ExGRPO: Learning to Reason from Experience
Abstract: Reinforcement learning from verifiable rewards (RLVR) is an emerging paradigm for improving the reasoning ability of LLMs. However, standard on-policy training discards rollout experiences after a single update, leading to computational inefficiency and instability. While prior work on RL has highlighted the benefits of reusing past experience, the role of experience characteristics in shaping learning dynamics of large reasoning models remains underexplored. In this paper, we are the first to investigate what makes a reasoning experience valuable and identify rollout correctness and entropy as effective indicators of experience value. Based on these insights, we propose ExGRPO (Experiential Group Relative Policy Optimization), a framework that organizes and prioritizes valuable experiences, and employs a mixed-policy objective to balance exploration with experience exploitation. Experiments on five backbone models (1.5B-8B parameters) show that ExGRPO consistently improves reasoning performance on mathematical/general benchmarks, with an average gain of +3.5/7.6 points over on-policy RLVR. Moreover, ExGRPO stabilizes training on both stronger and weaker models where on-policy methods fail. These results highlight principled experience management as a key ingredient for efficient and scalable RLVR.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI LLMs to “think out loud” better when solving hard problems, like math questions. The authors introduce a method called ExGRPO (Experiential Group Relative Policy Optimization) that helps models learn from their past attempts, not just their latest ones. The big idea: don’t throw away useful practice—save it, sort it, and reuse the best parts to learn faster and more stably.
What questions did the researchers ask?
They focused on two simple questions:
- Which past attempts are actually helpful for learning?
- How can we reuse those helpful attempts without making the model overconfident or stuck?
From their study, they found two clues that tell you an attempt is valuable:
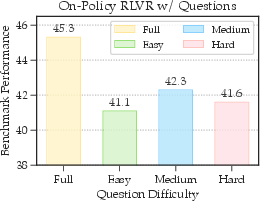
- The question was medium-difficulty for the model (neither too easy nor too hard).
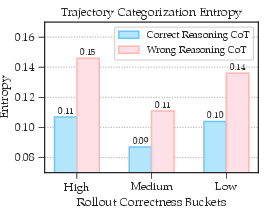
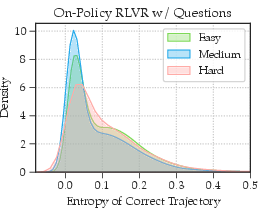
- The attempt had low “entropy,” meaning the model was relatively confident and consistent while generating the solution.
How did they do it?
Think of training like practicing for a math contest. The model tries problems, gets checked by an answer key, and then normally moves on. But ExGRPO keeps a “practice notebook” of good tries and reuses them smartly.
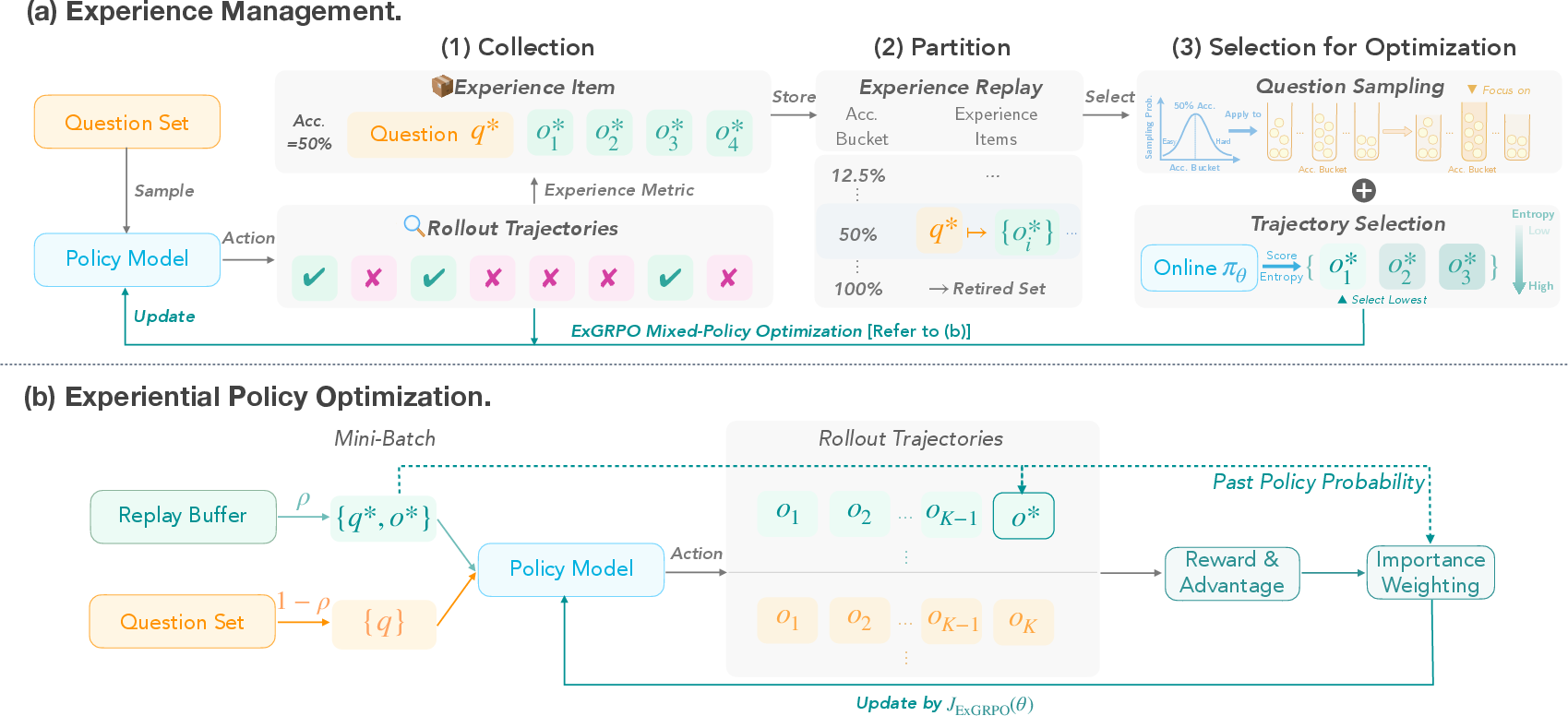
Step 1: Collect and organize experiences
- Every time the model solves a batch of problems, the system saves the successful attempts in a “replay buffer” (a library of past work).
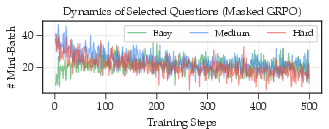
- Each question is labeled by how often the model currently gets it right:
- Easy: the model solves it most of the time
- Medium: the model solves it sometimes
- Hard: the model rarely solves it
- Questions that become “always solved” get “retired” so the model doesn’t waste time on them.
Step 2: Pick the most helpful tries
- When reusing past work, ExGRPO:
- Favors questions from the medium-difficulty bucket (these teach the most).
- For each chosen question, picks the lowest-entropy attempt. Entropy here means “how unsure or scattered the model was when writing the solution.” Lower entropy = clearer, steadier reasoning.
Everyday analogy: if you’re studying your old solutions, you’ll learn more from solid, steady explanations on problems you sometimes get right, rather than from shaky guesses or problems that are already trivial for you.
Step 3: Train with a mix of fresh and past tries
- The model trains on a mix of:
- New, freshly generated attempts (exploration).
- Selected, high-value past attempts (experience reuse).
- This balance helps the model improve quickly without losing the ability to discover new ideas.
Technical note in simple terms:
- When learning from older attempts, ExGRPO corrects for the fact that they came from an earlier version of the model. It uses a math “fairness weight” (importance weighting) so it doesn’t learn the wrong lesson from outdated behavior.
Extra safety features
- Policy shaping: When replaying past work, the method slightly boosts learning from less likely (more novel) parts of an answer and tones down overconfident parts. This encourages learning without making the model rigid.
- Delayed start: Experience replay only begins once the model reaches a certain basic skill level, so it doesn’t store lots of low-quality, lucky guesses early on.
What did they find?
Here are the main takeaways from experiments on several LLMs (from 1.5B to 8B parameters) across math and general reasoning tests:
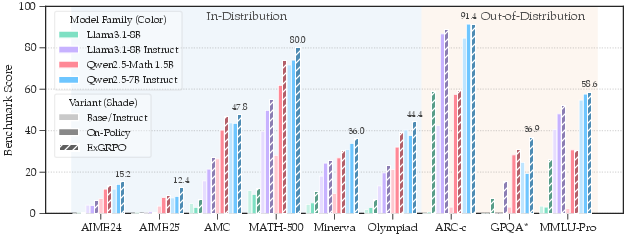
- ExGRPO beats standard “on-policy” training (which uses only fresh attempts). On average:
- +3.5 points on in-distribution math benchmarks
- +7.6 points on out-of-distribution benchmarks (harder, different types of questions)
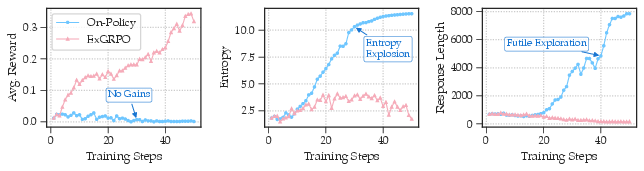
- It helps stabilize training, especially for weaker models that otherwise “collapse” (their training goes off the rails). Replaying good past attempts gives them steady signals to learn from.
- It confirms two practical rules:
- Medium-difficulty questions are the most useful for learning.
- Low-entropy (more confident and consistent) reasoning chains are more likely to be logically sound.
- It works across different model families (Qwen and Llama) and sizes, and even helps in a continual-learning setup (further training a strong model without breaking it).
Why entropy matters: If the model’s reasoning is very “jittery” (high entropy), it often found the right answer by luck. Reusing those can teach bad habits. Low-entropy attempts are more trustworthy.
Why does this matter?
- Efficiency: Training large models is expensive. Reusing the best past attempts squeezes more value out of every computation step.
- Stability: By focusing on medium-difficulty questions and steady reasoning, the model avoids wild swings in behavior and learns more reliably.
- Scalability: This approach turns “experience” into a first-class ingredient of training. As models solve more problems, they build a smarter library of examples to learn from.
- Generalization: The method improves not just on the training-style problems, but also on new kinds of questions, suggesting it helps models develop stronger reasoning habits.
In short, ExGRPO shows that managing and reusing a model’s own experience—especially medium-difficulty, low-entropy attempts—can make AI reasoning both better and more stable. This is a practical step toward building smarter, more reliable problem-solvers.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of the key gaps and unresolved questions that remain after this work, framed to guide future research and concrete follow-ups:
- Lack of theoretical guarantees: No formal analysis of convergence, bias, or variance for the mixed on-/off-policy ExGRPO objective—especially with GRPO-style advantage normalization, clipping, and the non-linear “policy shaping” term—which may break unbiasedness of importance sampling.
- Heuristic design choices unvalidated: The Normal sampling schedule for buckets (p ∝ N(Acc; μ=0.5, σ=1)), bucket thresholds (Hard/Medium/Easy: 0–25/25–75/75–100%), delayed start threshold (Pass@1 > 35%), replay ratio ρ, and shaping parameter β=0.1 are largely heuristic. Sensitivity analysis and principled tuning or adaptive schedules are missing.
- Entropy as a proxy for CoT quality: The paper uses trajectory entropy as a proxy for reasoning validity based on correlation analyses, but does not establish causality or domain-robustness, nor evaluate alternative proxies (e.g., verifier confidence, step-level consistency, self-consistency signals, semantic equivalence checks).
- Reliance on model-based CoT validation: Reasoning validity is judged by Qwen3-32B; potential bias or error in the judge is not quantified. No human validation or inter-annotator agreement is reported to calibrate the judge’s reliability.
- Group advantage normalization with mixed data: GRPO advantages are computed over groups mixing on-policy trajectories and replayed off-policy trajectories. The statistical impact of this mixing on advantage estimates and training stability is not analyzed.
- Importance-sampling variance and clipping: The per-token importance ratio for off-policy correction can have high variance. The paper does not analyze variance reduction strategies, the effect of CLIP vs. f(w) shaping on gradient stability, or provide guidance on clipping ε.
- Replay selection reduces diversity: Selecting only the lowest-entropy trajectory per question may induce mode-seeking and reduce trajectory diversity. The paper does not test top-k or diversity-aware selection, nor assess mode collapse or loss of exploratory behaviors.
- Retiring solved questions risks forgetting: Removing questions that reach perfect correctness (“Retired Set”) may cause catastrophic forgetting. No retention tests or longitudinal evaluations are performed to confirm sustained mastery.
- Experience staleness and refresh: The policy evolves while replayed trajectories remain fixed. How stale experiences affect learning—especially when current-policy entropy/likelihood diverges from past-policy distributions—remains unexplored. No policies for refreshing, decaying, or re-validating stale trajectories are tested.
- Ignoring informative failures: The buffer stores only successful rollouts. The utility of near-correct or high-quality failed trajectories (e.g., correct steps but wrong final answer) is not assessed; step-wise reward or partial credit is not used.
- Limited reward design: The work uses binary verifiable rewards (final-answer correctness). It remains open how ExGRPO behaves with richer/verifier-noisy rewards (e.g., step-wise correctness, weak/soft verifiers, partial credit, or learned reward models).
- Entropy collapse and regularization: While the paper notes risks of entropy collapse, it does not integrate explicit entropy regularization or constraints in the objective, nor compare with principled entropy-preserving methods.
- Mixed-group size and composition: The choice to use 1 replayed trajectory + K−1 fresh rollouts per group is heuristic. No study of trade-offs across K, replay count per question, or dynamic group composition strategies.
- Compute and memory costs: Experience scoring (entropy under current policy), storage, and retrieval can be expensive. The paper does not report memory footprint, wall-clock speed, throughput, or cost-benefit trade-offs versus pure on-policy training.
- Scaling beyond 8B parameters: Results are limited to 1.5B–8B backbones. Performance and stability on larger models (e.g., 70B+), across longer contexts, and with larger buffers are not evaluated.
- Generalization beyond math: Training is on math-only data; OOD evaluation is limited, and continual RLVR shows mixed OOD effects. The method’s applicability to other domains (code, logical reasoning, knowledge-intensive QA), multi-modal setups, and real-world agentic tasks is untested.
- Underexplored degradation in continual RLVR: The paper reports OOD underperformance in continual RLVR, attributing it to reduced on-policy exposure. There is no systematic analysis of schedules (e.g., annealing ρ), domain-balanced replay, or curriculum strategies to mitigate this.
- Verifier robustness and reward hacking: The reliability of Math-Verify and susceptibility to reward hacking or spurious formatting tricks are not tested. No robustness checks (e.g., adversarial inputs, ambiguous answers, numeric tolerances) are reported.
- Data contamination and dedup: No analysis of overlap or leakage between training data (OpenR1-Math) and evaluation sets, nor deduplication protocols to ensure fair test performance.
- Buffer management policies: The paper does not specify buffer capacity limits, eviction strategies (beyond retiring solved questions), or prioritization when storage is constrained. Scalability and policy for managing very large buffers remain open.
- Adaptive difficulty targeting: Using current-policy correctness rate to define difficulty may be biased by transient policy weaknesses. No exploration of alternative difficulty estimators (e.g., external difficulty labels, solver ensembles) or adaptive μ schedules over training.
- Token-level dynamics: The impact of removing length and std normalization (as in Dr.GRPO) on token-level gradient contributions and sequence-length biases is not dissected, especially under mixed (on/off) group normalization.
- Sequence length and structure: The effect of prioritizing low-entropy trajectories on CoT length, structure (e.g., tool use, code blocks), and reasoning patterns is not analyzed; potential biases toward shorter or more formulaic CoTs are not reported.
- Alternative off-policy methods: ExGRPO is not compared to established off-policy RL updates (e.g., V-trace, Retrace, AWAC, SAC-style actor updates) adapted to LRMs, nor to prioritized replay with principled importance correction.
- Multi-metric experience value: Beyond correctness and entropy, other signals (e.g., step consistency, self-verification, agreement across samples, edit distance to correct proof) are not evaluated for experience prioritization.
- Dynamic replay ratio schedules: Only static ratios (25/50/75%) are explored. The paper does not test adaptive schedules (e.g., increasing on-policy weight as buffer grows or as entropy drops) that may better balance exploration and exploitation over training.
- Stability conditions: While ExGRPO stabilizes Llama-3.1 8B training, the failure modes of on-policy RLVR and the precise stabilizing mechanisms (e.g., buffer composition, entropy selection, delayed start) are not causally identified or generalized to other weak models/datasets.
- Integration of external judges into training: Although CoT validity is judged for analysis, the paper does not integrate validity signals (e.g., judge-based rewards, filtering) into the training loop to suppress spurious successes.
- Fairness and safety scope: Ethics statement is generic; there is no assessment of bias, harmful reasoning patterns, or safety concerns arising from replaying spurious trajectories (e.g., misuse of tools or incorrect but convincing CoTs).
- Reproducibility details: While code and weights are released, exact verifier configurations, buffer sizes, pruning rules, entropy computation settings, and judge prompts are not exhaustively documented for end-to-end replication.
- Multi-turn/interactive settings: ExGRPO is evaluated in single-shot problem solving. Its suitability for interactive multi-turn setups, tool-augmented pipelines, or agents with stateful memory is not explored.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams training or operating reasoning-centric AI systems, leveraging ExGRPO’s experience-aware RLVR techniques (bucketed correctness, entropy-based trajectory selection, mixed-policy optimization, importance weighting, policy shaping, delayed start, and retired set management).
- Sector: Software/AI Infrastructure
- Application: More stable and cost-efficient RLVR training for math and general reasoning models.
- Tools/Workflows: Integrate an “ExGRPO module” into existing RL training frameworks (e.g., verl), including a replay buffer with correctness buckets, entropy-aware trajectory selector, mixed-policy optimizer with importance weighting, a policy-shaping function f(x)=x/(x+β), a delayed-start trigger (Pass@1 threshold), and a retired-set manager to avoid overfitting trivial cases.
- Assumptions/Dependencies: Verifiable reward functions exist for the task; compute budget supports multi-rollout training; the low-entropy-as-quality proxy holds sufficiently for the domain; correct tuning of ρ (experience ratio), K (rollouts), β (policy shaping), and bucket sampling distribution.
- Sector: Education
- Application: Train and deploy AI math/science tutors with more reliable step-by-step reasoning and better explanation quality, using verifiable math rewards (e.g., Math-Verify) and experience replay focused on medium-difficulty problems.
- Tools/Workflows: Curriculum-aware training pipelines that sample questions around 50% online correctness, select lowest-entropy trajectories per question, retire fully solved items, and monitor Pass@1 to activate replay; LMS integration for continual improvement.
- Assumptions/Dependencies: Robust verifiers for math answers; availability of graded datasets; alignment between low entropy and high-quality CoT; oversight to guard against entropy collapse.
- Sector: Software Engineering
- Application: Train code assistants and autonomous coding agents via RLVR with test-based verifiers (unit/integration tests), reusing partially successful rollouts for faster stabilization.
- Tools/Workflows: Test-driven RL training where the buffer stores trajectories passing some test cases; entropy-based selection to avoid brittle “lucky hits”; CI/CD plugins that schedule medium-difficulty tasks and retire fully solved ones.
- Assumptions/Dependencies: High-quality test suites act as verifiable rewards; careful replay ratio to prevent overfitting; correct handling of distribution mismatch via importance weighting.
- Sector: Data Analytics/Business Intelligence
- Application: Train SQL generation and BI reasoning agents with executable-query verifiers (correctness of outputs), improving reliability on complex queries.
- Tools/Workflows: An RLVR pipeline with query execution feedback as rewards; ExGRPO’s bucketed correctness and entropy-based selection to prioritize mid-difficulty queries; dashboards for retired-set growth and buffer health.
- Assumptions/Dependencies: Accurate and safe query execution environments; data privacy controls for logs; stable correlation between low entropy and sound reasoning steps.
- Sector: Customer Support/IT Ops
- Application: Troubleshooting agents trained with verifiable checklists or resolution conditions (e.g., reproducible fix scripts), using replay to stabilize reasoning on mid-complexity incidents.
- Tools/Workflows: Reasoning pipelines that validate outcomes (e.g., service restored, error cleared) and replay partially correct trajectories with mixed-policy objectives; retired-set for trivial recurring issues.
- Assumptions/Dependencies: Clear, programmable verifiers for resolution; careful handling of false positives (“lucky fixes”); monitoring entropy to avoid spurious rationales.
- Sector: Academia/Research (Budget-Constrained Labs)
- Application: Efficient training of 1.5B–8B reasoning models using ExGRPO to stabilize on-policy RLVR (especially where on-policy collapses), enabling smaller teams to reach competitive math/OOD performance.
- Tools/Workflows: Adoption of the open-source ExGRPO code and models; use of Math-Verify/xVerify; systematic buffer management; delayed start for replay once batch Pass@1 exceeds a threshold.
- Assumptions/Dependencies: Access to GPU resources (e.g., H100s or smaller clusters); availability of verifiable datasets; reproducible training logs and metrics.
- Sector: Model Governance/LLMOps
- Application: Train-time governance dashboards to monitor replay buffer composition, correctness buckets, entropy distributions, retired set growth, and exploration–exploitation balance (ρ).
- Tools/Workflows: “Training Governance Dashboard” that surfaces bucket sampling probabilities, low-entropy trajectory selection health checks, and alarms for entropy collapse; policy shaping toggles; Pass@1-based replay activation.
- Assumptions/Dependencies: Accurate telemetry; organizational processes to tune/explain RLVR decisions; dataset licensing compliance for storing and reusing trajectories.
- Sector: Benchmarking and Evaluation
- Application: More consistent performance on math and OOD reasoning benchmarks by stabilizing RL with principled experience management.
- Tools/Workflows: Integrate xVerify/Math-Verify; standardize correctness bucketing; measure gains with/without replay; ablation tracking for trajectory selection and shaping.
- Assumptions/Dependencies: Verifiers are representative; metric robustness; generalization beyond math depends on quality of verifiers in other domains.
Long-Term Applications
These applications extend ExGRPO principles to safety-critical, multimodal, or agentic contexts and require more research, stronger verifiers, scaling, or regulatory approvals.
- Sector: Healthcare
- Application: Clinical decision support systems trained via RLVR with guideline-compliance and dosage verifiers; replay buffered on mid-difficulty cases to improve diagnostic reasoning stability.
- Tools/Workflows: Medical verifier pipelines (formalized rules, simulators, or certified judges), experience management that retires trivial cases and emphasizes coherence via entropy selection; provenance/audit trails.
- Assumptions/Dependencies: High-assurance verifiers; rigorous validation; privacy and regulatory approvals (HIPAA, GDPR); mitigation of “lucky hits” and spurious rationales.
- Sector: Robotics and Autonomous Systems
- Application: LLM-based planners with RLVR using simulator/constraint verifiers, replaying low-entropy plans for consistent task execution and safe exploration.
- Tools/Workflows: Simulation-driven verifiable rewards (success criteria, safety constraints, energy limits); bucketed correctness sampling; mixed-policy optimization tuned for real-time planning.
- Assumptions/Dependencies: Accurate simulators and physical verifiers; safety certification; real-time inference constraints; robust off-policy correction for distribution mismatch.
- Sector: Finance and Compliance
- Application: RL-trained reasoning agents for risk analysis, audit, and compliance checks (e.g., rule adherence, P&L reconciliations), with verifiable outcome checks and experience replay for medium-complexity cases.
- Tools/Workflows: Formal verifiers for financial rules and calculations; experience-aware optimization with policy shaping to avoid overfitting; audit-ready buffer management.
- Assumptions/Dependencies: Legally recognized verification pipelines; strict governance; explainability requirements; resistance to adversarial “lucky” outcomes.
- Sector: Energy/Operations Research
- Application: Grid management and optimization agents trained with constraints/verifiers (e.g., load balance, frequency control), using ExGRPO to exploit valuable mid-difficulty scenarios.
- Tools/Workflows: Simulation verifiers; entropy-aware trajectory selection to prefer consistent plans; retired-set to focus on harder configurations.
- Assumptions/Dependencies: Safety-critical verification fidelity; real-time performance; domain-specific reward shaping; extensive stress testing.
- Sector: Multimodal Reasoning and Agentic Systems
- Application: Extend ExGRPO to vision-language, GUI, and tool-using agents (e.g., ARPO-like settings) with step verifiers (e.g., task completion, UI actions), stabilizing training with experience management.
- Tools/Workflows: Multimodal verifiers; trajectory entropy generalized beyond text; mixed-policy objectives for heterogeneous action spaces; replay scheduling aligned with agent capabilities.
- Assumptions/Dependencies: Reliable, scalable multimodal verifiers; correct entropy proxies across modalities; improved importance weighting for non-text actions.
- Sector: Safety, Alignment, and Interpretability
- Application: Use entropy-based selection and improved CoT validity judges to filter spurious rationales, reducing the risk of deceptive or incorrect reasoning while maintaining exploration via policy shaping.
- Tools/Workflows: CoT validity judges (model-based or formal checks), guardrails in replay sampling, governance dashboards for entropy/correctness trends.
- Assumptions/Dependencies: Robust judges beyond LRM proxies; formal verification methods; monitoring to avoid entropy collapse; domain-specific definitions of “valid reasoning.”
- Sector: Public Policy and Standards
- Application: Experience-aware RL standards in procurement and evaluation—require verifiable rewards, replay buffer governance, and transparency on correctness bucketing and entropy handling.
- Tools/Workflows: Policy frameworks specifying experience management, replay ratios, verifier quality thresholds, and reporting of training stability.
- Assumptions/Dependencies: Multi-stakeholder consensus; standardized verifiers; auditability; incentives for transparency.
- Sector: Personalized Education at Scale
- Application: Large-scale adaptive curricula where correctness-bucket sampling and retired-set dynamics drive continuous learning, with entropy heuristics guiding explanation quality.
- Tools/Workflows: Platforms that track per-learner online correctness rates and select trajectories/explanations accordingly; replay of partially solved items for targeted practice.
- Assumptions/Dependencies: Fairness and accessibility; reliable correctness measures; mitigation for bias or overfitting to mid-difficulty content.
- Sector: Commercial Tooling
- Application: “Experience Manager” products for RL training—replay buffer services with correctness bucketing, entropy-aware selector, mixed-policy optimizer SDKs, and training governance dashboards.
- Tools/Workflows: Managed services/APIs for buffer operations, trajectory scoring, “delayed start” gating, retired-set policies, and compliance reporting.
- Assumptions/Dependencies: Market adoption; integration with diverse RL frameworks; security/privacy for stored trajectories; support for task-specific verifiers.
Glossary
- Advantage (estimate): A measure of how much better a trajectory's reward is compared to the group's average, used to guide policy updates. "It estimates the advantage of each trajectory by normalizing rewards within a group of sampled solutions."
- Bucket (difficulty buckets): A grouping mechanism that partitions questions by online correctness rate to manage experience difficulty. "we categorize each question into one of three difficulty buckets"
- Chain-of-thought (CoT): The explicit sequence of reasoning steps generated by a LLM while solving a task. "RL augments LLMs' reasoning by modeling chain-of-thought (CoT) as action sequences optimized under verifiable rewards (RLVR)"
- Clipped surrogate function: A stabilized RL objective that limits the change in probability ratios during policy updates to prevent destructive steps. "The on-policy objective maximizes a clipped surrogate function:"
- Continual learning: Training a model further over time (often with new data or methods) to extend or refine its capabilities without starting from scratch. "and continual learning on the stronger LUFFY model"
- Distribution mismatch: A discrepancy between the data distribution used for training updates and the policy’s actual data distribution, requiring correction. "overlook importance weighting to correct distribution mismatch in off-policy updates."
- Distribution shift: Changes between the training and target distributions that can bias updates unless accounted for. "while correcting the distribution shift."
- Entropy: A measure of uncertainty in the model’s action (token) distribution, often averaged across a trajectory. "The entropy refers to the average action entropy:"
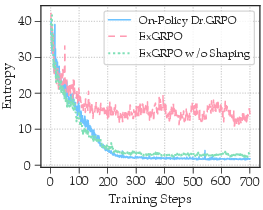
- Entropy collapse: A failure mode where entropy is driven too low, harming exploration and generalization. "can lead to entropy collapse~\citep{cui2025entropy}"
- Entropy explosion: A failure mode where entropy increases excessively, indicating unstable or overly uncertain policies. "and the model finally encountered entropy explosion on challenging training data."
- Entropy minimization: A heuristic to prefer lower-uncertainty trajectories, often correlating with higher reasoning quality. "entropy minimization is an effective heuristic for trajectory selection."
- Experience-based RL: Reinforcement learning approaches that explicitly leverage previously collected interactions to improve efficiency and stability. "This idea, often referred to as experience-based RL"
- Experience replay: The reuse of stored past trajectories to improve sample efficiency and stabilize training. "Experience replay~\citep{Lin1992} is a widely adopted technique in RL to address this issue and improve sample efficiency."
- Experiential Group Relative Policy Optimization (ExGRPO): A framework that prioritizes valuable past experiences and blends them with on-policy exploration for stable, efficient RLVR. "we introduce ExGRPO (Experiential Group Relative Policy Optimization), a novel framework designed to strategically identify, manage, and replay valuable experiences."
- Exploration–exploitation trade-off: The balance between trying new actions (exploration) and leveraging known good actions (exploitation). "thus motivating the need for a nuanced explorationâexploitation trade-off in the context of experience management."
- Group Relative Policy Optimization (GRPO): An RLVR method that normalizes rewards within groups of sampled trajectories to estimate advantages without an explicit value model. "GRPO~\citep{grpo} is a strong baseline within the RLVR paradigm~\citep{r1,simplerl-zoo,drgrpo}, achieving effective scaling without requiring an additional value model."
- Importance sampling: A correction technique that reweights off-policy trajectories to produce unbiased gradient estimates. "removing trajectory selection and importance-sampling correction mechanisms also leads to inferior performance"
- Importance weight: The probability ratio between current and reference (or past) policies used to reweight tokens/trajectories in off-policy updates. "the per-token importance weight is the probability ratio between the current policy and reference policy $\pi_{\theta_{\text{old}$"
- Knowledge distillation: Transferring knowledge from a teacher model to a student model, often as an auxiliary objective during RL. "or knowledge distillation~\citep{xu2025kdrl};"
- Mixed-policy objective: An optimization that combines on-policy trajectories with strategically selected replayed trajectories. "and employs a mixed-policy objective to balance exploration with experience exploitation."
- Off-policy: Learning from trajectories generated by a different (past or external) policy than the one currently being optimized. "Recent work has explored off-policy techniques"
- Off-policy policy gradients: Gradient-based RL updates that incorporate trajectories from past or external policies with importance weighting. "off-policy policy gradients~\citep{yan2025learning},"
- On-policy: Learning exclusively from trajectories sampled by the current policy being trained. "standard on-policy training discards rollout experiences after a single update"
- Out-of-distribution (OOD): Benchmarks or data that differ from the training distribution, used to measure generalization. "out-of-distribution reasoning benchmarks (ARC-c, GPQA, MMLU-Pro)."
- Pass@1: The fraction of problems solved correctly on a single attempt; a standard evaluation metric for reasoning tasks. "we use Pass@1 metric, representing the proportion of solved problems on a single attempt."
- Policy gradient: A class of methods that directly optimize the parameters of a policy via gradients of expected rewards. "To obtain an unbiased policy gradient estimate from the replayed trajectory"
- Policy shaping: A modulation technique that adjusts gradient contributions (e.g., via nonlinear transforms of importance weights) to preserve exploration. "we modulate the gradient from experiential data using policy shaping."
- Replay buffer: A memory structure that stores past trajectories for selection and reuse during training. "ExGRPO maintains a replay buffer of reasoning trajectories derived from partially correct rollouts"
- Retired Set: A collection of questions removed from the replay buffer after being consistently solved, to avoid overfitting on trivial cases. "we introduce a Retired Set: questions solved in all rollouts are removed from "
- Rollout: The process of sampling trajectories from a policy to generate experiences for training. "the valuable experience generated during the rollout phase is often discarded after a single gradient update"
- Rollout policy: The reference policy used to generate trajectories prior to the current update step. "Since the trajectory is generated by the rollout policy model before update"
- Sampling temperature: A parameter that controls randomness in token sampling; higher values yield more diverse outputs. "All evaluations use a sampling temperature of 0.6"
- State-action-reward tuple: The basic unit of experience in RL, capturing a state, an action taken, and the resulting reward. "interactions (i.e., state-action-reward tuples)"
- Top-p: Nucleus sampling that restricts token sampling to the smallest set whose cumulative probability exceeds a threshold p. "and a top-p of 1.0"
- Trajectory entropy: The uncertainty measure over a trajectory’s token choices; lower values often indicate more confident reasoning. "trajectory entropy (for trajectories) as effective online proxy metrics"
- Verifiable reward: A binary reward based on whether the model’s final answer matches a gold answer via an automatic checker. "The verifiable reward compares the extracted answer from the modelâs output with a predefined golden answer."
- Verifier: A rule-based or model-based component that checks the correctness of generated answers. "with rewards provided by rule-based~\citep{r1,yu2025dapo} or model-based verifiers~\citep{su2025crossing,ma2025general,chen2025xverify}"
Collections
Sign up for free to add this paper to one or more collections.

