VCRL: Variance-based Curriculum Reinforcement Learning for Large Language Models
Abstract: Policy-based reinforcement learning currently plays an important role in improving LLMs on mathematical reasoning tasks. However, existing rollout-based reinforcement learning methods (GRPO, DAPO, GSPO, etc.) fail to explicitly consider LLMs' learning ability for samples of different difficulty levels, which is contrary to the human cognitive process of mathematical reasoning tasks from easy to difficult. Intuitively, we find that the variance of the rollout group's reward in RLVR partly reflects the difficulty of the current sample for LLMs. Samples that are too easy or too difficult have a lower variance, while samples with moderate difficulty have a higher variance. Based on this, we propose VCRL, a curriculum reinforcement learning framework that dynamically controls the difficulty of training samples based on the variance of group rewards. Experiments on five mathematical benchmarks and two models reveal the advantages of VCRL over the current LLM RL baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new way to train LLMs to solve math problems more effectively. The idea is called VCRL, which stands for Variance-based Curriculum Reinforcement Learning. It helps the model learn in a smart order—from easier problems to harder ones—by measuring how “uncertain” the model is on each problem. This makes training faster, more stable, and leads to better results.
What questions the paper asks
The paper focuses on these simple questions:
- How can we help an LLM learn math reasoning more efficiently, like a student who practices problems in a good order?
- Can we figure out which training problems are “just right” for the model at each point in training—not too easy and not too hard?
- Does this approach beat popular training methods used today?
How the method works (in everyday language)
First, a few helpful terms explained with simple analogies:
- Reinforcement Learning (RL): Imagine teaching a robot or model by letting it try things and rewarding it when it gets them right. The model improves by learning from rewards.
- Rollouts: These are multiple attempts the model makes to answer the same question. It’s like taking several tries at solving one math problem in different ways.
- Verifiable Rewards (RLVR): In math tasks, a reward is easy to check—if the answer is correct, give 1 point; if not, give 0. This is a “verifiable” reward.
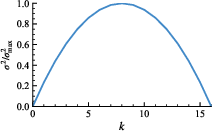
- Variance: This measures how spread out the results are. If the model’s rollouts for one problem are half correct and half wrong, the variance is high. If all are correct or all are wrong, variance is low.
Here’s the core idea in VCRL:
- Pick “just right” problems using variance. If a problem is too easy, all attempts are correct—low variance. If it’s too hard, all attempts are wrong—also low variance. If it’s in the middle, some tries are right and some are wrong—high variance. These “medium difficulty” problems are perfect for learning.
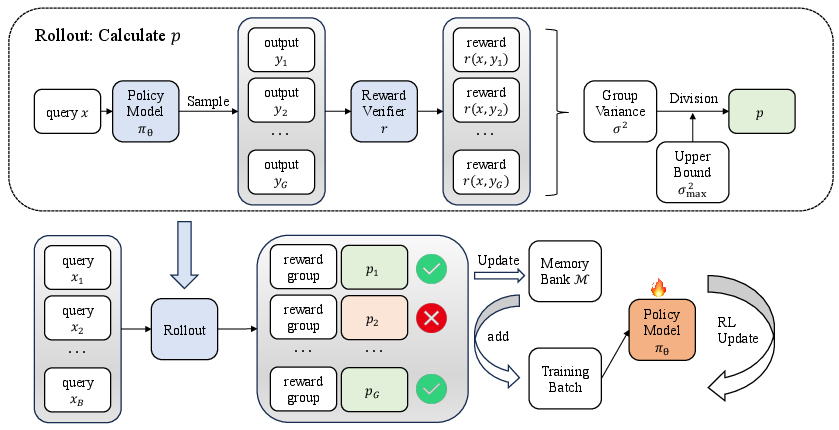
- Dynamic Sampling: During training, the model generates several answers (rollouts) per problem. VCRL computes a score (called p) that tells how high the variance is for that problem. If p is high, the problem is useful right now; if p is low, skip it.
- Replay Learning with a Memory Bank: The system keeps a “memory” of good, high-value problems—like a smart flashcard deck. When the current batch doesn’t have enough “just right” problems, it pulls some from memory. This keeps training focused on what helps the model learn fastest.
Under the hood, VCRL sits on top of a popular RL method called GRPO (Group Relative Policy Optimization), but the main takeaway is simple: VCRL carefully controls which problems the model trains on, based on how uncertain its answers are.
What the researchers found
The team tested VCRL on five math benchmarks:
- AIME-2024 and AIME-2025 (very challenging contest problems),
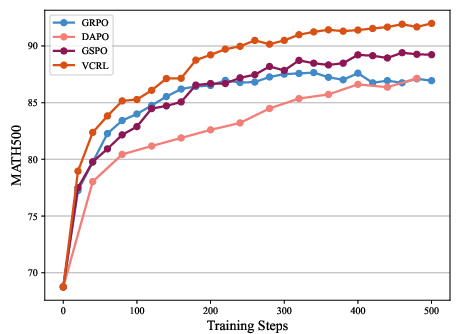
- MATH500,
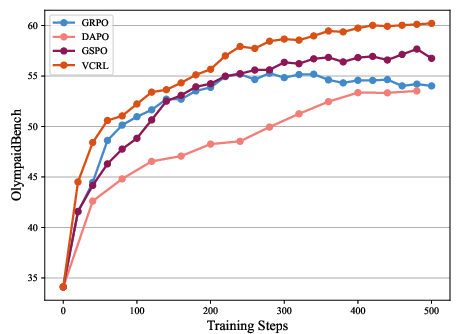
- OlympiadBench,
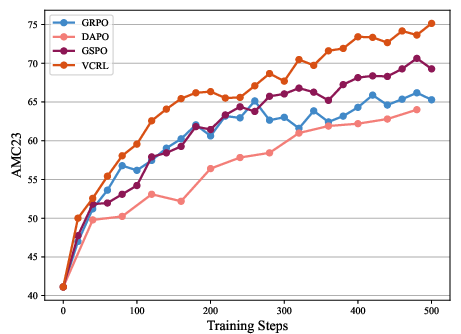
- AMC23.
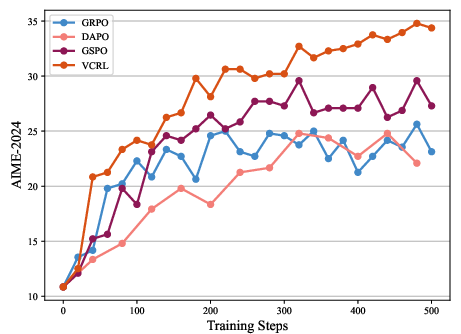
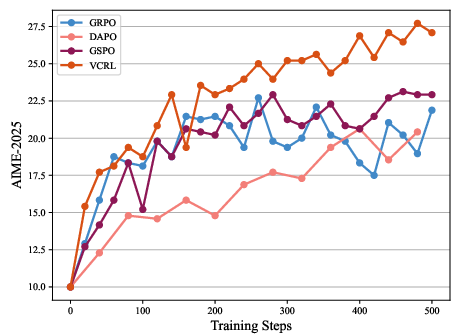
They trained two model sizes (Qwen3-4B and Qwen3-8B) and compared VCRL to other strong RL methods (GRPO, DAPO, GSPO).
Key results:
- VCRL consistently scored the best across all benchmarks and both model sizes.
- It improved the bigger model’s average score from about 33 (no RL) to about 58—beating the next-best RL method by several points.
- It improved the smaller model’s average score from about 27 (no RL) to about 49—again, clearly ahead of other RL baselines.
- VCRL improved faster early in training. In the first 100 steps, it pulled ahead quickly because it focused on the right problems at the right time.
- An ablation study (turning parts of the method on/off) showed both pieces—Variance-based Dynamic Sampling and Replay Learning—each added meaningful gains.
Why this matters:
- The model learns more efficiently when it practices problems that challenge it just enough.
- This approach is especially helpful on tough math problems that require careful step-by-step reasoning.
Why this research is important
- Smarter learning: VCRL mimics how people learn—starting from easier tasks and moving up—without hand-labeling problem difficulty. It figures out difficulty automatically from how the model performs.
- Better performance with fewer wasted efforts: By avoiding problems that are too easy or too hard, the model spends more time where it can actually grow.
- General idea: While tested on math, the approach could help models learn other skills that benefit from practice and feedback, like coding or scientific reasoning.
Simple takeaway
Think of training an AI like coaching a student for a math contest. If you always give problems that are way too easy or way too hard, the student doesn’t improve much. VCRL finds the “just right” problems—where the student sometimes succeeds and sometimes fails—and focuses practice there. It also keeps a smart stash of great practice problems to revisit at the right time. The result: faster learning and better scores.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each point is formulated to be concrete and actionable for future research.
- Lack of theoretical guarantees: No formal convergence analysis or sample-efficiency bounds for VCRL’s variance-based sampling under policy-gradient updates (e.g., GRPO, DAPO, GSPO), nor a proof that maximizing group-reward variance reliably improves learning dynamics.
- Assumption validity of “variance ≈ difficulty”: The paper assumes binary reward variance correlates with problem difficulty for the current model, but does not empirically validate this against human difficulty labels, solver hardness metrics, or calibrated success probabilities.
- Sensitivity to verifier noise: High reward variance may reflect noisy or inconsistent verifiers rather than true uncertainty; the method’s robustness to reward noise, parsing errors, or reward leakage is not analyzed.
- Generalization beyond binary rewards: VCRL is derived for RLVR’s Bernoulli rewards; it is unclear how to extend the approach to continuous or shaped rewards (e.g., partial credit, program tests), including the choice of normalized difficulty metric when .
- Reliability of variance estimation with small group sizes: With , the binomial variance estimate can have high sampling variance; there is no analysis of estimation error, confidence intervals, or corrections (e.g., Beta-Binomial smoothing) and how these affect sample selection.
- Hyperparameter sensitivity and schedules: No systematic study of sensitivity to the variance threshold schedule (), momentum constant , memory bank capacity, replay limits (max 2), or group size ; the chosen values lack justification and could critically affect outcomes.
- Dynamic thresholding vs fixed thresholds: Using fixed rather than percentile-based or adaptive thresholds may result in unstable acceptance rates as the model improves; effects on training diversity and stability are not explored.
- Memory bank staleness and priority updates: The memory bank’s priority is updated by time since last access (), not by re-evaluated with the current model; stale high- samples may persist despite becoming easy/hard later. Policies for decaying/removing outdated samples are unspecified.
- Sampling policy from memory bank: It is unclear whether “Pop queries” selects highest-priority samples deterministically or stochastically, and how this impacts overfitting, diversity, or cycling through similar mid-difficulty items.
- Compute efficiency and waste: VCRL requires full -rollouts per query to compute before filtering; the method does not quantify the fraction of compute spent on discarded samples nor propose cheaper pre-screening (e.g., fewer rollouts, entropy proxies) to reduce waste.
- Exploration vs exploitation trade-off: Emphasizing mid-difficulty samples may reduce exploration on very hard tasks and reinforce gaps in competence; there is no mechanism or study on re-introducing hard tasks at later stages or diversified sampling to prevent “curriculum myopia.”
- Catastrophic forgetting of easy fundamentals: Filtering out “too easy” tasks could erode base skills or formatting conventions over long training; no evaluation tracks retention of basic correctness or token efficiency.
- Integration with other rollout objectives: VCRL is implemented only atop GRPO; compatibility, benefits, and potential pitfalls when combined with GSPO’s sequence-level ratio or DAPO’s clip-higher/token-level losses are not evaluated.
- Reward shaping interactions: The approach assumes sparse, outcome-level rewards; how VCRL interacts with step-wise verifiers, process rewards, or reward shaping (e.g., correctness + brevity + format) is left unexplored.
- Model and domain generality: Results are limited to Qwen3-4B/8B on math benchmarks; there is no evaluation on larger models (e.g., 30B–70B), other architectures (LLaMA, Mistral), or non-math domains (code, tool use, retrieval, agent tasks).
- Test-time scaling dependencies: The paper claims improved TTS but does not analyze how gains vary with inference-time parameters (rollout count, temperature, CoT length), nor the compute–accuracy trade-offs induced by VCRL-trained policies.
- Distributional robustness and topic diversity: Filtering by variance may skew training towards certain problem types or lengths; no analysis of topic coverage, length distribution, or whether VCRL introduces hidden biases in the training corpus.
- Statistical significance and variability: Benchmarks report avg@16 but omit variance, confidence intervals, or significance testing across multiple seeds; stability claims are not supported by quantitative measures (e.g., KL drift, gradient norms).
- Token efficiency and length control: VCRL may favor longer CoTs if they yield mixed outcomes; impacts on generation length, token efficiency, and cost are not measured.
- Replay limit choice: The cap of 2 replays per sample is arbitrary; no evidence is provided on the optimal replay policy or how this cap affects convergence, diversity, or overfitting.
- Curriculum schedule design: The rationale for “ = 0.3 for first 20 steps, then 0.8” is unclear; alternative schedules (e.g., annealing, adaptive percentile, dual-threshold bands) and their effect on learning phases are not examined.
- Alternative uncertainty metrics: Only group-reward variance is used; untested alternatives (e.g., predicted success probability, entropy of policy, margin between best/worst rollouts, self-consistency variance) may be more robust or cheaper.
- Data leakage and verifier reliability in math: Benchmarks rely on answer-verifier correctness; the paper does not address potential data leakage or benchmark contamination risks, nor cross-checks with step-wise verification to confirm genuine reasoning gains.
- Memory bank capacity and eviction strategy: The paper does not specify the bank’s size, eviction policy, or how to balance high- retention against training diversity and fresh sample inflow.
- Batch-level acceptance dynamics: There is no monitoring of the proportion of queries passing the filter over time, nor controls to avoid too few accepted queries (leading to heavy reliance on memory bank and reduced novelty).
- Ablations are incomplete: The ablation isolates two components but lacks per-benchmark breakdowns, parameter sweeps (e.g., , , ), or removal/variation of memory bank features (e.g., priority formulation, sampling scheme).
- Practical reproducibility: Key implementation details (random seeds, exact verifier logic, code release, pipeline configurations) are not provided, making replication and fair comparison difficult.
- Safety and alignment considerations: Focusing training on mid-difficulty items may inadvertently optimize for reward hacks (formatting or guessing) rather than robust reasoning; failure modes and safety implications are not studied.
- Extension to multi-task curricula: The approach does not address how to coordinate variance-based sampling across heterogeneous tasks (math, code, QA) where difficulty and reward semantics differ, nor how to schedule cross-task curricula.
Practical Applications
Practical Applications of VCRL (Variance-based Curriculum Reinforcement Learning)
The paper introduces a reinforcement learning framework for LLMs that dynamically selects training samples based on reward variance and stabilizes training with a replay memory bank. These innovations directly enable more efficient, stable, and scalable training for tasks with verifiable outcomes (e.g., correctness checks, unit tests, format validators). Below are actionable applications for industry, academia, policy, and daily life, grouped by immediacy and including sectors, potential tools/workflows, and feasibility caveats.
Immediate Applications
The following use cases can be implemented now with existing RLVR/GRPO-style training pipelines, provided a reliable verifier and compute resources.
- Variance-based curriculum plugin for LLM training pipelines
- Sector: software/AI (model training), MLOps
- What: Integrate a “Variance Sampler” and “Replay Memory Bank” into GRPO/DAPO/GSPO or VERL-based RLVR workflows to prioritize moderately difficult samples that maximize learning signal.
- Tools/Workflows:
- Variance scoring module (
p = σ²/σ²_max) per prompt’s rollout group - Threshold scheduling (e.g., warm-up low κ, then high κ)
- Priority queue memory bank with momentum update
- Assumptions/Dependencies: binary or bounded scalar rewards; reliable verifier; enough rollouts (G≥8–16) to estimate variance; training framework support (e.g., VERL).
- Faster, lower-cost training for math and code reasoning models
- Sector: education (EdTech), software (dev tools), energy (compute efficiency)
- What: Reduce wasted compute on too-easy/too-hard samples, shorten time-to-quality for math solvers and coding assistants (using unit-test verifiers).
- Tools/Workflows: RLVR with pass/fail verifiers (math answer correctness, code unit tests), adaptive sampling based on variance.
- Assumptions/Dependencies: tasks must have verifiable outcomes; sufficient data diversity; tuning of κ and momentum α.
- Data curation and difficulty labeling via rollout reward variance
- Sector: academia (dataset design), AI product teams (data ops)
- What: Automatically annotate datasets with “current-model difficulty” using group reward variance to inform curriculum design, active sampling, and replay.
- Tools/Workflows: On-the-fly difficulty tagging in RL logs; “variance-curated” subsets for subsequent training runs.
- Assumptions/Dependencies: variance reflects difficulty for the current model; consistent verifier; enough rollouts per sample.
- Improved agent reliability in tool-use tasks with verifiable outcomes
- Sector: software/agents, enterprise automation
- What: Apply VCRL to tasks with binary verifiers (e.g., successful API/tool invocation, valid SQL execution), targeting uncertainty frontier samples to accelerate skill acquisition.
- Tools/Workflows: RLVR on tool pipelines; variance-based filtering; memory bank replay of high-value tool-use interactions.
- Assumptions/Dependencies: robust tool-call verifiers; stable reward definitions; careful handling of rollout cost.
- Training stability monitoring and governance
- Sector: MLOps, AI governance
- What: Monitor p-scores and memory bank composition as training quality signals; set guardrails (e.g., minimum high-variance share).
- Tools/Workflows: “Curriculum RL Dashboard” tracking p-distribution, replay counts, and performance curves.
- Assumptions/Dependencies: instrumentation in training stack; thresholds aligned with model size and task difficulty.
- Personalized math tutoring assistants with verifiable practice
- Sector: education (consumer/enterprise)
- What: Deploy models trained with VCRL for step-by-step math reasoning, improving accuracy on competition-level problems; tutors select practice items near the student’s uncertainty frontier (mirroring VCRL).
- Tools/Workflows: RL-trained math LLM; exercise generators with correctness verifiers; adaptive practice selection.
- Assumptions/Dependencies: high-quality math verifiers; privacy-safe user data handling.
Long-Term Applications
These require further research, domain-specific verifiers, scaling, or validation beyond math/code tasks.
- General-purpose curriculum RL for verifiable decision-making
- Sector: healthcare (clinical decision support), finance (compliance and risk), robotics (planning), energy (grid management)
- What: Extend VCRL to domains where decisions are checkable against rules/simulations (e.g., constraint satisfaction, safety checks, simulation outcomes).
- Tools/Workflows: Domain-specific verifiers (clinical guidelines, risk constraints, physics simulators); variance-driven sampling for frontier tasks; replay to stabilize rare-but-critical scenarios.
- Assumptions/Dependencies: high-fidelity, trustworthy verifiers; regulatory compliance; robust simulation-to-real guarantees (robotics).
- Auto-curriculum agents that learn from interaction uncertainty
- Sector: agentic AI, software automation
- What: Agents adapt difficulty based on uncertainty (variance of outcomes) in live environments, replaying valuable interactions to accelerate skill acquisition.
- Tools/Workflows: Online VCRL with test-time interaction; event-driven replay memory; adaptive κ scheduling.
- Assumptions/Dependencies: safe exploration; scalable logging and replay; drift detection.
- Formal reasoning and theorem-proving curricula with proof verifiers
- Sector: academia (math/logic), software (formal methods)
- What: Train proof-generating LLMs against proof checkers, using variance to select informative theorems/lemmas near current competence.
- Tools/Workflows: RLVR with proof checkers (Coq/Lean/Isabelle); curriculum replay on borderline proofs; sequence-level ratios (GSPO-style) combined with VCRL.
- Assumptions/Dependencies: strong formal-verification infrastructure; scalable rollout generation; avoidance of proof shortcuts.
- Curriculum RL for compliance-by-construction systems
- Sector: policy/regulation, finance, legal tech
- What: Use verifiers encoding regulations (e.g., KYC/AML constraints, privacy policies) and VCRL to train models that preferentially learn edge cases where compliance is uncertain.
- Tools/Workflows: “Regulatory verifiers” (rule engines); variance-based curriculum to focus on gray areas; replay of borderline cases to reduce risk.
- Assumptions/Dependencies: codified, machine-checkable regulations; auditing; legal oversight.
- Energy-aware AI training standards and procurement guidelines
- Sector: policy, energy, cloud providers
- What: Encourage curriculum RL methods (like VCRL) to reduce energy by cutting futile rollouts; include variance-based sampling in green AI standards.
- Tools/Workflows: procurement checklists requiring adaptive sampling; reporting of p-distributions and compute savings.
- Assumptions/Dependencies: standardized metrics; transparent training logs; third-party verification.
- Cross-domain difficulty estimation services (DataOps)
- Sector: AI infrastructure, data platforms
- What: Offer “difficulty-as-a-service” via rollout-variance scoring APIs to help teams build curricula without manual labeling.
- Tools/Workflows: hosted variance estimators; batched rollouts; memory bank management; connectors to training frameworks.
- Assumptions/Dependencies: access to model and verifier; data privacy/security; cost-effective rollout orchestration.
- Hybrid test-time scaling policies informed by training variance
- Sector: software/AI products
- What: Use training-time p-signals to set dynamic inference strategies (e.g., longer CoT or more samples on historically high-variance topics).
- Tools/Workflows: topic/skill-level variance profiles; inference-time routing (TTS) to allocate compute where uncertainty is high.
- Assumptions/Dependencies: reliable linkage between training variance and inference uncertainty; cost control; latency SLAs.
- Safe exploration protocols for critical tokens/steps
- Sector: AI safety, governance
- What: Combine VCRL with techniques that target critical tokens/decision points (e.g., adjusting KL penalties) to systematically explore high-variance reasoning regions while enforcing safety.
- Tools/Workflows: step-level uncertainty tracking; exploration boosts on critical steps; replay of error-prone reasoning paths.
- Assumptions/Dependencies: token-level verifiers or proxies; safety constraints; careful hyperparameter tuning to avoid degenerate behavior.
In all cases, the core dependencies include:
- Existence and quality of verifiers (binary or bounded scalar rewards).
- Sufficient rollouts per sample (to estimate variance reliably).
- Compute budget and RL framework support (e.g., GRPO/GSPO/DAPO, VERL).
- Proper threshold scheduling (κ) and memory bank momentum (α) tuning for stability.
- Domain generalization beyond math requires careful reward design and safety considerations.
Glossary
- Actor: The policy network in an RL setup that outputs actions (here, token probabilities) and is updated during training. "PPO optimizes the following objective for policy optimization to update the actor in the proximal region of the old policy"
- AdamW: An optimizer that decouples weight decay from gradient updates to improve generalization and training stability. "we utilize the AdamW \citep{adamw} optimizer with a constant learning rate of ."
- Chain-of-Thoughts (CoTs): A reasoning style where models generate explicit intermediate steps to solve problems. "The new generation of LLMs that use long Chain-of-Thoughts (CoTs) for reasoning"
- Clip-Higher: A DAPO-specific variant that increases the positive clipping range on importance ratios to stabilize training. "introduces the clip-higher and dynamic sampling with token-level loss"
- Clipping mechanism: PPO’s technique of restricting policy updates by clipping importance ratios within a preset range. "limits the update of the current policy to the proximal region of the old policy through the clipping mechanism."
- Curriculum Learning (CL): Training that progresses from easier to harder samples to improve efficiency and performance. "an approach called Curriculum Learning (CL)"
- DAPO (Decoupled Clip and Dynamic sampling Policy Optimization): An LLM RL method that removes KL regularization and adds clip-higher with dynamic sampling. "Decoupled Clip and Dynamic sampling Policy Optimization (DAPO) removes the KL divergence regularization"
- GAE (Generalized Advantage Estimator): A variance-reduction method for estimating advantages using exponentially-weighted TD residuals. "the advantage of is estimated using a value model by Generalized Advantage Estimator (GAE)"
- GRPO (Group Relative Policy Optimization): A policy optimization approach that uses relative advantages computed within rollout groups, avoiding a value model. "Group Relative Policy Optimization (GRPO) calculates the relative advantages of each response within a group of responses generated by LLM to the same query"
- Group variance: The variance of rewards across rollouts for the same prompt, used here as a difficulty/uncertainty signal. "the group variance for the query is given by"
- GSPO (Group Sequence Policy Optimization): A GRPO variant that aligns sequence-level rewards with sequence-level importance ratios. "Group Sequence Policy Optimization (GSPO) uses sequence-level importance ratio to replace the original token-level importance ratio"
- Importance ratio: The likelihood ratio between new and old policies for an action/token, central to PPO-style updates. "the importance ratio of the token is given by"
- Indicator function: A function that returns 1 if a condition holds and 0 otherwise, used to filter training samples. "and is the indicator function."
- KL divergence regularization: A penalty that constrains the updated policy to remain close to a reference policy by penalizing KL divergence. "removes the KL divergence regularization"
- KL penalty: A KL-based regularizer that controls exploration and stability during RL training. "and suggest increasing exploration around these tokens by changing the KL penalty."
- LLMs: Very large neural networks trained on extensive corpora for general language tasks and reasoning. "The new generation of LLMs"
- Memory bank: A replay store of high-value samples used to augment batches and stabilize training. "Replay Learning with a memory bank"
- Momentum update: An exponential smoothing scheme used to update priorities or parameters with a momentum coefficient. "maintaining it with a momentum update method."
- Normalized group variance p: Reward variance normalized by its maximum, used as a training value score for a query. "we can use the normalized group variance "
- Off-policy: Learning from data generated by a different policy than the current one. "enhances RLVR with off-policy reasoning traces, helping to balance imitation and exploration by combining off-policy demonstrations with on-policy rollouts."
- On-policy rollouts: Trajectories sampled from the current policy during training or evaluation. "by combining off-policy demonstrations with on-policy rollouts."
- PPO (Proximal Policy Optimization): A robust policy-gradient method that limits updates via a clipped objective for stability. "Proximal Policy Optimization (PPO) limits the update of the current policy to the proximal region of the old policy through the clipping mechanism."
- Priority queue: A data structure that serves higher-priority elements first; used for sampling from the memory bank. "The memory bank is implemented as a priority queue"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL where an external verifier provides correctness-based rewards to guide learning. "Reinforcement Learning with Verifiable Rewards (RLVR) has been proven to be an effective technique for achieving TTS in the post-training process."
- Replay Learning: Reusing stored, informative samples during training to improve efficiency and stability. "we further introduce Replay Learning with a memory bank to control training stability and improve training efficiency."
- Rollout: A generated trajectory (e.g., a response) from the policy for a given prompt. "Multiple rollouts for the same query can help measure how hard a training sample is for the current model."
- Sequence-level importance ratio: An importance ratio computed at the sequence level to match sequence-level rewards. "uses sequence-level importance ratio to replace the original token-level importance ratio"
- Sparse reward: A regime where non-zero rewards are rare, making learning signals infrequent. "current sparse reward system"
- Test-Time Interaction (TTI): An online RL approach that adapts rollout lengths during testing/training via a curriculum. "introduce TTI (Test-Time Interaction), an online RL method that adapts rollout lengths using a curriculum approach."
- Test-Time Scaling (TTS): Improving performance by increasing test-time compute (e.g., longer CoTs or more samples). "A notable feature of this type of LLMs is the phenomenon called Test-Time Scaling (TTS)"
- Top-p: Nucleus sampling that restricts sampling to the smallest set of tokens whose cumulative probability exceeds p. "The inference hyperparameters of evaluation are set to temperature 0.6 and top-p 0.95."
- Unbiased estimator: A statistic whose expected value equals the true parameter, used here for variance estimation. "the unbiased estimator of the group variance can be written as"
- Value model: A model estimating expected return/value used to compute advantages in policy gradients. "PPO relies on the value model to evaluate the current state."
- Variance-based Curriculum Reinforcement Learning (VCRL): The proposed framework that selects and replays high-variance samples to match model ability. "we introduce VCRL, a curriculum reinforcement learning framework that adjusts the difficulty of training samples based on the variance of group rewards."
- Variance-based Dynamic Sampling: Filtering queries by their normalized reward-variance score to focus on informative samples. "VCRL uses Variance-based Dynamic Sampling to select these samples for training"
- Verifier: An external checker that scores outputs to provide rewards in RLVR. "there is a verifier that can score a given query-response pair and obtain a reward"
Collections
Sign up for free to add this paper to one or more collections.