- The paper presents a bifurcated fine-tuning pipeline that separates semantic reasoning (SWE-Zero) from execution-based refinement (SWE-Hero) to improve software engineering agents.
- It leverages large-scale, execution-free training using distilled LLM trajectories to efficiently process real-world code without resource-heavy containerization.
- Empirical results on SWE-bench benchmarks show enhanced performance, cross-lingual generalization, and significant token efficiency improvements.
Execution-free to Execution-based Fine-tuning for SWE Agents: The SWE-Zero to SWE-Hero Paradigm
Introduction
This work establishes a bifurcated supervised fine-tuning (SFT) pipeline for software engineering (SWE) agents, termed SWE-Zero to SWE-Hero, that systematically decouples foundational semantic reasoning from grounded execution-based refinement. The proposed recipe addresses the critical scalability limitations of prior agentic frameworks, which rely extensively on resource-heavy, containerized environments for trajectory collection and training. By structuring the curriculum into a large-scale, execution-free phase (SWE-Zero) followed by a selective, execution-grounded refinement phase (SWE-Hero), the method demonstrates both superior efficiency and strong empirical results on standardized benchmarks.
Motivation and Framework Design
The primary constraint in scaling open-source SWE agents has been the dependence on Docker-based environments for task-level verification during learning. This introduces severe overheads in data curation, distributed training, and inference—especially as a sizable fraction of real-world repositories fail to build reliably when containerized, thus discarding otherwise valuable data.
The SWE-Zero approach circumvents this bottleneck by leveraging high-capacity LLMs as teacher models to distil execution-free agent trajectories, relying solely on static codebase analysis and internalized world models for issue resolution. This unlocks the previously inaccessible “long tail” of repository data. To compensate for the absence of runtime verification, trajectories are curated via a multistage filter that aggressively prunes non-coherent or invalid rollouts.
The SWE-Hero stage bridges semantic intuition with rigorous, executable grounding. A smaller, high-fidelity set of execution-based trajectories are distilled in a containerized environment, facilitating targeted SFT that instills robust feedback-driven workflows. The sequencing of these two regimes enables agents to internalize code semantics at scale before incurring the cost of physical execution, resulting in improved inductive bias and sample efficiency.
Pipeline and Data Curation
Task instances are aggregated from recent open-source SWE datasets, totaling more than 180k instances across 3,500+ repositories. The SWE-Zero dataset contains 300k trajectories, distilled from 150k real-world Python pull requests (PRs) without repository-specific execution, while the SWE-Hero dataset encompasses 13k container-backed, execution-verified rollouts. Agentic interaction is realized on the OpenHands platform, with Qwen3-Coder-480B as the teacher LLM for trajectory generation.
Two distinct scaffolds are established: one sandboxed and deprived of runtime feedback (SWE-Zero), and one fully containerized (SWE-Hero). Strict pipeline checks enforce the absence of prohibited tool calls and filter trajectories for logical consistency, step limits, and use of only whitelisted actions.
Experimental Results
The approach is evaluated on SWE-bench Verified and Multilingual benchmarks, both of which demand repository-level reasoning and practical patching in diverse real-world codebases. SWE-Hero agents surpass the majority of same-scale open-source baselines, particularly in the small and mid-scale (7B, 14B) LLM regimes.
SWE-Hero-32B achieves a 62.2% resolution rate on SWE-bench Verified (Table 1/Figure 1), matching or outperforming models with far higher data and infrastructure costs, such as OpenSWE-32B.
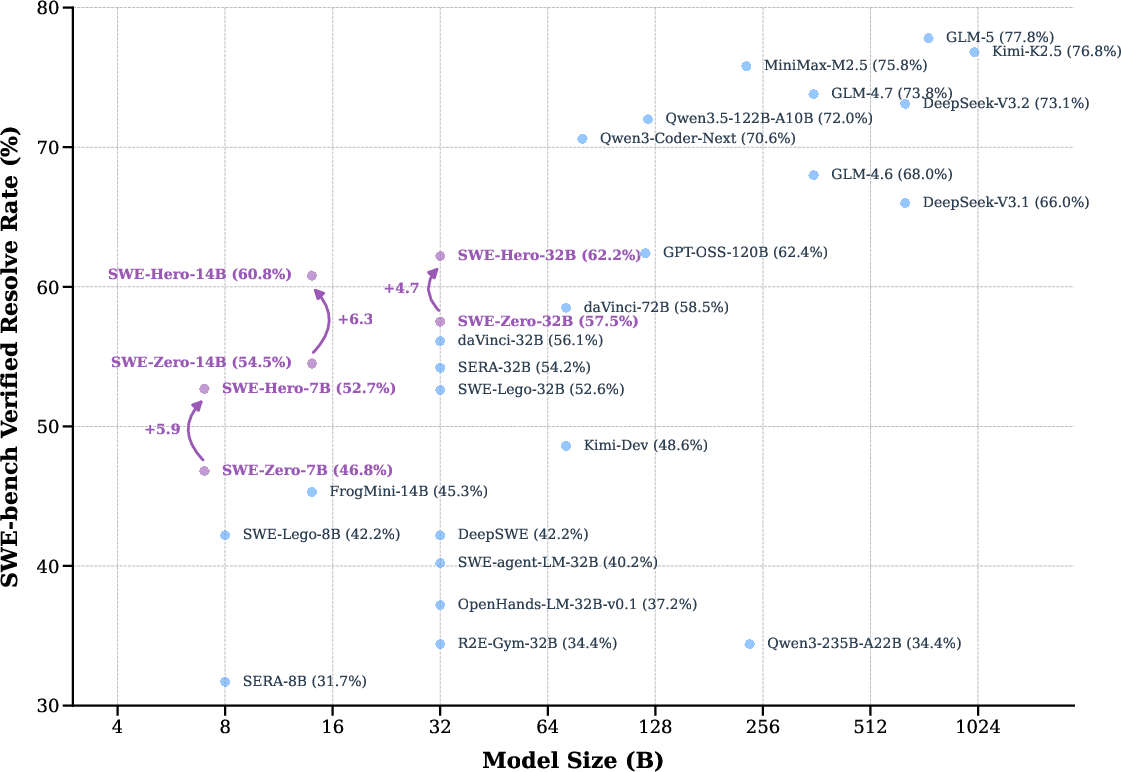
Figure 1: Performance overview of SWE-Hero and other models on SWE-bench Verified; SWE-Hero sets a new efficiency frontier for open-source agents.
Notably, ablations demonstrate that omitting the SWE-Zero phase—training directly on execution-based rollouts—yields substantially inferior results, indicating that large-scale semantic pretraining provides a critical inductive bias for robust agentic behaviors. Furthermore, the framework demonstrates strong cross-lingual generalization: despite training solely on Python, SWE-Hero-32B attains 44.1% zero-shot accuracy on SWE-bench Multilingual.
SWE-Zero trajectories are not only more data-efficient (40% lower token usage per instance), but also scale gracefully with data volume, with measurable gains in final accuracy as the corpus expands from 4k to 150k PRs.
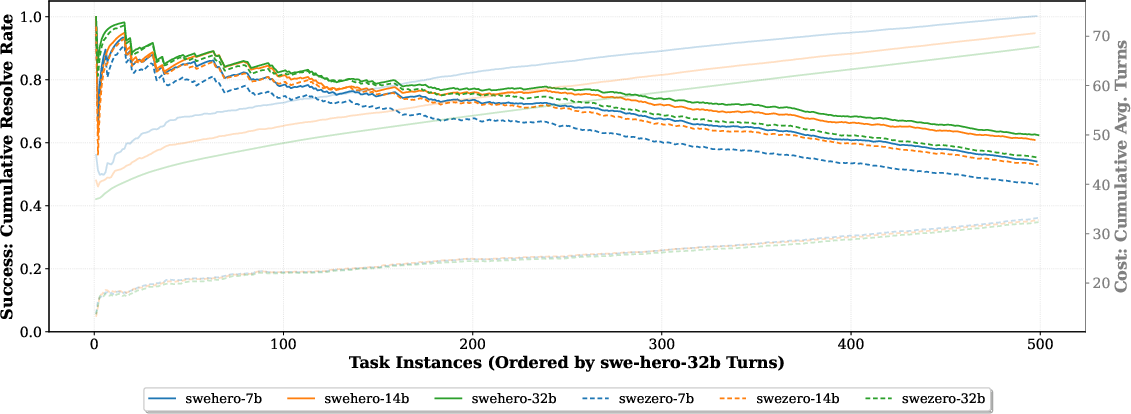
Figure 2: Cumulative performance and resource efficiency; SWE-Zero maintains lower turn-costs as complexity increases compared to execution-based agents.
Efficiency, Test Time Scaling, and Resource Utilization
A major advantage of SWE-Zero is efficiency—both in compute and token-cost. By eliminating execution feedback, each task consumes significantly fewer interaction turns and context tokens, making it viable for large-scale self-improvement. Inference efficiency is particularly valuable in resource-constrained or high-throughput applications.
Conversely, integrating execution-based SFT through SWE-Hero enhances accuracy at the cost of additional turns and tokens, driven by iterative self-verification and test authoring.
Test-time scaling (TTS), realized by generating multiple candidate rollouts and using generative verifiers for patch selection, provides additional performance boosts—though current open-source verifiers are not yet optimal and leave non-trivial headroom versus the "oracle" best-of-K attainable rate.
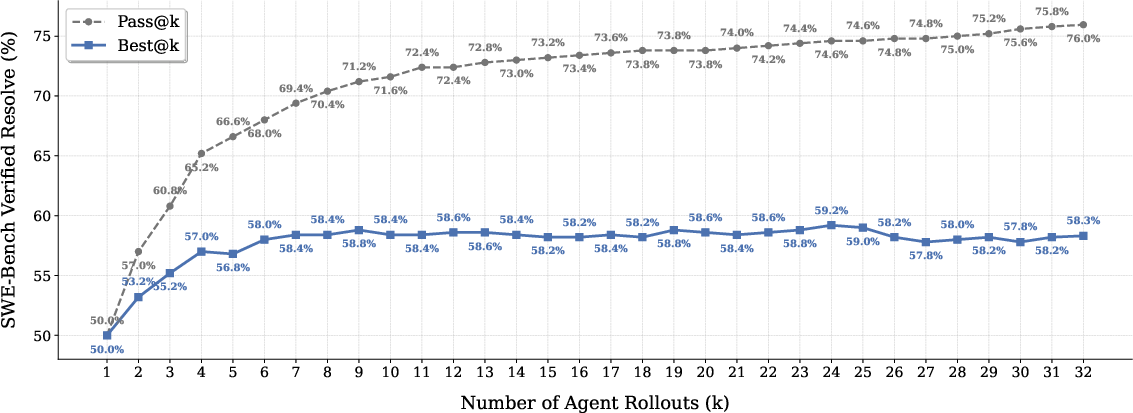
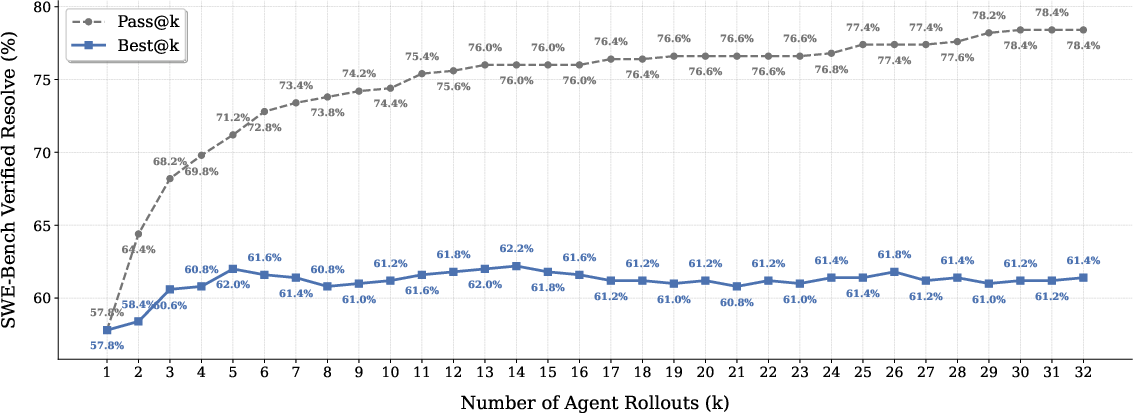
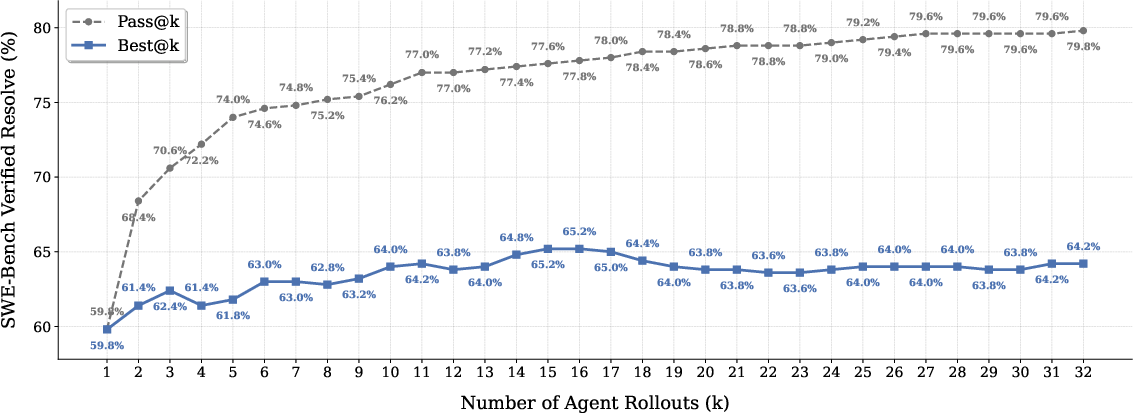
Figure 3: Increasing inference compute (TTS) with strong verifiers continues to improve resolution rate, but verifier quality constrains full potential.
Efficiency analyses also reveal that SWE-Zero achieves high success-to-cost ratios for simpler tasks, while SWE-Hero robustly resolves higher-complexity tasks where execution-grounded verification is critical.
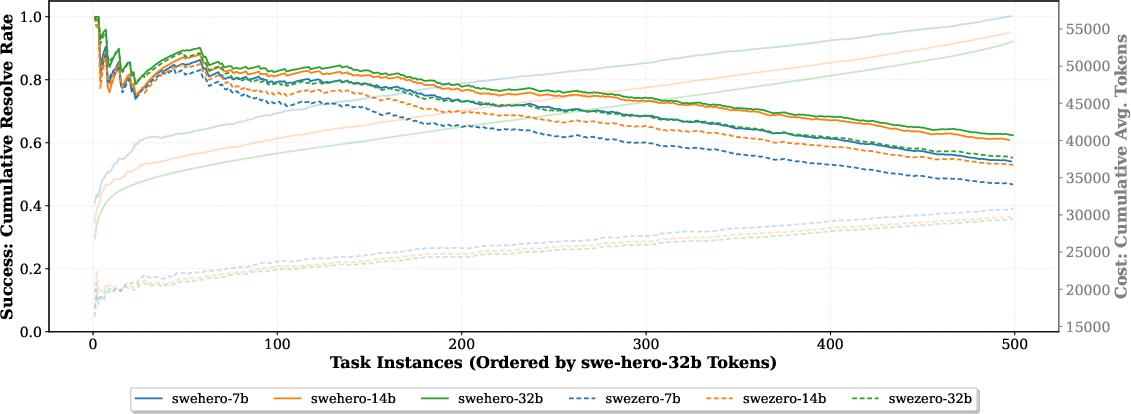
Figure 4: Cumulative performance vs. token cost on SWE-bench Verified; SWE-Zero remains more efficient by token usage, while SWE-Hero captures hard cases.
Implications and Future Directions
The SWE-Zero to SWE-Hero paradigm demonstrates the value of decoupling large-scale semantic learning from targeted execution refinement, establishing a scalable recipe for agentic SFT under realistic infrastructure constraints. Importantly, the execution-free pretraining not only eliminates Git-metatada leakage vulnerabilities ("Git hacking") but also unlocks new workflows for building and fine-tuning agentic LLMs at scale, particularly as models continue to improve in static codeworld modeling.
On the theoretical front, the curriculum structure validated here could be leveraged for more general agent learning tasks, where execution is costly, incomplete, or hazardous. For practical SWE, the resource-efficient scaling of agent capabilities enables their deployment in open-source and mid-scale environments previously inaccessible to execution-locked methods.
A critical challenge remains the design of robust task verifiers for TTS, as discriminative failures currently cap the utility of sampling strategies. Combining this fine-tuning framework with more powerful reward models and extending it to reasoning-optimized architectures (e.g., with explicit CoT operations) could further elevate autonomous code agent performance.
Conclusion
SWE-Zero to SWE-Hero outlines a highly effective, scalable approach to agentic fine-tuning for software issue resolution, separating high-throughput semantic distillation from execution-based refinement. The method pushes the frontier of open-source SWE agents, achieving competitive results to proprietary and highly-engineered counterparts, while supporting efficient training, robust cross-lingual transfer, and principled data curation. The released dataset and agent suite will enable broad, rigorous future investigations into autonomous software engineering.