lita: Minimal Agentic Framework for Evaluating LLM Coding Competence
Motivation and Problem Statement
The paper introduces Lita, a lightweight agentic framework designed to evaluate the coding capabilities of LLMs with minimal manual scaffolding. The motivation stems from the observation that current agentic and workflow-based systems for code tasks are heavily reliant on complex, hand-crafted workflows, extensive prompt engineering, and elaborate toolsets. These practices introduce confounding factors: they obscure the intrinsic capabilities of LLMs, inflate benchmark scores, and impose significant overhead in terms of design, maintenance, and token consumption. Lita operationalizes the principle of "liteness"—minimizing manual intervention while retaining the essential elements of autonomous agentic behavior—to enable more faithful, unified, and efficient evaluation of LLMs on coding tasks.
Agentic System Design: Principles and Architecture
Lita is built on four core design philosophies: decoupling the agent from specific LLMs and tasks, prioritizing simplicity over complexity, eschewing workflow-centric designs in favor of autonomy, and minimizing prompt engineering to trust the evolving capabilities of models. The agent system comprises three main components: tools, reasoning, and memory.
- Tools: Lita restricts its toolset to those strictly necessary for software engineering tasks—Editor, Terminal, Search, and Finish—invoked via function calls. Tool schemas are designed to be compact and unambiguous, avoiding over-engineering and benchmark-specific optimizations.
- Reasoning: The agent supports explicit reasoning through Think and Plan tools, enabling structured self-reflection and planning without embedding workflow instructions.
- Memory: Lita implements both linear (full interaction history) and summarized memory (LLM-driven condensation), defaulting to linear memory to best expose long-context management capabilities.
This minimal architecture is contrasted with workflow-heavy systems such as Aider and Agentless, and with more complex agentic frameworks like OpenHands.
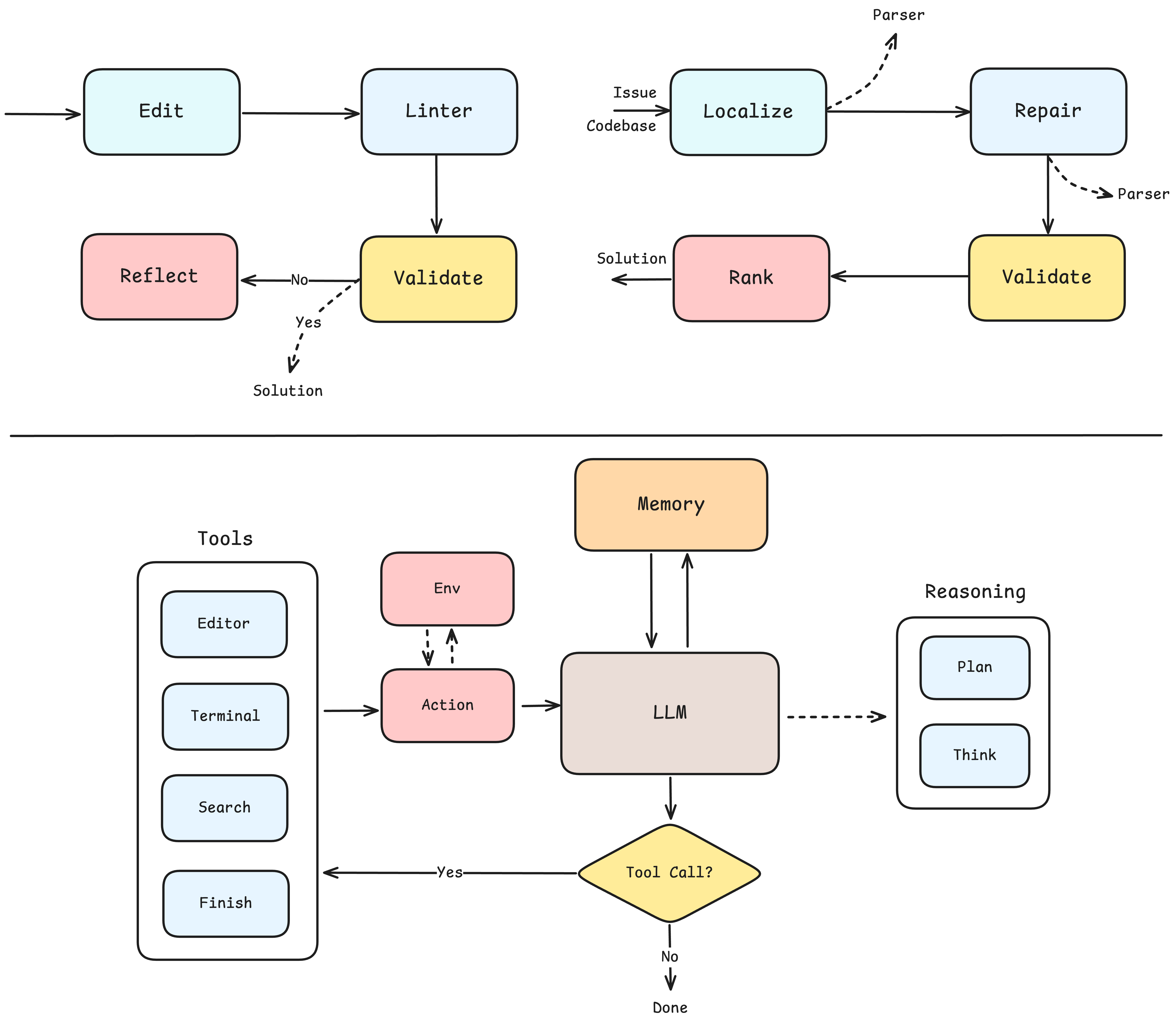
Figure 1: Comparison of workflow-based agents (Aider, Agentless) and the Lita autonomous agent framework, highlighting the decoupled, minimal architecture of Lita.
A key contribution is the transformation of widely used code benchmarks (HumanEval, Aider's Polyglot, SWE-Bench Verified) into agentic, multi-turn formats. Each benchmark instance is reformulated into a prompt template with four essential components: Initial State, Task Description, Output State, and Validation Steps. This harmonization enables fair, unified evaluation across diverse tasks and models, eliminating model-specific prompt optimizations.
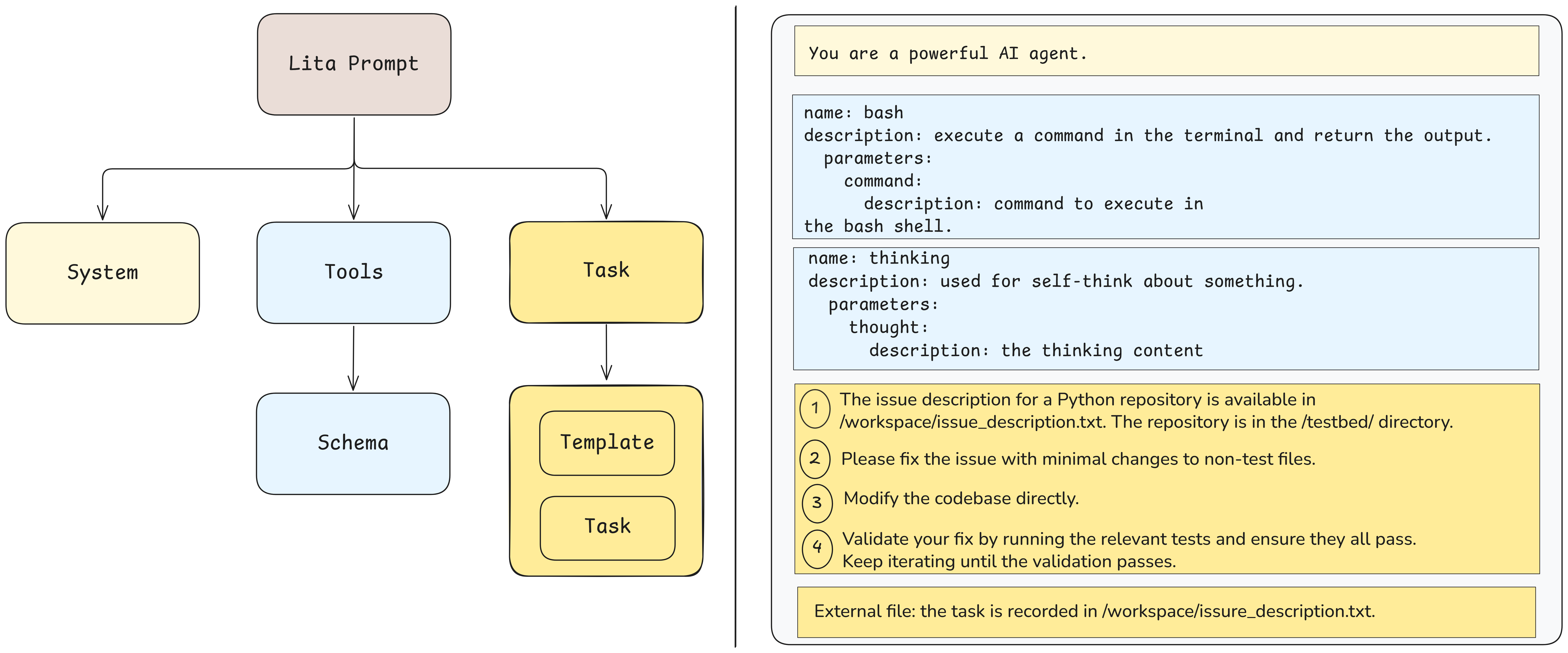
Figure 2: General agent system prompt components and a specific example of Lita's prompt design for SWE-Bench, illustrating the four-part template.
Quantifying Agent Complexity
The paper introduces Agent Intrinsic Complexity as a quantitative measure of agent design "liteness," defined by the number of supported tools and the system preloaded token cost (system prompt, initial user prompt, tool schema). This metric enables principled comparison of Lita against workflow-heavy and agent-rich baselines, and facilitates analysis of how design complexity impacts evaluation fidelity and model performance.
Experimental Evaluation
Datasets and Models
Lita is evaluated on HumanEval (function-level completion), Aider's Polyglot (multi-language code generation), and SWE-Bench Verified (real-world bug fixing), spanning a spectrum of task difficulty. Experiments cover both proprietary (GPT, Claude) and open-source (Qwen) models, enabling analysis across varying model strengths.
Scaffolding Paradigms
Three paradigms are compared:
- Workflow systems (Aider, Agentless)
- Agentic systems (OpenHands, mini-SWE-agent)
- Lita and its variants (Lita-diff, Lita-mini)
Key Results
- Lita vs. OpenHands: Lita consistently achieves higher pass rates and lower token consumption across most models and tasks, especially on Polyglot. This suggests that heavy optimization for specific benchmarks (as in OpenHands) leads to overfitting and reduced generality.
- Lita vs. Aider: Workflow guidance in Aider yields higher early-stage pass rates, but agentic methods (Lita) allow for autonomous recovery and iterative improvement, resulting in higher final resolution rates for stronger models.
- Editing Strategies: String replacement editing outperforms diff-based editing, particularly for weaker models, due to improved instruction-following.
- Minimal Tool Sufficiency: Terminal-only agents (Lita-mini) achieve competitive results on strong models, but explicit editing and reasoning tools remain necessary for weaker models.
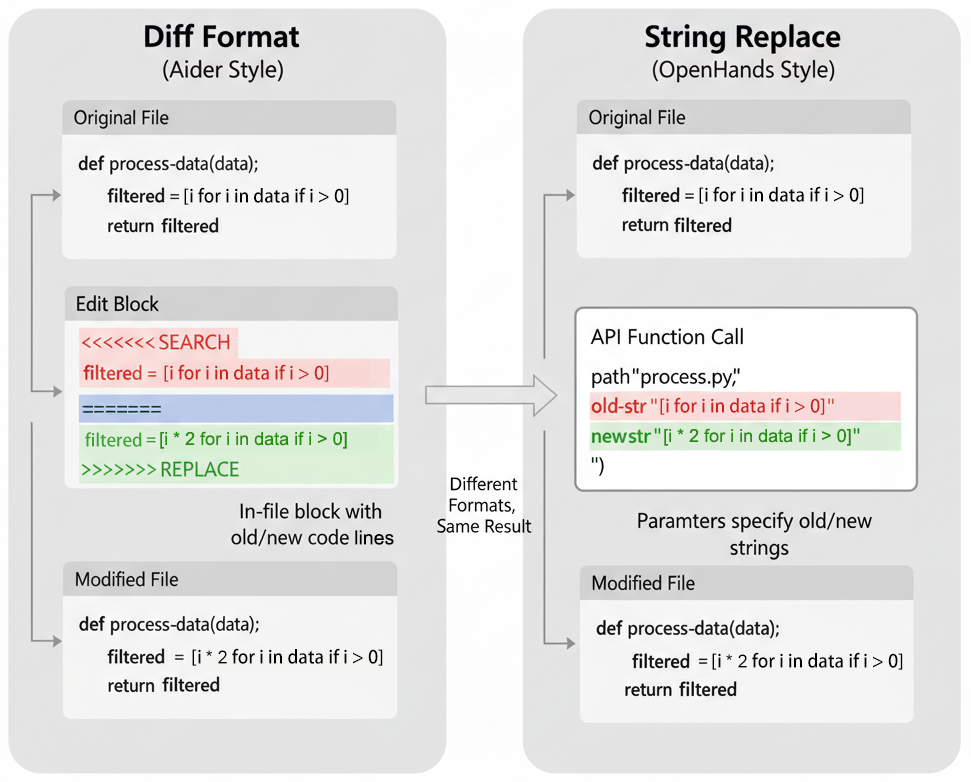
Figure 3: Comparison of diff block and string replace editing strategies, demonstrating the superior performance of string replacement for weaker models.
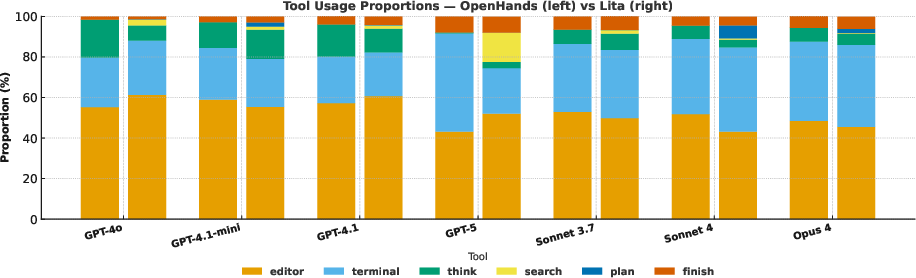
Figure 4: Distribution of tool call proportions across models and agent frameworks, highlighting Lita's emphasis on reasoning (Think, Plan) over repetitive edits.
Agent Complexity Law and Scaling Behavior
A central theoretical claim is the Agent Complexity Law: as the core model improves, the performance gap between agents of varying complexity (from simple to sophisticated designs) shrinks, ultimately converging to a negligible difference. Empirical results support this: on both Polyglot and SWE-Bench, performance gaps between Lita and more complex frameworks diminish as model strength increases. On simpler tasks, lightweight agents can even outperform complex systems.
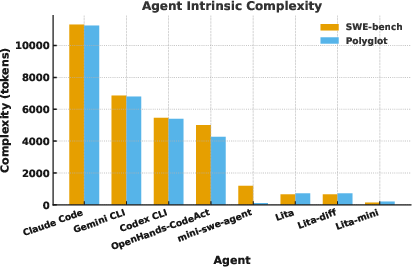
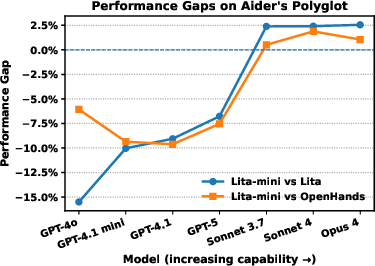
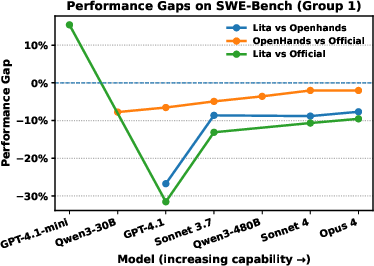
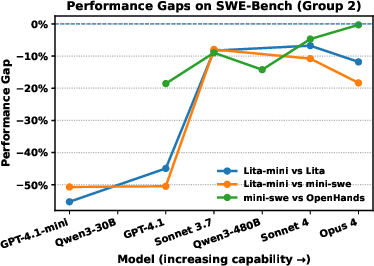
Figure 5: Agent Intrinsic Complexity and performance gaps between simple and complex agents, showing convergence of performance as model strength increases.
Discussion: Implications and Limitations
The findings have several practical and theoretical implications:
- Evaluation Fidelity: Minimal agentic frameworks like Lita provide more authentic evaluation of LLM coding competence, reducing confounding effects from prompt engineering and workflow-specific optimizations.
- Overhead Reduction: Lita's design reduces token consumption and development effort, improving scalability and portability across tasks and models.
- Autonomy and Robustness: Stronger models exhibit effective self-exploration and recovery in minimal agentic settings, while weaker models benefit from explicit reasoning and editing tools.
- Limitations: The current benchmarks and agent design do not cover multi-repository projects, collaborative development, or long-term maintenance. Advanced features (retrieval, web search, multi-agent collaboration) and post-training are not included, and long-term human-agent interaction remains unexplored.
Future Directions
The results suggest a shift in agent design philosophy: as LLMs continue to improve, the need for elaborate scaffolding will diminish, and evaluation frameworks should prioritize minimalism to better reveal intrinsic model capabilities. Future research should extend agentic evaluation to more complex, collaborative, and long-term software engineering scenarios, and explore the integration of advanced features within minimal agentic architectures.
Conclusion
Lita demonstrates that minimal agentic frameworks are sufficient to uncover the true coding capabilities of modern LLMs, challenging the necessity of complex, workflow-heavy designs. The Agent Complexity Law posits that as model strength increases, the marginal utility of architectural complexity vanishes. This has significant implications for both evaluation methodology and practical deployment of LLM-based coding agents, advocating for a paradigm shift toward simplicity, fairness, and authenticity in agentic system design.