Reinforce-Ada: An Adaptive Sampling Framework for Reinforce-Style LLM Training
Abstract: Reinforcement learning applied to LLMs for reasoning tasks is often bottlenecked by unstable gradient estimates due to fixed and uniform sampling of responses across prompts. Prior work such as GVM-RAFT addresses this by dynamically allocating inference budget per prompt to minimize stochastic gradient variance under a budget constraint. Inspired by this insight, we propose Reinforce-Ada, an adaptive sampling framework for online RL post-training of LLMs that continuously reallocates sampling effort to the prompts with the greatest uncertainty or learning potential. Unlike conventional two-stage allocation methods, Reinforce-Ada interleaves estimation and sampling in an online successive elimination process, and automatically stops sampling for a prompt once sufficient signal is collected. To stabilize updates, we form fixed-size groups with enforced reward diversity and compute advantage baselines using global statistics aggregated over the adaptive sampling phase. Empirical results across multiple model architectures and reasoning benchmarks show that Reinforce-Ada accelerates convergence and improves final performance compared to GRPO, especially when using the balanced sampling variant. Our work highlights the central role of variance-aware, adaptive data curation in enabling efficient and reliable reinforcement learning for reasoning-capable LLMs. Code is available at https://github.com/RLHFlow/Reinforce-Ada.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Reinforce-Ada, a smarter way to train reasoning-focused AI models (like math-solvers) using reinforcement learning. The main idea is to spend more “practice tries” on the prompts (questions) where the model is uncertain and fewer tries where things are already clear. This helps the model learn faster, more stably, and with better final results—without needing huge, expensive batches of attempts for every prompt.
What problem is the paper solving?
In reinforcement learning for LLMs, the model sees a prompt (question), tries to answer, and gets a reward (like a score: correct = 1, incorrect = 0). The model learns by adjusting itself based on these rewards. But there’s a big issue:
- If you only let the model try a few times per prompt, the feedback can be very noisy and unreliable (unstable learning).
- If you let it try many times, you get clear feedback—but generating all those tries is too expensive.
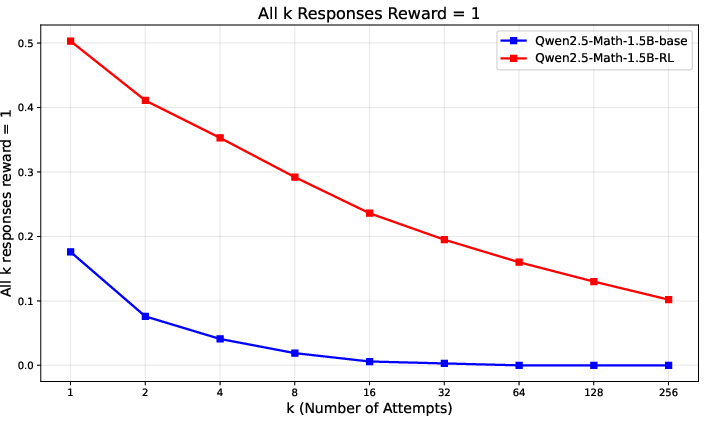
A popular method called GRPO uses a small, fixed number of tries per prompt (like n = 4). This often fails when all tries are either correct or all incorrect, because there’s no difference to learn from—so the model doesn’t improve on that prompt. The paper shows this “signal collapse” happens a lot and is mainly a sampling (not a model) problem.
Simple goals and questions
The authors aim to:
- Reduce wasted effort on prompts that are either too easy or already solved.
- Spend more effort on prompts where the model is uncertain and could learn more.
- Keep training stable by ensuring each prompt contributes meaningful, varied feedback.
- Improve accuracy on math benchmarks while keeping costs reasonable.
In simple terms: Can we collect the right kind of examples at the right time so the model learns faster and better?
How does Reinforce-Ada work?
Think of training like studying for a test:
- You have many questions (prompts).
- You can practice each question multiple times (generate responses).
- Your study time (compute budget) is limited, so you want to use it wisely.
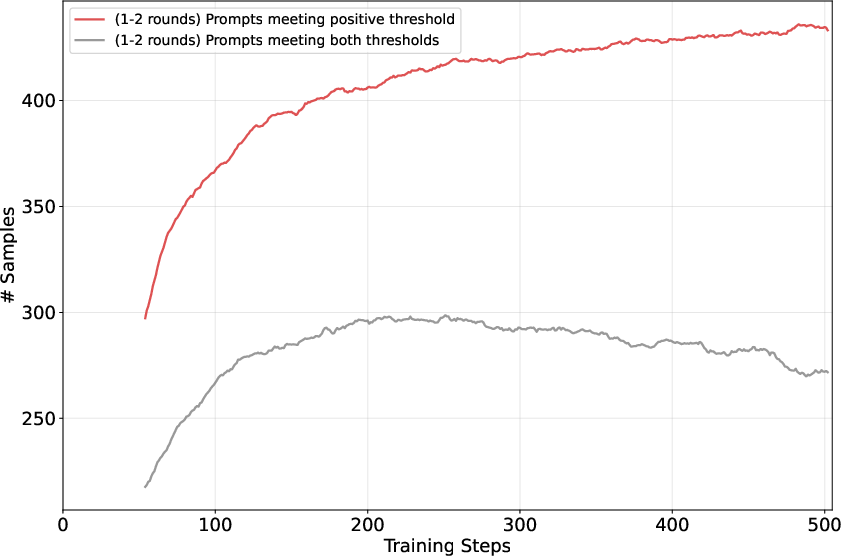
Reinforce-Ada uses adaptive sampling, which means it decides on the fly how many tries to give each prompt based on the feedback so far. Here’s the approach:
- Start with all prompts “active.”
- In rounds, generate a small batch of responses per active prompt.
- If a prompt has collected enough useful signals, stop sampling it (deactivate it) to save time.
The paper uses two straightforward “exit rules” (ways to decide when to stop sampling a prompt):
- Reinforce-Ada-pos: Stop once you get at least one correct answer for that prompt. This quickly finds positives and moves on.
- Reinforce-Ada-balance: Keep sampling until you have a balanced mix—about half correct and half incorrect responses. This ensures the model learns from both successes and failures.
To avoid any single prompt dominating training:
- The method down-samples (selects a fixed small group, like n = 4) from what was collected, trying to include both correct and incorrect examples.
- It uses a simple baseline (the overall average reward for that prompt from all collected attempts) to measure how good each attempt was compared to the prompt’s typical performance. This helps reduce noise and keep updates stable.
Finally, the training step includes standard safety guards (like clipping) to prevent overly large changes in the model when old and new policies differ too much. You can think of this like making sure each study “tweak” is small and safe rather than wild and unstable.
Main findings and why they matter
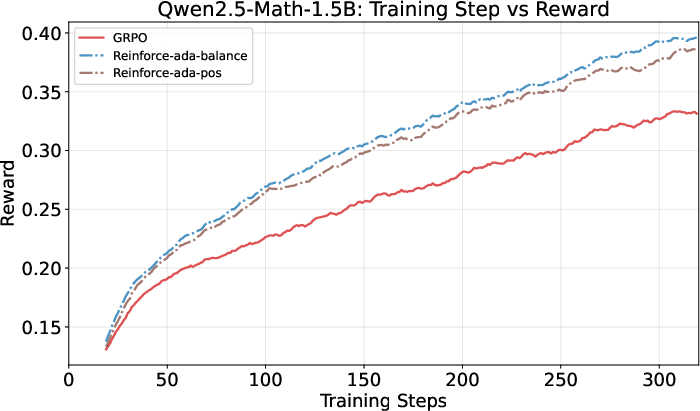
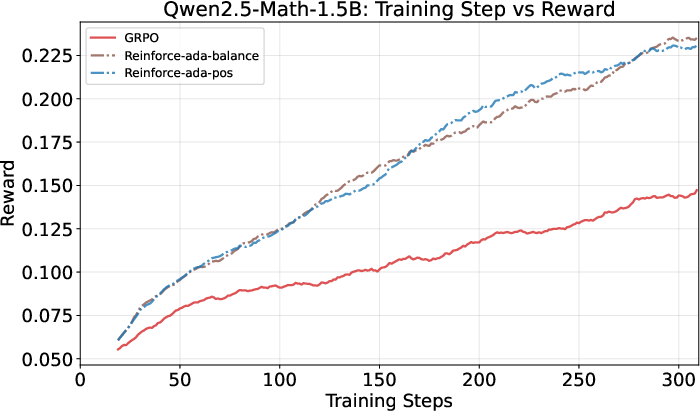
Across several LLMs and math benchmarks, Reinforce-Ada:
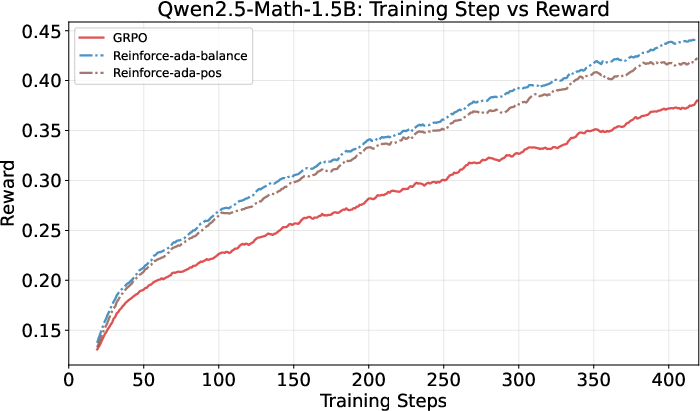
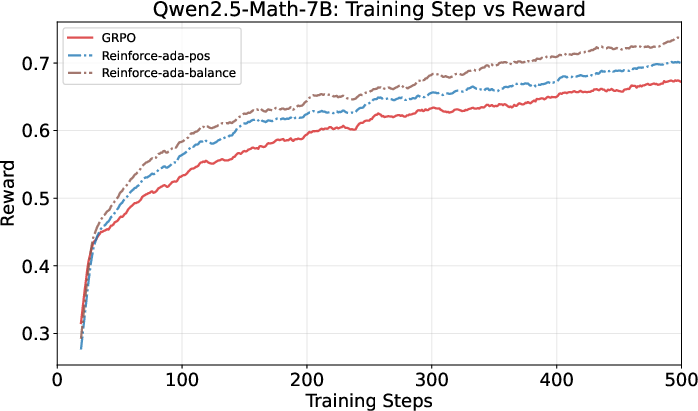
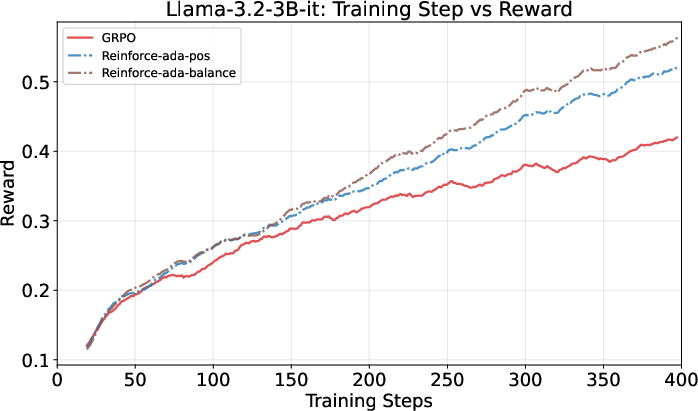
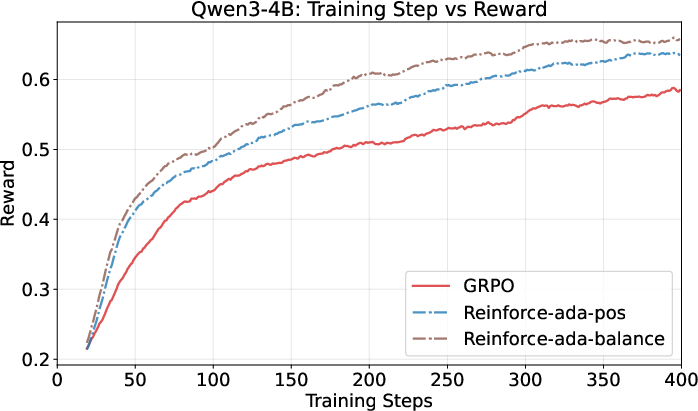
- Learns faster early on and keeps improving steadily, beating the traditional fixed-sampling approach (GRPO).
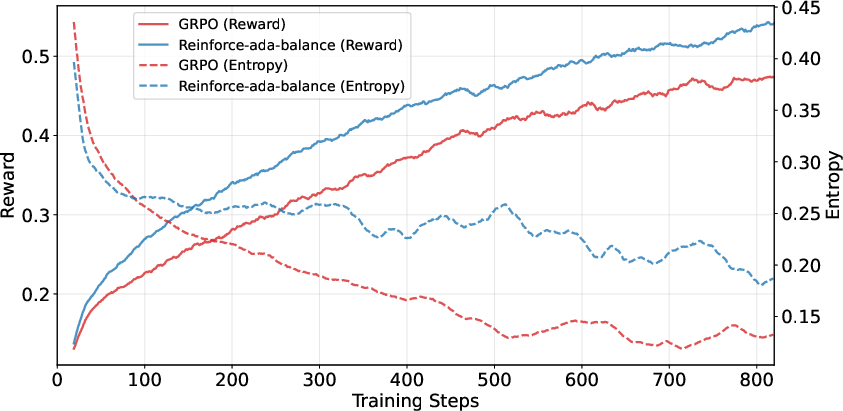
- Achieves higher accuracy (+1 to +3 points on average across test suites), especially with the Balanced variant (Reinforce-Ada-balance).
- Works best on harder prompt sets—where there’s more uncertainty and room to learn—because it keeps mining informative failures and avoids shutting down too early.
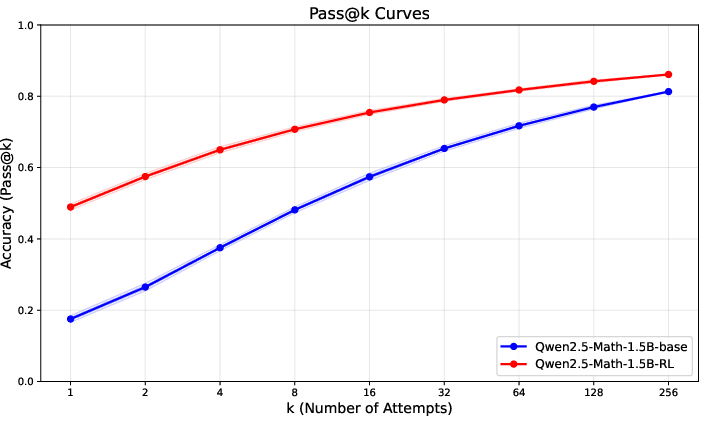
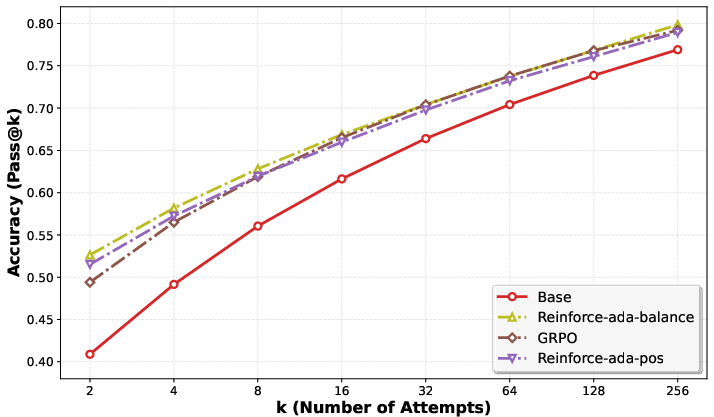
- Improves practical metrics like Pass@k (the chance of getting the right answer within k tries), especially for small k (like 1–8), which matters in real-world use.
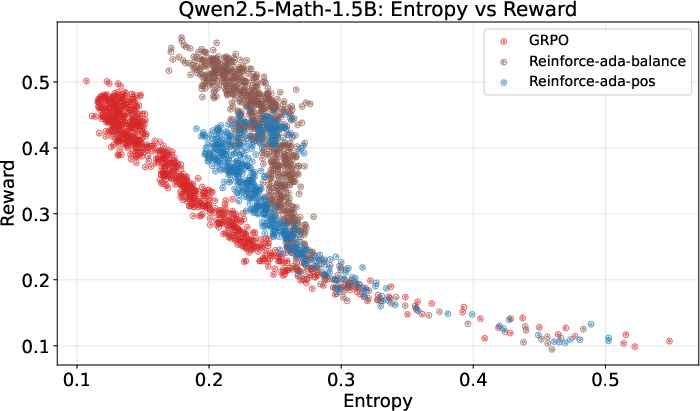
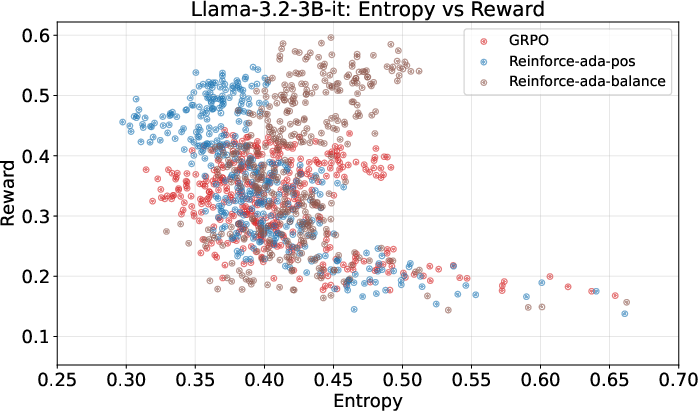
- Maintains diversity in answers (entropy), meaning the model avoids becoming too “rigid” or overconfident. This is good because a certain amount of exploration helps solve tricky problems.
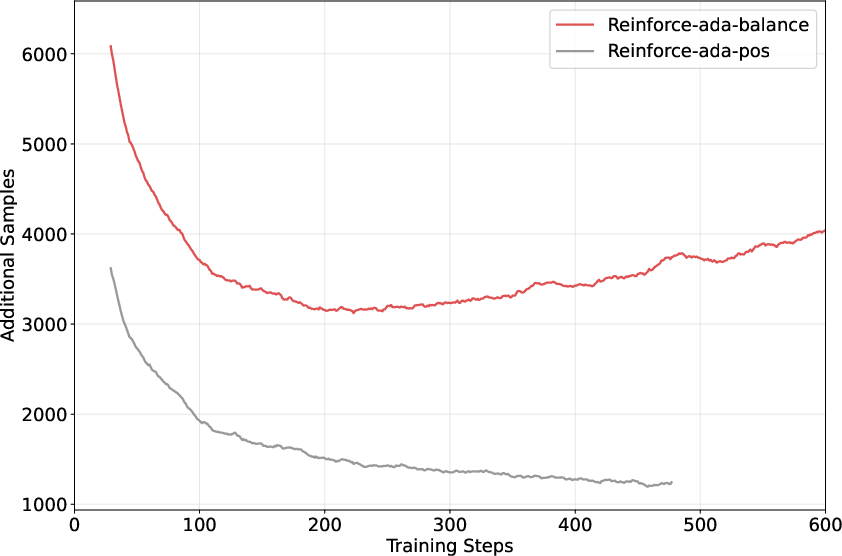
There is a moderate extra compute cost per training step because of the extra sampling, but it’s still much cheaper than using huge fixed groups for every prompt. In short, you get better training quality for a reasonable increase in cost.
What’s the big picture?
This paper shows that smarter data collection—deciding how many samples to take per prompt based on what you’ve seen so far—can fix a lot of stability and efficiency problems in RL training for LLMs. Instead of blindly giving every prompt the same number of tries, Reinforce-Ada:
- Focuses effort where it matters (uncertain prompts).
- Ensures each prompt provides a mix of successes and failures.
- Prevents the common “no learning signal” problem when all attempts are identical.
The result is more reliable and efficient training for reasoning-capable AI. This idea fits into a broader theme: better data curation during training (not just better algorithms) can make a big difference. The approach is plug-and-play, easy to use, and can complement other improvements in reinforcement learning.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and could guide future research.
- Theoretical guarantees: No formal analysis of bias/variance or sample complexity for the adaptive stopping scheme (successive elimination) under token-level PPO-style importance sampling and clipping; absence of proofs for unbiasedness or consistency of the gradient estimator when (i) exit-based stopping, (ii) balanced downsampling, and (iii) global baselines are combined.
- Bias from balanced downsampling: The selection of n/2 positive and n/2 negative samples per prompt changes the effective training distribution; the induced estimator bias and its effect on the true objective J(θ) under d0 are not characterized or corrected.
- Global-baseline mismatch: Advantages for selected samples are computed against a mean estimated from a larger superset of responses; potential selection-induced bias and its interaction with PPO clipping are not analyzed.
- Prompt-level distribution shift: Adaptive elimination reallocates sampling across prompts, altering the prompt distribution relative to d0; no importance weighting or correction is used to maintain unbiased optimization of Eq. (1).
- Compute-matched evaluation: Reported improvements are not normalized for equal inference budget or equal wall-clock time; missing head-to-head comparisons under fixed total tokens, fixed FLOPs, or fixed generation budget per run.
- Baseline comparisons: No direct empirical comparison to variance-aware budget-allocation methods (e.g., RAFT-EM/GVM-RAFT) or to uniform large-n (compute-matched), leaving unclear whether adaptive stopping is preferable under matched costs.
- Hyperparameter sensitivity: No systematic ablation on M (samples/round), N (rounds), n (group size), and exit-criteria thresholds; robustness regions and tuning guidelines are absent.
- Exit-condition design: Heuristic thresholds (e.g., “≥1 positive”, “≥n/2 pos/neg”) are not derived from uncertainty quantification; no exploration of confidence-interval–based or Bayesian stopping rules that adapt to per-prompt uncertainty.
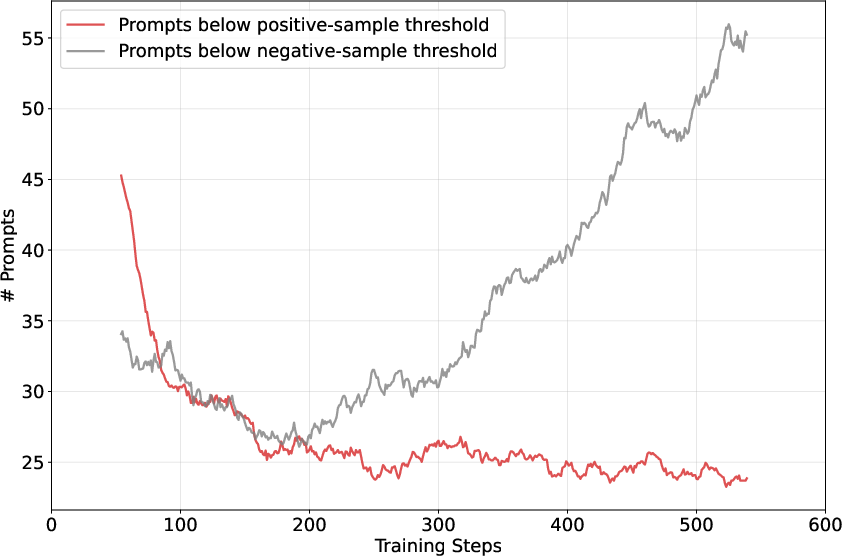
- Hard-negative quota stability: Reinforce-Ada-balance may require excessive sampling late in training when negatives are rare; no safeguard design or principled scheduler to cap overhead while preserving gradient quality.
- Off-policy corrections: Only token-level PPO ratios are used; the paper does not evaluate trajectory-level importance sampling, group-level ratio handling, or other off-policy stabilizers in combination with adaptive sampling.
- Verifier noise and reward misspecification: The method assumes accurate binary rewards; robustness to false positives/negatives (e.g., Math-Verify errors), stochastic verifiers, or uncertain/verifier-calibrated rewards is not examined.
- Non-binary and multi-objective rewards: Applicability to continuous rewards, process rewards, or multi-objective settings (e.g., accuracy, brevity, safety) is untested; exit rules and normalization for such rewards remain unclear.
- Generality beyond math: Experiments are limited to math reasoning; transfer to code generation, tool-use, safety alignment, instruction following, and multimodal tasks is untested.
- Scaling limits: Results are on small-to-mid models (1.5B–7B, 4B instruct); scalability to 30B–70B+ models and large distributed training regimes (throughput, latency, memory, scheduling) is not evaluated.
- Training stability metrics: Beyond reward/entropy, calibration, overconfidence, and unlearning dynamics induced by mining negatives are not measured; potential adverse effects on top-1 quality or general capabilities are not ruled out.
- Interplay with curriculum/difficulty selection: While synergy is hypothesized, there is no integrated, closed-loop design that jointly adapts prompt difficulty and per-prompt sampling; no study of oscillations or mode collapse under joint control.
- Token-length weighting: Sequence-level averaging is used, but effects on gradients for very long incorrect chains vs short correct ones are not analyzed; alternative normalization schemes (e.g., per-step baselines) are unexplored.
- Removal of σr in normalization: The choice to discard standard-deviation scaling is motivated empirically, but no controlled ablation across broader budgets/models quantifies stability vs performance trade-offs.
- Re-entry and memory of prompts: Prompts are deactivated within an iteration; whether and how hard prompts should re-enter across iterations (with cached statistics) to avoid stale estimates is not specified.
- Budget scheduling across rounds: M is fixed for active prompts; adaptive per-prompt M based on uncertainty/posterior variance was tried but not detailed; no analysis of when/why adaptive M should help or how to tune it.
- Global budget constraints: The method does not optimize a global compute budget across prompts/rounds (e.g., knapsack-style allocation) with guarantees on variance reduction per unit cost.
- Process supervision: The framework optimizes outcome rewards; combining adaptive sampling with process-level signals (stepwise rewards, self-verification, or CoT scoring) is not investigated.
- Safety and bias implications: Focusing compute on difficult prompts could skew the learned policy toward niche distributions; impact on safety, fairness, and unintended behaviors is unassessed.
- Pass@k vs deployment budgets: Gains are shown for Ave@32 and selected k values, but cost–quality curves (reward vs attempts vs compute) for deployment-relevant small k and tight latency constraints are not fully characterized.
- Robustness to data shifts: How adaptive sampling behaves under domain shifts or changing prompt distributions (e.g., new math topics) is unknown; no mechanism to detect or adapt to emergent hardness patterns.
- Integration with recent GRPO variants: Although claimed complementary, there are no empirical results combining Reinforce-Ada with alternative advantage estimators, clipping schemes, or group-level importance sampling.
- Failure modes and safeguards: Conditions under which adaptive sampling fails (e.g., extremely easy or extremely hard prompts, heavily noisy rewards) and corresponding fallback strategies are not established.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now using the paper’s findings and code, with links to likely sectors, products, and workflows. Each item also lists key assumptions/dependencies that affect feasibility.
- Software/AI infrastructure: Plug-and-play upgrade for RLHF/RLVR training loops
- What: Replace fixed-n GRPO sampling with Reinforce-Ada to reduce gradient variance and accelerate convergence in post-training of reasoning-capable LLMs.
- Where: Model training teams using frameworks like verl, TRL, vLLM-based pipelines.
- Products/workflows: “Adaptive Sampling Trainer” module; training dashboards showing active prompts, exit conditions, and reward-entropy curves; CI for RL runs with Balanced exit condition as default.
- Assumptions/dependencies: Availability of a verifier/reward signal; ability to generate multiple responses per prompt; minor integration work (generation API swap); compute overhead acceptable (≈1.4–2.8× step-time increase in reported settings).
- Production inference: Adaptive attempt budgeting (cost-aware Pass@k)
- What: At inference, stop sampling when a verifier passes or target diversity conditions are met, instead of using a fixed k per query.
- Where: Code assistants (run tests until pass), math/QA assistants (checker-based), RAG-verification workflows.
- Products/workflows: Adaptive “try-until-pass” sampler; per-query compute controllers that allocate more attempts to uncertain prompts and stop early on easy ones.
- Assumptions/dependencies: Fast, reliable per-query verification; latency budgets allow a few extra attempts; safeguards against verifier errors and reward hacking.
- Software engineering: RL post-training for code models with test-based rewards
- What: Use unit/integration tests as verifiers; allocate more rollouts for hard functions, collect a balanced set of passing/failing traces, and update with global baselines.
- Sector: Software, DevTools.
- Products/workflows: Code-repair/refactor bots; “self-healing” PR assistants; improved top-1 and top-8 correctness under limited sampling budgets.
- Assumptions/dependencies: Good test coverage; sandboxed execution for safety; handling flakiness in tests; compute for repeated trials.
- Education: Math tutors and graders with improved reasoning under small budgets
- What: Train/math-specialized LLMs using Reinforce-Ada with Math-Verify or equivalent checkers; deploy inference-time adaptive k to reduce cost while preserving accuracy.
- Sector: Education technology.
- Products/workflows: Homework helpers and auto-graders that remain diverse (avoid entropy collapse) yet improve Pass@k at k≤8; practice systems that surface “hard negatives” to improve teaching feedback.
- Assumptions/dependencies: Reliable verifiers (numeric/format checking); domain coverage beyond algebra requires curated checkers.
- Tool-using agents: Stability when tools can fail
- What: For agents that call tools/APIs, enforce balanced sampling to gather both valid and invalid tool trajectories and avoid zero-gradient regimes.
- Sector: Software, data platforms, customer support.
- Products/workflows: Trajectory filters that downsample to fixed n per prompt, require both successes and failures; tool-call validators; process rewards for partial credit.
- Assumptions/dependencies: Tool-call validity checkers; logging/telemetry to feed back failures; rate-limits and cost constraints for repeated trials.
- Data curation and curriculum-building for RL training
- What: Log exit conditions and active set dynamics to estimate prompt difficulty and pass rates; build curricula that present challenging prompts as models improve.
- Sector: AI/ML ops; academia.
- Products/workflows: Difficulty tags from adaptive sampling; online curriculum schedulers that keep uncertainty high; dashboards of “positives scarce vs. negatives scarce” bottlenecks.
- Assumptions/dependencies: Prompt pool large enough to avoid overfitting across epochs; simple heuristics suffice initially; periodic recalibration of difficulty models.
- Safety and alignment pipelines with verifier-based rewards
- What: Use adaptive sampling to gather balanced examples for safety objectives (e.g., refusal when harmful); enforce non-zero reward variance to prevent signal loss.
- Sector: Policy, platform safety.
- Products/workflows: Multi-checker “guardrail verifiers” (toxicity, personal data, jailbreaks) attached to adaptive loops; better sample efficiency than brute-force large-n.
- Assumptions/dependencies: High-precision verifiers for safety signals; careful bias control; logging and audits to detect reward hacking.
- Labeling/resource allocation: Human-in-the-loop budget focus
- What: Apply successive elimination to allocate human review or preference-collection budget toward prompts with highest uncertainty; stop early when signals saturate.
- Sector: Data operations; research labs.
- Products/workflows: Review queue prioritization by uncertainty; balanced sampling ensures a mix of positive/negative examples for preference models.
- Assumptions/dependencies: Reliable uncertainty proxies (pass rates, reward variance); reviewer SLAs; policies to avoid amplifying dataset biases.
- Evaluation practice: Reward–entropy frontier and small-k Pass@k as default views
- What: Adopt reward–entropy plotting and Pass@k for small k (≤8) as standard metrics to detect entropy collapse and practical gains.
- Sector: Academia, benchmarking, product eval.
- Products/workflows: Continuous evaluation dashboards tracking reward–entropy shifts and Pass@k; regression checks for entropy collapse.
- Assumptions/dependencies: Consistent temperature and decoding controls; stable benchmark splits; verifier availability for target domains.
Long-Term Applications
These applications require additional research, scaling, or domain-specific development (e.g., robust verifiers, reward models, or systems integration).
- Cross-domain reasoning with learned reward models
- What: Extend Reinforce-Ada to domains lacking automatic verifiers (law, medicine, scientific reasoning) by training reliable reward models; use balanced exit conditions to avoid collapse.
- Sectors: Healthcare, legal, research.
- Potential tools/workflows: Ensemble reward models; counterfactual/causal checks; triage to humans on edge cases.
- Assumptions/dependencies: High-quality, debiased reward models; strong calibration; governance for error analysis and red teaming.
- Multi-objective alignment with composite verifiers (helpfulness, harmlessness, honesty)
- What: Adaptive sampling over multiple reward channels with per-prompt uncertainty-aware budget allocation; ensure balanced positives/negatives across objectives.
- Sectors: Policy and safety, foundation model training.
- Tools/workflows: Objective-aware sampler; per-objective exit rules; Pareto-front dashboards.
- Assumptions/dependencies: Reliable, independent verifiers per objective; conflict resolution among objectives; compute and orchestration complexity.
- Robotics and embodied agents (simulation-in-the-loop training)
- What: Use simulators as verifiers to adaptively sample high-level plans; collect both successful/failed trajectories to improve planning robustness.
- Sector: Robotics, logistics, industrial automation.
- Tools/workflows: Sim2real-aware adaptive loops; scenario generators focusing on uncertain cases; safety constraints and reset policies.
- Assumptions/dependencies: Fast, high-fidelity simulators; safe exploration; bridging sim-to-real gaps; cost of repeated trials.
- Edge/on-device adaptation with verifiers
- What: Privacy-preserving, on-device adaptive sampling for personalized reasoning tasks (e.g., calendars, basic math/planning) when light-weight verifiers are available.
- Sector: Consumer devices.
- Tools/workflows: Lightweight verifiers; local caching; energy-aware budgets; occasional federated updates.
- Assumptions/dependencies: Strict privacy; resource constraints (compute, battery); resilient fallback to server-side training.
- Adaptive sampling for enterprise safety/compliance verification
- What: Train domain-specific models to reduce regulatory risk (finance, healthcare) by collecting “hard negatives” under adaptive budgets and process rewards (e.g., HIPAA/PCI checks).
- Sectors: Finance, healthcare, legal.
- Tools/workflows: Compliance verifiers; incident simulation; balanced sampling to prevent overconfidence on easy rules while catching edge-cases.
- Assumptions/dependencies: Comprehensive, evolving rulebases; auditability; governance sign-off; high cost of false positives/negatives.
- Energy/compute optimization as a platform capability
- What: Make “variance-aware compute allocation” a first-class feature of training platforms, optimizing total tokens and energy per unit of accuracy gained.
- Sectors: Cloud/AI infrastructure, energy.
- Tools/workflows: Schedulers that modulate inference budget per prompt; carbon-aware training modes; cost–accuracy Lagrangian tuning.
- Assumptions/dependencies: Accurate cost/energy telemetry; SLAs for throughput; extensibility to mixed workloads.
- Human–AI research co-pilots with uncertainty-aware exploration
- What: In scientific discovery and analytics, allocate sampling to hypotheses/questions with higher uncertainty; stop when evidence saturates or a verifier threshold is met.
- Sectors: R&D, pharma, materials.
- Tools/workflows: Hypothesis trackers; simulators/analysis verifiers; balanced evidence gathering workflows to avoid confirmation bias.
- Assumptions/dependencies: Clear, automatable success criteria; integration with lab pipelines; human oversight policies.
- Standard-setting and governance for RLHF data curation
- What: Codify variance-aware, adaptive data curation as a best practice for RLHF procurement and public funding programs to reduce waste and improve reproducibility.
- Sector: Policy, funding agencies, consortiums.
- Tools/workflows: Guidelines for verifiers, exit conditions, and reporting reward–entropy curves; benchmarks emphasizing small-k Pass@k and stability.
- Assumptions/dependencies: Community consensus; robust open-source implementations; domain-specific verification standards.
Common assumptions and dependencies across applications
- Verifier availability and quality: Success depends on accurate, low-latency verifiers or reward models. Noisy verifiers can bias global baselines and misallocate budget.
- Compute/latency trade-offs: Balanced exit conditions improve performance but increase sampling cost; systems need budget caps and back-off strategies.
- Safety and reward hacking: Strong monitoring is needed to prevent models from exploiting verifier loopholes; diversified checks mitigate this.
- Data scale and diversity: Larger, varied prompt pools maximize benefits of adaptive sampling; curriculum integration yields stronger gains on hard prompts.
- Integration maturity: While the code is plug-and-play for certain stacks (e.g., verl), broader ecosystem support (TRL, Ray, orchestration) makes adoption smoother.
Glossary
- Advantage: In policy gradient methods, the excess reward of an action over a baseline, used to reduce variance in gradient estimates. "Compute advantage for -th response of prompt as ."
- Ave@32: An evaluation metric averaging accuracy over 32 samples per problem. "For all evaluations, we report the Ave@32 metric, where we generate 32 responses per problem using a temperature of 1.0 and a maximum token limit of 4096 and compute the average accuracy."
- Balanced sampling: Constructing training groups with roughly equal numbers of correct and incorrect responses to ensure non-zero reward variance. "This balanced sampling strategy is an effective technique used in several recent works \citep{xu2025not, ye2025beyond}."
- Baseline: A reference value subtracted from rewards to reduce variance while keeping the gradient unbiased. "A standard remedy introduces a baseline , yielding "
- Clipping: The PPO technique of limiting the importance sampling ratio to stabilize policy updates. "we clip the gradient when the importance sampling ratio $\rho_{i,t} = \frac{\pi_\theta(a_{i,t}|x)}{\pi_{\theta_{\text{old}(a_{i,t}|x)}$ exceeds thresholds"
- Curriculum learning: A strategy that orders training data by difficulty to improve learning efficiency. "Recent studies have explored macro, prompt-level strategies, such as curriculum learning \citep{zhao2024automatic, shi2025efficient, zhang2025speed}, to shape the distribution of training data during online learning."
- Entropy collapse: A degeneration of the policy to low-entropy (overly deterministic) behavior during training. "yielding more stable advantages, slower entropy collapse, and higher final accuracy."
- Entropy regularization: A loss term that encourages exploration by increasing the policy’s entropy. "an entropy regularization term with coefficient is applied"
- Expectation–Maximization (EM) framework: An iterative optimization approach alternating between inferring latent variables and optimizing parameters. "frame rejection sampling fine-tuning (RAFT) \citep{dong2023raft} within an Expectation-Maximization (EM) framework \citep{singh2023beyond, zhong2025brite}."
- Group Relative Policy Optimization (GRPO): A group-based policy optimization method that normalizes advantages within prompt-specific response groups. "Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmath} extends this principle by assigning responses per prompt and normalizing each sampleâs advantage:"
- Importance sampling: Reweighting samples collected under one policy to estimate or optimize another policy. "Since the current policy differs from the sampling policy, we need to correct the distribution by importance sampling."
- Importance sampling ratio: The likelihood ratio between current and behavior policies used to weight gradients. "we clip the gradient when the importance sampling ratio $\rho_{i,t} = \frac{\pi_\theta(a_{i,t}|x)}{\pi_{\theta_{\text{old}(a_{i,t}|x)}$ exceeds thresholds"
- KL penalty: A regularizer that penalizes divergence from a reference policy via Kullback–Leibler divergence. "while no KL penalty is introduced."
- Multi-armed bandit: A framework for allocating sampling budget across options to balance exploration and exploitation. "inspired by successive elimination methods in the multi-armed bandit literature \citep{slivkins2019introduction}."
- Oversample-then-downsample: A data construction strategy that generates many responses and then selects a subset by criteria. "some methods employ an oversample-then-downsample strategy: they first generate a large, uniform set of responses for each prompt and then select a subset based on specific criteria."
- Pass rate: The probability that a model produces a correct response on a prompt. "pass rates () are first estimated periodically using a small portion of compute budget"
- Pass@k: The probability that at least one of k generated responses is correct. "Pass@k curves (left) and the ratio of prompts with all-correct responses (right) for two models on a subset of the Open-R1 prompt set."
- Policy gradient: A class of RL methods that directly optimize policy parameters via gradients of expected reward. "Vanilla policy gradient with small has notoriously high variance."
- Proximal Policy Optimization (PPO): A stable policy gradient algorithm that uses clipped importance-weighted objectives. "Finally, we employ the importance sampling correction and clipping technique from the seminal PPO work \citep{schulman2017proximal}."
- Rejection Sampling Fine-Tuning (RAFT): A post-training approach that selects high-reward samples via rejection sampling for supervised updates. "This is related to prior work on budget allocation for rejection sampling fine-tuning \citep{yao2025optimizing, dong2023raft}"
- Reward diversity: Ensuring a mix of successes and failures in training groups to avoid zero-variance gradients. "To stabilize updates, we form fixed-size groups with enforced reward diversity"
- Successive elimination: An online allocation strategy that deactivates items once stopping criteria are met. "Reinforce-Ada interleaves estimation and sampling in an online successive elimination process"
- Trajectory-level importance sampling: Applying importance weighting to entire generated sequences rather than per token. "We notice that the trajectory-level importance sampling suggested by recent work \citep{zheng2025group} can also be combined with the proposed adaptive sampling"
- Verifier: An automated checker that labels model outputs as correct or incorrect. "which a verifier scores as ."
Collections
Sign up for free to add this paper to one or more collections.

