- The paper introduces Self-Aligned Reward (SAR) which uses relative perplexity differences to evaluate and reward concise, query-aligned responses.
- It integrates verifiable rewards with SAR in RL frameworks like PPO and GRPO, achieving up to 4% accuracy gains and 30% reduction in output length.
- Empirical results demonstrate that SAR mitigates overthinking and reward hacking, promoting efficient advanced reasoning across diverse benchmarks.
Self-Aligned Reward: A Fine-Grained Approach to Effective and Efficient LLM Reasoning
Motivation and Problem Statement
Reinforcement learning (RL) with verifiable rewards has been instrumental in advancing the reasoning capabilities of LLMs, particularly in domains such as mathematical problem solving. However, verifiable rewards—typically binary correctness signals—are inherently coarse. They fail to distinguish between concise and verbose correct answers, and cannot provide partial credit for partially correct or nearly correct responses. This limitation leads to inefficiencies, such as unnecessarily verbose outputs and increased computational cost, and can even encourage "overthinking" behaviors in LLMs. Existing solutions, such as length penalties or brevity-oriented objectives, often compromise accuracy by penalizing both redundant and essential reasoning steps.
The paper introduces Self-Aligned Reward (SAR), a self-guided, internal reward signal that complements verifiable rewards to promote both accuracy and efficiency in LLM reasoning. SAR is defined as the relative perplexity difference between an answer conditioned on the query and the standalone answer: RSA=clip(ppl(a)ppl(a)−ppl(a∣q),−1,1)
where ppl(a) is the perplexity of the answer in isolation, and ppl(a∣q) is the perplexity conditioned on the query. A higher RSA indicates that the answer is more tightly aligned with the query, favoring concise, relevant, and query-specific responses.
This reward can be seamlessly integrated into standard RL algorithms such as PPO and GRPO, yielding variants like SA-PPO and SA-GRPO. The combined reward is: RSA-PPO/GRPO(q,a,gt)=RVR(q,a,gt)+αRSA
where RVR is the standard verifiable reward and α is a tunable hyperparameter controlling the trade-off between correctness and self-alignment.
Fine-Grained Reward Analysis
SAR provides a more nuanced reward landscape than existing approaches. It distinguishes between:
- Concise, correct answers (high reward)
- Redundant, correct answers (lower reward)
- Partially correct answers (partial credit)
- Completely irrelevant or memorized answers (penalized)
This fine-grained discrimination is not achievable with binary correctness or length-based rewards. SAR also penalizes memorized answers that lack reasoning, as such answers have low perplexity both with and without the query, resulting in a low or negative RSA.

Figure 1: Token-level importance scores v(aj) highlight which tokens are valuable for self-aligned reward (red) and which are not (blue).
At the token level, SAR decomposes into per-token contributions: v(aj)=logP(aj∣a1...j−1)P(aj∣q,a1...j−1)
Tokens that leverage query information receive higher scores, while redundant or repeated tokens are penalized. This mechanism encourages models to focus on extracting and utilizing information from the query, rather than generating generic or repetitive content.
Empirical Results: Accuracy, Efficiency, and Trade-offs
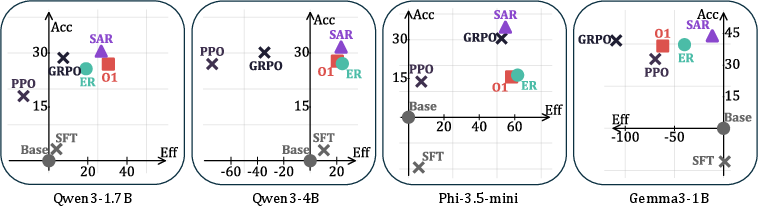
Extensive experiments were conducted on four base models (Qwen3-1.7B, Qwen3-4B, Phi-3.5-mini, Gemma3-1B) across seven benchmarks, including five math reasoning datasets and two logical reasoning datasets. The key findings are:
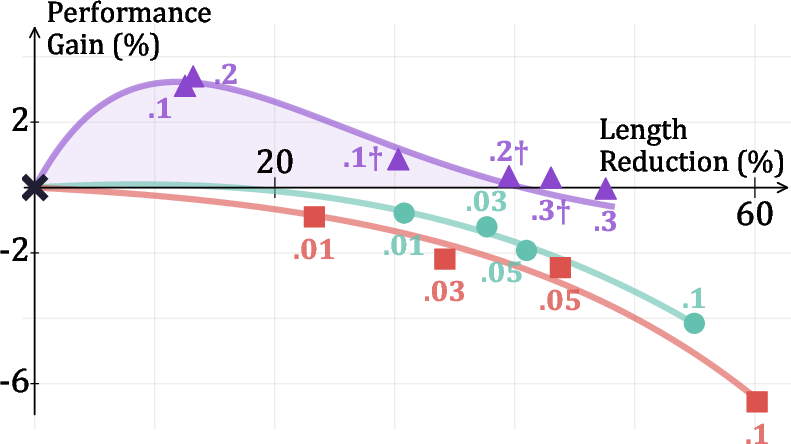
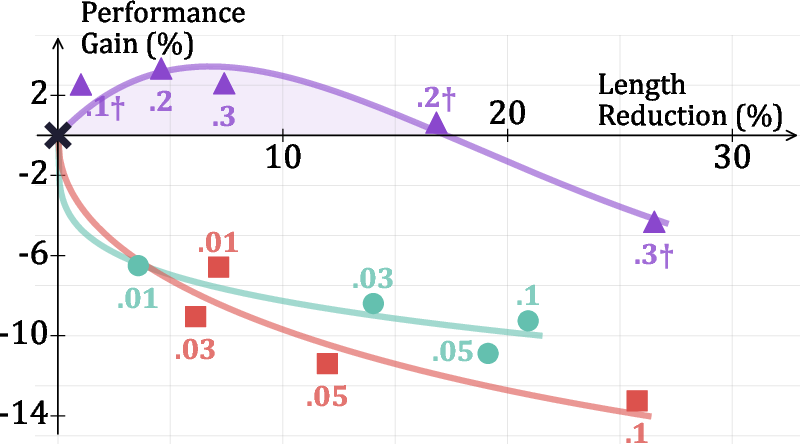
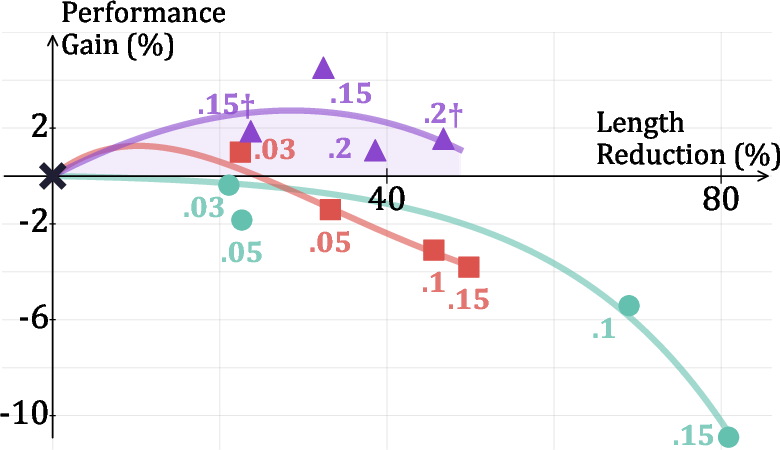
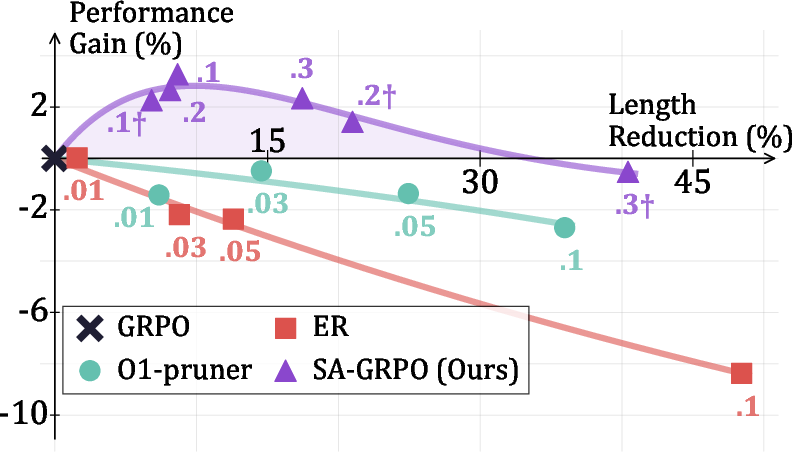
Figure 3: SA-GRPO achieves a Pareto-optimal balance between accuracy and efficiency, outperforming length-based methods across a range of α values.
Notably, SAR's improvements are robust across model sizes and architectures, and generalize to out-of-domain tasks such as logical reasoning, where it maintains or improves accuracy while reducing output length.
Ablation and Behavioral Analysis
Ablation studies demonstrate that both the verifiable reward and the conditioned perplexity drop are critical for optimal performance. Using SAR alone leads to shallow reasoning and poor accuracy, while using only entropy minimization (self-confidence) is less effective than SAR. The combination of verifiable and self-aligned rewards is necessary to avoid reward hacking and ensure stable, meaningful learning trajectories.
Behavioral analysis reveals that SA-GRPO maintains a high frequency of advanced reasoning behaviors (backtracking, verification, subgoal setting, enumeration) while using fewer tokens. In contrast, length-based methods suppress these behaviors, as they are penalized for requiring additional tokens.
Implementation and Computational Considerations
SAR is efficiently implemented within existing RL frameworks. The additional computation required for ppl(a) is negligible, as log-probabilities are already computed for KL regularization. Training cost is not increased compared to standard GRPO, and may even be reduced due to shorter outputs.
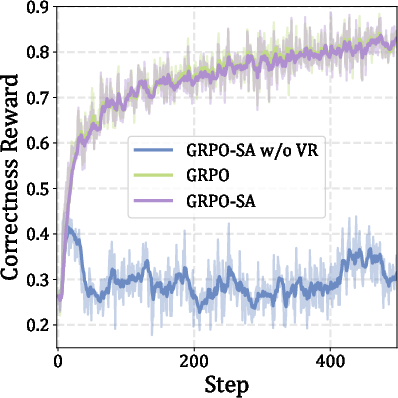
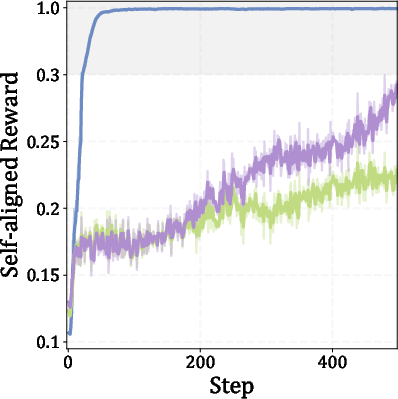
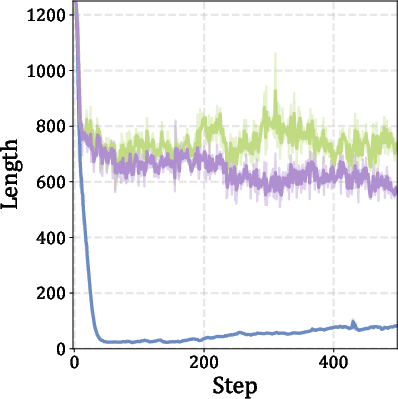
Figure 4: Training plots for Qwen3-4B show stable convergence and improved efficiency with SA-GRPO.
Theoretical and Practical Implications
The introduction of SAR represents a shift toward content-aware, intrinsic reward shaping in LLM RL training. By leveraging the model's own perplexity as a proxy for answer quality and query alignment, SAR provides a scalable, fine-grained supervision signal that does not require external reward models or human preference data. This approach mitigates reward hacking, supports partial credit, and enables flexible tuning of the accuracy-efficiency trade-off.
Practically, SAR enables the deployment of LLMs that are both more accurate and more efficient, reducing inference and training costs without sacrificing reasoning depth. The method is broadly applicable to any domain where concise, relevant, and correct outputs are desired.
Future Directions
Potential avenues for future research include:
- Extending SAR to multimodal and vision-LLMs, possibly by integrating visual-aware reward components.
- Exploring hybrid reward functions that combine SAR with other intrinsic or extrinsic signals.
- Investigating the theoretical properties of SAR in more complex RL settings, including exploration-exploitation trade-offs and convergence guarantees.
- Applying SAR to other domains requiring fine-grained, content-aware supervision, such as code generation or scientific reasoning.
Conclusion
Self-Aligned Reward (SAR) provides a principled, efficient, and effective mechanism for fine-grained reward shaping in LLM RL training. By measuring the alignment between answers and queries via perplexity differentials, SAR enables models to achieve higher accuracy and efficiency without external supervision. The approach establishes a new paradigm for RL-based LLM training, with significant implications for both research and real-world deployment.