- The paper introduces a novel two-stage data selection pipeline combining offline PageRank-weighted DPP and online explorability metrics to boost data efficiency.
- The paper demonstrates substantial speed-ups, achieving factors of 1.85 and 1.66 on AIME24 and AIME25 benchmarks respectively, while maintaining performance.
- The paper validates the effectiveness of its approach through ablation studies, confirming that both dynamic replay and precise sample selection are critical for reduced computational load.
Towards High Data Efficiency in Reinforcement Learning with Verifiable Reward
Introduction
The paper addresses the challenge of enhancing data efficiency in Reinforcement Learning with Verifiable Rewards (RLVR), which is crucial in optimizing the training process of LLMs in reasoning tasks. With the growing compute demand and dataset size, traditional methods tend to incur significant computational costs. The proposed approach in this paper focuses on selecting high-quality subsets of data, both offline and online, to streamline the training pipeline.
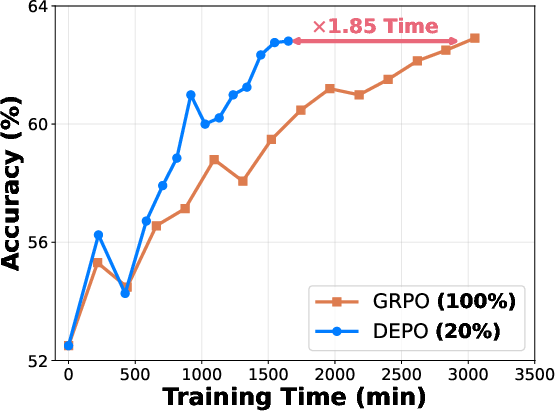
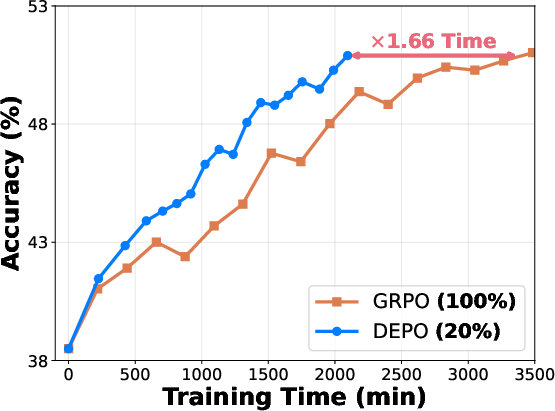
Figure 1: AIME24 benchmark results showing significant speed-up with the proposed method using 20% training data.
Methodology
The methodology is centered around a two-stage data selection pipeline designed to reduce redundancy and computational overhead while maintaining model performance.
Offline Data Selection
The offline strategy involves constructing a sample graph based on feature representations and applying a PageRank-weighted Determinantal Point Process (DPP) technique. This method ensures that samples retained are both diverse and influential. After pruning, further refinement is achieved by selecting samples such that their difficulty levels follow a normal distribution.
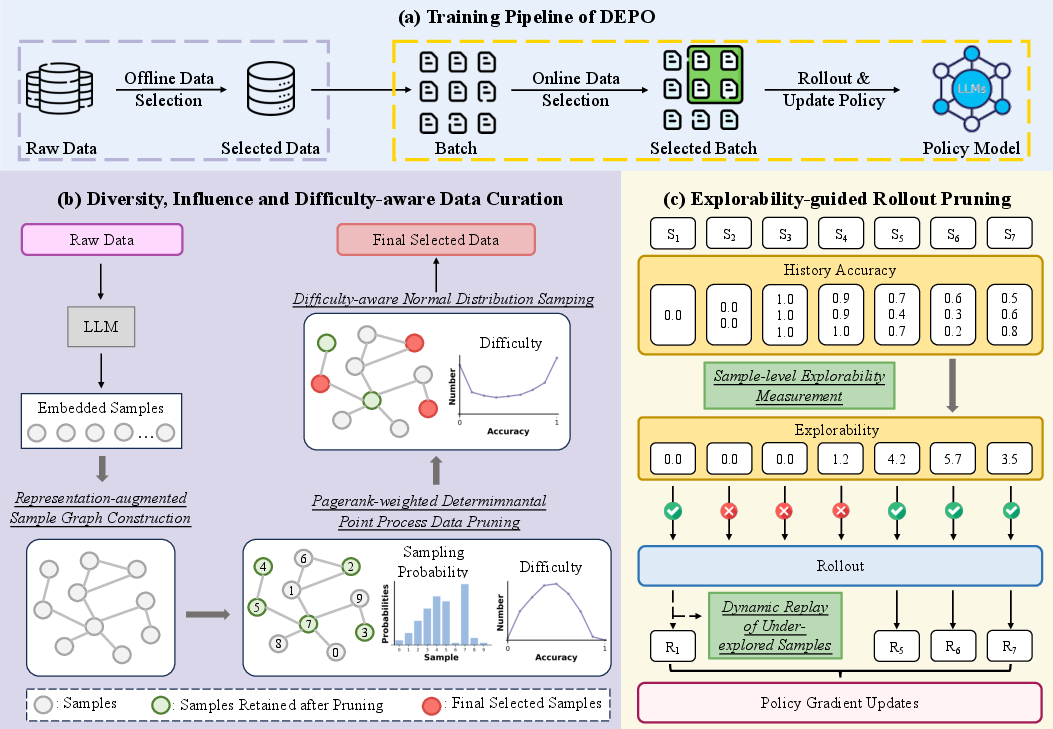
Figure 2: The overview of the proposed approach. Efficient pipeline through offline and online data selection.
Online Data Selection
During the RLVR training, a sample-level explorability metric is introduced to guide rollout pruning, prioritizing samples with high exploration potential. Moreover, a dynamic replay mechanism is employed to revisit under-explored samples, ensuring a balanced training progression across all samples.
Experimental Results
Experiments on several reasoning benchmarks underline the effectiveness of this approach. The model achieves comparable performance to traditional methods while drastically reducing the amount of required data and rollout computation. Detailed benchmark results demonstrated speed-up factors of 1.85 and 1.66 on AIME24 and AIME25, respectively.
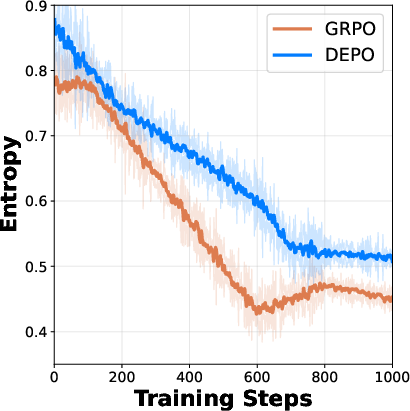
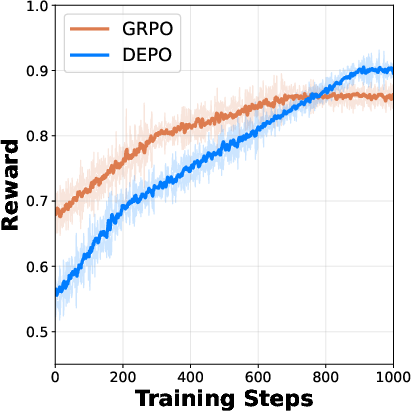
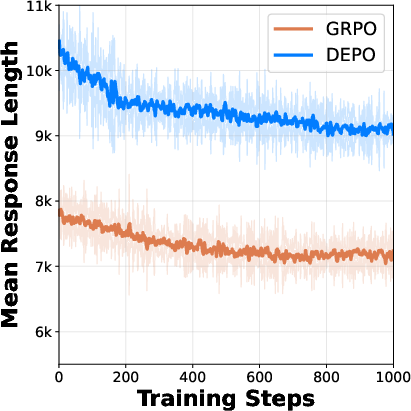
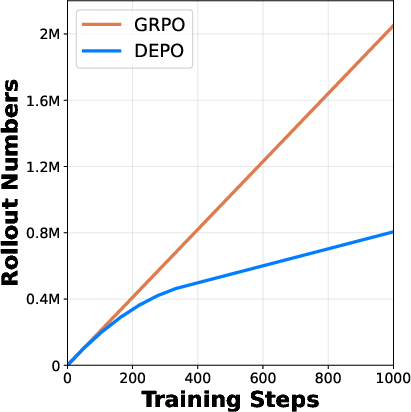
Figure 3: Entropy dynamics during training showcasing enhanced sampling efficiency.
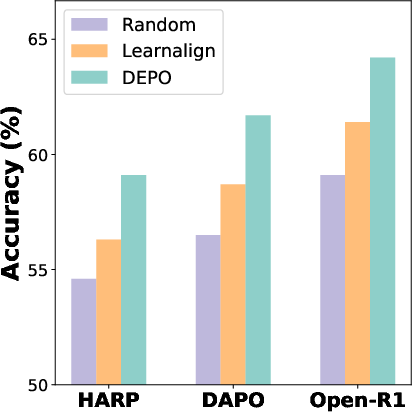
Figure 4: Offline Selection method utilizing PageRank-weighted determinantal point processes.
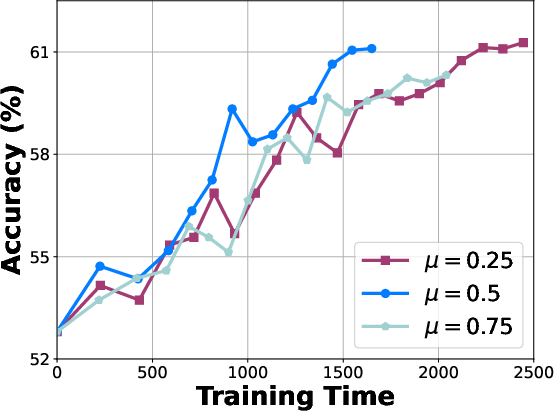
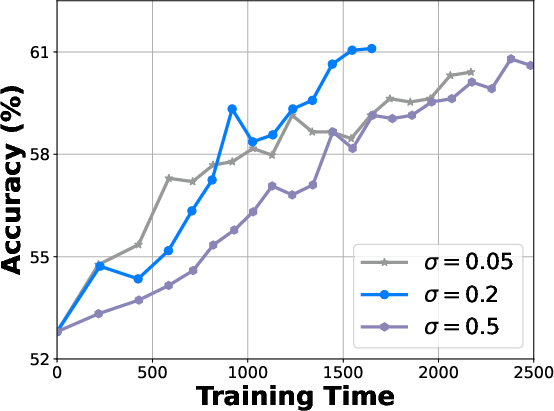
Figure 5: Comparison between different sampling strategies.
Ablation Studies
Additional studies confirmed the critical role each component plays, from the determinantal point process in offline selection to explorability metrics for rollout pruning. The method's robustness across varying dataset sizes and sampling ratios illustrates its adaptability and efficiency.
Conclusion
The proposed data-efficient policy optimization pipeline effectively reduces computational burden while accelerating RLVR training. This approach holds promise for future deployments in large-scale ML systems, paving the way for more efficient AI training methodologies. Detailed experiments confirm its effectiveness across different benchmarks and model configurations, establishing a foundational approach to data-efficient AI training.
The insights from this paper are set to influence future research on improving data efficiency, particularly in reinforcement learning applications involving LLMs, as the demand for reasoning capabilities in real-world applications grows.

