- The paper introduces ARRoL, an online rollout pruning method that optimizes reward balance during RLVR.
- It employs a lightweight quality head to predict rollout success early, significantly reducing computational overhead.
- Experimental results demonstrate notable accuracy improvements and faster training, enhancing RL for LLM reasoning.
Online Rollout Pruning for Efficient and Balanced RLVR
Introduction
This work systematically analyzes and addresses core inefficiencies and reward-signal sparsity in RLVR (Reinforcement Learning with Verifiable Rewards) for LLM-based reasoning. RLVR methods such as GRPO and DAPO improve LLM reasoning via verifiable (e.g., correctness-based) rewards but rely on sampling multiple rollouts per prompt, incurring high computational cost and suffering from low within-group reward variance when rewards are dominated by all-correct or all-incorrect traces. The proposed method, ARRoL (Accelerating RLVR via online RoLlout Pruning), introduces an online rollout pruning strategy leveraging a learned, lightweight quality head for partial rollout scoring. This approach implements early, quality-aware pruning for both computational efficiency and explicit reward balance control, substantially improving both model performance and train-test resource usage.
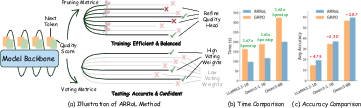
Figure 1: Overview of ARRoL, illustrating early pruning with a learned quality head, training acceleration, and accuracy improvements versus GRPO.
Methodology
Reward-Balanced Online Pruning
ARRoL's central innovation is policy-gradient acceleration via pruning uninformative or unbalanced rollouts during generation, rather than only after full sequence sampling. Formally, GRPO operates by normalizing reward signals within prompt-specific groups; when all group rewards are identical (all 0 or all 1), the gradient signal collapses. ARRoL introduces an online mechanism that monitors the evolving reward distribution and prunes rollouts to achieve a target positive-reward ratio (usually ρ=0.5), maximizing group variance and learning signal. This claim is formally proven with high-probability bounds that show posterior-guided pruning yields empirical reward distributions O(ϵ)-close to the optimal balance.
Lightweight Quality Head
Since the true reward for a rollout is only known at generation end, ARRoL trains a small MLP quality head to predict success probability from partial rollout representations. Compared with previous heuristic confidence signals (e.g., token-level entropy, DeepConf, self-certainty), the quality head is shown to better separate correct from incorrect rollouts, as evidenced both by improved distribution separability and higher rank correlations to actual correctness.

Figure 2: (a) Failure case for trace confidence metrics; (b) Quality-head scores distinctly separate correct/incorrect rollouts; (c) Higher predictive correlation from the quality head across data; (d) Early detection (length ≤512) is reliable and computationally preferred.
A sliding-window, binned posterior estimator is used for empirical calibration of quality-head outputs. At a detection length (generally 512), the backend computes survival probabilities for each rollout, dynamically discarding low-potential ones to rebalance the group as needed. This allows efficient GPU scheduling and sharper within-group reward variance necessary for effective RL updates.
System Architecture
ARRoL is integrated into a two-part pipeline: a backend (built on vLLM) that handles generation, online pruning, and quality prediction, and a frontend (using verl) responsible for logprobs, reward computation, and policy optimization. Surviving rollouts post-pruning are rebatch-processed, saving both compute and memory throughout the RL pipeline.
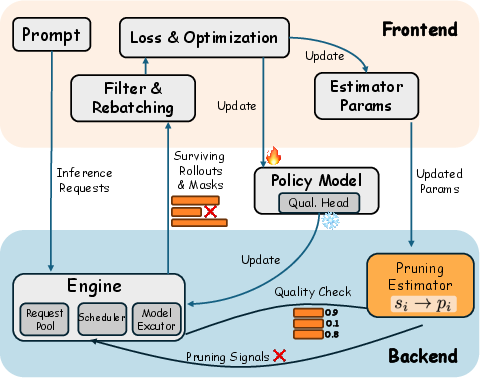
Figure 3: The ARRoL system: Backend interleaves online quality evaluation and pruning with generation; frontend processes only surviving rollouts for gradient and optimization steps.
Test-Time Scaling
ARRoL’s quality head further enables improved test-time scaling (TTS): when sampling multiple candidates at inference, quality scores are used as voting weights instead of a naive majority or empirical trace confidence. This score-weighted aggregation boosts accuracy, especially in settings where standard confidence proxies fail to align with actual solution correctness.
Experimental Results
Empirical results cover both model-scale and real-time efficiency across multiple RLVR benchmarks (Qwen-3, LLaMA-3.2, Math500, AMC'23, and others):
- Accuracy gains: On Math500/MinervaMath and challenge sets, ARRoL outperforms vanilla GRPO by +2.30–+2.99 points, with much larger boosts (+7.50–+10.00) on certain high-difficulty math problems.
- Wall-clock speedup: End-to-end training achieves up to $1.6$–1.7× speedup across both rollout generation and optimization phases. Major reductions are realized by dropping redundant or low-value rollouts prior to expensive logprob and gradient steps.
- Test-time scaling: The quality head as a voting mechanism yields test accuracy increases of up to +8.33 over previous TTS methods using log-likelihood-based heuristics.
ARRoL also robustly outperforms random pruning, increasing within-group reward variance (measured as O(ϵ)0) and thus the potential for meaningful policy-gradient updates. Ablation across keep ratio O(ϵ)1 confirms the strong effect/efficiency trade-off, with optimal performance at O(ϵ)2.
Practical and Theoretical Implications
ARRoL delivers a general, deployable mechanism to unify efficiency and reward-signal control in RLVR. Practically, the system can be adopted in any transformer RLVR pipeline with minimal architectural change. Its learnable confidence signal is task-adaptive and robust against failure modes intrinsic to token-entropy-based confidence proxies. Theoretically, ARRoL's pruning strategy is proven to optimize reward balance in finite groups, making it suitable for domains where binary reward collapse and sparse gradients are major challenges, e.g., tool-use, verification, or complex program synthesis.
Potential extensions include:
- Adapting online quality-head-guided pruning to imperfectly verifiable or continuous reward spaces.
- Integration with advanced speculative decoding and parallelized TTS.
- Cross-domain adaptation where reward function calibration may itself be uncertain.
Conclusion
ARRoL establishes online, reward-balance-driven rollout pruning as an effective and efficient paradigm for RLVR-based LLM training. By combining a lightweight, high-quality prediction head with dynamic pruning and robust system integration, ARRoL achieves both substantial accuracy gains and strong computational savings. The framework further extends to test-time aggregation, suggesting future directions for confidence-weighted sampling in both training and inference. This advances the state of efficient RL for reasoning-centric LLMs and provides theoretical foundations for reward variance maximization through online sampling interventions (2603.24840).