Context Bootstrapped Reinforcement Learning
Abstract: Reinforcement Learning from Verifiable Rewards (RLVR) suffers from exploration inefficiency, where models struggle to generate successful rollouts, resulting in minimal learning signal. This challenge is particularly severe for tasks that require the acquisition of novel reasoning patterns or domain-specific knowledge. To address this, we propose Context Bootstrapped Reinforcement Learning (CBRL), which augments RLVR training by stochastically prepending few-shot demonstrations to training prompts. The injection probability follows a curriculum that starts high to bootstrap early exploration, then anneals to zero so the model must ultimately succeed without assistance. This forces the policy to internalize reasoning patterns from the demonstrations rather than relying on them at test time. We validate CBRL across two model families and five Reasoning Gym tasks. Our results demonstrate that CBRL consistently improves success rate, provides better exploration efficiency, and is algorithm-agnostic. We further demonstrate CBRL's practical applicability on Q, a domain-specific programming language that diverges significantly from mainstream language conventions.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑language summary of “Context Bootstrapped Reinforcement Learning”
What is this paper about?
This paper introduces a simple idea to help AI models learn tricky tasks faster and better. The idea is called Context Bootstrapped Reinforcement Learning (CBRL). It adds a few worked examples to some practice questions while the model is training, and then slowly removes those examples over time. The goal is to teach the model new reasoning skills early on, and then make sure it can solve problems on its own.
What questions did the researchers ask?
The researchers focused on a common problem in training: when a model only gets a reward if its final answer is exactly right, it can struggle to improve because it rarely gets things right at the beginning. They asked:
- Can we kick‑start learning by showing a few examples at the start of training?
- If we gradually stop showing examples, will the model keep the skills it learned and perform well without help?
- Does this approach work across different tasks, different models, and different training algorithms?
How did they do it? (Simple explanation with analogies)
Think of teaching as two phases:
- Early on, you give students a couple of solved examples before they try a new problem.
- Later, you remove the examples so they have to solve problems by themselves.
That’s exactly what CBRL does:
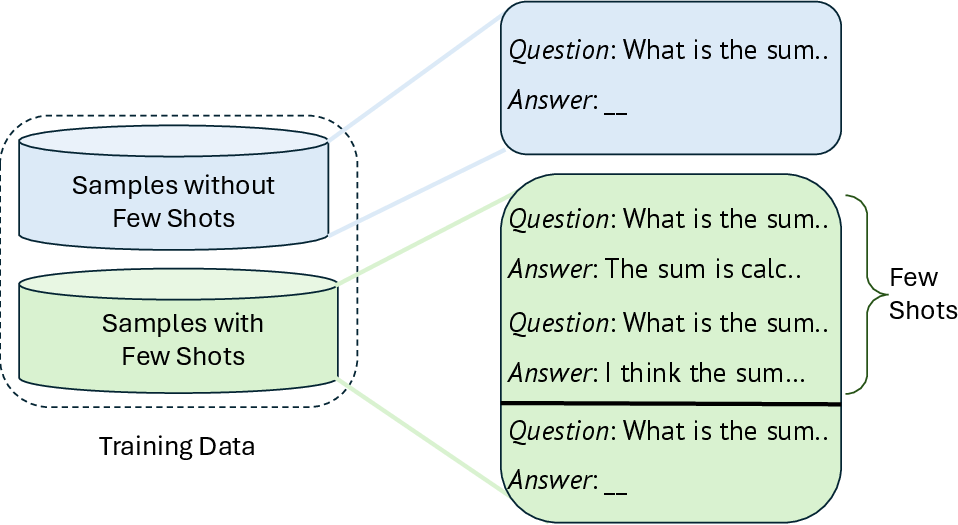
- Few‑shot examples: The model keeps a small “bank” of solved examples (like 2 examples per problem type).
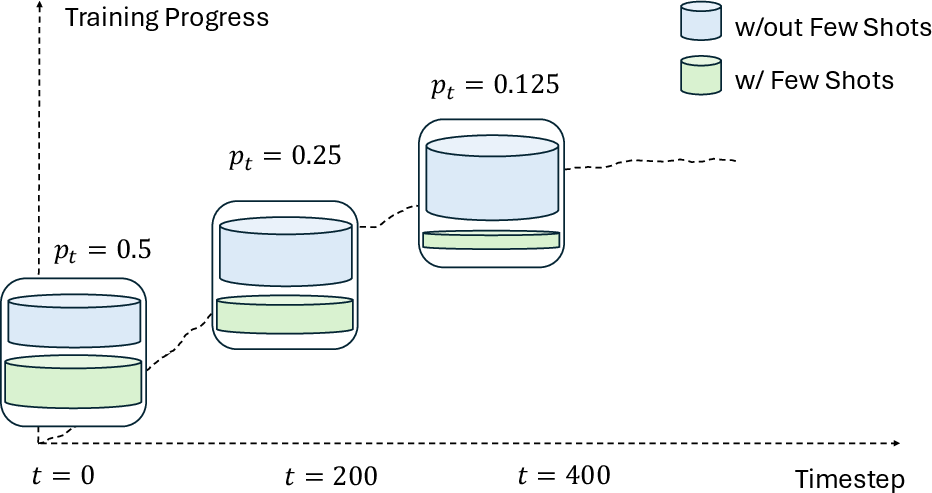
- Random injection: During training, the model sometimes gets those examples added to the front of the prompt (like seeing a worked example on top of the worksheet). This happens with a certain probability.
- Annealing schedule: That probability starts fairly high (about 50%) and then slowly goes down to zero. By the end, the model no longer sees any examples and must work independently.
Key terms in everyday language:
- Reinforcement Learning from Verifiable Rewards (RLVR): The model gets a “point” only if its final answer is correct. This is like a test that’s automatically graded as right or wrong—no partial credit unless tests are set up to allow it.
- Exploration inefficiency: If the model rarely gets anything right, it gets almost no feedback and struggles to improve—like guessing on a puzzle where you only learn something when you accidentally guess the full answer.
- In‑context learning: The model can learn patterns just by reading a few examples in the prompt, even without changing its internal “brain” yet—like a student learning from worked examples right on the page.
They tested CBRL on:
- Five puzzle‑like “Reasoning Gym” tasks (sorting words, reversing a word, grid/matrix changes, a one‑dimensional logic task, and the 24 game).
- Writing code in Q, a niche programming language with unusual rules (for example, it evaluates expressions right‑to‑left), which most models haven’t seen much in their training.
They also checked that CBRL works with different reinforcement learning techniques, including GRPO and RLOO (you can think of these as two different ways to update the model based on rewards).
What did they find, and why is it important?
Main results:
- Better accuracy across the board on puzzles: CBRL beat the standard training method on all five Reasoning Gym tasks and with two different model families (Qwen and Llama). In some cases, the improvement was big—for example, on “Word Sorting” one model jumped by about 22 percentage points.
- Big gains on Q programming: With Q code problems, the average fraction of tests passed per problem rose from about 27% to 43%, and the chance of fully solving a problem (passing all tests) went from about 5% to 26%. That’s a strong sign the model learned not just to write valid‑looking Q code, but to solve tasks correctly.
- Works with different algorithms: CBRL improved results when paired with two different reinforcement learning methods (GRPO and RLOO). That means it’s “algorithm‑agnostic”—it slots into many training setups.
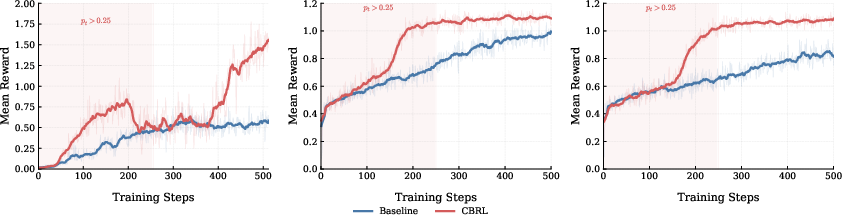
- Faster, sturdier learning: Training curves showed that models using CBRL started getting rewards earlier (thanks to the examples), and they kept the improvement even after the examples were phased out. In other words, the method helps the model discover good strategies sooner and then internalize them.
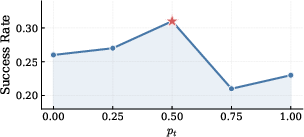
- The “just right” amount of help matters: Starting with a moderate chance (around 50%) of showing examples worked best. Too many examples made the model lazy; too few didn’t help enough.
Why this matters:
- It tackles the “slow start” problem in training: By giving temporary, light guidance, the model gets the early wins it needs to learn faster, especially in unfamiliar areas.
- It builds lasting skills: Because the examples are gradually removed, the model actually learns the reasoning patterns instead of depending on examples at test time.
- It’s simple and general: You don’t need to change the core learning algorithm—just occasionally add examples at the start, then taper off.
What’s the potential impact?
- Smarter training for hard reasoning tasks: Subjects like math puzzles, algorithmic thinking, or unusual languages (like Q) can be learned more efficiently.
- Better use of examples: Instead of always relying on examples in the prompt (which can be slow and costly at test time), this method uses examples only during training, so the final model answers on its own.
- Easy to combine with other methods: Because it doesn’t change the reward or the optimizer, CBRL can be layered on top of many existing training pipelines.
Bottom line
CBRL is like giving a learner training wheels and then removing them at the right pace. It helps AI models find successful solutions early, learn the reasoning behind them, and then ride on their own—faster and more confidently—across different tasks, models, and training styles.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces CBRL and shows promising results, but several aspects remain uncertain or unexplored. Future researchers could address the following gaps:
- Scaling behavior: How does CBRL perform with larger models (e.g., 7B–70B+) and different architectures beyond Qwen and Llama? Does the optimal injection schedule or k change with scale?
- Task diversity and realism: CBRL is validated on five synthetic Reasoning Gym tasks and Q programming; its effectiveness on broader, real-world reasoning benchmarks (e.g., GSM8K, MATH, MBPP/HumanEval, NL reasoning, tool-use) is untested.
- Long-horizon settings: The method’s applicability to multi-step, long-horizon tasks and agentic workflows (where early errors compound) remains open, including whether annealed context still bootstraps exploration effectively.
- Token/computation budget fairness: Context injection increases prompt length and thus training tokens per step. The study does not control for equalized token budgets or report training-time/throughput overheads, leaving cost-effectiveness and fair comparison unresolved.
- Annealing schedule design: Only a linear decay with a small ablation on the initial probability is evaluated. The impact of schedule type (e.g., exponential, cosine, cyclical), anneal rate, and adaptive/performance-based schedules is not explored.
- Hyperparameter sensitivity: The effects of k (number of exemplars), bank size, example ordering/formatting, and mixing ratio schedules on stability and final performance are underexplored.
- Demonstration bank construction: Best practices for building the few-shot bank (size, diversity, domain coverage, difficulty mix) are not established; robustness to noisy or partially incorrect demonstrations (e.g., GPT-generated traces) is untested.
- Selection/retrieval strategy: Example selection is either uniform or coarse tag-filtered; there is no learned or similarity-based retrieval analysis. Misalignment between retrieved context and instance likely explains the observed failures (e.g., ARC-1D and Matrix under RLOO), but no diagnostic or mitigation is provided.
- Negative transfer and failure detection: Conditions under which CBRL harms learning (observed with RLOO on some tasks) are not characterized; methods to detect/avoid misleading demonstrations in-the-loop are absent.
- Reward design interaction: The interaction between CBRL and different RLVR reward structures (binary vs partial shaping, format bonuses, group sizes) is not systematically studied.
- Algorithm generality beyond GRPO/RLOO: Although claimed “algorithm-agnostic,” evidence is limited to two PG methods; behavior with other objectives (e.g., PPO-variants with KL, DPO/IPO-style methods, off-policy RL, value baselines) is unknown.
- Exploration efficiency quantification: While training curves suggest earlier rewards, the work does not quantify exploration sample-efficiency (e.g., successful rollouts per token, gradient variance reduction) or provide a formal analysis.
- Inference robustness and distribution shift: The study verifies that performance persists without test-time exemplars but does not assess sensitivity to prompt/style shifts, adversarial formatting, or cross-domain/generalization stress tests.
- Content of demonstrations: Only full demonstrations (question, reasoning, answer) are used; ablations on what to include (e.g., reasoning only vs answer only vs IO pairs) and their differing effects on credit assignment or reward hacking are missing.
- Potential leakage/contamination: For the Q dataset, it is unclear whether the demonstration bank strictly excludes test problems/solutions, and whether near-duplicate patterns exist. A documented de-duplication protocol and leakage checks are absent.
- Syntax vs functionality trade-off in Q: CBRL improves Pass@1 but lowers the valid Q rate; the reasons and trade-offs (syntax correctness vs functional correctness) are not analyzed, nor are remedies (e.g., dual-objective rewards) explored.
- Retrieval granularity for code domains: Tag-based filtering for Q is coarse; no study of embedding-based retrieval, program analysis features, or difficulty-aware selection to better align demonstrations with target problems.
- Context length limits: The impact of longer prompts on models with constrained context windows is not examined, particularly for tasks requiring longer inputs or more exemplars.
- Extended training dynamics: Persistence of gains with longer training beyond 500 steps and behavior when annealing reaches zero for extended periods are not reported.
- Interaction with complementary methods: Compositions with hints, self-reflection, off-policy seeding, self-generated curricula, or tool-use are not evaluated, leaving synergy/antagonism unknown.
- Safety and spurious pattern reliance: Whether CBRL encourages reliance on surface patterns from demonstrations (vs causal reasoning) and how robust learned strategies are to perturbations is not tested.
- Theoretical grounding: There is no formal account of when/why CBRL improves gradients (e.g., bias/variance effects on group-relative estimators) or sample complexity, nor criteria to predict when it may hurt.
- Reproducibility details: The work omits some practical details (e.g., exact bank contents, seeds, prompt templates, and full hyperparameter sweeps), hindering faithful replication and controlled comparisons.
- Data/resource release: Public release of the few-shot banks, training scripts, and evaluation harnesses (particularly for Q) is not specified, limiting independent validation and extension.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s LLMs, verifiers, and RL training stacks by adding a few-shot example bank and the annealed context-injection schedule described in the paper.
- Software: domain‑specific code assistants (e.g., Q/kdb+, SQL dialects, config DSLs)
- What: Train code assistants to produce correct programs in niche or proprietary DSLs (e.g., Q in finance, router configs, EDA scripts, SAS/ABAP/COBOL, PLC ladder logic) using unit tests or linters as verifiers.
- Workflow/product: “CBRL Trainer” plug‑in for GRPO/RLOO pipelines; few‑shot bank service with task tags; annealing scheduler; unit‑test harness.
- Why now: Paper shows 5.0% → 26.3% Pass@1 on Q; RLVR verifiers (tests/linters) are readily available for many DSLs.
- Dependencies/assumptions: Existence of verifiable rewards (unit tests, compilers, validators); curated few‑shot bank; safe sandboxes for code execution; compute for longer training prompts; careful tuning of injection probability (≈0.5 worked best).
- Data engineering and analytics: reliable transformation/code generation
- What: Train LLMs to emit SQL/DBT/ETL scripts with test‑driven verifiers (schema/row‑level tests, snapshot checks).
- Workflow/product: CBRL‑augmented training that injects 1–3 solved examples with tags (e.g., “windowing,” “joins”) early in training; anneal to zero.
- Why now: Deterministic tests can score correctness; boosts early exploration on unfamiliar warehouse dialects.
- Dependencies/assumptions: Good coverage of unit tests; example bank diversity; retrieval that matches examples to tasks.
- Networking and telecom: configuration synthesis and validation
- What: Generate network configs (ACLs, QoS, routing) validated by offline checkers and policy engines.
- Workflow/product: Enterprise “ConfigOps CBRL” integrating vendor validators; example bank of canonical policy‑compliant configs; annealed injection during RL.
- Why now: Strong verifiers (syntax + policy checks) exist; authorship includes Cisco Research.
- Dependencies/assumptions: Accurate policy verifiers; up‑to‑date device models; security sandboxing.
- Finance: quantitative scripting and query assistants (Q/kdb+, risk DSLs)
- What: Train assistants to author performant Q queries and analytics with unit tests on time‑series outputs.
- Workflow/product: Pass@k evaluation harness, test‑case rewards, bank of tagged examples (arrays, DP, joins).
- Why now: Demonstrated gains on Q; finance teams often have internal test suites.
- Dependencies/assumptions: Representative test cases; governance around proprietary code in few‑shot banks.
- Education: math/logic solvers with programmatic verifiers
- What: Improve solvers for problem types with exact checkers (arithmetic, algebra, combinatorics, puzzles).
- Workflow/product: Auto‑graded problem banks; small demonstration sets with step‑by‑step traces; CBRL‑GRPO training.
- Why now: Reasoning Gym results show consistent gains; math verifiers are easy to build.
- Dependencies/assumptions: High‑quality example explanations; prevent leakage to test split.
- Quality assurance and CI/CD: “test‑driven” code refactoring bots
- What: Train bots to satisfy existing test suites during refactors or code repair.
- Workflow/product: CI job runs RLVR with CBRL on failing tests; banks seeded with past fixes; anneal injection over runs.
- Why now: Verifiers are existing tests; zero inference overhead post‑training.
- Dependencies/assumptions: Robust, non‑flaky tests; execution sandbox; compute budget.
- Tool‑use chains with deterministic checkers
- What: Train agents to call calculators, formatters, or schema validators to pass objective checks (e.g., JSON schema).
- Workflow/product: CBRL plug‑in for tool‑augmented RL; example banks of correct tool invocation patterns.
- Why now: Many tool calls can be deterministically verified, aligning with RLVR.
- Dependencies/assumptions: Stable tool APIs; secure tool sandboxes; example coverage of tool patterns.
- Enterprise personalization: rapid adaptation to team‑specific conventions
- What: Fine‑tune assistants to team coding styles/templates (e.g., logging macros), verified by lints and style tests.
- Workflow/product: Lightweight CBRL on internal repos with style checkers as rewards; few curated examples per rule.
- Why now: Requires few examples and existing verifiers; avoids reliance on in‑context prompts at inference.
- Dependencies/assumptions: Lint rules accurately reflect style goals; IP governance for examples.
- Daily life and prosumer tools: spreadsheet formula and script generation
- What: Train small models to produce correct spreadsheet formulas or shell scripts validated by test sheets or golden outputs.
- Workflow/product: “Personal CBRL” with a small bank of user‑solved examples; annealed training on local datasets.
- Why now: Simple verifiers (expected cell values, CLI outputs) are easy to set up.
- Dependencies/assumptions: User willing to provide a handful of solved cases; sandboxing for script execution.
- Research tooling: faster RLVR prototyping with better exploration
- What: Use CBRL to stabilize early training on new tasks/environments with sparse rewards.
- Workflow/product: Open‑source CBRL module (few‑shot bank manager + scheduler) for GRPO/RLOO in standard RLVR stacks.
- Why now: Method is algorithm‑agnostic and only alters input distribution.
- Dependencies/assumptions: Minimal—curate 10–50 examples; select annealing schedule; track early‑training rewards.
Long‑Term Applications
These applications need additional research, scaling, or infrastructure (e.g., richer verifiers, longer‑horizon credit assignment, automated example curation) before wide deployment.
- Robotics and manufacturing: policy learning with simulator verifiers
- What: Train task planners or code generators (e.g., PLC, robot DSLs) using simulation as a verifiable reward.
- Potential product: “CBRL‑Sim” tying example trajectories and task scripts to physics‑based simulators; schedule‑aware context injection.
- Research gaps: Fast, faithful simulators as deterministic verifiers; handling long horizons and compounding errors.
- Multi‑step agentic workflows and long‑horizon reasoning
- What: Apply CBRL to complex pipelines (web agents, multi‑tool plans) where correctness is measured at episode end.
- Potential product: Agent frameworks with episode‑level verifiers and adaptive injection.
- Research gaps: Credit assignment; partial/hierarchical verifiers; curriculum over subgoals.
- Healthcare: guideline‑conformant data transforms and queries
- What: Train models to generate EHR queries, FHIR transforms, or cohort definitions verified against rule engines or synthetic data.
- Potential product: “Clinical CBRL” with audited example banks and compliance checkers.
- Research gaps: High‑fidelity verifiers; privacy‑preserving example curation; regulatory approval pathways.
- Security and compliance: policy‑as‑code synthesis with formal checks
- What: Generate IAM policies, firewall rules, or compliance templates verified by formal or symbolic checkers.
- Potential product: “CBRL‑Policy” integrated with OPA/ASP and formal methods backends.
- Research gaps: Robust formal verifiers across real‑world edge cases; preventing reward hacking.
- Energy and industrial control: SCADA/EMS scripting with validator or digital‑twin rewards
- What: Train assistants to propose safe control scripts validated in digital twins.
- Potential product: Twin‑integrated CBRL with domain‑tagged example banks.
- Research gaps: Accurate twins; safety constraints; regulatory acceptance.
- Adaptive injection schedules and learned retrieval
- What: Make the probability schedule and example selection policy adaptive to reward trends or uncertainty.
- Potential product: “Auto‑CBRL” that learns per‑task schedules and retrieval via bandits or RL.
- Research gaps: Stability guarantees; avoidance of over‑scaffolding; generalization across tasks.
- Automatic construction of few‑shot banks
- What: Mine high‑quality demonstrations from stronger models, self‑play, or production traces with verification gates.
- Potential product: Example‑bank builder with deduplication, tagging, and leakage guards.
- Research gaps: Filtering for true solution diversity; preventing overfitting and data leakage.
- Government and policy: procurement standards for verifiable‑reward post‑training
- What: Encourage adoption of RLVR + CBRL for transparency and auditability in public sector AI systems.
- Potential product: Guidance documents and benchmarks on exploration efficiency and annealed scaffolding.
- Research gaps: Domain‑specific verifiers for civic tasks; conformance testing; standard metrics.
- On‑device or privacy‑preserving personalization
- What: Local CBRL fine‑tuning using private examples and synthetic verifiers (e.g., local tests).
- Potential product: Edge fine‑tuning runtimes with low‑rank adaptation and context injection.
- Research gaps: Memory/computation constraints for long prompts; private/verifiable reward construction.
- Cross‑model and cross‑domain generalization studies
- What: Systematic evaluation across scales and domains to define best‑practice schedules and bank sizes.
- Potential product: Community benchmarks and leaderboards on exploration efficiency under CBRL.
- Research gaps: Scaling laws; domain‑mismatch effects; robust retrieval strategies.
- Safety‑aware CBRL with intervention limits
- What: Combine CBRL with guardrails to avoid unsafe scaffolding in sensitive domains.
- Potential product: Safety wrapper that filters examples and constrains exploration.
- Research gaps: Measuring and mitigating unintended behaviors; safe reward design.
Notes on feasibility across items:
- CBRL assumes access to verifiable rewards; tasks without deterministic or high‑fidelity verifiers will see limited benefit.
- Quality and relevance of the few‑shot bank are critical; poor or mismatched examples can hurt performance (as seen on some RLOO tasks).
- Training‑time overhead increases due to longer prompts, though inference‑time cost is unchanged.
- Proper annealing and moderate initial injection probability (~0.5) are important to avoid over‑scaffolding and ensure durable capability acquisition.
Glossary
- Advantage (group advantage): A policy-gradient signal measuring how much a sampled outcome exceeds its peers; used to guide updates. "the group advantage collapses to zero"
- Annealing schedule: A training schedule that gradually reduces a parameter over time to encourage autonomy. "The injection probability follows a linear annealing schedule:"
- ARC-1D: A one-dimensional version of the ARC-AGI reasoning benchmark used as an RL environment. "ARC-1D: A one-dimensional adaptation of the ARC-AGI challenge"
- Bernoulli: A 0/1 random variable with success probability p; used to decide whether to inject examples. "Bernoulli(p)"
- Binary reward: A reward that is either 0 or 1 based solely on final answer correctness. "the model receives a binary reward purely based on its final output."
- CBRL (Context Bootstrapped Reinforcement Learning): The proposed method that stochastically prepends few-shot exemplars during training and anneals their use to zero. "Context Bootstrapped Reinforcement Learning (CBRL) augments the standard RLVR training process by incorporating in-context examples as temporary scaffolding."
- Curriculum (curriculum schedule): A staged training plan that starts with more assistance and reduces it to promote independent performance. "The injection probability follows a curriculum that starts high to bootstrap early exploration, then anneals to zero"
- Deterministic verifiers: Non-learned checkers that deterministically judge correctness to produce rewards. "RLVR leverages deterministic verifiers providing binary feedback based on answer correctness."
- Exploration inefficiency: A failure mode where the agent rarely finds successful solutions, yielding little learning signal. "suffers from exploration inefficiency"
- FSDP: Fully Sharded Data Parallel; a distributed training technique that shards model parameters across devices. "using FSDP"
- GRPO (Group Relative Policy Optimization): A policy-gradient algorithm that computes advantages relative to other samples in the same group. "Group Relative Policy Optimization (GRPO)."
- ICL-augmented prompts: Prompts enhanced with few-shot exemplars to guide reasoning during training. "ICL-augmented prompts."
- In-Context Learning (ICL): The ability of an LLM to learn from examples provided in the prompt without parameter updates. "leverages the In-Context Learning capabilities of LLMs"
- Importance sampling: A technique that reweights samples to correct for distribution mismatch, sometimes with regularization. "regularized importance sampling"
- kdb+: A high-performance columnar/time-series database system on which the Q language is built. "built on the kdb+ database system."
- Off-policy trajectories: Training examples generated by a policy different from the one being optimized. "off-policy trajectories"
- On-policy rollouts: Trajectories sampled from the current policy during training. "on-policy rollouts"
- Pass@1: The probability that the first generated solution passes all tests. "Pass@1 ()"
- Policy gradient methods: Algorithms that optimize policies by estimating gradients of expected rewards from sampled trajectories. "policy gradient method (GRPO, RLOO, or others)"
- Programmatic verifier: An automated checker that deterministically evaluates solution correctness. "we evaluate using the programmatic verifier"
- Q Programming: The Q language used with kdb+, featuring terse, array-oriented syntax and right-to-left evaluation. "We further evaluate on Q Programming"
- Reasoning Gym: A benchmark of procedurally generated reasoning environments for training and evaluation. "five reasoning tasks from the Reasoning Gym benchmark"
- REINFORCE Leave-One-Out (RLOO): A variance-reduced policy-gradient estimator that excludes one sample when computing baselines. "REINFORCE Leave-One-Out (RLOO)"
- Reinforcement Learning from Human Feedback (RLHF): RL that uses a learned reward model trained on human preferences. "Reinforcement Learning from Human Feedback (RLHF)"
- Reinforcement Learning from Verifiable Rewards (RLVR): RL that uses deterministic verifiers to provide binary correctness-based feedback. "Reinforcement Learning from Verifiable Rewards (RLVR)"
- Reward sparsity: A condition where non-zero rewards are rare, making learning difficult. "This reward sparsity is particularly severe"
- Rollouts: Generated trajectories or sequences (e.g., model outputs) used to compute rewards for training. "successful rollouts"
- Value model: A learned estimator of expected return that some RL methods require but GRPO avoids. "eliminating the need for a separate value model"
Collections
Sign up for free to add this paper to one or more collections.